

덴드로그램을 사용하여 클러스터 시각화

일반적으로 우리는 클러스터 시각화를 위해 산점도를 사용하지만, 일부 클러스터링 알고리즘을 시각화할 때는 산점도가 이상적이지 않기 때문에 이번 글에서는 덴드로그램(Dendrograms)을 사용하여 클러스터링 결과를 시각화하는 방법을 소개합니다.
Dendogram
덴드로그램은 개체, 그룹 또는 변수 간의 계층적 관계를 보여주는 다이어그램입니다. 덴드로그램은 유사한 특성을 가진 관측치 그룹을 나타내는 노드 또는 클러스터에 연결된 가지로 구성됩니다. 가지의 높이나 노드 사이의 거리는 그룹이 얼마나 다르거나 유사한지를 나타냅니다. 즉, 가지가 길수록 또는 노드 사이의 거리가 멀수록 그룹의 유사성은 줄어듭니다. 가지가 짧을수록 또는 노드 사이의 거리가 작을수록 그룹이 더 유사합니다.
Dendograms는 복잡한 데이터 구조를 시각화하고 유사한 특성을 가진 데이터의 하위 그룹 또는 클러스터를 식별하는 데 유용합니다. 이는 생물학, 유전학, 생태학, 사회 과학 및 유사성이나 상관 관계를 기반으로 데이터를 그룹화할 수 있는 기타 분야에서 일반적으로 사용됩니다.
배경 지식:
"dendrogram"이라는 단어는 그리스어 "dendron"(나무)와 "gramma"(그림)에서 유래되었습니다. 1901년 영국의 수학자이자 통계학자인 칼 피어슨(Karl Pearson)은 다양한 식물 종 간의 관계를 보여주기 위해 수형도를 사용했습니다. 그는 이 그래프를 "클러스터 그래프"라고 불렀습니다. 이는 덴드로그램의 첫 번째 사용으로 간주될 수 있습니다.
데이터 준비
클러스터링을 위해 여러 회사의 실제 주가를 사용할 것입니다. 간편한 접근을 위해 Alpha Vantage에서 제공하는 무료 API를 사용하여 데이터를 수집합니다. Alpha Vantage는 무료 API와 프리미엄 API를 모두 제공합니다. API를 통해 액세스하려면 키가 필요합니다. 해당 웹사이트를 참조하세요.
import pandas as pd
import requests
companies={'Apple':'AAPL','Amazon':'AMZN','Facebook':'META','Tesla':'TSLA','Alphabet (Google)':'GOOGL','Shell':'SHEL','Suncor Energy':'SU',
'Exxon Mobil Corp':'XOM','Lululemon':'LULU','Walmart':'WMT','Carters':'CRI','Childrens Place':'PLCE','TJX Companies':'TJX',
'Victorias Secret':'VSCO','MACYs':'M','Wayfair':'W','Dollar Tree':'DLTR','CVS Caremark':'CVS','Walgreen':'WBA','Curaleaf':'CURLF'}기술, 소매, 석유 및 가스, 기타 산업 분야에서 선정된 20개 기업.
import time
all_data={}
for key,value in companies.items():
# Replace YOUR_API_KEY with your Alpha Vantage API key
url = f'https://www.alphavantage.co/query?function=TIME_SERIES_DAILY_ADJUSTED&symbol={value}&apikey=<YOUR_API_KEY>&outputsize=full'
response = requests.get(url)
data = response.json()
time.sleep(15)
if 'Time Series (Daily)' in data and data['Time Series (Daily)']:
df = pd.DataFrame.from_dict(data['Time Series (Daily)'], orient='index')
print(f'Received data for {key}')
else:
print("Time series data is empty or not available.")
df.rename(columns = {'1. open':key}, inplace = True)
all_data[key]=df[key]위 코드는 너무 자주 차단되지 않도록 API 호출 사이에 15초 일시 중지를 설정합니다.
# find common dates among all data frames common_dates = None for df_key, df in all_data.items(): if common_dates is None: common_dates = set(df.index) else: common_dates = common_dates.intersection(df.index) common_dates = sorted(list(common_dates)) # create new data frame with common dates as index df_combined = pd.DataFrame(index=common_dates) # reindex each data frame with common dates and concatenate horizontally for df_key, df in all_data.items(): df_combined = pd.concat([df_combined, df.reindex(common_dates)], axis=1)
위의 데이터를 필요한 DF에 통합하면 바로 아래에서 사용할 수 있습니다.
