
매개변수화된 양자 회로를 기반으로 하는 기계 학습 알고리즘은 시끄러운 양자 컴퓨터의 단기 응용을 위한 주요 후보입니다. 이러한 방향으로 다양한 유형의 양자 기계 학습 모델이 도입되고 광범위하게 연구되었습니다. 그러나 이러한 모델을 서로 비교하고 기존 모델과 비교하는 방법에 대한 우리의 이해는 여전히 제한적입니다.
최근 오스트리아 인스브루크 대학교 연구팀은 매개변수화된 양자 회로를 기반으로 모든 표준 모델을 포착하는 구성적 프레임워크인 선형 양자 모델을 식별했습니다.
연구원들은 양자 정보 이론의 도구를 사용하여 데이터 재업로드 회로를 양자 힐베르트 공간에서 선형 모델의 간단한 그림으로 효율적으로 매핑하는 방법을 보여줍니다. 또한 이러한 모델의 실험적으로 관련된 리소스 요구 사항은 큐비트 수와 학습해야 하는 데이터 양 측면에서 분석됩니다. 고전적인 기계 학습을 기반으로 한 최근 결과는 선형 양자 모델이 특정 학습 작업을 해결하기 위해 데이터 재업로드 모델보다 더 많은 큐비트를 사용해야 하는 반면 커널 방법에는 더 많은 데이터 포인트가 필요하다는 것을 보여줍니다. 결과는 양자 기계 학습 모델에 대한 보다 포괄적인 이해뿐만 아니라 NISQ 제약 조건이 있는 다양한 모델의 호환성에 대한 통찰력을 제공합니다.
연구 제목은 "커널 방법을 넘어서는 양자 기계 학습"이며 2023년 1월 31일 "Nature Communications"에 게재되었습니다.
문서 링크: https://www.nature.co m/articles/s41467-023-36159-y
중간양자(NISQ) 시대에는 약간의 하드웨어 제약 조건과 호환되는 유용한 양자 알고리즘을 구축하기 위한 여러 가지 방법이 제안되었습니다. 이러한 방법의 대부분은 특정 계산 작업을 해결하기 위해 고전적인 방식으로 최적화된 Ansatz 양자 회로의 사양을 포함합니다. 화학 분야의 변형 양자 서명 솔버 및 변형된 양자 근사 최적화 알고리즘 외에도 이러한 매개변수화된 양자 회로를 기반으로 하는 기계 학습 방법은 양자 이점을 생성하기 위한 가장 유망한 실제 응용 프로그램 중 하나입니다.
커널 방법은 패턴 인식 알고리즘의 한 유형입니다. 그 목적은 일련의 데이터에서 상호 관계를 찾고 학습하는 것입니다. 커널 방법은 비선형 패턴 분석 문제를 해결하는 효과적인 방법입니다. 핵심 아이디어는 먼저 일부 비선형 매핑을 통해 원본 데이터를 적절한 고차원 특징 공간에 삽입한 다음 일반 선형 학습기를 사용하여 새로운 분석 모드를 사용하는 것입니다. 그리고 우주에서의 처리.
이전 작업에서는 일부 양자 모델과 고전 기계 학습의 커널 방법 간의 연결을 활용하여 이 방향으로 큰 진전을 이루었습니다. 실제로 많은 양자 모델은 고차원 힐베르트 공간에서 데이터를 인코딩하고 이 특징 공간에서 평가된 내부 곱만 사용하여 데이터의 속성을 모델링함으로써 작동합니다. 이것은 또한 핵 방법이 작동하는 방식입니다.
이 유사성을 기반으로 특정 양자 인코딩을 사용하여 두 가지 유형의 모델을 정의할 수 있습니다. (a) 인코딩 데이터 포인트가 해당 레이블을 지정하는 변형 관측 가능 항목에 따라 측정되는 명시적 양자 모델 또는 (b) 인코딩된 데이터 포인트의 가중치 내적을 사용하여 레이블을 할당하는 암시적 커널 모델. 양자 기계 학습 문헌에서는 암시적 모델을 많이 강조합니다.
