

Python에서 loguru 로그 라이브러리를 사용하는 방법

1. 개요
python의 로그 라이브러리 logging은 log4j와 약간 비슷하지만 구성이 일반적으로 더 복잡하며 로그 서버 구축도 어렵다. 표준 라이브러리 logging을 대체하는 loguru는 사용이 훨씬 간단합니다. python中的日志库logging使用起来有点像log4j,但配置通常比较复杂,构建日志服务器时也不是方便。标准库logging的替代品是loguru,loguru使用起来就简单的多。
loguru默认的输出格式是:时间、级别、模块、行号以及日志内容。loguru不需要手动创建 logger,开箱即用,比logging使用方便得多;另外,日志输出内置了彩色功能,颜色和非颜色控制很方便,更加友好。
loguru是非标准库,需要事先安装,命令是:**pip3 install loguru****。**安装后,最简单的使用样例如下:
from loguru import logger logger.debug('hello, this debug loguru') logger.info('hello, this is info loguru') logger.warning('hello, this is warning loguru') logger.error('hello, this is error loguru') logger.critical('hello, this is critical loguru')
上述代码输出:
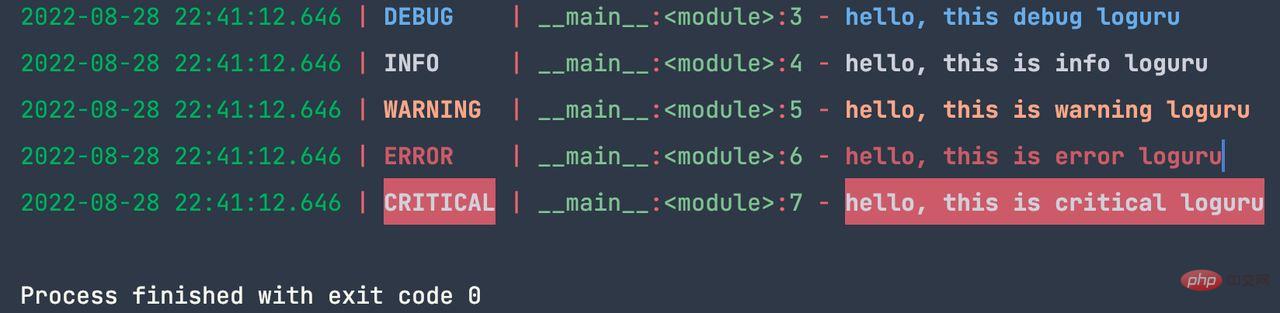
日志打印到文件的用法也很简单,代码如下:
from loguru import logger logger.add('myloguru.log') logger.debug('hello, this debug loguru') logger.info('hello, this is info loguru') logger.warning('hello, this is warning loguru') logger.error('hello, this is error loguru') logger.critical('hello, this is critical loguru')
上述代码运行时,可以打印到console,也可以打印到文件中去。
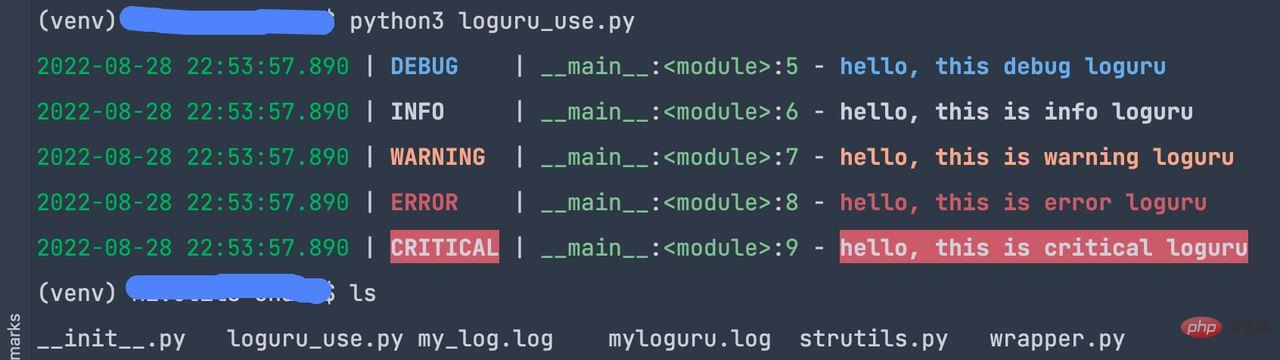
2.常见用法
2.1.显示格式
loguru默认格式是时间、级别、名称+模块和日志内容,其中名称+模块是写死的,是当前文件的__name__变量,此变量最好不要修改。
工程比较复杂的情况下,自定义模块名称,是非常有用的,容易定界定位,避免陷入细节中。我们可以通过logger.configure手工指定模块名称。如下如下:
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>mymodule</> | - <lvl>{message}</>",
"colorize": True
},
])
logger.debug('this is debug')
logger.info('this is info')
logger.warning('this is warning')
logger.error('this is error')
logger.critical('this is critical')
handlers:表示日志输出句柄或者目的地,sys.stderr表示输出到命令行终端。
"sink": sys.stderr,表示输出到终端
"format":表示日志格式化。<lvl>{level:8}</>表示按照日志级别显示颜色。8表示输出宽度为8个字符。
"colorize":True**:表示显示颜色。
上述代码的输出为:

这里写死了模块名称,每个日志都这样设置也是比较繁琐。下面会介绍指定不同模块名称的方法。
2.2.写入文件
日志一般需要持久化,除了输出到命令行终端外,还需要写入文件。标准日志库可以通过配置文件配置logger,在代码中也可以实现,但过程比较繁琐。loguru相对而已就显得稍微简单一些,我们看下在代码中如何实现此功能。日志代码如下:
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>mymodule</> | - <lvl>{message}</>",
"colorize": True
},
{
"sink": 'first.log',
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |{level:8}| {name} : {module}:{line:4} | mymodule | - {message}",
"colorize": False
},
])
logger.debug('this is debug')
logger.info('this is info')
logger.warning('this is warning')
