

Java 스레드 풀 실행자 사용 방법

스레드 풀 클래스 다이어그램
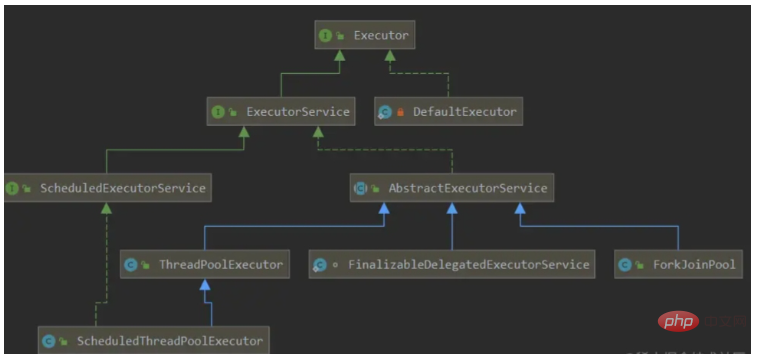
스레드 풀을 생성하고 스레드를 사용하기 위해 가장 일반적으로 사용되는 Executor 구현은 주로 위의 클래스 다이어그램에서 제공되는 클래스를 사용합니다. 위의 클래스 다이어그램에는 실행을 예약하고 일련의 실행 전략 호출을 기반으로 비동기 작업을 제어하는 프레임워크인 Executor 프레임워크가 포함되어 있습니다. 목적은 작업 실행 방법과 작업 제출을 분리하는 메커니즘을 제공하는 것입니다. 여기에는 세 가지 실행기 인터페이스가 포함되어 있습니다.
Executor: 새 작업을 실행하기 위한 간단한 인터페이스
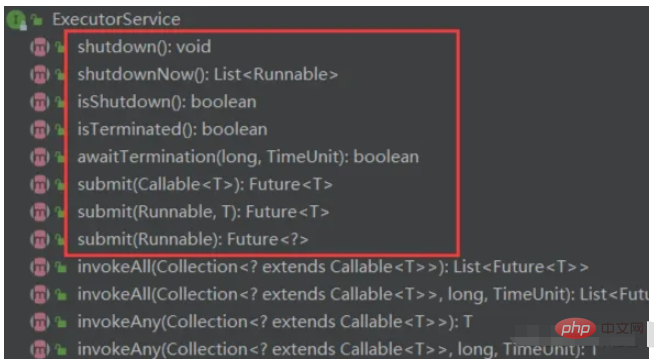
ExecutorService: Executor를 확장하고 실행기 수명 주기 및 작업 수명 주기를 관리하는 메서드 추가
ScheduleExcutorService: 지원하는 확장 ExecutorService 향후 및 주기적 작업 실행
스레드 풀의 이점
리소스 소비 감소 - 기존 스레드 재사용, 객체 생성 및 종료 비용 감소, 성능 향상
응답 속도 - It 최대 동시 스레드 수를 효과적으로 제어하고, 시스템 리소스 활용도를 향상시키며, 동시에 과도한 리소스 경쟁을 방지하고 차단을 방지할 수 있습니다. 태스크가 도착하면 스레드 생성을 기다리지 않고 즉시 태스크를 실행할 수 있습니다
스레드 관리성 향상 - 예약 실행, 주기 실행, 단일 스레드, 동시성 제어 등의 기능을 제공합니다.
새 스레드의 단점
새 스레드가 새 객체를 생성할 때마다 성능이 저하됩니다.
통합 스레드 관리가 부족하여 무제한의 새 스레드가 생겨 서로 경쟁하고 점유할 수 있습니다. 시스템 리소스가 너무 많아 충돌이나 OOM(메모리 부족 메모리 오버플로)이 발생하는 경우, 이 문제의 원인은 단순히 새로운 스레드가 아니라 프로그램 버그나 설계 결함으로 인해 지속적으로 새로운 스레드가 발생할 수도 있습니다.
추가 실행, 주기적 실행, 스레드 중단과 같은 추가 기능이 없습니다.
