

Java HashSet에 순회 요소를 추가하는 방법

HashSet 클래스 다이어그램
HashSet 간단한 설명
1.HashSet은 Set 인터페이스HashSet 实现了 Set 接口
2.HashSet 底层实际上是由 HashMap 实现的
public HashSet() {
map = new HashMap<>();
}3.可以存放 null,但是只能有一个 null
4.HashSet 不保证元素是有序的(即不保证存放元素的顺序和取出元素的顺序一致),取决于 hash 后,再确定索引的结果
5.不能有重复的元素
HashSet 底层机制说明
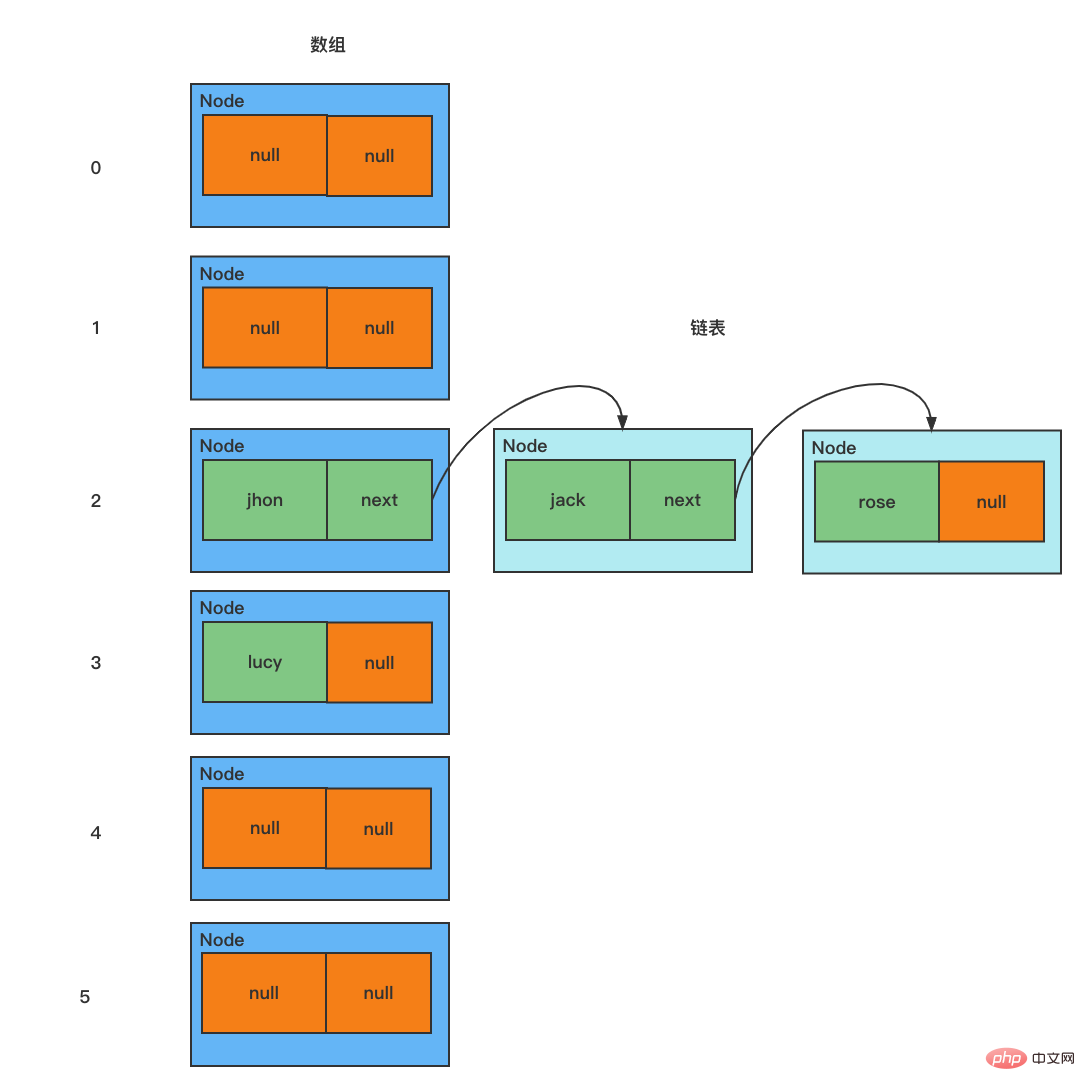
HashSet 底层是 HashMap,HashMap 底层是 数组 + 链表 + 红黑树
模拟数组+链表的结构
/**
* 模拟 HashSet 数组+链表的结构
*/
public class HashSetStructureMain {
public static void main(String[] args) {
// 模拟一个 HashSet(HashMap) 的底层结构
// 1. 创建一个数组,数组的类型为 Node[]
// 2. 有些地方直接把 Node[] 数组称为 表
Node[] table = new Node[16];
System.out.println(table);
// 3. 创建节点
Node john = new Node("john", null);
table[2] = jhon; // 把节点 john 放在数组索引为 2 的位置
Node jack = new Node("jack", null);
jhon.next = jack; // 将 jack 挂载到 jhon 的后面
Node rose = new Node("rose", null);
jack.next = rose; // 将 rose 挂载到 jack 的后面
Node lucy = new Node("lucy", null);
table[3] = lucy; // 将 lucy 放在数组索引为 3 的位置
System.out.println(table);
}
}
// 节点类 存储数据,可以指向下一个节点,从而形成链表
class Node{
Object item; // 存放数据
Node next; // 指向下一个节点
public Node(Object item, Node next){
this.item = item;
this.next = next;
}
}HashSet 添加元素底层机制
HashSet 添加元素的底层实现
1.HashSet 底层是 HashMap
2.当添加一个元素时,会先得到 待添加元素的 hash 值,然后将其转换成一个 索引值
3.查询存储数据表(Node 数组) table,看当前 待添加元素 所对应的 索引值 的位置是否已经存放了 其它元素
4.如果当前 索引值 所对应的的位置不存在 其它元素,就将当前 待添加元素 放到这个 索引值 所对应的的位置
5.如果当前 索引值 所对应的位置存在 其它元素,就调用 待添加元素.equals(已存在元素) 比较,结果为 true,则放弃添加;结果为 false,则将 待添加元素 放到 已存在元素 的后面(已存在元素.next = 待添加元素)
HashSet 扩容机制
1.HashSet 的底层是 HashMap,第一次添加元素时,table 数组扩容到 cap = 16,threshold(临界值) = cap * loadFactor(加载因子 0.75) = 12
2.如果 table 数组使用到了临界值 12,就会扩容到 cap * 2 = 32,新的临界值就是 32 * 0.75 = 24,以此类推
3.在 Java8 中,如果一条链表上的元素个数 到达 TREEIFY_THRESHOLD(默认是 8),并且 table 的大小 >= MIN_TREEIFY_CAPACITY(默认是 64),就会进行 树化(红黑树)
4.判断是否扩容是根据 ++size > threshold,即是否扩容,是根据 HashMap 所存的元素个数(size)是否超过临界值,而不是根据 table.length() 是否超过临界值
HashSet 添加元素源码
/**
* HashSet 源码分析
*/
