

Java 다중 스레드 동시 프로그래밍은 데이터 처리 효율성을 얼마나 향상시킵니까?

작업 시나리오에서 우리는 호스트의 IP 주소를 기반으로 다른 모델의 관련 정보를 업데이트해야 하는 요구 사항에 직면했습니다. 요구 사항은 매우 간단하며 일반적인 데이터베이스 연결 쿼리 및 업데이트 작업만 포함됩니다. 그러나 코딩 구현 과정에서 호스트 수가 많아 쿼리 및 업데이트를 반복하는 데 시간이 오래 걸리는 것으로 나타났습니다. 인터페이스를 한 번 호출하는 데 약 30~40초가 소요됩니다. 작업을 완료하는 데 걸리는 최소 시간입니다.
따라서 인터페이스 메서드의 실행 시간을 효과적으로 단축하려면 멀티 스레드 동시 프로그래밍 방법을 사용하고, 멀티 코어 프로세서의 병렬 실행 기능을 활용하고, 데이터를 비동기식으로 처리하여 실행 시간을 크게 단축하는 것이 좋습니다. 실행 효율성을 향상시킵니다.
여기에는 고정된 수의 스레드 FixedThreadPool가 있는 재사용 가능한 스레드 풀이 사용되며, CountDownLatch 동시성 도구 클래스에서 제공하는 동시 프로세스 제어 도구를 함께 사용하여 다중 스레드 동시 프로그래밍 프로세스 일반 작업: FixedThreadPool,并使用 CountDownLatch 并发工具类提供的并发流程控制工具作为配合使用,保证多线程并发编程过程中的正常运行:
首先,通过
Runtime.getRuntime().availableProcessors()方法获取运行机器的 CPU 线程数,用于后续设置固定线程池的线程数量。其次,判断任务的特性,如果为计算密集型任务则设置线程数为
CPU 线程数+1,如果为 IO 密集型任务则设置线程数为2 * CPU 线程数,由于在方法中需要与数据库进行频繁的交互,因此属于 IO 密集型任务。之后,对数据进行分组切割,每个线程处理一个分组的数据,分组的组数与线程数保持一致,并且还要创建计数器对象
CountDownLatch,调用构造函数,初始化参数值为线程数个数,保证主线程等待所有子线程运行结束后,再进行后续的操作。然后,调用
executorService.execute()方法,重写run方法编写业务逻辑与数据处理代码,执行完当前线程后记得将计数器减1操作。最后,当所有子线程执行完成后,关闭线程池。
在省略工作场景中的业务逻辑代码后,通用的处理方法示例如下所示:
public ResponseData updateHostDept() {
// ...
List<Map> hostMapList = mongoTemplate.find(query, Map.class, "host");
// split the hostMapList for the following multi-threads task
// return the number of logical CPUs
int processorsNum = Runtime.getRuntime().availableProcessors();
// set the threadNum as 2*(the number of logical CPUs) for handling IO Tasks,
// if Computing Tasks set the threadNum as (the number of logical CPUs) + 1
int threadNum = processorsNum * 2;
// the number of each group data
int eachGroupNum = hostMapList.size() / threadNum;
List<List<Map>> groupList = new ArrayList<>();
for (int i = 0; i < threadNum; i++) {
int start = i * eachGroupNum;
if (i == threadNum - 1) {
int end = mapList.size();
groupList.add(hostMapList.subList(start, end));
} else {
int end = (i+1) * eachGroupNum;
groupList.add(hostMapList.subList(start, end));
}
}
// update data by using multi-threads asynchronously
ExecutorService executorService = Executors.newFixedThreadPool(threadNum/2);
CountDownLatch countDownLatch = new CountDownLatch(threadNum);
for (List<Map> group : groupList) {
executorService.execute(()->{
try {
for (Map map : group) {
// update the data in mongodb
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// let counter minus one
countDownLatch.countDown();
}
});
}
try {
// main thread donnot execute until all child threads finish
countDownLatch.await();
} catch (Exception e) {
e.printStackTrace();
}
// remember to shutdown the threadPool
executorService.shutdown();
return ResponseData.success();
}那么在使用多线程异步更新的策略后,从当初调用接口所需的大概时间为 30-40 min 下降到了 8-10 min,大大提高了执行效率。
需要注意的是,这里使用的
newFixedThreadPool创建线程池,它有一个缺陷就是,它的阻塞队列默认是一个无界队列,默认值为Integer.MAX_VALUE极有可能会造成 OOM 问题。因此,一般可以使用ThreadPoolExecutor
- First,
Runtime.getRuntime().availableProcessors( )메서드 실행 중인 시스템의 CPU 스레드 수는 이후에 고정 스레드 풀의 스레드 수를 설정하는 데 사용됩니다.