스레드 풀 코어 클래스-ThreadPoolExecutor
매개변수 설명: ThreadPoolExecutor에는 총 7개의 매개변수가 함께 작동하여 스레드 풀의 강력한 기능을 형성합니다.
corePoolSize: 코어 스레드 수
maximumPoolSize: 최대 스레드 수
workQueue: 대기열 차단, 실행 대기 중인 작업 저장, 매우 중요합니다. 스레드에 상당한 영향을 미칩니다. 풀 실행 프로세스
새 작업을 스레드 풀에 제출하면 스레드 풀은 현재 풀에서 실행 중인 스레드 수에 따라 작업을 처리하는 방법을 결정합니다. 3가지 처리 방법이 있습니다.
1. 직접 전환(SynchronusQueue)
2. Unbounded queue(LinkedBlockingQueue) 생성할 수 있는 최대 스레드 수는 corePoolSize이며, 이때 maximumPoolSize는 작동하지 않습니다. 스레드 풀의 모든 코어 스레드가 실행 중이면 새 작업 제출이 대기 대기열에 배치됩니다.
3. 제한된 대기열(ArrayBlockingQueue)의 최대 풀 크기는 리소스 소비를 줄일 수 있지만 이 방법은 스레드 풀 예약을 더 어렵게 만듭니다. 스레드 풀과 대기열 용량이 제한되어 있기 때문입니다. 따라서 스레드 풀 및 처리 작업의 처리 속도가 합리적인 범위에 도달하기를 원하고 스레드 스케줄링을 상대적으로 단순하게 만들고 리소스 소비를 최대한 줄이려면 이 두 가지 수량 할당 기술을 합리적으로 제한해야 합니다. : [ CPU 사용량, 운영 체제 리소스 사용량, 컨텍스트 전환 오버헤드 등을 포함하여 리소스 사용량을 줄이려는 경우 대기열 용량을 크게 설정하고 스레드 풀 용량을 작게 설정하면 스레드 풀의 처리량이 줄어듭니다. . 제출하는 작업이 자주 차단되는 경우 maximumPoolSize를 조정할 수 있습니다. 대기열 용량이 작다면 스레드 풀 크기를 더 크게 설정해야 CPU 사용량이 상대적으로 높아집니다. 그러나 스레드 풀의 용량을 너무 크게 설정하여 작업 개수를 너무 많이 늘리면 동시성(concurrency)의 양이 늘어나게 되므로 스레드 간 스케줄링을 고려해야 할 문제이다. 대신 처리 작업의 처리량이 줄어들 수 있습니다. ]
keepAliveTime: 작업 실행이 없을 때 스레드가 지속될 수 있는 시간(스레드의 스레드 수가 corePoolSize보다 큰 경우, 이때 제출된 새 작업이 없으면 코어 스레드 외부의 스레드) 즉시 소멸되지 않고 keepAliveTime이 초과될 때까지 기다립니다)
unit: keepAliveTime의 시간 단위
threadFactory: 스레드를 생성하는 데 사용되는 스레드 팩토리, 스레드를 생성하는 기본 팩토리가 있으므로 새로 생성된 스레드의 우선순위가 같다는 것, 데몬이 아닌 스레드인지, 이름이 설정되어 있는지)
rejectHandler: 작업 처리를 거부할 때의 정책(차단 대기열이 가득 찼을 때)(AbortPolicy 기본 정책은 예외가 직접 발생하면 CallerRunsPolicy는 호출자의 스레드를 사용하여 작업을 실행하고 DiscardOldestPolicy는 대기열을 삭제합니다. 상위 작업과 현재 작업을 실행하면 DiscardPolicy는 현재 작업을 직접 삭제합니다.