계층적 클러스터링
계층적 클러스터링은 기계 학습 및 데이터 분석에 사용되는 클러스터링 알고리즘입니다. 이는 중첩된 클러스터의 계층 구조를 사용하여 유사한 객체를 유사성을 기준으로 클러스터로 그룹화합니다. 알고리즘은 단일 개체로 시작하여 이를 클러스터로 병합하는 응집형이거나 큰 클러스터에서 시작하여 이를 더 작은 클러스터로 반복적으로 나누는 분할형일 수 있습니다.
모든 클러스터링 방법이 계층적 클러스터링 방법은 아니며 덴드로그램은 일부 클러스터링 알고리즘에서만 사용할 수 있다는 점에 유의해야 합니다.
클러스터링 알고리즘 scipy 모듈에서 제공하는 계층적 클러스터링을 사용하겠습니다.
1. 하향식 클러스터링
import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# Convert correlation matrix to distance matrix
dist_mat = 1 - df_combined.corr()
# Perform top-down clustering
clustering = sch.linkage(dist_mat, method='complete')
cuts = sch.cut_tree(clustering, n_clusters=[3, 4])
# Plot dendrogram
plt.figure(figsize=(10, 5))
sch.dendrogram(clustering, labels=list(df_combined.columns), leaf_rotation=90)
plt.title('Dendrogram of Company Correlations (Top-Down Clustering)')
plt.xlabel('Companies')
plt.ylabel('Distance')
plt.show()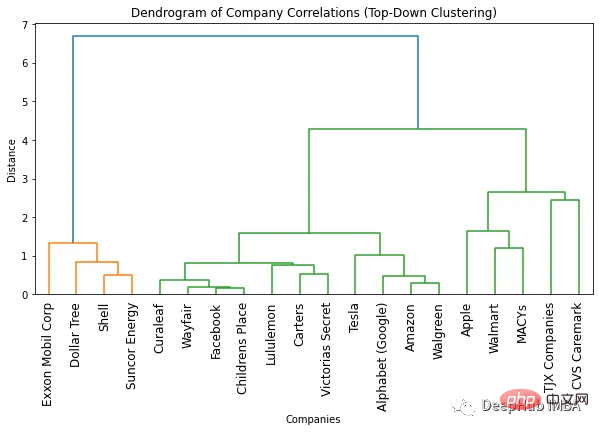
덴드로그램을 기반으로 최적의 클러스터 수를 결정하는 방법
최적의 클러스터 수를 찾는 가장 쉬운 방법은 생성된 덴드로그램을 살펴보는 것입니다. 색상의 수. 최적의 클러스터 수는 색상 수보다 하나 적습니다. 따라서 위의 덴드로그램에 따르면 최적의 클러스터 수는 2개입니다.
최적의 클러스터 수를 찾는 또 다른 방법은 클러스터 사이의 거리가 갑자기 변하는 지점을 식별하는 것입니다. 이를 "니 포인트" 또는 "엘보우 포인트"라고 하며 데이터의 변동을 가장 잘 포착하는 클러스터 수를 결정하는 데 사용할 수 있습니다. 위 그림에서 서로 다른 수의 클러스터 사이의 최대 거리 변화는 1개와 2개의 클러스터 사이에서 발생하는 것을 볼 수 있습니다. 따라서 최적의 클러스터 수는 2개입니다.
덴드로그램에서 원하는 개수의 클러스터 가져오기
덴드로그램 사용의 한 가지 장점은 덴드로그램을 보면 객체를 원하는 개수의 클러스터로 클러스터링할 수 있다는 것입니다. 예를 들어 두 개의 클러스터를 찾아야 하는 경우 덴드로그램의 위쪽 수직선을 보고 클러스터를 결정할 수 있습니다. 예를 들어, 이 예에서 두 개의 클러스터가 필요한 경우 첫 번째 클러스터에는 4개의 회사가 있고 두 번째 클러스터에는 16개의 회사가 있습니다. 3개의 클러스터가 필요한 경우 두 번째 클러스터를 11개 회사와 5개 회사로 추가로 분할할 수 있습니다. 더 필요한 경우 이 예를 따를 수 있습니다.
2. 상향식 클러스터링
import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# Convert correlation matrix to distance matrix
dist_mat = 1 - df_combined.corr()
# Perform bottom-up clustering
clustering = sch.linkage(dist_mat, method='ward')
# Plot dendrogram
plt.figure(figsize=(10, 5))
sch.dendrogram(clustering, labels=list(df_combined.columns), leaf_rotation=90)
plt.title('Dendrogram of Company Correlations (Bottom-Up Clustering)')
plt.xlabel('Companies')
plt.ylabel('Distance')
plt.show()
상향식 클러스터링으로 얻은 덴드로그램은 하향식 클러스터링과 유사합니다. 최적의 클러스터 수는 여전히 2개입니다(색상 수와 "변곡점" 방법을 기반으로 함). 그러나 더 많은 클러스터가 필요한 경우 약간의 미묘한 차이가 관찰됩니다. 이는 사용된 방법이 다르기 때문에 정상적인 현상이며 결과에 약간의 차이가 있을 수 있습니다.
