

Java 크롤러를 사용하여 이미지를 일괄적으로 크롤링하는 방법

크롤링 아이디어
이런 종류의 이미지 획득은 본질적으로 파일 다운로드(HttpClient)입니다. 하지만 단순히 사진을 얻는 것만이 아니기 때문에 페이지를 파싱하는 과정(Jsoup)도 있습니다.
Jsoup: HTML 페이지를 구문 분석하고 이미지에 대한 링크를 가져옵니다.
HttpClient: 이미지 링크를 요청하고 이미지를 로컬에 저장합니다.
특정 단계
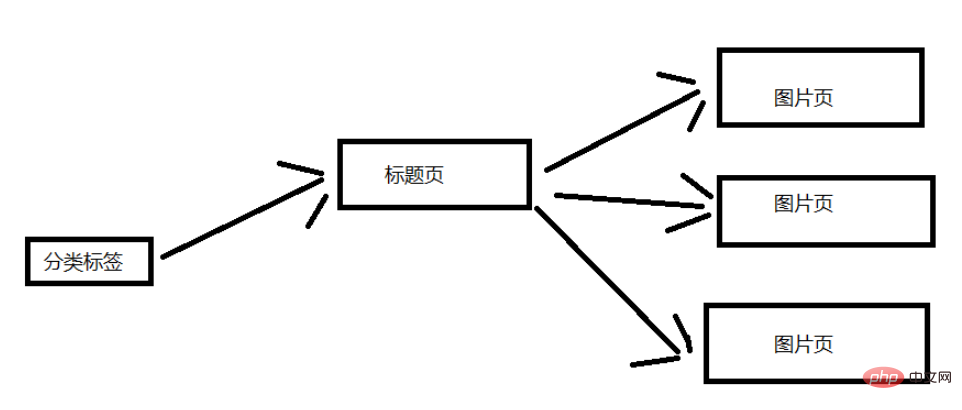
먼저 분석을 위해 홈 페이지에 들어가면 주로 다음과 같은 카테고리가 있습니다(여기서 모든 카테고리는 아니지만 이것만으로 충분합니다. 이것은 단지 학습 기술일 뿐입니다.). 우리의 목표는 각 카테고리 아래의 정보를 얻는 것입니다. 카테고리 사진.
웹사이트의 구조를 간단하게 분석해 보겠습니다. 아래 그림은 일반적인 구조를 보여줍니다. 여기서는 설명을 위해 분류 레이블을 선택했습니다. 카테고리 탭 페이지에는 여러 제목 페이지가 포함되어 있으며 각 제목 페이지에는 여러 이미지 페이지가 포함되어 있습니다. (제목 페이지에 해당하는 수십 장의 사진)
특정 코드
프로젝트 종속 jar 패키지 좌표를 가져오거나 해당 jar 패키지를 직접 다운로드하거나 프로젝트를 가져올 수도 있습니다.
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.6</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>Entity 클래스 그림 및 도구 클래스 HeaderUtil
Entity 클래스: 속성을 객체로 캡슐화하여 호출을 더 쉽게 만듭니다.
package com.picture;
public class Picture {
private String title;
private String url;
public Picture(String title, String url) {
this.title = title;
this.url = url;
}
public String getTitle() {
return this.title;
}
public String getUrl() {
return this.url;
}
}도구 카테고리 : 계속 바뀌는 UA (유용한지는 모르겠지만 자체 IP를 사용하다보니 거의 활용도가 없을 것 같네요)
package com.picture;
public class HeaderUtil {
public static String[] headers = {
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11",
"Opera/9.25 (Windows NT 5.1; U; en)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12",
"Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9",
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
};
}다운로드 카테고리
멀티스레딩이 정말 너무 빠르네요, 게다가 IP가 하나뿐이고 사용할 프록시 IP도 없습니다. (저는 그것에 대해 잘 모릅니다.) IP를 차단하기 위해 멀티스레딩을 사용하는 것이 매우 빠릅니다.
