

의사결정 트리에서 변환기까지 - 레스토랑 리뷰를 위한 감정 분석 모델 비교

Translator | Zhu Xianzhong
Reviewer | Popular
마케도니아 레스토랑 리뷰의 감정 분석을 위한 임베딩 기법의 효과, 여러 고전 작품을 탐색하고 비교합니다. 기계 학습 모델과 신경망 및 Transformers를 포함한 최신 딥 러닝 기술을 제공합니다. 실험은 최신 OpenAI 임베딩을 사용하여 미세 조정된 Transformers 모델과 딥 러닝 모델이 훨씬 다른 방법보다 뛰어난 성능을 발휘한다는 것을 보여줍니다. 자연어 처리를 위한 기계 학습 모델은 전통적으로 영어, 스페인어 등 인기 있는 언어 에 중점을 두었지만 하지만
은 그렇지 않습니다. 너무 일반적으로 사용되는 언어의 개발
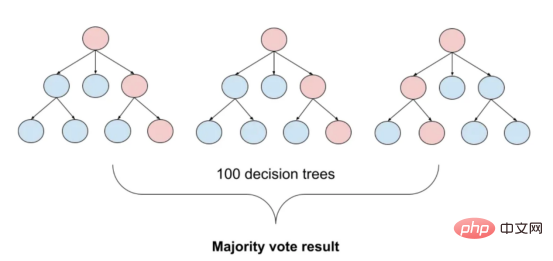
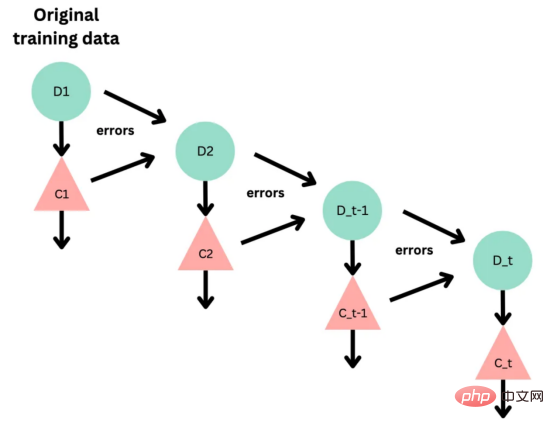
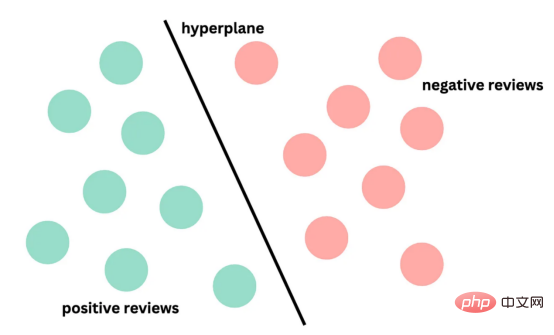
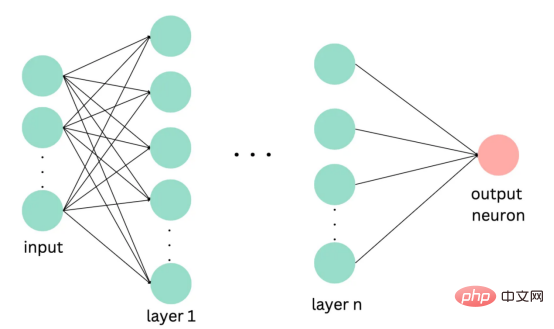
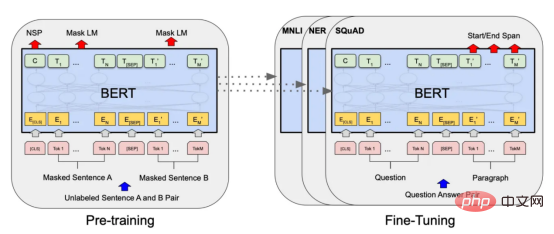
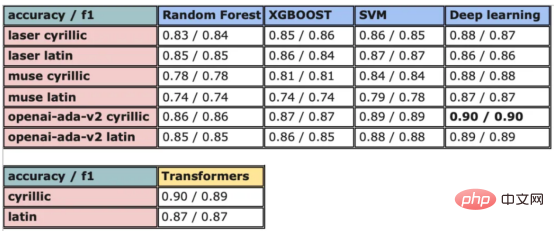
기계 학습 모델과 관련된 연구 및 적용이 훨씬 적습니다. 한편 코로나19 팬데믹으로 인해 전자상거래가 증가하면서 마케도니아어 등 흔하지 않은 언어들도 온라인 리뷰를 통해 대량의 데이터를 생성해냈습니다. 이는 마케도니아 레스토랑 리뷰의 감정 분석을 위한 기계 학습 모델을 개발하고 훈련 할 수 있는 기회를 제공하며, 성공할 경우 이는 기업이 고객 감정을 더 잘 이해하고 관련 서비스를 개선하는 데 도움이 될 수 있습니다. 본 연구에서는 이 문제로 인한 과제를 해결하고 마케도니아 레스토랑 리뷰의 감정을 분석하기 위한 다양한 감정 분석 모델을 탐색하고 비교합니다. 고전적인 랜덤 포레스트부터 현대적인 딥 러닝 기술 및 Transformersetc까지 . 우선, 이 기사의 내용에 대한 개요를 제공합니다: 언어는 인간의 의사소통을 위한 고유한 도구이며 적절한 처리 기술 없이는 컴퓨터로 해석할 수 없습니다. 기계가 언어를 분석하고 이해하려면 복잡한 의미 및 어휘 정보를 계산 가능한 방식으로 표현해야 합니다. 이를 달성하는 인기 있는 방법 중 하나는 벡터 표현을 사용하는 것입니다. 최근에는 언어별 표현 모델 외에도 다국어 모델이 등장했습니다. 이러한 모델은 광범위한 언어에 걸쳐 텍스트의 의미론적 컨텍스트를 캡처할 수 있습니다. 그러나 키릴 문자 (키릴 문자) 문자를 사용하는 언어의 경우 인터넷 사용자가 라틴어 문자를 사용하여 자신을 표현하는 경우가 많기 때문에 라틴어 문자와 키릴 문자가 혼합되어 있습니다. 데이터 ; 이로 인해 추가적인 문제가 발생합니다. 이 문제를 해결하기 위해 저는 라틴 문자와 키릴 문자가 모두 포함된 약 500개의 리뷰 - 가 있는 현지 레스토랑의 데이터 세트를 사용했습니다. 데이터 세트에는 하이브리드 데이터의 성능을 평가하는 데 도움이 되는 작은 영어 설명 세트도 포함되어 있습니다. 또한 온라인 텍스트에는 제거해야 할 이모티콘과 같은 기호가 포함될 수 있습니다. 따라서 전처리는 텍스트 임베딩을 수행하기 전에 중요한 단계입니다. 데이터 세트에 분포가 거의 동일한 양수 클래스와 음수 클래스가 포함되어 있음을 확인했습니다. 이모티콘을 제거하기 위해 저는 이모티콘과 기타 기호를 쉽게 제거할 수 있는 Python 라이브러리 이모티콘을 사용했습니다. figure 1 : 컨버전 출력의 결과 目前,没有大规模的马其顿语言描述模型可用。然而,我们可以使用基于马其顿语文本训练的多语言模型。当前,有几种这样的模型可用,但对于这项任务,我发现LASER和多语言通用句子编码器是最合适的选择。 LASER(Language-Agnostic Sentence Representations)是一种生成高质量多语言句子嵌入的语言不可知方法。