두 번째로 계산 집약적인 작업인 경우 스레드 수를 CPU 스레드 수 + 1</strong>로 설정합니다. code>인 경우 집약적인 작업의 경우 스레드 수를 <code>2 * CPU 스레드 수로 설정합니다. 이 메서드는 데이터베이스와 자주 상호 작용해야 하므로 IO 집약적인 작업입니다.
그 후 데이터를 그룹화하고 잘라냅니다. 각 스레드는 그룹화된 하나의 데이터를 처리하며, 그룹화된 그룹 수는 스레드 수와 일치하며 카운터 개체는 다음과 같습니다. 또한 < code>CountDownLatch를 생성하고, 생성자를 호출하고, 매개변수 값을 스레드 수로 초기화하고, 후속 작업을 수행하기 전에 기본 스레드가 모든 하위 스레드의 실행이 완료될 때까지 기다리도록 합니다.
그런 다음 executorService.execute() 메서드를 호출하고 run 메서드를 다시 작성하여 비즈니스 논리와 데이터 처리 코드, 현재 스레드를 실행한 후 카운터를 1씩 감소시키는 것을 기억하십시오. 마지막으로 모든 하위 스레드의 실행이 완료되면 스레드 풀을 닫습니다. 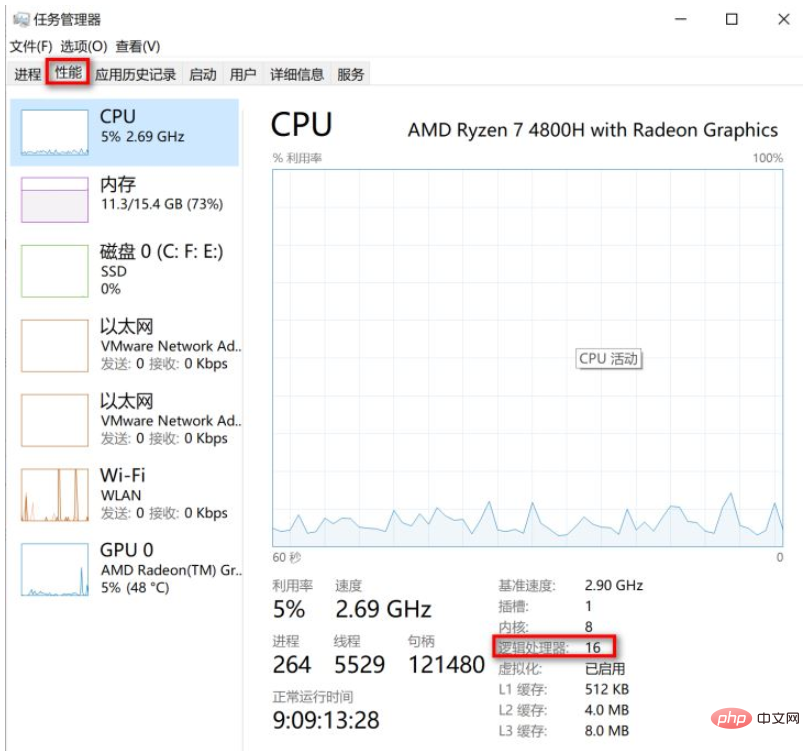
작업 시나리오에서 비즈니스 로직 코드를 생략한 후 일반적인 처리 방법 예는 다음과 같습니다.
public ResponseData updateHostDept() {
// ...