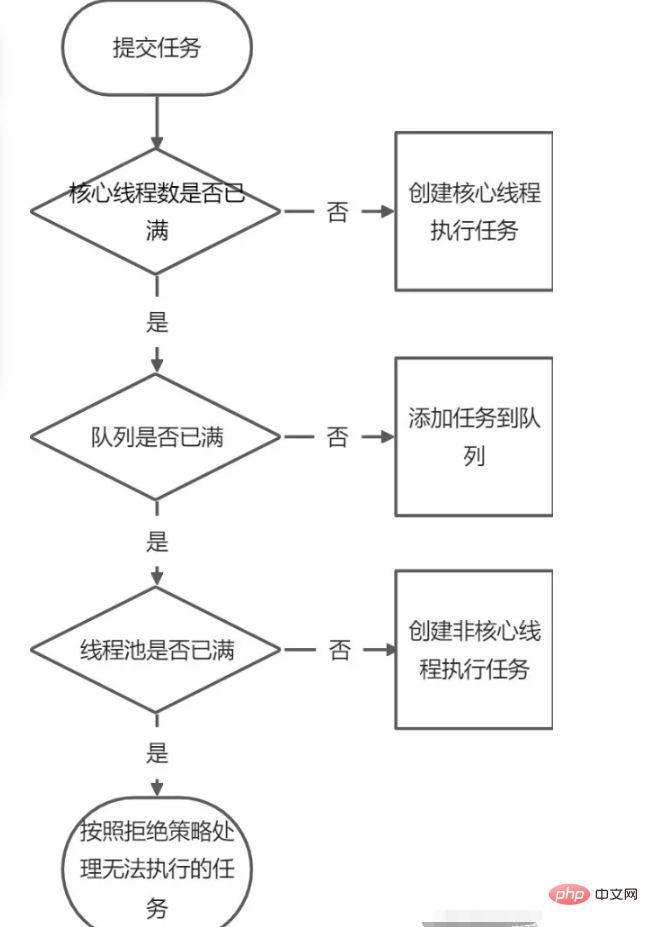
corePoolSize, maximumPoolSize 및 workQueue의 관계: 실행 중인 스레드 수가 corePoolSize보다 적으면 작업을 처리하기 위해 새 스레드가 직접 생성됩니다. 스레드 풀의 다른 스레드가 유휴 상태인 경우에도 마찬가지입니다. 실행 중인 스레드 수가 corePoolSize보다 크고 maximumPoolSize보다 작은 경우 workQueue가 가득 찼을 때만 작업을 처리하기 위해 새 스레드가 생성됩니다. corePoolSize와 maximumPoolSize가 동일한 경우 생성되는 스레드 풀의 크기는 고정됩니다. 이때 새로운 작업이 제출되며, workQueue가 가득 차지 않으면 요청이 workQueue에 배치됩니다. 빈 스레드가 작업 대기열에서 작업을 제거할 때까지 기다립니다. 이때 workQueue도 가득 찬 경우 추가 거부 정책 매개변수를 사용하여 거부 정책을 실행합니다.
초기화 방법: 7개의 매개변수를 4개의 초기화 방법으로 구성
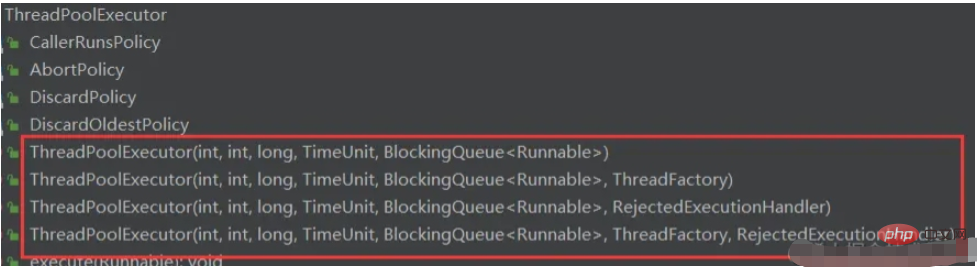
기타 방법:
execute(); //提交任务,交给线程池执行 submit();//提交任务,能够返回执行结果 execute+Future shutdown();//关闭线程池,等待任务都执行完 shutdownNow();//关闭线程池,不等待任务执行完 getTaskCount();//线程池已执行和未执行的任务总数 getCompleteTaskCount();//已完成的任务数量 getPoolSize();//线程池当前的线程数量 getActiveCount();//当前线程池中正在执行任务的线程数量
스레드 풀 수명 주기:
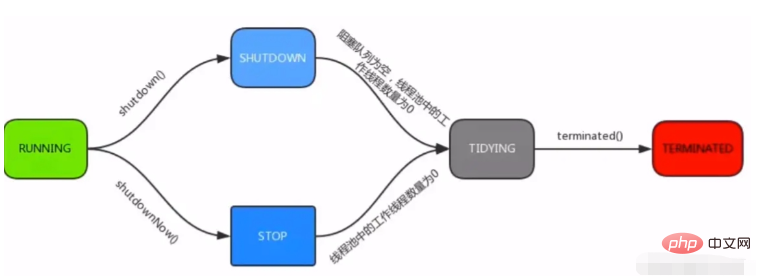
running: 새로 제출된 작업을 수락하고 처리할 수도 있습니다. the Blocking queue
shutdown: 새 작업을 처리할 수 없지만 차단 대기열에 있는 작업은 계속 처리할 수 있습니다
stop: 새 작업을 받을 수도 없고 대기열에 있는 작업도 처리할 수 없습니다
tidying: 모든 작업이 종료되었으며 유효 스레드 수는 0
종료됨: 최종 상태
Executor를 사용하여 스레드 풀 생성
Executor를 사용하면 위에서 언급한 스레드 풀에 해당하는 4개의 스레드 풀을 생성할 수 있습니다. 풀 초기화 방법
Executors.newCachedThreadPool
newCachedThreadPool은 작업이 제출되면 corePoolSize가 0이고 코어 스레드가 생성되지 않는 스레드 풀입니다. 이해할 수 있음 대기열이 항상 가득 차 있기 때문에 결국 작업을 수행하기 위해 비핵심 스레드가 생성됩니다. 비코어 스레드는 60초 동안 유휴 상태일 때 재활용됩니다. Integer.MAX_VALUE는 크기가 매우 크기 때문에 스레드를 무한히 생성할 수 있어 리소스가 제한되어 있을 경우 OOM 예외가 쉽게 발생할 수 있다고 생각할 수 있습니다.