logger.error('this is error')
logger.critical('this is critical')与2.1.唯一不同的地方,
logger.configure新增了一个handler,写入到日志文件中去。用法很简单。
上述只是通过logger.configure设置日志格式,但是模块名不是可变的,实际项目开发中,不同模块写日志,需要指定不同的模块名称。因此,模块名称需要参数化,这样实用性更强。样例代码如下:
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>{extra[module_name]}</> | - <lvl>{message}</>",
"colorize": True
},
{
"sink": 'first.log',
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |{level:8}| {name} : {module}:{line:4} | {extra[module_name]} | - {message}",
"colorize": False
},
])
log = logger.bind(module_name='my-loguru')
log.debug("this is hello, module is my-loguru")
log2 = logger.bind(module_name='my-loguru2')
log2.info("this is hello, module is my-loguru2")
logger.bind(module_name='my-loguru')通过bind方法,实现module_name的参数化。bind返回一个日志对象,可以通过此对象进行日志输出,这样就可以实现不同模块的日志格式。loguru中自定义模块名称的功能比标准日志库有点不同。通过bind方法,可以轻松实现标准日志
logging的功能。而且,可以通过bind和logger.configure,轻松实现结构化日志。
上述代码的输出如下:

2.3.json日志
loguru保存成结构化json格式非常简单,只需要设置serialize=True参数即可。代码如下:
from loguru import logger logger.add('json.log', serialize=True, encoding='utf-8') logger.debug('this is debug message') logger.info('this is info message') logger.error('this is error message')
输出内容如下:

2.4.日志绕接
loguru日志文件支持三种设置:循环、保留、压缩。设置也比较简单。尤其是压缩格式,支持非常丰富,常见的压缩格式都支持,比如:"gz", "bz2", "xz", "lzma", "tar", "tar.gz", "tar.bz2", "tar.xz", "zip"
loguru기본 출력 형식은 시간, 레벨, 모듈, 줄 번호 및 로그 내용입니다. loguru는 logger를 수동으로 생성할 필요가 없으며 바로 사용할 수 있어 logging보다 사용하기가 훨씬 쉽습니다. , 로그 출력에는 색상 기능이 내장되어 있으며 비 색상 제어가 더욱 편리하고 사용자 친화적입니다. 🎜🎜loguru는 비표준 라이브러리이므로 미리 설치해야 합니다. 명령은 **pip3 install loguru****입니다. **설치 후 가장 간단한 사용 예는 다음과 같습니다. 🎜from loguru import logger
logger.add("file_1.log", rotation="500 MB") # 自动循环过大的文件
logger.add("file_2.log", rotation="12:00") # 每天中午创建新文件
logger.add("file_3.log", rotation="1 week") # 一旦文件太旧进行循环
logger.add("file_X.log", retention="10 days") # 定期清理
logger.add("file_Y.log", compression="zip") # 压缩节省空间logger.add("somefile.log", enqueue=True)🎜🎜2. 일반적인 사용법 🎜2.1. 표시 형식
🎜loguru기본 형식은 시간, 레벨, 이름 + 모듈 및 로그 내용이며, 여기서 이름 + 모듈은 <입니다. 현재 파일 >__name__ 변수의 코드를 수정하지 않는 것이 가장 좋습니다. 🎜🎜프로젝트가 더 복잡할 때 모듈 이름을 사용자 정의하는 것은 매우 유용하며 정의 및 위치 지정이 쉽고 세부 사항에 얽매이는 것을 방지할 수 있습니다. logger.configure를 통해 모듈 이름을 수동으로 지정할 수 있습니다. 다음과 같습니다: 🎜import logging
