

Java가 문자 스트림을 사용하여 텍스트가 아닌 바이너리 파일을 읽을 수 없는 이유는 무엇입니까?

파일 읽기
Java의 IO 스트림 부분을 처음 배웠을 때 책에서는 그림, 비디오 등 텍스트가 아닌 바이너리 파일을 읽는 데 바이트 스트림만 사용할 수 있고 문자 스트림은 사용할 수 없다고 했습니다. 손상될 수 있습니다. 그래서 나는 이것을 항상 기억하고 있었지만 왜 그것을 사용할 수 없는지 항상 의문이었습니다. 오늘 이 문제에 대해 다시 한번 생각해 보았는데, 한번에 해결하는 게 낫지 않을까 싶습니다.
먼저 이미지 복사에 대한 코드 예제를 살펴보겠습니다. 참고: 내 컴퓨터에는 D:/DB 경로가 있습니다. DB 폴더가 없으면 새로 만들어야 합니다.
package dragon;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.file.Path;
import java.nio.file.Paths;
public class ReadImage {
public static void main(String[] args) throws IOException {
String imgPath = "D:/DB/husky/kkk.jpeg";
String byteImgCopyPath = "D:/DB/husky/byteCopykkk.jpeg";
String charImgCopyPath = "D:/DB/husky/charCopykkk.jpeg";
Path srcPath = Paths.get(imgPath);
Path desPath2 = Paths.get(byteImgCopyPath);
Path desPath3 = Paths.get(charImgCopyPath);
byteRead(srcPath.toFile(), desPath2.toFile());
System.out.println("字节复制执行成功!");
characterRead(srcPath.toFile(), desPath3.toFile());
System.out.println("字符复制执行成功!");
}
static void byteRead(File src, File des) throws IOException {
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream(src));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(des))) {
int hasRead = 0;
byte[] b = new byte[1024];
while ((hasRead = bis.read(b)) != -1) {
bos.write(b, 0, hasRead);
}
}
}
static void characterRead(File src, File des) throws IOException {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(src), "UTF-8"));
BufferedWriter writer = new BufferedWriter(new FileWriter(des))) {
int hasRead = 0;
char[] c = new char[1024];
while ((hasRead = reader.read(c)) != -1) {
writer.write(c, 0, hasRead);
}
}
}
}실행 결과: 이미지와 같은 바이너리 파일은 문자 스트림을 사용하여 읽을 수 없으며 바이트 스트림을 사용해야 함을 알 수 있습니다.

그림 크기 변경: 문자 스트림을 사용하면 그림 크기가 변경되는 것을 볼 수 있지만 바이트 스트림을 사용하면 변경되지 않습니다.

이게 왜죠?
위의 예를 통해 문자 스트림을 사용하여 파일을 복사하는 것은 실제로 불가능하다는 것을 알 수 있으며, 문자 스트림을 사용하여 파일을 복사한 후에는 파일 크기도 변경되므로 논의할 제목이 됩니다. 오늘.
먼저 생각해 봅시다. 왜 텍스트 파일을 열 때 텍스트가 표시될 수 있나요? 텍스트 파일이건 텍스트가 아닌 파일이건 컴퓨터에서 처리되는 파일은 결국 컴퓨터 내부에 바이너리 형식으로 저장된다는 사실은 우리 모두 알고 있습니다.
텍스트 파일을 열려면 텍스트 편집기의 16진수 모드를 사용하세요.
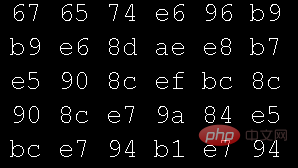
위 프로그램에서 사용하는 그림 파일을 열려면 편집기의 16진수 모드를 사용하세요.
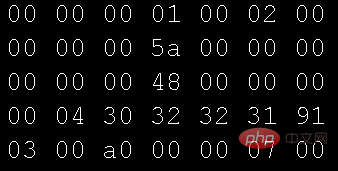
비교하세요. 두 그림 텍스트의 데이터에는 차이가 없어야 하는데 왜 텍스트 데이터가 표시될 수 있습니까? 이것은 매우 기본적인 질문입니다. 대학의 기본 과정은 모두 이 측면을 다루고 있습니다 - 문자 인코딩 테이블. 처음 C언어를 배웠고, 가장 먼저 접한 코딩 테이블은 ASCII(American Standard Code for Information Interchange)였고, 나중에 Java를 배우면서 유니코드(Unicode)와 잘 어울리는 이름이었습니다. 현재 가장 일반적으로 사용되는 것은 유니코드의 가변 길이 문자 인코딩인 UTF-8입니다.)
참고: UTF-8을 사용하는 것도 BOM(Byte Order Mark)의 두 가지 형식으로 나뉩니다. ) 및 , 없이 혼합 사용하면 오류가 발생할 수 있습니다.