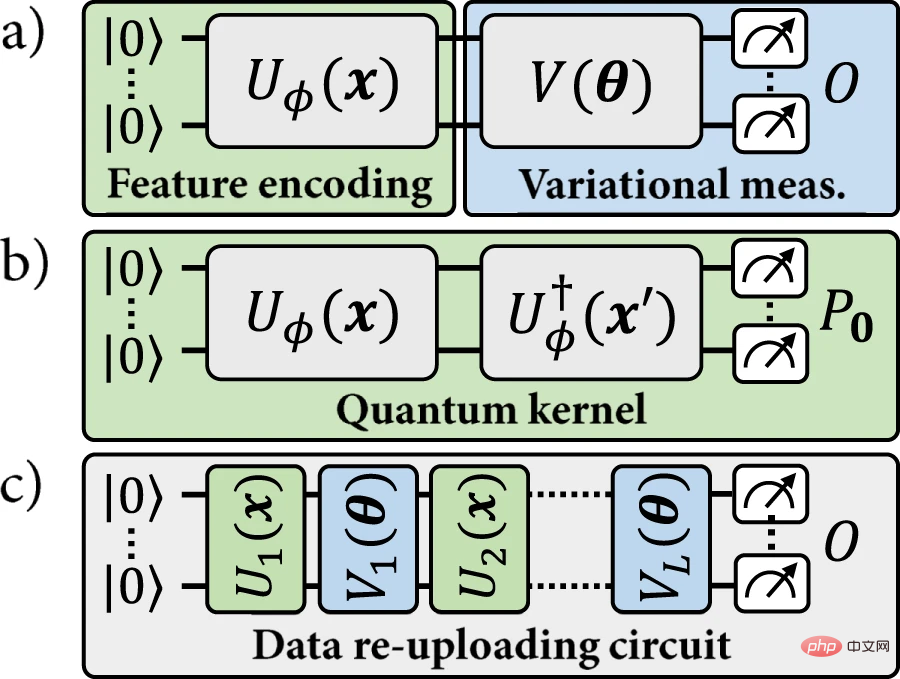
그림 1: 이 작업에서 연구한 양자 기계 학습 모델. (출처: 논문)
최근에는 소위 데이터 재업로드 모델이 발전하고 있습니다. 데이터 재업로드 모델은 명시적 모델의 일반화라고 볼 수 있습니다. 그러나 이 일반화는 주어진 데이터 포인트 x가 더 이상 고정된 인코딩 포인트 ρ(x)에 해당하지 않기 때문에 암시적 모델과의 일치성을 깨뜨립니다. 데이터 재업로드 모델은 명시적 모델보다 훨씬 더 일반적이며 커널 모델 패러다임과 호환되지 않습니다. 지금까지는 커널 방법을 보장하는 데이터 재업로드 모델에서 일부 이점을 얻을 수 있는지 여부에 대한 공개적인 질문이 남아 있습니다.
이 연구에서 연구자들은 명시적, 암시적 및 데이터 재업로드 양자 모델을 위한 통합 프레임워크를 도입합니다.