package com.picture;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.Random;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.util.EntityUtils;
import com.m3u8.HttpClientUtil;
public class SinglePictureDownloader {
private String referer;
private CloseableHttpClient httpClient;
private Picture picture;
private String filePath;
public SinglePictureDownloader(Picture picture, String referer, String filePath) {
this.httpClient = HttpClientUtil.getHttpClient();
this.picture = picture;
this.referer = referer;
this.filePath = filePath;
}
public void download() {
HttpGet get = new HttpGet(picture.getUrl());
Random rand = new Random();
//设置请求头
get.setHeader("User-Agent", HeaderUtil.headers[rand.nextInt(HeaderUtil.headers.length)]);
get.setHeader("referer", referer);
System.out.println(referer);
HttpEntity entity = null;
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
entity = response.getEntity();
if (entity != null) {
File picFile = new File(filePath, picture.getTitle());
try (OutputStream out = new BufferedOutputStream(new FileOutputStream(picFile))) {
entity.writeTo(out);
System.out.println("下载完毕:" + picFile.getAbsolutePath());
}
}
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
//关闭实体,关于 httpClient 的关闭资源,有点不太了解。
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}자주 연결을 생성하여 성능 소모를 피하기 위해 HttpClient 연결을 얻기 위한 도구 클래스입니다. (그런데 여기서는 단일 스레드를 사용해서 크롤링을 하기 때문에 그다지 유용하지는 않습니다. HttpClient 연결 하나만 사용하면 크롤링이 가능합니다. 처음에는 여러 스레드를 사용하여 크롤링을 했기 때문이지만 기본적으로 몇 장의 사진을 얻는 것은 금지되었기 때문에 단일 스레드 크롤러로 변경되었으므로 연결 풀은 그대로 유지됩니다.)
package com.m3u8;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
public class HttpClientUtil {
private static final int TIME_OUT = 10 * 1000;
private static PoolingHttpClientConnectionManager pcm; //HttpClient 连接池管理类
private static RequestConfig requestConfig;
static {
requestConfig = RequestConfig.custom()
.setConnectionRequestTimeout(TIME_OUT)
.setConnectTimeout(TIME_OUT)
.setSocketTimeout(TIME_OUT).build();
pcm = new PoolingHttpClientConnectionManager();
pcm.setMaxTotal(50);
pcm.setDefaultMaxPerRoute(10); //这里可能用不到这个东西。
}
public static CloseableHttpClient getHttpClient() {
return HttpClients.custom()
.setConnectionManager(pcm)
.setDefaultRequestConfig(requestConfig)
.build();
}
}가장 중요한 클래스: 구문 분석 페이지 클래스 PictureSpider
package com.picture;
import java.io.File;
import java.io.IOException;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import com.m3u8.HttpClientUtil;
/**
* 首先从顶部分类标题开始,依次爬取每一个标题(小分页),每一个标题(大分页。)
* */
public class PictureSpider {
private CloseableHttpClient httpClient;
private String referer;
private String rootPath;
private String filePath;
public PictureSpider() {
httpClient = HttpClientUtil.getHttpClient();
}
/**
* 开始爬虫爬取!