import logging.handlers
import sys
from loguru import logger
handler = logging.handlers.SysLogHandler(address=('localhost', 514))
logger.add(handler)
class LoguruHandler(logging.Handler):
def emit(self, record):
try:
level = logger.level(record.levelname).name
except ValueError:
level = record.levelno
frame, depth = logging.currentframe(), 2
while frame.f_code.co_filename == logging.__file__:
frame = frame.f_back
depth += 1
logger.opt(depth=depth, exception=record.exc_info).log(level, record.getMessage())
logging.basicConfig(handlers=[LoguruHandler()], level=0, format='%(asctime)s %(filename)s %(levelname)s %(message)s',
datefmt='%Y-%M-%D %H:%M:%S')
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | [ModuleA] | - <lvl>{message}</>",
"colorize": True
},
])
log = logging.getLogger('root')
# 使用标注日志系统输出
log.info('hello wrold, that is from logging')
log.debug('debug hello world, that is from logging')
log.error('error hello world, that is from logging')
log.warning('warning hello world, that is from logging')
# 使用loguru系统输出
logger.info('hello world, that is from loguru')🎜🎜위 코드의 출력은 다음과 같습니다. 🎜🎜handlers: 로그 출력 핸들 또는 대상을 나타내고,sys.stderr는 명령줄 터미널에 대한 출력을 나타냅니다. 🎜🎜"sink": sys.stderr는 터미널에 대한 출력을 의미하고 🎜🎜"format":은 로그 형식을 의미합니다.<lvl>{level:8}</>은 로그 수준에 따라 색상을 표시한다는 의미입니다. 8은 출력 너비가 8자임을 의미합니다. 🎜🎜"colorize":True**: 표시 색상을 나타냅니다. 🎜
🎜🎜여기서 모듈 이름이 하드코딩되어 있는데 이렇게 로그 하나하나 설정하는 게 꽤 번거롭습니다. 다음은 다양한 모듈 이름을 지정하는 방법을 설명합니다. 🎜
2.2. 파일 쓰기
🎜로그는 일반적으로 명령줄 터미널에 출력하는 것 외에도 파일에 기록되어야 합니다. 표준 로그 라이브러리는 구성 파일을 통해 로거를 구성할 수 있고 코드로 구현할 수도 있지만 프로세스가 상대적으로 번거롭습니다. Loguru는 비교적 간단합니다. 이 기능을 코드에서 구현하는 방법을 살펴보겠습니다. 로그 코드는 다음과 같습니다. 🎜# client.py
import pickle
import socket
import struct
import time
from loguru import logger
class SocketHandler:
def __init__(self, host, port):
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock.connect((host, port))
def write(self, message):
record = message.record
data = pickle.dumps(record)
slen = struct.pack(">L", len(data))
self.sock.send(slen + data)
logger.configure(handlers=[{"sink": SocketHandler('localhost', 9999)}])
while True:
time.sleep(1)
logger.info("Sending info message from the client")
logger.debug("Sending debug message from the client")