//创建newCachedThreadPool线程池源码
public static ExecutorService newCachedThreadPool() {
/**
*corePoolSize: 0,核心线程池的数量为0
*maximumPoolSize: Integer.MAX_VALUE,可以认为最大线程数是无限的
*keepAliveTime: 60L
*unit: 秒
*workQueue: SynchronousQueue
**/
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}사용 사례:
public static void main(String[] args) {
ExecutorService executor = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int index = i;
executor.execute(new Runnable() {
@Override
public void run() {
log.info("task:{}",index);
}
});
}
}newCachedThreadPool의 반환 값은 ExecutorService 유형이라는 점에 유의할 필요가 있습니다. 이 유형에는 기본 스레드 풀 메서드만 포함되어 있으며, 스레드 모니터링 관련 메서드는 포함되지 않습니다. 새 스레드를 생성할 때 ExecutorService 스레드 풀 유형을 고려해야 합니다.
Executors.newSingleThreadExecutor
newSingleThreadExecutor는 단일 스레드 풀로, 단 하나의 코어 스레드만 갖고 작업을 실행하는 데 단 하나의 공유 스레드를 사용하여 모든 작업이 지정된 순서(FIFO, 우선 순위)로 실행되도록 합니다. ..)
//newSingleThreadExecutor创建线程池源码
public static ExecutorService newSingleThreadExecutor() {
/**
* corePoolSize : 1,核心线程池的数量为1
* maximumPoolSize : 1,只可以创建一个非核心线程
* keepAliveTime : 0L
* unit => 秒
* workQueue => LinkedBlockingQueue
**/
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}작업이 제출되면 작업을 실행하기 위해 먼저 코어 스레드가 생성됩니다. 코어 스레드 수가 이 수를 초과하면 LinkedBlockingQueue는 길이가 있는 대기열이므로 대기열에 추가됩니다. Integer.MAX_VALUE의 경우 무한한 대기열로 간주될 수 있으므로 대기열에 무제한으로 삽입할 수 있으며, 이는 무제한으로 인해 리소스가 제한될 때 쉽게 OOM 예외가 발생할 수 있습니다. 대기열의 경우 maximumPoolSize 및 keepAliveTime 매개변수는 유효하지 않으며 비핵심 스레드는 전혀 생성되지 않습니다.
