
Ajax 요청을 받아 필수 필드를 JSON으로 파싱
데이터를 Excel에 저장
쉽게 분석할 수 있도록 데이터를 MySQL에 저장
2. 페이지 구조
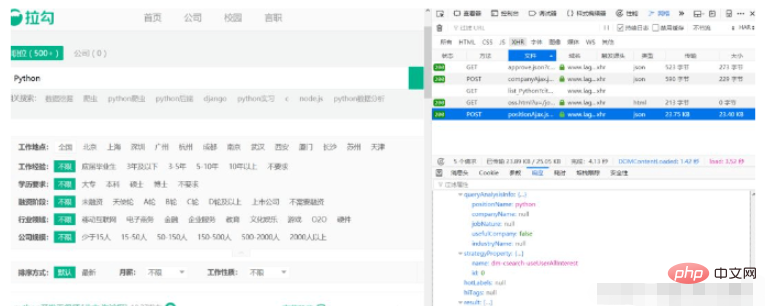 응답 결과를 보면 이 요청이 정확히 우리에게 필요한 요청입니다. 나중에 이 주소를 직접 요청할 수 있습니다. 그림에서 알 수 있듯이 다음 결과는 각 위치의 정보입니다.
응답 결과를 보면 이 요청이 정확히 우리에게 필요한 요청입니다. 나중에 이 주소를 직접 요청할 수 있습니다. 그림에서 알 수 있듯이 다음 결과는 각 위치의 정보입니다.
이제 우리는 어디서 데이터를 요청하고 어디서 결과를 얻을 수 있는지 알았습니다. 그런데 결과 목록의 첫 번째 페이지에는 15개의 데이터만 있습니다. 다른 페이지의 데이터는 어떻게 가져오나요?
3. 요청 매개변수
세 개의 양식 데이터가 제출된 것을 확인했습니다. kd는 우리가 검색한 키워드이고 pn은 현재 페이지 번호입니다. 기본적으로 첫 번째로 설정하세요. 걱정하지 마세요. 이제 남은 것은 30페이지의 데이터를 다운로드하기 위한 요청을 작성하는 것입니다.
4. 요청 구성 및 데이터 구문 분석
data = {'first': 'true', 'pn': page, 'kd': lang_name}를 구성한 다음 요청을 사용하여 URL 주소를 요청합니다. 구문 분석된 JSON 데이터가 완료되었습니다. Lagou는 크롤러에 대해 엄격한 제한을 두기 때문에 브라우저에 모든 헤더 필드를 추가하고 크롤러 간격을 10~20초로 늘려야 정상적으로 데이터를 얻을 수 있습니다.
import requests
def get_json(url, page, lang_name):
headers = {
'Host': 'www.lagou.com',
'Connection': 'keep-alive',
'Content-Length': '23',
'Origin': 'https://www.lagou.com',
'X-Anit-Forge-Code': '0',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'X-Anit-Forge-Token': 'None',
'Referer': 'https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7'
}
data = {'first': 'false', 'pn': page, 'kd': lang_name}
json = requests.post(url, data, headers=headers).json()
list_con = json['content']['positionResult']['result']
info_list = []
for i in list_con:
info = []
info.append(i.get('companyShortName', '无'))
info.append(i.get('companyFullName', '无'))
info.append(i.get('industryField', '无'))
info.append(i.get('companySize', '无'))
info.append(i.get('salary', '无'))
info.append(i.get('city', '无'))
info.append(i.get('education', '无'))
info_list.append(info)
return info_list4. 모든 데이터 가져오기
위 내용은 Python을 사용하여 직무 분석 보고서를 구현하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