List<Map> hostMapList = mongoTemplate.find(query, Map.class, "host");
// split the hostMapList for the following multi-threads task
// return the number of logical CPUs
int processorsNum = Runtime.getRuntime().availableProcessors();
// set the threadNum as 2*(the number of logical CPUs) for handling IO Tasks,
// if Computing Tasks set the threadNum as (the number of logical CPUs) + 1
int threadNum = processorsNum * 2;
// the number of each group data
int eachGroupNum = hostMapList.size() / threadNum;
List<List<Map>> groupList = new ArrayList<>();
for (int i = 0; i < threadNum; i++) {
int start = i * eachGroupNum;
if (i == threadNum - 1) {
int end = mapList.size();
groupList.add(hostMapList.subList(start, end));
} else {
int end = (i+1) * eachGroupNum;
groupList.add(hostMapList.subList(start, end));
}
}
// update data by using multi-threads asynchronously
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 8, 30L, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100));
CountDownLatch countDownLatch = new CountDownLatch(threadNum);
for (List<Map> group : groupList) {
executor.execute(()->{
try {
for (Map map : group) {
// update the data in mongodb
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// let counter minus one
countDownLatch.countDown();
}
});
}
try {
// main thread donnot execute until all child threads finish
countDownLatch.await();
} catch (Exception e) {
e.printStackTrace();
}
// remember to shutdown the threadPool
executor.shutdown();
return ResponseData.success();
}30~40분에서 8~10분으로 단축되어 실행 효율성이 크게 향상되었습니다. 🎜🎜여기서 스레드 풀을 생성하기 위해 사용된newFixedThreadPool에는 차단 대기열이 기본적으로 무제한 대기열이고 기본값이Integer라는 결함이 있다는 점에 유의해야 합니다. MAX_VALUEOOM 문제가 발생할 가능성이 매우 높습니다. 따라서 일반적으로ThreadPoolExecutor를 사용하여 스레드 풀을 생성할 수 있으며, 대기 대기열의 스레드 수를 지정하여 OOM 문제를 방지할 수 있습니다. 🎜🎜rrreee🎜위 코드에서 코어 스레드 수는 5개, 최대 스레드 수는 8개입니다. 큰 값으로 설정하면 스레드 간 컨텍스트 전환이 잦아지므로 크게 설정하지 않았습니다. 소모 시간도 늘어나지만 멀티스레딩의 장점을 극대화할 수는 없습니다. 적절한 매개변수를 선택하는 방법은 기계의 매개변수와 작업 유형에 따라 결정되어야 합니다. 🎜🎜마지막으로, 비코딩 방법을 통해 머신의 CPU 스레드 수를 얻으려는 경우에도 매우 간단합니다. Windows 시스템에서는 작업 관리자를 통해 CPU 스레드 수를 확인하고 "성능"을 선택하면 됩니다. ", 아래 그림과 같이 표시: 🎜🎜🎜🎜🎜위 그림에서 볼 수 있듯이 내 컴퓨터의 코어는 8개의 CPU이지만 하이퍼스레딩 기술을 통해 물리적 CPU 코어를 두 개의 논리적 코어로 시뮬레이션할 수 있습니다. CPU 스레드이므로 내 컴퓨터는 8 코어 16 스레드를 지원합니다. 🎜
위 내용은 Java 다중 스레드 동시 프로그래밍은 데이터 처리 효율성을 얼마나 향상시킵니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7319
7319
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29



 Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기 안내. 여기서는 예제를 통해 Java의 함수와 예제를 통해 두 가지 다른 생성기에 대해 설명합니다.
 자바의 웨카
Aug 30, 2024 pm 04:28 PM
자바의 웨카
Aug 30, 2024 pm 04:28 PM
Java의 Weka 가이드. 여기에서는 소개, weka java 사용 방법, 플랫폼 유형 및 장점을 예제와 함께 설명합니다.
 자바의 암스트롱 번호
Aug 30, 2024 pm 04:26 PM
자바의 암스트롱 번호
Aug 30, 2024 pm 04:26 PM
자바의 암스트롱 번호 안내 여기에서는 일부 코드와 함께 Java의 Armstrong 번호에 대한 소개를 논의합니다.
 Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 Smith Number 가이드. 여기서는 정의, Java에서 스미스 번호를 확인하는 방법에 대해 논의합니다. 코드 구현의 예.
 Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
이 기사에서는 가장 많이 묻는 Java Spring 면접 질문과 자세한 답변을 보관했습니다. 그래야 면접에 합격할 수 있습니다.
 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