LASER模型基于两阶段过程。其中,第一阶段是对文本进行预处理,包括标记化、小写和应用句子。这部分是特定于语言的;第二阶段涉及使用多层双向LSTM将预处理的输入文本映射到固定长度的嵌入。 在一系列基准数据集上,LASER已经被证明优于其他流行的句子嵌入方法,如fastText和InferSent。此外,LASER模型是开源的,免费提供,使每个人都可以轻松访问。 使用LASER创建嵌入是一个简单的过程: 多语言通用句子编码器(MUSE)是由Facebook开发的用于生成句子嵌入的预训练模型。MUSE旨在将多种语言的句子编码到一个公共空间中。 该模型基于深度神经网络,该网络使用“编码器-解码器”架构来学习句子与其在高维空间中的对应嵌入向量之间的映射。MUSE是在一个大规模的多语言语料库上训练的,其中包括维基百科的文本、新闻文章和网页。 2022年底,OpenAI宣布了他们全新的最先进嵌入模型text-embedding-ada-002(https://openai.com/blog/new-and-improved-embedding-model/)。由于此模型基于GPT-3构建,因此具有多语言处理能力。为了比较西里尔文和拉丁语评论的结果,我决定在两个数据集上运行了模型: 本节将探讨用于预测马其顿餐厅评论中情绪的各种机器学习模型。从传统的机器学习模型到深度学习技术,我们将研究每个模型的优缺点,并比较它们在数据集上的性能。 在运行任何模型之前,应该先对数据进行分割,以便针对每种嵌入类型进行训练和测试。这可以通过sklearn库轻松完成。 图2:随机森林分类的简化表示。构建100个决策树,并将结果作为每个决策树的结果之间的多数表决进行计算 随机森林是一种广泛使用的机器学习算法,它使用决策树集合对数据点进行分类。该算法通过在完整数据集的子集和特征的随机子集上训练每个决策树来工作。在推理过程中,每个决策树都会生成一个情绪预测,最终的结果是通过对所有树进行多数投票获得的。这种方法有助于防止过度拟合,并可导致更稳健和准确的预测结果。 图3:基于boosting算法的顺序过程。每个下一个决策树都基于上一个决策的残差(误差)进行训练 XGBoost(极限梯度增强)是一种强大的集成方法,主要用于表格数据。与随机森林算法模型一样,XGBoost也使用决策树对数据点进行分类,但方法不同。XGBoost不是一次训练所有树,而是以顺序的方式训练每棵树,从上一棵树所犯的错误中学习。这个过程被称为“增强”,这意味着将弱模型结合起来,形成一个更强的模型。虽然XGBoost主要使用表格数据产生了很好的结果,但使用向量嵌入测试该模型也会很有趣。 图4:支持向量分类的简化表示。在具有1024个输入特征的这种情绪分析的情况下,超平面将是1023维 支持向量机(SVM)是一种用于分类和回归任务的流行且强大的机器学习算法。它的工作原理是找到将数据分成不同类的最佳超平面,同时最大化类之间的边界。SVM对高维数据特别有用,可以使用核函数处理非线性边界。 图5:此问题中使用的神经网络的简化表示 深度学习是一种先进的机器学习方法,它利用由多层和神经元组成的人工神经网络。深度学习网络在文本和图像数据方面表现出色。使用Keras库实现这些网络是一个很简单的过程。 在此,使用了具有两个隐藏层和校正线性单元(ReLU)激活函数的神经网络。输出层包含一个具有S形激活函数的神经元,使网络能够对积极或消极情绪进行二元预测。二元交叉熵损失函数与S形激活配对以训练模型。此外,Dropout被用于帮助防止过度拟合和改进模型的泛化。我用各种不同的超参数进行了测试,发现这种配置最适合这个问题。 通过以下函数,我们可以可视化模型的训练。 图6:示例训练输出 图7:BERT大型语言模型的预训练和微调过程。(BERT原始论文地址:https://arxiv.org/pdf/1810.04805v2.pdf) 微调Transformers是自然语言处理中的一种流行技术,涉及调整预先训练的变换器模型以适应特定任务。Transformers,如BERT、GPT-2和RoBERTa,在大量文本数据上进行了预训练,能够学习语言中的复杂模式和关系。然而,为了在特定任务(如情绪分析或文本分类)上表现良好,需要根据任务特定数据对这些模型进行微调。 对于这些类型的模型,不需要我们之前创建的向量表示,因为它们直接处理标记(直接从文本中提取)。在马其顿语的情绪分析任务中,我使用了bert-base-multilingual-uncased,这是BERT模型的多语言版本。 