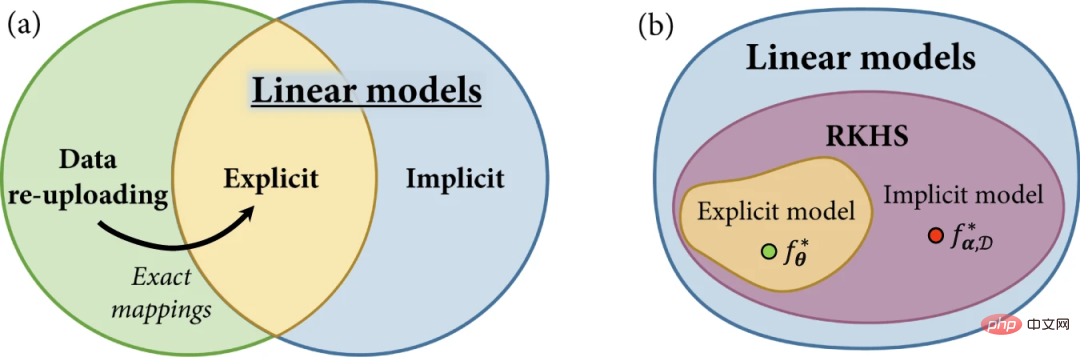
그림 2: 양자 기계 학습의 모델 계열. (출처: 논문)
선형 양자 모델의 개념을 검토하고 양자 특징 공간에 정의된 선형 모델 측면에서 명시적 모델과 암시적 모델을 설명하는 것부터 시작하세요. 그런 다음 데이터 재업로드 모델이 명시적 모델의 일반화로 정의되었지만 더 큰 힐베르트 공간에서 선형 모델로 구현될 수도 있음을 제시하고 보여줍니다.
아래 그림은 데이터 재업로드에서 명시적 모델로의 매핑이 어떻게 달성되는지 시각적으로 설명하는 예시적인 구조를 제공합니다.
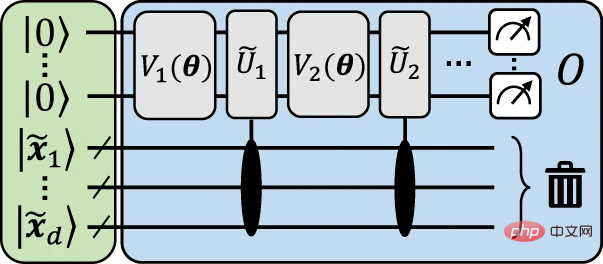
그림 3: 데이터 재업로드 회로를 근사하는 명시적 모델 예시. (출처: Paper)
이 구조의 일반적인 아이디어는 입력 데이터를 인코딩하는 것입니다.
이제 기본 구조로 이동하여 데이터를 다시 업로드하고 명시적 모델 간의 정확한 매핑을 수행합니다. 여기서는 이전 구조와 유사한 아이디어를 사용하여 입력 데이터가 보조 큐비트에 인코딩된 다음 데이터 독립적인 작업을 사용하여 작업 큐비트에 인코딩 게이트가 구현됩니다. 여기서 차이점은 측정 기반 양자 컴퓨팅의 일종인 게이트 순간이동을 사용하여 인코딩 게이트를 보조 큐비트에 직접 구현하고 필요할 때 작동 큐비트로 다시 순간이동(얽힘 측정을 통해)한다는 것입니다.
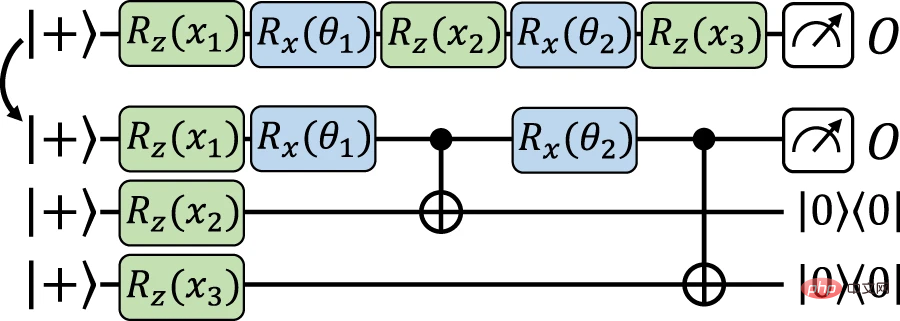
그림 4: 게이트 순간 이동을 사용하여 데이터 재업로드 모델에서 동등한 명시적 모델로의 정확한 매핑. (출처: 논문)
연구원들은 선형 양자 모델이 명시적 및 암시적 모델뿐만 아니라 데이터 재업로드 회로도 설명할 수 있음을 입증했습니다. 더 구체적으로 말하면, 데이터 재업로드 모델의 모든 가설 클래스는 동등한 클래스의 명시적 모델, 즉 제한된 관측 가능 항목이 있는 선형 모델에 매핑될 수 있습니다.