public class HashSetSourceMain {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("java");
hashSet.add("php");
hashSet.add("java");
System.out.println("set = " + hashSet);
// 源码分析
// 1. 执行 HashSet()
/**
* public HashSet() { // HashSet 底层是 HashMap
* map = new HashMap<>();
* }
*/
// 2. 执行 add()
/**
* public boolean add(E e) { // e == "java"
* // HashSet 的 add() 方法其实是调用 HashMap 的 put()方法
* return map.put(e, PRESENT)==null; // (static) PRESENT = new Object(); 用于占位
* }
*/
// 3. 执行 put()
// hash(key) 得到 key(待存元素) 对应的hash值,并不等于 hashcode()
// 算法是 h = key.hashCode()) ^ (h >>> 16
/**
* public V put(K key, V value) {
* return putVal(hash(key), key, value, false, true);
* }
*/
// 4. 执行 putVal()
// 定义的辅助变量:Node<K,V>[] tab; Node<K,V> p; int n, i;
// table 是 HashMap 的一个属性,初始化为 null;transient Node<K,V>[] table;
// resize() 方法,为 table 数组指定容量
// p = tab[i = (n - 1) & hash] 计算 key的hash值所对应的 table 中的索引位置,将索引位置对应的 Node 赋给 p
/**
* final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
* boolean evict) {
* Node<K,V>[] tab; Node<K,V> p; int n, i; // 辅助变量
* // table 就是 HashMap 的一个属性,类型是 Node[]
* // if 语句表示如果当前 table 是 null,或者 table.length == 0
* // 就是 table 第一次扩容,容量为 16
* if ((tab = table) == null || (n = tab.length) == 0)
* n = (tab = resize()).length;
* // 1. 根据 key,得到 hash 去计算key应该存放到 table 的哪个索引位置
* // 2. 并且把这个位置的索引值赋给 i;索引值对应的元素,赋给 p
* // 3. 判断 p 是否为 null
* // 3.1 如果 p 为 null,表示还没有存放过元素,就创建一个Node(key="java",value=PRESENT),并把这个元素放到 i 的索引位置
* // tab[i] = newNode(hash, key, value, null);
* if ((p = tab[i = (n - 1) & hash]) == null)
* tab[i] = newNode(hash, key, value, null);
* else {
* Node<K,V> e; K k; // 辅助变量
* // 如果当前索引位置对应的链表的第一个元素和待添加的元素的 hash值一样
* // 并且满足下面两个条件之一:
* // 1. 待添加的 key 与 p 所指向的 Node 节点的key 是同一个对象
* // 2. 待添加的 key.equals(p 指向的 Node 节点的 key) == true
* // 就认为当前待添加的元素是重复元素,添加失败
* if (p.hash == hash &&
* ((k = p.key) == key || (key != null && key.equals(k))))
* e = p;
* // 判断 当前 p 是不是一颗红黑树
* // 如果是一颗红黑树,就调用 putTreeVal,来进行添加