Executors.newFixedThreadPool
고정 길이 스레드 풀, 코어 스레드 수 및 최대 스레드 수가 사용자에 의해 전달됩니다. 최대 동시 스레드 수를 설정할 수 있으며 최대 동시 스레드 수는 대기합니다. in the queue
//newFixedThreadPool创建线程池源码
public static ExecutorService newFixedThreadPool(int nThreads) {
/**
* corePoolSize : 核心线程的数量为自定义输入nThreads
* maximumPoolSize : 最大线程的数量为自定义输入nThreads
* keepAliveTime : 0L
* unit : 秒
* workQueue : LinkedBlockingQueue
**/
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}newFixedThreadPool은 SingleThreadExecutor와 유사하지만 유일한 차이점은 코어 스레드의 숫자가 다르며 LinkedBlockingQueue를 사용하기 때문에 리소스가 제한될 때 OOM 예외가 발생하기 쉽습니다.
Executors.newScheduledThreadPool
고정 길이 스레드 풀, 사용자가 코어 스레드 수 전달, 예약 및 주기적인 작업 실행 지원
//newScheduledThreadPool创建线程池源码
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
/**
* corePoolSize : 核心线程的数量为自定义输入corePoolSize
* maximumPoolSize : 最大线程的数量为Integer.MAX_VALUE
* keepAliveTime : 0L
* unit : 纳秒
* workQueue : DelayedWorkQueue
**/
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}작업이 제출되면 corePoolSize가 사용자 정의 입력이고 코어 스레드가 생성됩니다. 먼저 코어 스레드가 가득 차서 결국에는 작업을 수행하기 위해 비코어 스레드가 생성됩니다. 비핵심 스레드는 사용 후 재활용됩니다. Integer.MAX_VALUE는 크기가 매우 크기 때문에 스레드를 무한히 생성할 수 있어 리소스가 제한되어 있을 경우 OOM 예외가 쉽게 발생할 수 있다고 생각할 수 있습니다. 사용된 DelayedWorkQueue는 예약된 작업과 주기적인 작업을 구현할 수 있기 때문입니다. ScheduledExecutorService는 사용할 수 있는 세 가지 방법을 제공합니다.

schedule: 지연 후 작업 실행 ScheduleAtFixedRate: 지정된 속도로 작업 실행 ScheduleWithFixedDelay: 지정된 지연으로 작업 실행 사용 사례:
public static void main(String[] args) {
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(1);
// executorService.schedule(new Runnable() {
// @Override
// public void run() {
// log.warn("schedule run");
// }
// //延迟3秒后执行
// }, 3, TimeUnit.SECONDS);
// executorService.shutdown();
// executorService.scheduleWithFixedDelay(new Runnable() {
// @Override
// public void run() {
// log.warn("scheduleWithFixedDelay run");
// }
// //延迟一秒后每隔3秒执行
// }, 1, 3, TimeUnit.SECONDS);
executorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
log.warn("schedule run");
}
//延迟一秒后每隔3秒执行
}, 1, 3, TimeUnit.SECONDS);
/**
* 定时器调度,不推荐使用,推荐ScheduledExecutorService调度
*/
// Timer timer = new Timer();
// timer.schedule(new TimerTask() {
// @Override
// public void run() {
// log.warn("timer run");
// }
// //从当前时间每隔5秒执行
// }, new Date(), 5 * 1000);
}요약
FixThreadPool 및 SingleThreadExecutor 허용되는 요청 대기열 길이는 Integer.MAX_VALUE이며, 이로 인해 많은 수의 요청이 누적되어 OOM 예외가 발생할 수 있습니다
CachedThreadPool 및 newScheduledThreadPool에서 생성할 수 있는 스레드 수는 Integer.MAX_VALUE이며, 이로 인해 많은 수의 스레드가 생성되어 OOM 예외가 발생할 수 있습니다.