logger.error("Sending error message from the client")🎜2.1과의 유일한 차이점은🎜위에서는logger.configure가 새로운handler를 추가하고 이를 로그 파일에 기록한다는 것입니다. 사용법은 매우 간단합니다. 🎜
logger.configure를 통해서만 로그 형식을 설정하지만, 모듈 이름은 가변적이지 않습니다. 실제 프로젝트 개발에서는 로그 작성 시 모듈마다 다른 모듈 이름을 지정해야 합니다. 따라서 모듈 이름을 보다 실용적으로 매개변수화해야 합니다. 샘플 코드는 다음과 같습니다. 🎜# server.py
import pickle
import socketserver
import struct
from loguru import logger
class LoggingStreamHandler(socketserver.StreamRequestHandler):
def handle(self):
while True:
chunk = self.connection.recv(4)
if len(chunk) < 4:
break
slen = struct.unpack('>L', chunk)[0]
chunk = self.connection.recv(slen)
while len(chunk) < slen:
chunk = chunk + self.connection.recv(slen - len(chunk))
record = pickle.loads(chunk)
level, message = record["level"].no, record["message"]
logger.patch(lambda record: record.update(record)).log(level, message)
server = socketserver.TCPServer(('localhost', 9999), LoggingStreamHandler)
server.serve_forever()🎜🎜위 코드의 출력은 다음과 같습니다. 🎜🎜logger.bind(module_name='my-loguru')module_name의 매개변수화는 바인드 메소드를 통해 이루어집니다. 바인드는 로그 출력을 수행할 수 있는 로그 객체를 반환하므로 다양한 모듈에 대한 로그 형식을 구현할 수 있습니다. 🎜🎜loguru의 사용자 정의 모듈 이름 기능은 표준 로깅 라이브러리와 약간 다릅니다. 바인드 메소드를 통해 표준 로그로깅기능을 쉽게 구현할 수 있습니다. 또한bind 및 logger.configure를 통해 구조화된 로깅을 쉽게 구현할 수 있습니다. 🎜
🎜2.3.json log
🎜loguru는 구조화된 json 형식으로 저장하는 것이 매우 간단합니다. < code>serialize=True 매개변수가 전부입니다. 코드는 다음과 같습니다. 🎜# client.py
import zmq
from zmq.log.handlers import PUBHandler
from loguru import logger
socket = zmq.Context().socket(zmq.PUB)
socket.connect("tcp://127.0.0.1:12345")
handler = PUBHandler(socket)logger.add(handler)
logger.info("Logging from client")🎜2.4. 로그 래핑
🎜loguru 로그 파일은 재활용, 보존, 압축이라는 세 가지 설정을 지원합니다. 설정도 비교적 간단합니다. 특히 압축 형식에 대한 지원은 매우 풍부하며 "gz", "bz2", "xz"<와 같은 일반적인 압축 형식이 지원됩니다. /code> , "lzma", "tar", "tar.gz", "tar.bz2", < code>"tar.xz", "zip". 샘플 코드는 다음과 같습니다. 🎜from loguru import logger
logger.add("file_1.log", rotation="500 MB") # 自动循环过大的文件
logger.add("file_2.log", rotation="12:00") # 每天中午创建新文件
logger.add("file_3.log", rotation="1 week") # 一旦文件太旧进行循环
logger.add("file_X.log", retention="10 days") # 定期清理
logger.add("file_Y.log", compression="zip") # 压缩节省空间2.5.并发安全
loguru默认是线程安全的,但不是多进程安全的,如果使用了多进程安全,需要添加参数enqueue=True,样例代码如下:
logger.add("somefile.log", enqueue=True)
loguru另外还支持协程,有兴趣可以自行研究。
3.高级用法