다음으로 연구원들은 암시적 모델에 비해 명시적 모델과 데이터 재업로드 모델의 장점을 더욱 엄격하게 분석했습니다. 이 예에서 학습 작업을 해결하는 양자 모델의 효율성은 적지 않은 예상 손실을 달성하는 데 필요한 큐비트 수와 훈련 세트 크기로 정량화됩니다. 관심 있는 학습 과제는 홀수 함수와 짝수 함수를 학습하는 것입니다.
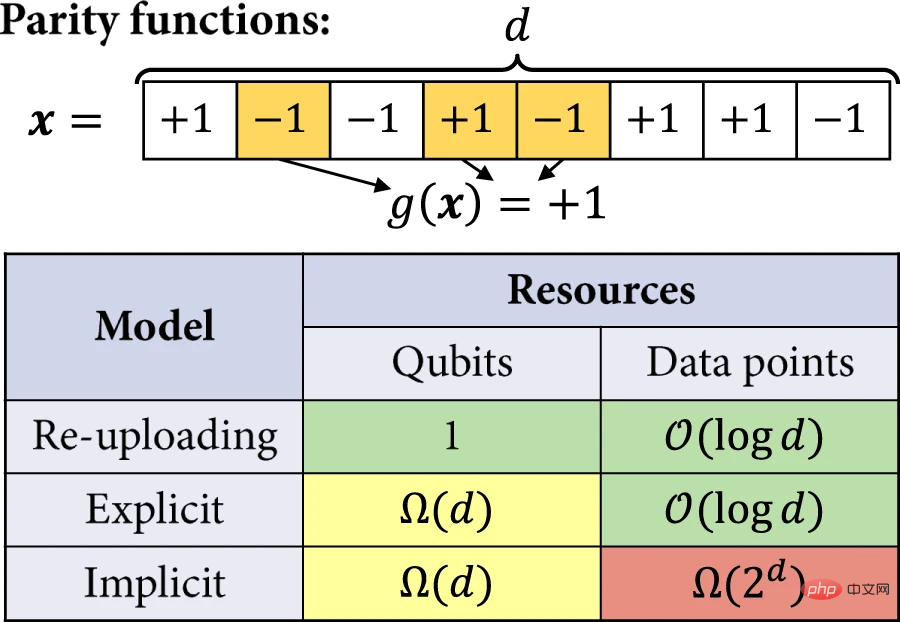
그림 5: 분리 학습. (출처: 논문)
양자 기계 학습의 주요 과제는 이 작업에서 논의된 양자 방법이 (표준) 고전 방법에 비해 학습 이점을 달성할 수 있음을 보여주는 것입니다.
이 연구에서는 Google Quantum Artificial Intelligence의 Huang et al. ) 목적 함수 자체가 (명시적) 양자 모델에 의해 생성되는 학습 작업을 연구하는 것이 좋습니다.
Huang 외 연구진과 마찬가지로 연구원들은 fashion-MNIST 데이터세트의 입력 데이터를 사용하여 회귀 작업을 수행했습니다. 여기서 각 예는 28x28 회색조 이미지였습니다.