HuggingFace使微调Transformers成为一项非常简单的任务。首先,需要将数据加载到Transformers数据集中。然后将文本标记化,最后训练模型。 因此,我们成功地调整了BERT进行情绪分析。 图8:所有模型的结果大对比 实验证明,马其顿餐厅评论的情绪分析结果是很有希望的,从上图中可见,其中有几个模型获得了很高的准确性和F1分数。实验表明,深度学习模型和变换器的性能优于传统的机器学习模型,如随机森林和支持向量机,尽管相差不大。使用新OpenAI嵌入的Transformers和深度神经网络成功打破了0.9精度的障碍。 OpenAI嵌入模型textembedding-ada-002成功地极大提高了从经典ML模型获得的结果,尤其是在支持向量机上。本研究中的最佳结果是在深度学习模型上嵌入西里尔文文本。 一般来说,拉丁语文本的表现比西里尔语文本差。尽管我最初假设这些模型的性能会更好,但考虑到拉丁语中类似单词在其他斯拉夫语言中的流行,以及嵌入模型是基于这些数据训练的事实,这些发现并不支持这一假设。 향후 작업에서는 특히 검토 주제와 소스가 더 다양한 경우 모델을 추가로 훈련하고 테스트하기 위해 더 많은 데이터를 수집하는 것이 매우 중요할 것입니다. 또한 메타데이터(예: 리뷰어의 연령, 성별, 위치) 또는 시간 정보(예: 리뷰 시간)와 같은 더 많은 기능을 모델에 통합하려고 하면 정확도가 향상될 수 있습니다. 마지막으로, 덜 일반적으로 사용되는 다른 언어로 분석을 확장하고 모델의 성능을 마케도니아 리뷰에서 훈련된 모델과 비교하는 것이 흥미로울 것입니다. 결론 머신러닝 모델과 임베딩 기술의 효율성을 보여줍니다. 랜덤 포레스트 및 SVM과 같은 여러 가지 고전적인 기계 학습 모델은 물론 신경망 및 Transformers를 포함한 최신 딥 러닝 기술을 탐색하고 비교합니다. 결과는 최신 OpenAI 임베딩을 사용하여 미세 조정된 Transformers 모델과 딥 러닝 모델이 90%의 높은 검증 정확도로 다른 방법보다 성능이 우수하다는 것을 보여줍니다. 번역가 소개 원제: 결정 트리에서 변환기까지: 마케도니아 레스토랑 리뷰를 위한 감정 분석 모델 비교, 저자: Danilo Najkov
데이터 전처리
import pandas as pd
import numpy as np
#把数据集加载进一个dataframe
df = pd.read_csv('/content/data.tsv', sep='t')
# 注意sentiment类别的分布情况
df['sentiment'].value_counts()
# -------
# 0 337
# 1 322
# Name: sentiment, dtype: int64!pip install emoji
import emoji
clt = []
for comm in df['comment'].to_numpy():
clt.append(emoji.replace_emoji(comm, replace=""))
df['comment'] = clt
df.head()
import cyrtranslit
latin = []
cyrillic = []
for comm in df['comment'].to_numpy():
latin.append(cyrtranslit.to_latin(comm, "mk"))
cyrillic.append(cyrtranslit.to_cyrillic(comm, "mk"))
df['comment_cyrillic'] = cyrillic
df['comment_latin'] = latin
df.head()
矢量嵌入
LASER
!pip install laserembeddings
!python -m laserembeddings download-models
from laserembeddings import Laser
#创建嵌入
laser = Laser()
embeddings_c = laser.embed_sentences(df['comment_cyrillic'].to_numpy(),lang='mk')