이것이 Executor를 사용하여 스레드 풀을 생성하는 것을 금지하는 이유입니다. 하지만 ThreadPoolExecutor를 직접 생성하는 것이 좋습니다. 이유
스레드 풀 매개 변수 정의 방법
CPU 집약적: 스레드 풀의 크기는 CPU 수 + 1을 권장합니다. CPU 수를 얻을 수 있습니다. Runtime.availableProcessors 메소드에 따라 IO 집약적: CPU 수 * CPU 사용률 * ( 1 + 스레드 대기 시간/스레드 CPU 시간) 하이브리드 유형: 작업을 CPU 집약적 및 IO 집약적으로 나누어 사용 Blocking queue 조정: 제한된 대기열을 사용하는 것이 리소스 고갈을 방지하는 데 도움이 됩니다. 거부 전략: 기본값은 다음과 같습니다. 프로그램에서 직접 RejectedExecutionException을 발생시키는 AbortPolicy 거부 전략(시간 예외가 실행 중이기 때문에 강제 포착 없음), 이 처리 방법은 충분히 우아하지 않습니다. 거부 처리에는 다음 전략이 권장됩니다.
프로그램에서 RejectedExecutionException 예외를 포착하고 포착된 예외에서 작업을 처리합니다. 기본 거부 정책
의 경우 CallerRunsPolicy 거부 정책을 사용합니다. 이 정책은 실행을 호출하는 스레드(보통 메인 스레드)에 작업을 넘겨줍니다. 이때 기본 스레드는 어떤 작업도 제출할 수 없습니다. 일정 기간 동안 작업자 스레드가 진행 중인 작업을 처리하게 합니다. 이때 제출된 스레드는 TCP 대기열에 저장됩니다. TCP 대기열이 가득 차면 이는 클라이언트에 영향을 미치게 됩니다. 이는 거부 전략을 사용자 정의하려면 RejectedExecutionHandler 인터페이스만 구현하면 됩니다.
작업이 특별히 중요하지 않은 경우 DiscardPolicy 및 DiscardOldestPolicy 거부 정책을 사용하여 작업을 삭제하는 것도 가능합니다.
Executors의 정적 메서드를 사용하여 ThreadPoolExecutor 개체를 생성하는 경우 Semaphore를 사용할 수 있습니다. 작업 실행을 제한하고 OOM 예외를 방지하려면
위 내용은 Java 스레드 풀 실행자 사용 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
 PHP : 웹 개발의 핵심 언어
Apr 13, 2025 am 12:08 AM
PHP : 웹 개발의 핵심 언어
Apr 13, 2025 am 12:08 AM
PHP는 서버 측에서 널리 사용되는 스크립팅 언어이며 특히 웹 개발에 적합합니다. 1.PHP는 HTML을 포함하고 HTTP 요청 및 응답을 처리 할 수 있으며 다양한 데이터베이스를 지원할 수 있습니다. 2.PHP는 강력한 커뮤니티 지원 및 오픈 소스 리소스를 통해 동적 웹 컨텐츠, 프로세스 양식 데이터, 액세스 데이터베이스 등을 생성하는 데 사용됩니다. 3. PHP는 해석 된 언어이며, 실행 프로세스에는 어휘 분석, 문법 분석, 편집 및 실행이 포함됩니다. 4. PHP는 사용자 등록 시스템과 같은 고급 응용 프로그램을 위해 MySQL과 결합 할 수 있습니다. 5. PHP를 디버깅 할 때 error_reporting () 및 var_dump ()와 같은 함수를 사용할 수 있습니다. 6. 캐싱 메커니즘을 사용하여 PHP 코드를 최적화하고 데이터베이스 쿼리를 최적화하며 내장 기능을 사용하십시오. 7
 PHP vs. Python : 차이점 이해
Apr 11, 2025 am 12:15 AM
PHP vs. Python : 차이점 이해
Apr 11, 2025 am 12:15 AM
PHP와 Python은 각각 고유 한 장점이 있으며 선택은 프로젝트 요구 사항을 기반으로해야합니다. 1.PHP는 간단한 구문과 높은 실행 효율로 웹 개발에 적합합니다. 2. Python은 간결한 구문 및 풍부한 라이브러리를 갖춘 데이터 과학 및 기계 학습에 적합합니다.