* else if (p instanceof TreeNode)
* e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
* else {
* // 如果 当前索引位置已经形成一个 链表,就使用 for 循环比较
* // 将待添加元素依次和链表上的每个元素进行比较
* // 1. 比较过程中如果出现待添加元素和链表中的元素有相同的,比较结束,出现重复元素,添加失败
* // 2. 如果比较到链表最后一个元素,链表中都没出现与待添加元素相同的,就把当前待添加元素放到该链表最后的位置
* // 注意:在把待添加元素添加到链表后,立即判断 该链表是否已经到达 8 个节点
* // 如果到达,就调用 treeifyBin() 对当前这个链表进行数化(转成红黑树)
* // 注意:在转成红黑树前,还要进行判断
* // if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
* // resize();
* // 如果上面条件成立,先对 table 进行扩容
* // 如果上面条件不成立,才转成红黑树
* for (int binCount = 0; ; ++binCount) {
* if ((e = p.next) == null) {
* p.next = newNode(hash, key, value, null);
* if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
* treeifyBin(tab, hash);
* break;
* }
* if (e.hash == hash &&
* ((k = e.key) == key || (key != null && key.equals(k))))
* break;
* p = e;
* }
* }
* // e 不为 null ,说明添加失败
* if (e != null) { // existing mapping for key
* V oldValue = e.value;
* if (!onlyIfAbsent || oldValue == null)
* e.value = value;
* afterNodeAccess(e);
* return oldValue;
* }
* }
* ++modCount;
* // 扩容:说明判断 table 是否扩容不是看 table 的length
* // 而是看 整个 HashMap 的 size(即已存元素个数)
* if (++size > threshold)
* resize();
* afterNodeInsertion(evict);
* return null;
* }
*/
}
}HashSet 遍历元素底层机制
HashSet 遍历元素底层机制
1.HashSet 的底层是 HashMap,HashSet 的迭代器也是借由 HashMap 来实现的
2.HashSet.iterator() 实际上是去调用 HashMap 的 KeySet().iterator()
public Iterator<E> iterator() {
return map.keySet().iterator();
}3.KeySet() 方法返回一个 KeySet 对象,而 KeySet 是 HashMap 的一个内部类
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new KeySet();
keySet = ks;
}
return ks;
}4.KeySet().iterator() 方法返回一个 KeyIterator 对象,KeyIterator 是 HashMap 的一个内部类
public final Iterator<K> iterator() { return new KeyIterator(); }5.KeyIterator 继承了 HashIterator(HashMap的内部类) 类,并实现了 Iterator 接口,即 KeyIterator、HashIterator 才是真正实现 迭代器 的类
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}6.当执行完 Iterator iterator = HashSet.iterator; 之后,此时的 iterator 对象中已经存储了一个元素节点
怎么做到的?