embeddings_l = laser.embed_sentences(df['comment_latin'].to_numpy(),lang='mk')
# 保存嵌入
np.save('/content/laser_multi_c.npy', embeddings_c)
np.save('/content/laser_multi_l.npy', embeddings_l)多语言通用句子编码器
!pip install tensorflow_text
import tensorflow as tf
import tensorflow_hub as hub
import numpy as np
import tensorflow_text
#加载MUSE模型
module_url = "https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3"
embed = hub.load(module_url)
sentences = df['comment_cyrillic'].to_numpy()
muse_c = embed(sentences)
muse_c = np.array(muse_c)
sentences = df['comment_latin'].to_numpy()
muse_l = embed(sentences)
muse_l = np.array(muse_l)
np.save('/content/muse_c.npy', muse_c)
np.save('/content/muse_l.npy', muse_l)OpenAI Ada v2
!pip install openai
import openai
openai.api_key = 'YOUR_KEY_HERE'
embeds_c = openai.Embedding.create(input = df['comment_cyrillic'].to_numpy().tolist(), model='text-embedding-ada-002')['data']
embeds_l = openai.Embedding.create(input = df['comment_latin'].to_numpy().tolist(), model='text-embedding-ada-002')['data']
full_arr_c = []
for e in embeds_c:
full_arr_c.append(e['embedding'])
full_arr_c = np.array(full_arr_c)
full_arr_l = []
for e in embeds_l:
full_arr_l.append(e['embedding'])
full_arr_l = np.array(full_arr_l)
np.save('/content/openai_ada_c.npy', full_arr_c)
np.save('/content/openai_ada_l.npy', full_arr_l)机器学习模型
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(embeddings_c, df['sentiment'], test_size=0.2, random_state=42)
随机森林
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
rfc = RandomForestClassifier(n_estimators=100)
rfc.fit(X_train, y_train)
print(classification_report(y_test,rfc.predict(X_test)))
print(confusion_matrix(y_test,rfc.predict(X_test)))
XGBoost
from xgboost import XGBClassifier
from sklearn.metrics import classification_report, confusion_matrix
rfc = XGBClassifier(max_depth=15)
rfc.fit(X_train, y_train)
print(classification_report(y_test,rfc.predict(X_test)))