 PHP 대 기타 언어 : 비교
Apr 13, 2025 am 12:19 AM
PHP 대 기타 언어 : 비교
Apr 13, 2025 am 12:19 AM
PHP는 특히 빠른 개발 및 동적 컨텐츠를 처리하는 데 웹 개발에 적합하지만 데이터 과학 및 엔터프라이즈 수준의 애플리케이션에는 적합하지 않습니다. Python과 비교할 때 PHP는 웹 개발에 더 많은 장점이 있지만 데이터 과학 분야에서는 Python만큼 좋지 않습니다. Java와 비교할 때 PHP는 엔터프라이즈 레벨 애플리케이션에서 더 나빠지지만 웹 개발에서는 더 유연합니다. JavaScript와 비교할 때 PHP는 백엔드 개발에서 더 간결하지만 프론트 엔드 개발에서는 JavaScript만큼 좋지 않습니다.
 PHP vs. Python : 핵심 기능 및 기능
Apr 13, 2025 am 12:16 AM
PHP vs. Python : 핵심 기능 및 기능
Apr 13, 2025 am 12:16 AM
PHP와 Python은 각각 고유 한 장점이 있으며 다양한 시나리오에 적합합니다. 1.PHP는 웹 개발에 적합하며 내장 웹 서버 및 풍부한 기능 라이브러리를 제공합니다. 2. Python은 간결한 구문과 강력한 표준 라이브러리가있는 데이터 과학 및 기계 학습에 적합합니다. 선택할 때 프로젝트 요구 사항에 따라 결정해야합니다.
 캡슐의 양을 찾기위한 Java 프로그램
Feb 07, 2025 am 11:37 AM
캡슐의 양을 찾기위한 Java 프로그램
Feb 07, 2025 am 11:37 AM
캡슐은 3 차원 기하학적 그림이며, 양쪽 끝에 실린더와 반구로 구성됩니다. 캡슐의 부피는 실린더의 부피와 양쪽 끝에 반구의 부피를 첨가하여 계산할 수 있습니다. 이 튜토리얼은 다른 방법을 사용하여 Java에서 주어진 캡슐의 부피를 계산하는 방법에 대해 논의합니다. 캡슐 볼륨 공식 캡슐 볼륨에 대한 공식은 다음과 같습니다. 캡슐 부피 = 원통형 볼륨 2 반구 볼륨 안에, R : 반구의 반경. H : 실린더의 높이 (반구 제외). 예 1 입력하다 반경 = 5 단위 높이 = 10 단위 산출 볼륨 = 1570.8 입방 단위 설명하다 공식을 사용하여 볼륨 계산 : 부피 = π × r2 × h (4
 PHP의 영향 : 웹 개발 및 그 이상
Apr 18, 2025 am 12:10 AM
PHP의 영향 : 웹 개발 및 그 이상
Apr 18, 2025 am 12:10 AM
phphassignificallyimpactedwebdevelopmentandextendsbeyondit
 PHP : 많은 웹 사이트의 기초
Apr 13, 2025 am 12:07 AM
PHP : 많은 웹 사이트의 기초
Apr 13, 2025 am 12:07 AM
PHP가 많은 웹 사이트에서 선호되는 기술 스택 인 이유에는 사용 편의성, 강력한 커뮤니티 지원 및 광범위한 사용이 포함됩니다. 1) 배우고 사용하기 쉽고 초보자에게 적합합니다. 2) 거대한 개발자 커뮤니티와 풍부한 자원이 있습니다. 3) WordPress, Drupal 및 기타 플랫폼에서 널리 사용됩니다. 4) 웹 서버와 밀접하게 통합하여 개발 배포를 단순화합니다.