요약
Dendograms는 복잡한 데이터 구조를 시각화하고 유사한 특성을 가진 데이터의 하위 그룹 또는 클러스터를 식별하는 데 유용한 도구입니다. 이 기사에서는 계층적 클러스터링 방법을 사용하여 덴드로그램을 생성하고 최적의 클러스터 수를 결정하는 방법을 보여줍니다. 데이터 트리 다이어그램은 여러 회사 간의 관계를 이해하는 데 도움이 될 뿐만 아니라 데이터의 계층 구조를 이해하기 위해 다양한 다른 영역에서도 사용할 수 있습니다.
위 내용은 덴드로그램을 사용하여 클러스터 시각화의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7675
7675
 15
1393
52
1207
24
91
11
73
19
15
1393
52
1207
24
91
11
73
19

 권장되는 AI 지원 프로그래밍 도구 4가지
Apr 22, 2024 pm 05:34 PM
권장되는 AI 지원 프로그래밍 도구 4가지
Apr 22, 2024 pm 05:34 PM
이 AI 지원 프로그래밍 도구는 급속한 AI 개발 단계에서 유용한 AI 지원 프로그래밍 도구를 많이 발굴했습니다. AI 지원 프로그래밍 도구는 개발 효율성을 높이고, 코드 품질을 향상시키며, 버그 발생률을 줄일 수 있습니다. 이는 현대 소프트웨어 개발 프로세스에서 중요한 보조자입니다. 오늘 Dayao는 4가지 AI 지원 프로그래밍 도구(모두 C# 언어 지원)를 공유하겠습니다. 이 도구가 모든 사람에게 도움이 되기를 바랍니다. https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot은 더 빠르고 적은 노력으로 코드를 작성하는 데 도움이 되는 AI 코딩 도우미이므로 문제 해결과 협업에 더 집중할 수 있습니다. 힘내
 최고의 AI 프로그래머는 누구일까요? Devin, Tongyi Lingma 및 SWE 에이전트의 잠재력을 살펴보세요.
Apr 07, 2024 am 09:10 AM
최고의 AI 프로그래머는 누구일까요? Devin, Tongyi Lingma 및 SWE 에이전트의 잠재력을 살펴보세요.
Apr 07, 2024 am 09:10 AM
세계 최초의 AI 프로그래머 데빈(Devin)이 태어난 지 한 달도 채 안 된 2022년 3월 3일, 프린스턴 대학의 NLP팀은 오픈소스 AI 프로그래머 SWE-에이전트를 개발했습니다. GPT-4 모델을 활용하여 GitHub 리포지토리의 문제를 자동으로 해결합니다. SWE-bench 테스트 세트에서 SWE-agent의 성능은 Devin과 유사하며 평균 93초가 걸리고 문제의 12.29%를 해결합니다. SWE-agent는 전용 터미널과 상호 작용하여 파일 내용을 열고 검색하고, 자동 구문 검사를 사용하고, 특정 줄을 편집하고, 테스트를 작성 및 실행할 수 있습니다. (참고: 위 내용은 원문 내용을 약간 조정한 것이지만 원문의 핵심 정보는 그대로 유지되며 지정된 단어 수 제한을 초과하지 않습니다.) SWE-A
 Go 언어를 사용하여 모바일 애플리케이션을 개발하는 방법을 알아보세요.
Mar 28, 2024 pm 10:00 PM
Go 언어를 사용하여 모바일 애플리케이션을 개발하는 방법을 알아보세요.
Mar 28, 2024 pm 10:00 PM
Go 언어 개발 모바일 애플리케이션 튜토리얼 모바일 애플리케이션 시장이 지속적으로 성장함에 따라 점점 더 많은 개발자가 Go 언어를 사용하여 모바일 애플리케이션을 개발하는 방법을 모색하기 시작했습니다. 간단하고 효율적인 프로그래밍 언어인 Go 언어는 모바일 애플리케이션 개발에서도 강력한 잠재력을 보여주었습니다. 이 기사에서는 Go 언어를 사용하여 모바일 애플리케이션을 개발하는 방법을 자세히 소개하고 독자가 빠르게 시작하고 자신의 모바일 애플리케이션 개발을 시작할 수 있도록 특정 코드 예제를 첨부합니다. 1. 준비 시작하기 전에 개발 환경과 도구를 준비해야 합니다. 머리
 가장 인기 있는 다섯 가지 Go 언어 라이브러리 요약: 개발을 위한 필수 도구
Feb 22, 2024 pm 02:33 PM
가장 인기 있는 다섯 가지 Go 언어 라이브러리 요약: 개발을 위한 필수 도구
Feb 22, 2024 pm 02:33 PM
가장 인기 있는 다섯 가지 Go 언어 라이브러리 요약: Go 언어는 탄생 이후 광범위한 관심과 적용을 받아왔습니다. 새롭게 떠오르는 효율적이고 간결한 프로그래밍 언어인 Go의 급속한 발전은 풍부한 오픈 소스 라이브러리의 지원과 불가분의 관계입니다. 이 기사에서는 인기 있는 Go 언어 라이브러리 5개를 소개합니다. 이러한 라이브러리는 Go 개발에서 중요한 역할을 하며 개발자에게 강력한 기능과 편리한 개발 경험을 제공합니다. 동시에 이러한 라이브러리의 용도와 기능을 더 잘 이해하기 위해 구체적인 코드 예제를 통해 설명하겠습니다.