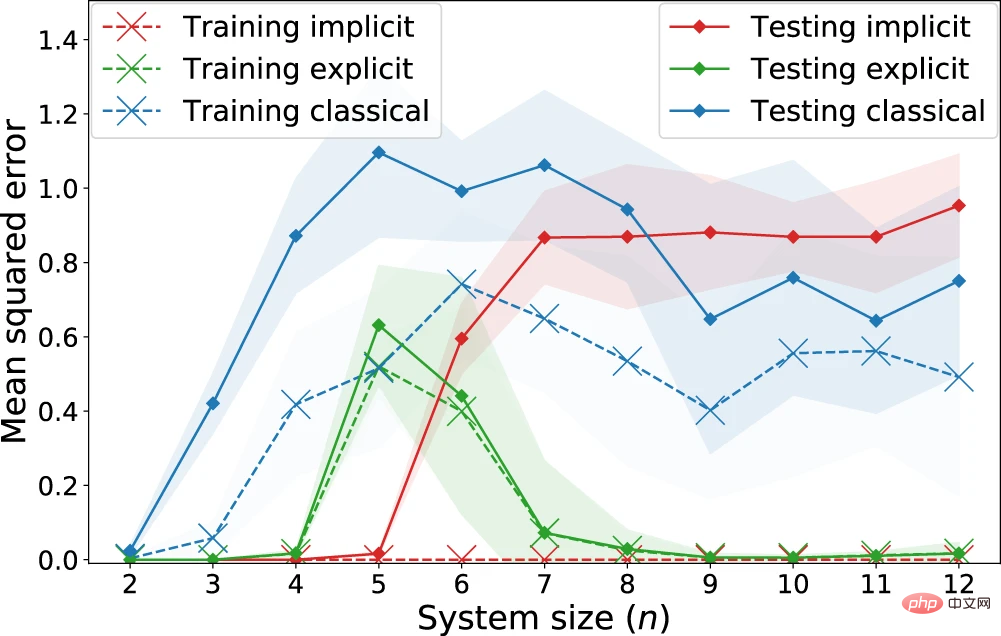
그림 6: "양자 맞춤화" 학습 작업에 대한 명시적, 암시적 및 고전적 모델의 회귀 성능. (출처: 논문)
관찰: 암시적 모델은 명시적 모델보다 체계적으로 더 낮은 훈련 손실을 달성합니다. 특히 비정규화된 손실의 경우 암시적 모델은 훈련 손실 0을 달성합니다. 반면, 예상 손실을 나타내는 테스트 손실과 관련하여 n = 7 큐비트부터 명확한 분리가 있습니다. 여기서 고전 모델은 암시적 모델과 경쟁적인 성능을 갖기 시작하는 반면 명시적 모델은 둘 다 확실히 능가합니다. . 이는 명시적(또는 데이터 재업로드) 모델이 더 나은 학습 성능을 숨길 수도 있으므로 고전 모델과 양자 커널 방법을 비교하는 것만으로는 양자 이점의 존재를 평가해서는 안 된다는 것을 의미합니다.
이러한 결과는 양자 기계 학습 분야에 대한 보다 포괄적인 이해를 제공하고 NISQ 메커니즘에서 실질적인 학습 이점을 달성하기 위한 모델 유형에 대한 시야를 넓힙니다.
연구원들은 서로 다른 양자 모델 사이의 지수적 학습 분리의 존재를 증명하는 학습 작업이 홀수 함수와 짝수 함수에 기반을 두고 있다고 믿습니다. 이는 기계 학습에서 실질적인 관심을 끄는 개념적 클래스가 아닙니다. 그러나 하한 결과는 대규모 개념 클래스(즉, 많은 직교 함수로 구성)를 사용하여 다른 학습 작업으로 확장될 수도 있습니다.
양자 커널 방법에는 반드시 이 차원에 따라 선형적으로 확장되는 많은 데이터 포인트가 필요하며, 결과에서 볼 수 있듯이 데이터 재업로드 회로의 유연성과 명시적 모델의 제한된 표현 기능은 상당한 리소스를 절약합니다. 이러한 모델을 당면한 기계 학습 작업에 맞게 조정할 수 있는 방법과 시기를 탐색하는 것은 여전히 흥미로운 연구 방향입니다.
위 내용은 커널 방식을 뛰어넘는 양자 머신러닝, 양자 학습 모델을 위한 통합 프레임워크의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