3.1.接管标准日志logging
更换日志系统或者设计一套日志系统,比较难的是兼容现有的代码,尤其是第三方库,因为不能因为日志系统的切换,而要去修改这些库的代码,也没有必要。好在loguru可以方便的接管标准的日志系统。
样例代码如下:
import logging
import logging.handlers
import sys
from loguru import logger
handler = logging.handlers.SysLogHandler(address=('localhost', 514))
logger.add(handler)
class LoguruHandler(logging.Handler):
def emit(self, record):
try:
level = logger.level(record.levelname).name
except ValueError:
level = record.levelno
frame, depth = logging.currentframe(), 2
while frame.f_code.co_filename == logging.__file__:
frame = frame.f_back
depth += 1
logger.opt(depth=depth, exception=record.exc_info).log(level, record.getMessage())
logging.basicConfig(handlers=[LoguruHandler()], level=0, format='%(asctime)s %(filename)s %(levelname)s %(message)s',
datefmt='%Y-%M-%D %H:%M:%S')
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | [ModuleA] | - <lvl>{message}</>",
"colorize": True
},
])
log = logging.getLogger('root')
# 使用标注日志系统输出
log.info('hello wrold, that is from logging')
log.debug('debug hello world, that is from logging')
log.error('error hello world, that is from logging')
log.warning('warning hello world, that is from logging')
# 使用loguru系统输出
logger.info('hello world, that is from loguru')输出为:

3.2.输出日志到网络服务器
如果有需要,不同进程的日志,可以输出到同一个日志服务器上,便于日志的统一管理。我们可以利用自定义或者第三方库进行日志服务器和客户端的设置。下面介绍两种日志服务器的用法。
3.2.1.自定义日志服务器
日志客户端段代码如下:
# client.py
import pickle
import socket
import struct
import time
from loguru import logger
class SocketHandler:
def __init__(self, host, port):
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock.connect((host, port))
def write(self, message):
record = message.record
data = pickle.dumps(record)
slen = struct.pack(">L", len(data))
self.sock.send(slen + data)
logger.configure(handlers=[{"sink": SocketHandler('localhost', 9999)}])
while True:
time.sleep(1)
logger.info("Sending info message from the client")
logger.debug("Sending debug message from the client")
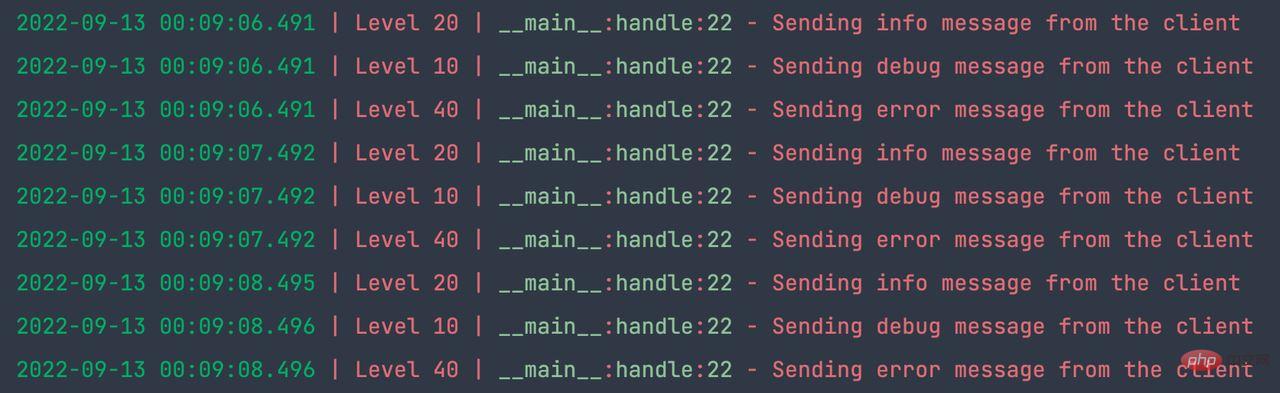
logger.error("Sending error message from the client")日志服务器代码如下:
# server.py
import pickle
import socketserver
import struct
from loguru import logger
class LoggingStreamHandler(socketserver.StreamRequestHandler):
def handle(self):
while True:
chunk = self.connection.recv(4)