 Kafka 탐색을 위한 다섯 가지 시각화 도구 선택
Feb 01, 2024 am 08:03 AM
Kafka 탐색을 위한 다섯 가지 시각화 도구 선택
Feb 01, 2024 am 08:03 AM
Kafka 시각화 도구를 위한 다섯 가지 옵션 ApacheKafka는 대량의 실시간 데이터를 처리할 수 있는 분산 스트림 처리 플랫폼입니다. 실시간 데이터 파이프라인, 메시지 대기열 및 이벤트 기반 애플리케이션을 구축하는 데 널리 사용됩니다. Kafka의 시각화 도구는 사용자가 Kafka 클러스터를 모니터링 및 관리하고 Kafka 데이터 흐름을 더 잘 이해하는 데 도움이 될 수 있습니다. 다음은 널리 사용되는 5가지 Kafka 시각화 도구에 대한 소개입니다.
 Android 개발에 가장 적합한 Linux 배포판은 무엇입니까?
Mar 14, 2024 pm 12:30 PM
Android 개발에 가장 적합한 Linux 배포판은 무엇입니까?
Mar 14, 2024 pm 12:30 PM
Android 개발은 바쁘고 흥미로운 작업이며, 개발에 적합한 Linux 배포판을 선택하는 것이 특히 중요합니다. 많은 Linux 배포판 중에서 Android 개발에 가장 적합한 배포판은 무엇입니까? 이 기사에서는 이 문제를 여러 측면에서 살펴보고 구체적인 코드 예제를 제공합니다. 먼저 현재 인기 있는 여러 Linux 배포판(Ubuntu, Fedora, Debian, CentOS 등)을 살펴보겠습니다. 이들은 모두 고유한 장점과 특징을 가지고 있습니다.
 Go 언어 프런트엔드 기술 탐색: 프런트엔드 개발을 위한 새로운 비전
Mar 28, 2024 pm 01:06 PM
Go 언어 프런트엔드 기술 탐색: 프런트엔드 개발을 위한 새로운 비전
Mar 28, 2024 pm 01:06 PM
빠르고 효율적인 프로그래밍 언어인 Go 언어는 백엔드 개발 분야에서 널리 사용됩니다. 그러나 Go 언어를 프런트엔드 개발과 연관시키는 사람은 거의 없습니다. 실제로 프런트엔드 개발에 Go 언어를 사용하면 효율성이 향상될 뿐만 아니라 개발자에게 새로운 지평을 열어줄 수도 있습니다. 이 기사에서는 프런트엔드 개발에 Go 언어를 사용할 수 있는 가능성을 살펴보고 독자가 이 영역을 더 잘 이해할 수 있도록 구체적인 코드 예제를 제공합니다. 전통적인 프런트엔드 개발에서는 사용자 인터페이스를 구축하기 위해 JavaScript, HTML, CSS를 사용하는 경우가 많습니다.
 VSCode 이해: 이 도구는 어떤 용도로 사용됩니까?
Mar 25, 2024 pm 03:06 PM
VSCode 이해: 이 도구는 어떤 용도로 사용됩니까?
Mar 25, 2024 pm 03:06 PM
"VSCode 이해: 이 도구는 어떤 용도로 사용됩니까?" 》프로그래머로서 초보자이든 숙련된 개발자이든 코드 편집 도구를 사용하지 않으면 할 수 없습니다. 많은 편집 도구 중에서 Visual Studio Code(약칭 VSCode)는 가볍고 강력한 오픈 소스 코드 편집기로 개발자들 사이에서 매우 인기가 높습니다. 그렇다면 VSCode는 정확히 어떤 용도로 사용되나요? 이 기사에서는 VSCode의 기능과 사용법을 자세히 살펴보고 독자에게 도움이 되는 구체적인 코드 예제를 제공합니다.