*
* 从爬虫队列的第一条开始,依次爬取每一条url。
*
* 分页爬取:爬10页
* 每个url属于一个分类,每个分类一个文件夹
* */
public void start(List<String> urlList) {
urlList.stream().forEach(url->{
this.referer = url;
String dirName = url.substring(22, url.length()-1); //根据标题名字去创建目录
//创建分类目录
File path = new File("D:/DragonFile/DBC/mzt/", dirName); //硬编码路径,需要用户自己指定一个
if (!path.exists()) {
path.mkdir();
rootPath = path.toString();
}
for (int i = 1; i <= 10; i++) { //分页获取图片数据,简单获取几页就行了
this.page(url + "page/"+ 1);
}
});
}
/**
* 标题分页获取链接
* */
public void page(String url) {
System.out.println("url:" + url);
String html = this.getHtml(url); //获取页面数据
Map<String, String> picMap = this.extractTitleUrl(html); //抽取图片的url
if (picMap == null) {
return ;
}
//获取标题对应的图片页面数据
this.getPictureHtml(picMap);
}
private String getHtml(String url) {
String html = null;
HttpGet get = new HttpGet(url);
get.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36");
get.setHeader("referer", url);
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
HttpEntity entity = response.getEntity();
if (entity != null) {
html = EntityUtils.toString(entity, "UTf-8"); //关闭实体?
}
}
else {
System.out.println(statusCode);
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return html;
}
private Map<String, String> extractTitleUrl(String html) {
if (html == null) {
return null;
}
Document doc = Jsoup.parse(html, "UTF-8");
Elements pictures = doc.select("ul#pins > li");
//不知为何,无法直接获取 a[0],我不太懂这方面的知识。
//那我就多处理一步,这里先放下。
Elements pictureA = pictures.stream()
.map(pic->pic.getElementsByTag("a").first())
.collect(Collectors.toCollection(Elements::new));
return pictureA.stream().collect(Collectors.toMap(
pic->pic.getElementsByTag("img").first().attr("alt"),
pic->pic.attr("href")));
}
/**
* 进入每一个标题的链接,再次分页获取图片的链接
* */
private void getPictureHtml(Map<String, String> picMap) {
//进入标题页,在标题页中再次分页下载。
picMap.forEach((title, url)->{
//分页下载一个系列的图片,每个系列一个文件夹。
File dir = new File(rootPath, title.trim());
if (!dir.exists()) {
dir.mkdir();
filePath = dir.toString(); //这个 filePath 是每一个系列图片的文件夹
}
for (int i = 1; i <= 60; i++) {
String html = this.getHtml(url + "/" + i);
if (html == null) {
//每个系列的图片一般没有那么多,
//如果返回的页面数据为 null,那就退出这个系列的下载。
return ;
}
Picture picture = this.extractPictureUrl(html);
System.out.println("开始下载");
//多线程实在是太快了(快并不是好事,我改成单线程爬取吧)
SinglePictureDownloader downloader = new SinglePictureDownloader(picture, referer, filePath);
downloader.download();
try {
Thread.sleep(1500); //不要爬的太快了,这里只是学习爬虫的知识。不要扰乱别人的正常服务。
System.out.println("爬取完一张图片,休息1.5秒。");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
/**
* 获取每一页图片的标题和链接
* */
private Picture extractPictureUrl(String html) {
Document doc = Jsoup.parse(html, "UTF-8");
//获取标题作为文件名
String title = doc.getElementsByTag("h3")
.first()
.text();
//获取图片的链接(img 标签的 src 属性)
String url = doc.getElementsByAttributeValue("class", "main-image")
.first()
.getElementsByTag("img")
.attr("src");
//获取图片的文件扩展名
title = title + url.substring(url.lastIndexOf("."));
return new Picture(title, url);
}
}Startup 클래스 BootStrap
여기에 크롤러 대기열이 있습니다. 결국 첫 번째 크롤링도 하지 못했습니다. 계산을 잘못해서 두 자릿수만큼 계산을 놓쳤기 때문입니다. 그러나 프로그램의 기능은 정확합니다.
package com.picture;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* 爬虫启动类
* */
public class BootStrap {
public static void main(String[] args) {
//反爬措施:UA、refer 简单绕过就行了。
//refer https://www.mzitu.com
//使用数组做一个爬虫队列
String[] urls = new String[] {
"https://www.mzitu.com/xinggan/",
"https://www.mzitu.com/zipai/"
};
// 添加初始队列,启动爬虫
List<String> urlList = new ArrayList<>(Arrays.asList(urls));
PictureSpider spider = new PictureSpider();
spider.start(urlList);
}
}크롤링 결과

Notes
여기에 계산 오류가 있습니다. 코드는 다음과 같습니다.