回到第 4 步,
2.KeySet().iterator()方法返回一个KeyIteratorHashSet를 구현합니다. 하단 레이어 실제로는HashMap🎜🎜3에 의해 구현됩니다./** * Node<K,V> next; // next entry to return * Node<K,V> current; // current entry * int expectedModCount; // for fast-fail * int index; // current slot * HashIterator() { * expectedModCount = modCount; * Node<K,V>[] t = table; * current = next = null; * index = 0; * if (t != null && size > 0) { // advance to first entry * do {} while (index < t.length && (next = t[index++]) == null); * } * } */로그인 후 복사로그인 후 복사null을 저장할 수 있지만null🎜🎜4은 하나만 있을 수 있습니다. code>HashSet< /code> 는 요소가 순서대로 되어 있는지 보장하지 않습니다(즉, 요소가 저장된 순서와 요소를 꺼내는 순서가 동일하다는 것을 보장하지 않습니다). 인덱스는hash🎜🎜5 이후에 결정됩니다. 중복이 있을 수 없습니다. 요소 🎜🎜HashSet 기본 메커니즘 설명🎜🎜HashSet맨 아래 레이어는HashMap</code입니다. >, <code>HashMap의 하위 레이어는 배열 + 연결 목록 + 레드-블랙 트리🎜배열 + 연결 목록의 구조 시뮬레이션
🎜< img src="https://img.php.cn/upload/article/000/887/227/168265824976128.png" alt=" Java HashSet에 순회 요소를 추가하는 방법" />🎜🎜HashSet의 기본 메커니즘 요소 추가🎜public final boolean hasNext() { return next != null; }로그인 후 복사로그인 후 복사요소를 추가하는 HashSet의 기본 구현
🎜1.HashSet맨 아래 레이어는HashMap</ code>🎜🎜2입니다. 먼저 추가할 요소의 <strong>해시값을 가져온 다음 이를 인덱스 값으로 변환합니다. >🎜🎜3 저장소 데이터 테이블(노드 배열)table을 사용하여 현재 추가할 요소에 해당하는 색인 값의 위치가 다른 요소를 저장했는지 확인하세요🎜 🎜4. 현재 인덱스 값에 해당하는 위치에 다른 요소가 없으면 현재 대기 요소를 해당 위치에 추가합니다. 인덱스 값 🎜🎜5. 현재 인덱스 값 Strong>에 해당하는 위치에 다른 요소가 있는 경우 Element를 호출합니다. 추가됩니다.equals(기존 요소)를 비교하여 결과가true이면 추가를 포기하고 결과는false입니다. 그런 다음 기존 요소 뒤에 >추가할 요소 (기존 요소.next = 추가할 요소)🎜HashSet 확장 메커니즘
🎜1HashSet의 맨 아래 레이어는HashMap입니다. 요소가 처음 추가되면table배열이cap로 확장됩니다. = 16,threshold(임계값) = cap * loadFactor (로딩 인자 0.75) = 12🎜🎜2table배열이 임계값 12를 사용하는 경우 ,cap * 2 = 32로 확장되고 새로운 임계값은32 * 0.75 = 24등입니다🎜🎜3. 연결 목록 도달TREEIFY_THRESHOLD(기본값은 8) 요소 수 및테이블>=MIN_TREEIFY_CAPACITY</code 크기 > (기본값은 64) <strong>Tree(red-black tree)</strong>🎜🎜4입니다. 확장 여부는 <code>++size > 즉, 확장 여부는 <code>HashMap에 저장된 요소의 개수(size)가 임계값을 초과하는지 여부에 따라 결정되며,table.length()에 따라 결정되지 않습니다.가 임계값을 초과합니다🎜HashSet은 요소 소스 코드를 추가합니다
🎜HashSet는 요소의 기본 메커니즘을 통과합니다🎜/** * HashSet 源码分析 */ public class HashSetSourceMain { public static void main(String[] args) { HashSet hashSet = new HashSet(); hashSet.add("java"); hashSet.add("php"); hashSet.add("java"); System.out.println("set = " + hashSet); // HashSet 迭代器实现原理 // HashSet 底层是 HashMap,HashMap 底层是 数组 + 链表 + 红黑树 // HashSet 本身没有实现迭代器,而是借由 HashMap 来实现的 // 1. hashSet.iterator() 实际上是去调用 HashMap 的 keySet().iterator() /** * public Iteratoriterator() { * return map.keySet().iterator(); * } */ // 2. KeySet() 方法返回一个 KeySet 对象,而 KeySet 是 HashMap 的一个内部类 /** * public Set