print(confusion_matrix(y_test,rfc.predict(X_test)))
支持向量机
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix
rfc = SVC()
rfc.fit(X_train, y_train)
print(classification_report(y_test,rfc.predict(X_test)))
print(confusion_matrix(y_test,rfc.predict(X_test)))
深度学习
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
model = keras.Sequential()
model.add(keras.layers.Dense(256, activatinotallow='relu', input_shape=(1024,)))
model.add(keras.layers.Dropout(0.2))
model.add(keras.layers.Dense(128, activatinotallow='relu'))
model.add(keras.layers.Dense(1, activatinotallow='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=11, validation_data=(X_test, y_test))
test_loss, test_acc = model.evaluate(X_test, y_test)
print('Test accuracy:', test_acc)
y_pred = model.predict(X_test)
print(classification_report(y_test,y_pred.round()))
print(confusion_matrix(y_test,y_pred.round()))import matplotlib.pyplot as plt
def plot_accuracy(history):
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()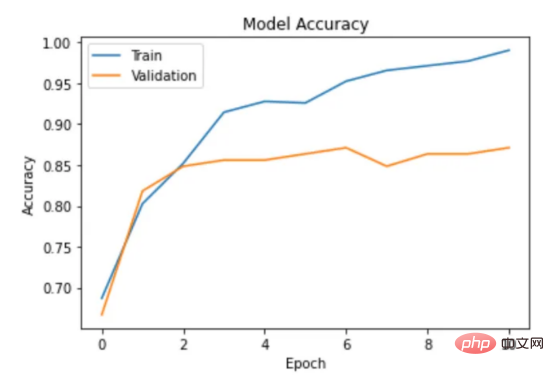
Transformers
from sklearn.model_selection import train_test_split
from datasets import load_dataset
from transformers import TrainingArguments, Trainer
from sklearn.metrics import classification_report, confusion_matrix
# 创建由数据集加载的训练和测试集的csv文件
df.rename(columns={"sentiment": "label"}, inplace=True)
train, test = train_test_split(df, test_size=0.2)
pd.DataFrame(train).to_csv('train.csv',index=False)
pd.DataFrame(test).to_csv('test.csv',index=False)
#加载数据集
dataset = load_dataset("csv", data_files={"train": "train.csv", "test": "test.csv"})
# 标记文本
tokenizer = AutoTokenizer.from_pretrained('bert-base-multilingual-uncased')
encoded_dataset = dataset.map(lambda t: tokenizer(t['comment_cyrillic'], truncatinotallow=True), batched=True,load_from_cache_file=False)
# 加载预训练的模型
model = AutoModelForSequenceClassification.from_pretrained('bert-base-multilingual-uncased',num_labels =2)
#微调模型