for (int i = 1; i <= 10; i++) { //分页获取图片数据,简单获取几页就行了
this.page(url + "page/"+ 1);
}계산에 실수를 해서 i 값이 너무 큽니다. 이 상황에 따라 다운로드하면 총 4*10*(30-5)*60=64800장의 사진이 다운로드됩니다. (각 페이지에는 30개의 제목 페이지가 포함되어 있으며 약 5개는 광고입니다.) 처음에는 사진이 몇백 장밖에 없는 줄 알았습니다! 이는 추정치이지만 실제 다운로드량은 이와 크게 다르지 않을 것입니다. (차수차이는 없습니다) 그래서 한동안 다운로드를 해보니 첫 번째 대기열의 사진만 다운로드되는 것을 발견했습니다. 물론 크롤러 학습 프로그램으로서는 여전히 자격을 갖추고 있습니다.
이 프로그램은 학습용으로 각 그림의 다운로드 간격을 1.5초로 설정했고, 단일 스레드 프로그램이므로 속도가 매우 느립니다. 그러나 그것은 중요하지 않습니다. 프로그램이 올바르게 작동하는 한 누구도 이미지가 다운로드될 때까지 기다리지 않을 것입니다.
오랜 시간이 소요될 것으로 예상됩니다: 64800*1.5s = 97200s = 27h. 이는 대략적인 추정일 뿐이며 프로그램의 다른 실행 시간을 고려하지 않지만 다른 시간은 기본적으로 무시할 수 있습니다.
위 내용은 Java 크롤러를 사용하여 이미지를 일괄적으로 크롤링하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7490
7490
 15
1377
52
77
11
52
19
19
41
15
1377
52
77
11
52
19
19
41


 Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기 안내. 여기서는 예제를 통해 Java의 함수와 예제를 통해 두 가지 다른 생성기에 대해 설명합니다.
 자바의 웨카
Aug 30, 2024 pm 04:28 PM
자바의 웨카
Aug 30, 2024 pm 04:28 PM
Java의 Weka 가이드. 여기에서는 소개, weka java 사용 방법, 플랫폼 유형 및 장점을 예제와 함께 설명합니다.
 Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 Smith Number 가이드. 여기서는 정의, Java에서 스미스 번호를 확인하는 방법에 대해 논의합니다. 코드 구현의 예.
 Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
이 기사에서는 가장 많이 묻는 Java Spring 면접 질문과 자세한 답변을 보관했습니다. 그래야 면접에 합격할 수 있습니다.
 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
 Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 TimeStamp to Date 안내. 여기서는 소개와 예제와 함께 Java에서 타임스탬프를 날짜로 변환하는 방법에 대해서도 설명합니다.
 미래를 창조하세요: 완전 초보자를 위한 Java 프로그래밍
Oct 13, 2024 pm 01:32 PM
미래를 창조하세요: 완전 초보자를 위한 Java 프로그래밍
Oct 13, 2024 pm 01:32 PM
Java는 초보자와 숙련된 개발자 모두가 배울 수 있는 인기 있는 프로그래밍 언어입니다. 이 튜토리얼은 기본 개념부터 시작하여 고급 주제를 통해 진행됩니다. Java Development Kit를 설치한 후 간단한 "Hello, World!" 프로그램을 작성하여 프로그래밍을 연습할 수 있습니다. 코드를 이해한 후 명령 프롬프트를 사용하여 프로그램을 컴파일하고 실행하면 "Hello, World!"가 콘솔에 출력됩니다. Java를 배우면 프로그래밍 여정이 시작되고, 숙달이 깊어짐에 따라 더 복잡한 애플리케이션을 만들 수 있습니다.