문자 인코딩 테이블의 역할은 인코딩에 반영됩니다. 백과사전 인용:
모니터에 보이는 텍스트, 그림 및 기타 정보는 실제로 컴퓨터에서 보는 것과 다릅니다. 모든 것을 알고 있습니다. 정보는 하드 드라이브에 저장되어 있으며, 분해하면 내부에는 아무것도 보이지 않고 플래터 몇 개만 보입니다. 현미경을 사용하여 원판을 확대해 보면 원판의 표면이 고르지 못한 것을 볼 수 있습니다. 볼록한 부분은 자화되어 있고, 오목한 부분은 자화되어 있지 않습니다. 볼록한 부분은 숫자 1을 나타내고, 오목한 부분은 자성을 나타냅니다. 숫자 0. 하드 디스크는 0과 1만 사용하여 모든 텍스트, 그림 및 기타 정보를 나타낼 수 있습니다. 그렇다면 문자 "A"는 하드 드라이브에 어떻게 저장되어 있습니까? 어쩌면 Xiao Zhang의 컴퓨터는 문자 "A"를 1100001로 저장하고 Xiao Wang의 컴퓨터는 문자 "A"를 11000010으로 저장합니다. 이런 식으로 두 당사자가 정보를 교환할 때 오해를 받게 될 것입니다. 예를 들어 Xiao Zhang은 Xiao Wang에게 1100001을 보냈습니다. Xiao Wang은 1100001이 문자 "A"라고 생각하지 않았지만 아마도 문자 "X"라고 생각했을 것입니다. 따라서 Xiao Wang은 하드 디스크에 저장된 1100001에 액세스했습니다. , 화면에 문자 "X"가 표시됩니다. 즉, Xiao Zhang과 Xiao Wang은 서로 다른 코딩 테이블을 사용했습니다.
그래서 문자 인코딩 테이블은 이진수와 문자의 일대일 매핑입니다. 예를 들어 65(숫자)는 A를 나타내므로 다음 코드는 화면에 A를 출력합니다.
char c = 65; System.out.println(c);
루프를 사용하여 테스트해 보겠습니다.
char c = 0;
for (int i = 9999; i < 10009; i++) {
c = (char) i;
System.out.print(c+" ");
}테스트 결과: (물론 이는 현재 문자 인코딩 테이블에 따라 다릅니다. ASCII를 사용하면 흥미로울 것입니다.)
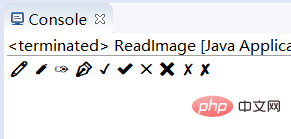
这样就解释了前面那个问题(为什么文本文件打开可以显示文字?),我们之所以可以看见文本文件的字符是因为计算机按照我们文件的编码(ASCII、UTF-8或者GBK等),从字符编码表中找出来对应的字符。 所以,当我们使用记事本打开二进制文件会看到乱码,这就是原因。文件的复制过程也是复制的二进制数据,而不是真实的文字。
因此可以这样理解文件复制的过程:
字符流:二进制数据 --编码-> 字符编码表 --解码-> 二进制数据
字节流:二进制数据 —> 二进制数据
所以问题就是出现在编码和解码的过程中,既然是字符的编码表,那它就是包含所有的字符,但是字符的数量是有限的,这就意味着它不能表示一些超过编码表的字符,因为根本不存在表中。所以,JVM 会使用一些字符进行替换,基本上都是乱码(所以大小会发生变化),而且如果有一个数据恰好是-1,那么读取就会中断,引起数据丢失。
例如如下代码使用字符流读取就会错误:
String filename = "D:/DB/fos.txt"; //文件名
byte[] b = new byte[] {-1, -1}; //两个字节,127的二进制就是 1111 1111
//数据写入文件
try (FileOutputStream fos = new FileOutputStream(filename)) {
fos.write(b, 0, b.length); //将两个127连续写入,就是 1111 1111 1111 1111
}
File file = new File(filename);
//输出文件的大小
System.out.println("file length: " + file.length());
char[] c = new char[2];
//使用字符流读取文件
try (FileReader reader = new FileReader(filename)) {
int count = reader.read(c); //Java使用Unicode编码,读取的是从 0-65535 之间的数字。
System.out.println("以文本形式输出:" + new String(c, 0, count)+" "+count);
for (char d : c) {
System.out.println("字符为:" + d);
}
}
System.out.println("表示字符:" + c[0]);
//再写入文件
try (FileWriter writer = new FileWriter(filename)) {
writer.write(c, 0, 2);
}
File f = new File(filename);
System.out.println("file length: " + f.length());结果:

说明: 我将两个1字节的-1写入(字节流)了文本文件(注意是字节:-1,不是字符:-1),然后再读取(字符流),再写入(字符流)就已经出现了问题。读取出的字符显示了一个奇怪的符号,而且它的值为:65533,这个值如果用字节表示的话,一个字节是不够的,所以文件的大小就会变化。在非文本的二进制数据中,出现这种情况都是正常的,因为本来就不是按照字符编码的。
因为字符都是正数,而非字符编码的话,字节数可能是负数(很可能),但是负数在字符看来就是正数,这也是为什么-1,被读成 65533的原因。可以看出来,读取就已经错误了。
注意: 这里的重点是对于使用字符流读取非文本文件,在读取-写入的过程中的问题。
위 내용은 Java가 문자 스트림을 사용하여 텍스트가 아닌 바이너리 파일을 읽을 수 없는 이유는 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7467
7467
 15
1376
52
77
11
48
19
19
20
15
1376
52
77
11
48
19
19
20



 Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기 안내. 여기서는 예제를 통해 Java의 함수와 예제를 통해 두 가지 다른 생성기에 대해 설명합니다.
 자바의 웨카
Aug 30, 2024 pm 04:28 PM
자바의 웨카
Aug 30, 2024 pm 04:28 PM
Java의 Weka 가이드. 여기에서는 소개, weka java 사용 방법, 플랫폼 유형 및 장점을 예제와 함께 설명합니다.
 Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 Smith Number 가이드. 여기서는 정의, Java에서 스미스 번호를 확인하는 방법에 대해 논의합니다. 코드 구현의 예.
 Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
이 기사에서는 가장 많이 묻는 Java Spring 면접 질문과 자세한 답변을 보관했습니다. 그래야 면접에 합격할 수 있습니다.
 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
 Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 TimeStamp to Date 안내. 여기서는 소개와 예제와 함께 Java에서 타임스탬프를 날짜로 변환하는 방법에 대해서도 설명합니다.