arg = TrainingArguments(
"mbert-sentiment-mk",
learning_rate=5e-5,
num_train_epochs=5,
per_device_eval_batch_size=8,
per_device_train_batch_size=8,
seed=42,
push_to_hub=True
)
trainer = Trainer(
model=model,
args=arg,
tokenizer=tokenizer,
train_dataset=encoded_dataset['train'],
eval_dataset=encoded_dataset['test']
)
trainer.train()
# 取得预测结果
predictions = trainer.predict(encoded_dataset["test"])
preds = np.argmax(predictions.predictions, axis=-1)
# 评估
print(classification_report(predictions.label_ids,preds))
print(confusion_matrix(predictions.label_ids,preds))实验结果与讨论
향후 작업
위 내용은 의사결정 트리에서 변환기까지 - 레스토랑 리뷰를 위한 감정 분석 모델 비교의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7442
7442
 15
1371
52
76
11
38
19
9
6
15
1371
52
76
11
38
19
9
6

 Bytedance Cutting, SVIP 슈퍼 멤버십 출시: 연간 연속 구독료 499위안, 다양한 AI 기능 제공
Jun 28, 2024 am 03:51 AM
Bytedance Cutting, SVIP 슈퍼 멤버십 출시: 연간 연속 구독료 499위안, 다양한 AI 기능 제공
Jun 28, 2024 am 03:51 AM
이 사이트는 6월 27일에 Jianying이 ByteDance의 자회사인 FaceMeng Technology에서 개발한 비디오 편집 소프트웨어라고 보도했습니다. 이 소프트웨어는 Douyin 플랫폼을 기반으로 하며 기본적으로 플랫폼 사용자를 위한 짧은 비디오 콘텐츠를 제작합니다. Windows, MacOS 및 기타 운영 체제. Jianying은 멤버십 시스템 업그레이드를 공식 발표하고 지능형 번역, 지능형 하이라이트, 지능형 패키징, 디지털 인간 합성 등 다양한 AI 블랙 기술을 포함하는 새로운 SVIP를 출시했습니다. 가격면에서 SVIP 클리핑 월 요금은 79위안, 연간 요금은 599위안(본 사이트 참고: 월 49.9위안에 해당), 월간 연속 구독료는 월 59위안, 연간 연속 구독료는 59위안입니다. 연간 499위안(월 41.6위안)입니다. 또한, 컷 관계자는 "사용자 경험 향상을 위해 기존 VIP에 가입하신 분들도
 Rag 및 Sem-Rag를 사용한 상황 증강 AI 코딩 도우미
Jun 10, 2024 am 11:08 AM
Rag 및 Sem-Rag를 사용한 상황 증강 AI 코딩 도우미
Jun 10, 2024 am 11:08 AM
검색 강화 생성 및 의미론적 메모리를 AI 코딩 도우미에 통합하여 개발자 생산성, 효율성 및 정확성을 향상시킵니다. EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG에서 번역됨, 저자 JanakiramMSV. 기본 AI 프로그래밍 도우미는 자연스럽게 도움이 되지만, 소프트웨어 언어에 대한 일반적인 이해와 소프트웨어 작성의 가장 일반적인 패턴에 의존하기 때문에 가장 관련성이 높고 정확한 코드 제안을 제공하지 못하는 경우가 많습니다. 이러한 코딩 도우미가 생성한 코드는 자신이 해결해야 할 문제를 해결하는 데 적합하지만 개별 팀의 코딩 표준, 규칙 및 스타일을 따르지 않는 경우가 많습니다. 이로 인해 코드가 애플리케이션에 승인되기 위해 수정되거나 개선되어야 하는 제안이 나타나는 경우가 많습니다.