keySet() { * Set ks = keySet; * if (ks == null) { * ks = new KeySet(); * keySet = ks; * } * return ks; * } */ // 3. KeySet().iterator() 方法返回一个 KeyIterator 对象,KeyIterator 是 HashMap的一个内部类 /** * public final Iterator<K> iterator() { return new KeyIterator(); } */ // 4. KeyIterator 继承了 HashIterator(HashMap的内部类) 类,并实现了 Iterator 接口 // 即 KeyIterator、HashIterator 才是真正实现 迭代器的类 /** * final class KeyIterator extends HashIterator * implements Iterator { * public final K next() { return nextNode().key; } * } */ // 5. 当执行完 Iterator iterator = hashSet.iterator(); 后 // 此时的 iterator 对象中已经存储了一个元素节点 // 怎么做到的? // 回到第 3 步,KeySet().iterator() 方法返回一个 KeyIterator 对象 // new KeyIterator() 调用 KeyIterator 的无参构造器 // 在这之前,会先调用 KeyIterator 父类 HashIterator 的无参构造器 // 因此分析 HashIterator 的无参构造器就知道发生了什么 /** * Node 로그인 후 복사로그인 후 복사HashSet은 요소의 기본 메커니즘을 통과합니다
🎜1.HashSet의 메커니즘은HashMap이고HashSet의 반복자는HashMap🎜🎜2에 의해 구현됩니다. HashSet.iterator()는 실제로HashMap의KeySet().iterator()🎜rrreee🎜3.KeySet()를 호출합니다. 메소드는KeySet객체를 반환하고KeySet는HashMap🎜rrreee🎜4의 내부 클래스입니다. ) 메소드는KeyIterator객체를 반환하고,KeyIterator는HashMap🎜rrreee🎜5.KeyIterator</의 내부 클래스입니다. code>는 <code>HashIterator(HashMap의 내부 클래스) 클래스를 상속하고Iterator인터페이스, 즉KeyIterator</code를 구현합니다. > 및 <code>HashIterator는 Iterator의 클래스🎜rrreee🎜6의 실제 구현입니다.Iterator iterator = HashSet.iterator;를 실행한 후 요소는 이번에는iterator객체에 저장되었습니다. Node 🎜- 🎜어떻게 할까요? 🎜
- 🎜4단계로 돌아가서
KeySet().iterator()메서드는KeyIterator객체를 반환합니다🎜 new KeyIterator()调用KeyIterator的无参构造器在这之前,会先调用其父类
HashIterator的无参构造器因此,分析
HashIterator的无参构造器就知道发生了什么
/** * Node<K,V> next; // next entry to return * Node<K,V> current; // current entry * int expectedModCount; // for fast-fail * int index; // current slot * HashIterator() { * expectedModCount = modCount; * Node<K,V>[] t = table; * current = next = null; * index = 0; * if (t != null && size > 0) { // advance to first entry * do {} while (index < t.length && (next = t[index++]) == null); * } * } */로그인 후 복사로그인 후 복사next、current、index都是HashIterator的属性Node<K,V>[] t = table;先把Node数组talbe赋给tcurrent = next = null;current、next都置为nullindex = 0;index置为0do {} while (index < t.length && (next = t[index++]) == null);这个do-while会在table中遍历Node结点一旦
(next = t[index++]) == null不成立 时,就说明找到了一个table中的Node结点将这个节点赋给
next,并退出当前do-while循环此时
Iterator iterator = HashSet.iterator;就执行完了当前
iterator的运行类型其实是HashIterator,而HashIterator的next中存储着从table中遍历出来的一个Node结点
7.执行
iterator.hasNext此时的
next存储着一个Node,所以并不为null,返回truepublic final boolean hasNext() { return next != null; }로그인 후 복사로그인 후 복사8.执行
iterator.next()I.
Node<K,V> e = next;把当前存储着Node结点的next赋值给了eII.