if len(chunk) < 4:
break
slen = struct.unpack('>L', chunk)[0]
chunk = self.connection.recv(slen)
while len(chunk) < slen:
chunk = chunk + self.connection.recv(slen - len(chunk))
record = pickle.loads(chunk)
level, message = record["level"].no, record["message"]
logger.patch(lambda record: record.update(record)).log(level, message)
server = socketserver.TCPServer(('localhost', 9999), LoggingStreamHandler)
server.serve_forever()运行结果如下:
3.2.2.第三方库日志服务器
日志客户端代码如下:
# client.py
import zmq
from zmq.log.handlers import PUBHandler
from loguru import logger
socket = zmq.Context().socket(zmq.PUB)
socket.connect("tcp://127.0.0.1:12345")
handler = PUBHandler(socket)logger.add(handler)
logger.info("Logging from client")日志服务器代码如下:
# server.py
import sys
import zmq
from loguru import logger
socket = zmq.Context().socket(zmq.SUB)
socket.bind("tcp://127.0.0.1:12345")
socket.subscribe("")
logger.configure(handlers=[{"sink": sys.stderr, "format": "{message}"}])
while True:
_, message = socket.recv_multipart()
logger.info(message.decode("utf8").strip())3.3.与pytest结合
官方帮助中有一个讲解loguru与pytest结合的例子,讲得有点含糊不是很清楚。简单的来说,pytest有个fixture,可以捕捉被测方法中的logging日志打印,从而验证打印是否触发。
下面就详细讲述如何使用loguru与pytest结合的代码,如下:
import pytest
from _pytest.logging import LogCaptureFixture
from loguru import logger
def some_func(i, j):
logger.info('Oh no!')
logger.info('haha')
return i + j
@pytest.fixture
def caplog(caplog: LogCaptureFixture):
handler_id = logger.add(caplog.handler, format="{message}")
yield caplog
logger.remove(handler_id)
def test_some_func_logs_warning(caplog):
assert some_func(-1, 3) == 2
assert "Oh no!" in caplog.text测试输出如下:
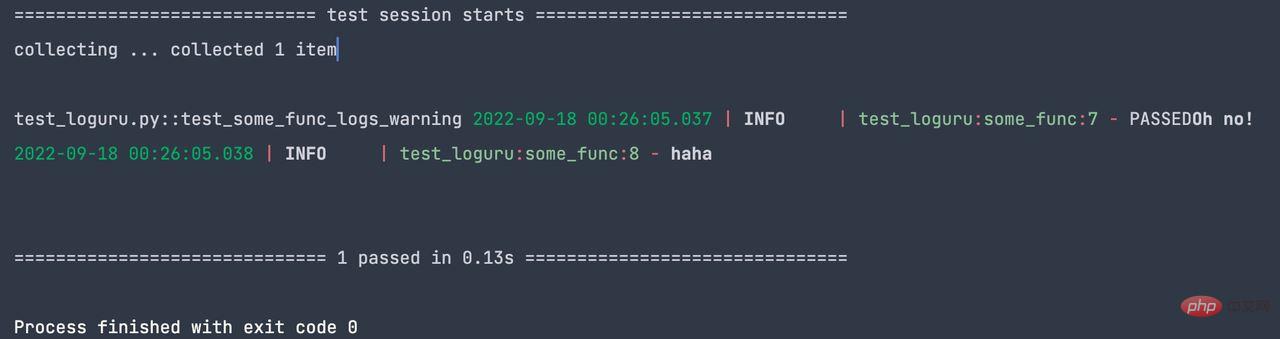
위 내용은 Python에서 loguru 로그 라이브러리를 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7500
7500
 15
1377
52
78
11
52
19
19
54
15
1377
52
78
11
52
19
19
54

 hadidb : 파이썬의 가볍고 수평 확장 가능한 데이터베이스
Apr 08, 2025 pm 06:12 PM
hadidb : 파이썬의 가볍고 수평 확장 가능한 데이터베이스
Apr 08, 2025 pm 06:12 PM
HADIDB : 가볍고 높은 수준의 확장 가능한 Python 데이터베이스 HadIDB (HADIDB)는 파이썬으로 작성된 경량 데이터베이스이며 확장 수준이 높습니다. PIP 설치를 사용하여 HADIDB 설치 : PIPINSTALLHADIDB 사용자 관리 사용자 만들기 사용자 : createUser () 메소드를 작성하여 새 사용자를 만듭니다. Authentication () 메소드는 사용자의 신원을 인증합니다. Fromhadidb.operationimportuseruser_obj = user ( "admin", "admin") user_obj.
 MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
해시 값으로 저장되기 때문에 MongoDB 비밀번호를 Navicat을 통해 직접 보는 것은 불가능합니다. 분실 된 비밀번호 검색 방법 : 1. 비밀번호 재설정; 2. 구성 파일 확인 (해시 값이 포함될 수 있음); 3. 코드를 점검하십시오 (암호 하드 코드 메일).
 2 시간의 파이썬 계획 : 현실적인 접근
Apr 11, 2025 am 12:04 AM
2 시간의 파이썬 계획 : 현실적인 접근
Apr 11, 2025 am 12:04 AM
2 시간 이내에 Python의 기본 프로그래밍 개념과 기술을 배울 수 있습니다. 1. 변수 및 데이터 유형을 배우기, 2. 마스터 제어 흐름 (조건부 명세서 및 루프), 3. 기능의 정의 및 사용을 이해하십시오. 4. 간단한 예제 및 코드 스 니펫을 통해 Python 프로그래밍을 신속하게 시작하십시오.
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 파이썬 : 기본 응용 프로그램 탐색
Apr 10, 2025 am 09:41 AM
파이썬 : 기본 응용 프로그램 탐색
Apr 10, 2025 am 09:41 AM
Python은 웹 개발, 데이터 과학, 기계 학습, 자동화 및 스크립팅 분야에서 널리 사용됩니다. 1) 웹 개발에서 Django 및 Flask 프레임 워크는 개발 프로세스를 단순화합니다. 2) 데이터 과학 및 기계 학습 분야에서 Numpy, Pandas, Scikit-Learn 및 Tensorflow 라이브러리는 강력한 지원을 제공합니다. 3) 자동화 및 스크립팅 측면에서 Python은 자동화 된 테스트 및 시스템 관리와 같은 작업에 적합합니다.
 Amazon Athena와 함께 AWS Glue Crawler를 사용하는 방법
Apr 09, 2025 pm 03:09 PM
Amazon Athena와 함께 AWS Glue Crawler를 사용하는 방법
Apr 09, 2025 pm 03:09 PM
데이터 전문가는 다양한 소스에서 많은 양의 데이터를 처리해야합니다. 이것은 데이터 관리 및 분석에 어려움을 겪을 수 있습니다. 다행히도 AWS Glue와 Amazon Athena의 두 가지 AWS 서비스가 도움이 될 수 있습니다.
 MySQL이 SQL 서버에 연결할 수 있습니다
Apr 08, 2025 pm 05:54 PM
MySQL이 SQL 서버에 연결할 수 있습니다
Apr 08, 2025 pm 05:54 PM
아니요, MySQL은 SQL Server에 직접 연결할 수 없습니다. 그러나 다음 방법을 사용하여 데이터 상호 작용을 구현할 수 있습니다. 미들웨어 사용 : MySQL에서 중간 형식으로 데이터를 내보낸 다음 미들웨어를 통해 SQL Server로 가져옵니다. 데이터베이스 링커 사용 : 비즈니스 도구는 본질적으로 미들웨어를 통해 여전히 구현되는보다 우호적 인 인터페이스와 고급 기능을 제공합니다.
 Redis로 서버를 시작하는 방법
Apr 10, 2025 pm 08:12 PM
Redis로 서버를 시작하는 방법
Apr 10, 2025 pm 08:12 PM
Redis 서버를 시작하는 단계에는 다음이 포함됩니다. 운영 체제에 따라 Redis 설치. Redis-Server (Linux/MacOS) 또는 Redis-Server.exe (Windows)를 통해 Redis 서비스를 시작하십시오. Redis-Cli Ping (Linux/MacOS) 또는 Redis-Cli.exe Ping (Windows) 명령을 사용하여 서비스 상태를 확인하십시오. Redis-Cli, Python 또는 Node.js와 같은 Redis 클라이언트를 사용하여 서버에 액세스하십시오.