 7가지 멋진 GenAI 및 LLM 기술 인터뷰 질문
Jun 07, 2024 am 10:06 AM
7가지 멋진 GenAI 및 LLM 기술 인터뷰 질문
Jun 07, 2024 am 10:06 AM
AIGC에 대해 자세히 알아보려면 다음을 방문하세요. 51CTOAI.x 커뮤니티 https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou는 인터넷 어디에서나 볼 수 있는 전통적인 문제 은행과 다릅니다. 고정관념에서 벗어나 생각해야 합니다. LLM(대형 언어 모델)은 데이터 과학, 생성 인공 지능(GenAI) 및 인공 지능 분야에서 점점 더 중요해지고 있습니다. 이러한 복잡한 알고리즘은 인간의 기술을 향상시키고 많은 산업 분야에서 효율성과 혁신을 촉진하여 기업이 경쟁력을 유지하는 데 핵심이 됩니다. LLM은 자연어 처리, 텍스트 생성, 음성 인식 및 추천 시스템과 같은 분야에서 광범위하게 사용될 수 있습니다. LLM은 대량의 데이터로부터 학습하여 텍스트를 생성할 수 있습니다.
 미세 조정을 통해 LLM이 실제로 새로운 것을 배울 수 있습니까? 새로운 지식을 도입하면 모델이 더 많은 환각을 생성할 수 있습니다.
Jun 11, 2024 pm 03:57 PM
미세 조정을 통해 LLM이 실제로 새로운 것을 배울 수 있습니까? 새로운 지식을 도입하면 모델이 더 많은 환각을 생성할 수 있습니다.
Jun 11, 2024 pm 03:57 PM
LLM(대형 언어 모델)은 대규모 텍스트 데이터베이스에서 훈련되어 대량의 실제 지식을 습득합니다. 이 지식은 매개변수에 내장되어 필요할 때 사용할 수 있습니다. 이러한 모델에 대한 지식은 훈련이 끝나면 "구체화"됩니다. 사전 훈련이 끝나면 모델은 실제로 학습을 중단합니다. 모델을 정렬하거나 미세 조정하여 이 지식을 활용하고 사용자 질문에 보다 자연스럽게 응답하는 방법을 알아보세요. 그러나 때로는 모델 지식만으로는 충분하지 않을 때도 있으며, 모델이 RAG를 통해 외부 콘텐츠에 접근할 수 있더라도 미세 조정을 통해 모델을 새로운 도메인에 적응시키는 것이 유익한 것으로 간주됩니다. 이러한 미세 조정은 인간 주석 작성자 또는 기타 LLM 생성자의 입력을 사용하여 수행됩니다. 여기서 모델은 추가적인 실제 지식을 접하고 이를 통합합니다.