(next = (current = e).next) == null判断当前结点的下一个结点是否为null(a). 如果当前结点的下一个结点为
null,就执行do {} while (index < t.length && (next = t[index++]) == null);,在table数组中遍历,寻找table数组中的下一个Node并赋值给next(b). 如果当前结点的下一个结点不为
null,就将当前结点的下一个结点赋值给next,并且此刻不会去table数组中遍历下一个Node结点
III.将找到的结点
e返回IV.之后每次执行
iterator.next()都像 (a)、(b) 那样去判断遍历,直到遍历完成HashSet 遍历元素源码
/** * HashSet 源码分析 */ public class HashSetSourceMain { public static void main(String[] args) { HashSet hashSet = new HashSet(); hashSet.add("java"); hashSet.add("php"); hashSet.add("java"); System.out.println("set = " + hashSet); // HashSet 迭代器实现原理 // HashSet 底层是 HashMap,HashMap 底层是 数组 + 链表 + 红黑树 // HashSet 本身没有实现迭代器,而是借由 HashMap 来实现的 // 1. hashSet.iterator() 实际上是去调用 HashMap 的 keySet().iterator() /** * public Iteratoriterator() { * return map.keySet().iterator(); * } */ // 2. KeySet() 方法返回一个 KeySet 对象,而 KeySet 是 HashMap 的一个内部类 /** * public Set keySet() { * Set ks = keySet; * if (ks == null) { * ks = new KeySet(); * keySet = ks; * } * return ks; * } */ // 3. KeySet().iterator() 方法返回一个 KeyIterator 对象,KeyIterator 是 HashMap的一个内部类 /** * public final Iterator<K> iterator() { return new KeyIterator(); } */ // 4. KeyIterator 继承了 HashIterator(HashMap的内部类) 类,并实现了 Iterator 接口 // 即 KeyIterator、HashIterator 才是真正实现 迭代器的类 /** * final class KeyIterator extends HashIterator * implements Iterator { * public final K next() { return nextNode().key; } * } */ // 5. 当执行完 Iterator iterator = hashSet.iterator(); 后 // 此时的 iterator 对象中已经存储了一个元素节点 // 怎么做到的? // 回到第 3 步,KeySet().iterator() 方法返回一个 KeyIterator 对象 // new KeyIterator() 调用 KeyIterator 的无参构造器 // 在这之前,会先调用 KeyIterator 父类 HashIterator 的无参构造器 // 因此分析 HashIterator 的无参构造器就知道发生了什么 /** * Node 로그인 후 복사로그인 후 복사위 내용은 Java HashSet에 순회 요소를 추가하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7489
7489
 15
1377
52
77
11
52
19
19
41
15
1377
52
77
11
52
19
19
41


 Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기 안내. 여기서는 예제를 통해 Java의 함수와 예제를 통해 두 가지 다른 생성기에 대해 설명합니다.
 자바의 웨카
Aug 30, 2024 pm 04:28 PM
자바의 웨카
Aug 30, 2024 pm 04:28 PM
Java의 Weka 가이드. 여기에서는 소개, weka java 사용 방법, 플랫폼 유형 및 장점을 예제와 함께 설명합니다.
 Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 Smith Number 가이드. 여기서는 정의, Java에서 스미스 번호를 확인하는 방법에 대해 논의합니다. 코드 구현의 예.
 Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
이 기사에서는 가장 많이 묻는 Java Spring 면접 질문과 자세한 답변을 보관했습니다. 그래야 면접에 합격할 수 있습니다.
 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
 Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 TimeStamp to Date 안내. 여기서는 소개와 예제와 함께 Java에서 타임스탬프를 날짜로 변환하는 방법에 대해서도 설명합니다.
 미래를 창조하세요: 완전 초보자를 위한 Java 프로그래밍
Oct 13, 2024 pm 01:32 PM
미래를 창조하세요: 완전 초보자를 위한 Java 프로그래밍
Oct 13, 2024 pm 01:32 PM
Java는 초보자와 숙련된 개발자 모두가 배울 수 있는 인기 있는 프로그래밍 언어입니다. 이 튜토리얼은 기본 개념부터 시작하여 고급 주제를 통해 진행됩니다. Java Development Kit를 설치한 후 간단한 "Hello, World!" 프로그램을 작성하여 프로그래밍을 연습할 수 있습니다. 코드를 이해한 후 명령 프롬프트를 사용하여 프로그램을 컴파일하고 실행하면 "Hello, World!"가 콘솔에 출력됩니다. Java를 배우면 프로그래밍 여정이 시작되고, 숙달이 깊어짐에 따라 더 복잡한 애플리케이션을 만들 수 있습니다.