 대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
편집자 |ScienceAI 질문 응답(QA) 데이터 세트는 자연어 처리(NLP) 연구를 촉진하는 데 중요한 역할을 합니다. 고품질 QA 데이터 세트는 모델을 미세 조정하는 데 사용될 수 있을 뿐만 아니라 LLM(대형 언어 모델)의 기능, 특히 과학적 지식을 이해하고 추론하는 능력을 효과적으로 평가하는 데에도 사용할 수 있습니다. 현재 의학, 화학, 생물학 및 기타 분야를 포괄하는 과학적인 QA 데이터 세트가 많이 있지만 이러한 데이터 세트에는 여전히 몇 가지 단점이 있습니다. 첫째, 데이터 형식이 비교적 단순하고 대부분이 객관식 질문이므로 평가하기 쉽지만 모델의 답변 선택 범위가 제한되고 모델의 과학적 질문 답변 능력을 완전히 테스트할 수 없습니다. 이에 비해 개방형 Q&A는
 당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
머신 러닝은 명시적으로 프로그래밍하지 않고도 컴퓨터가 데이터로부터 학습하고 능력을 향상시킬 수 있는 능력을 제공하는 인공 지능의 중요한 분야입니다. 머신러닝은 이미지 인식, 자연어 처리, 추천 시스템, 사기 탐지 등 다양한 분야에서 폭넓게 활용되며 우리의 삶의 방식을 변화시키고 있습니다. 기계 학습 분야에는 다양한 방법과 이론이 있으며, 그 중 가장 영향력 있는 5가지 방법을 "기계 학습의 5개 학교"라고 합니다. 5개 주요 학파는 상징학파, 연결주의 학파, 진화학파, 베이지안 학파, 유추학파이다. 1. 상징주의라고도 알려진 상징주의는 논리적 추론과 지식 표현을 위해 상징을 사용하는 것을 강조합니다. 이 사고 학교는 학습이 기존을 통한 역연역 과정이라고 믿습니다.
 SOTA 성능, 샤먼 다중 모드 단백질-리간드 친화성 예측 AI 방법, 최초로 분자 표면 정보 결합
Jul 17, 2024 pm 06:37 PM
SOTA 성능, 샤먼 다중 모드 단백질-리간드 친화성 예측 AI 방법, 최초로 분자 표면 정보 결합
Jul 17, 2024 pm 06:37 PM
Editor | KX 약물 연구 및 개발 분야에서 단백질과 리간드의 결합 친화도를 정확하고 효과적으로 예측하는 것은 약물 스크리닝 및 최적화에 매우 중요합니다. 그러나 현재 연구에서는 단백질-리간드 상호작용에서 분자 표면 정보의 중요한 역할을 고려하지 않습니다. 이를 기반으로 Xiamen University의 연구자들은 처음으로 단백질 표면, 3D 구조 및 서열에 대한 정보를 결합하고 교차 주의 메커니즘을 사용하여 다양한 양식 특징을 비교하는 새로운 다중 모드 특징 추출(MFE) 프레임워크를 제안했습니다. 조정. 실험 결과는 이 방법이 단백질-리간드 결합 친화도를 예측하는 데 있어 최첨단 성능을 달성한다는 것을 보여줍니다. 또한 절제 연구는 이 프레임워크 내에서 단백질 표면 정보와 다중 모드 기능 정렬의 효율성과 필요성을 보여줍니다. 관련 연구는 "S"로 시작된다
 단백질과 모든 살아있는 분자의 상호 작용과 구조를 이전보다 훨씬 더 정확하게 예측하는 AlphaFold 3 출시
Jul 16, 2024 am 12:08 AM
단백질과 모든 살아있는 분자의 상호 작용과 구조를 이전보다 훨씬 더 정확하게 예측하는 AlphaFold 3 출시
Jul 16, 2024 am 12:08 AM
Editor | Radish Skin 2021년 강력한 AlphaFold2가 출시된 이후 과학자들은 단백질 구조 예측 모델을 사용하여 세포 내 다양한 단백질 구조를 매핑하고 약물을 발견하며 알려진 모든 단백질 상호 작용에 대한 "우주 지도"를 그려 왔습니다. 방금 Google DeepMind는 단백질, 핵산, 소분자, 이온 및 변형된 잔기를 포함한 복합체에 대한 결합 구조 예측을 수행할 수 있는 AlphaFold3 모델을 출시했습니다. AlphaFold3의 정확도는 과거의 많은 전용 도구(단백질-리간드 상호작용, 단백질-핵산 상호작용, 항체-항원 예측)에 비해 크게 향상되었습니다. 이는 단일 통합 딥러닝 프레임워크 내에서 다음을 달성할 수 있음을 보여줍니다.
