
2012년 Hinton et al.은 "특징 탐지기의 공동 적응을 방지하여 신경망 개선"이라는 논문에서 드롭아웃을 제안했습니다. 같은 해 AlexNet의 등장으로 딥러닝의 새로운 시대가 열렸습니다. AlexNet은 드롭아웃을 사용하여 과적합을 크게 줄이고 ILSVRC 2012 대회에서 승리하는 데 핵심적인 역할을 했습니다. 중퇴가 없었다면 현재 우리가 보고 있는 딥 러닝의 발전은 몇 년 정도 지연되었을 수도 있습니다.
드롭아웃이 출시된 이후 신경망의 과적합을 줄이기 위한 정규화 도구로 널리 사용되었습니다. 드롭아웃은 확률 p로 각 뉴런을 비활성화하여 서로 다른 기능이 서로 적응하는 것을 방지합니다. 드롭아웃을 적용한 후에는 일반적으로 훈련 손실이 증가하고 테스트 오류가 감소하여 모델의 일반화 격차가 줄어듭니다. 딥러닝의 발전은 계속해서 새로운 기술과 아키텍처를 도입하지만, 드롭아웃은 여전히 존재합니다. AlphaFold 단백질 예측, DALL-E 2 이미지 생성 등 최신 AI 성과에서 계속해서 역할을 수행하여 다양성과 효율성을 입증하고 있습니다.
드롭아웃의 지속적인 인기에도 불구하고 그 강도(드롭률 p로 표시)는 해가 갈수록 감소하고 있습니다. 초기 드롭아웃 노력에서는 기본 드롭률 0.5를 사용했습니다. 그러나 최근에는 0.1과 같이 더 낮은 드랍률이 사용되는 경우가 많습니다. 관련 예는 BERT 및 ViT 교육에서 볼 수 있습니다. 이러한 추세의 주요 동인은 사용 가능한 훈련 데이터가 폭발적으로 증가하여 과적합이 점점 더 어려워지고 있다는 것입니다. 다른 요인과 결합하면 과적합 문제보다 과소적합 문제가 더 많이 발생할 수 있습니다.
최근 "Dropout Reduces Underfitting"이라는 논문에서 Meta AI, University of California, Berkeley 및 기타 기관의 연구자들은 드롭아웃을 사용하여 과소적합 문제를 해결하는 방법을 시연했습니다.
논문 주소: https://arxiv.org/abs/2303.01500
그들은 먼저 경사 표준에 대한 흥미로운 관찰을 통해 중퇴의 훈련 역학을 연구한 후 주요 경험적 발견을 도출했습니다. 학습 초기 단계에서 드롭아웃은 미니 배치의 기울기 분산을 줄이고 모델이 보다 일관된 방향으로 업데이트되도록 합니다. 또한 이러한 방향은 아래 그림 1에 표시된 것처럼 전체 데이터세트의 그라데이션 방향과 더욱 일치합니다.
따라서 모델은 개별 미니 배치의 영향을 받지 않고 전체 훈련 세트에 대한 훈련 손실을 보다 효과적으로 최적화할 수 있습니다. 즉, 드롭아웃은 SGD(확률적 경사하강법)에 대응하고 훈련 초기에 샘플링된 미니 배치의 무작위성으로 인해 발생하는 과도한 정규화를 방지합니다.
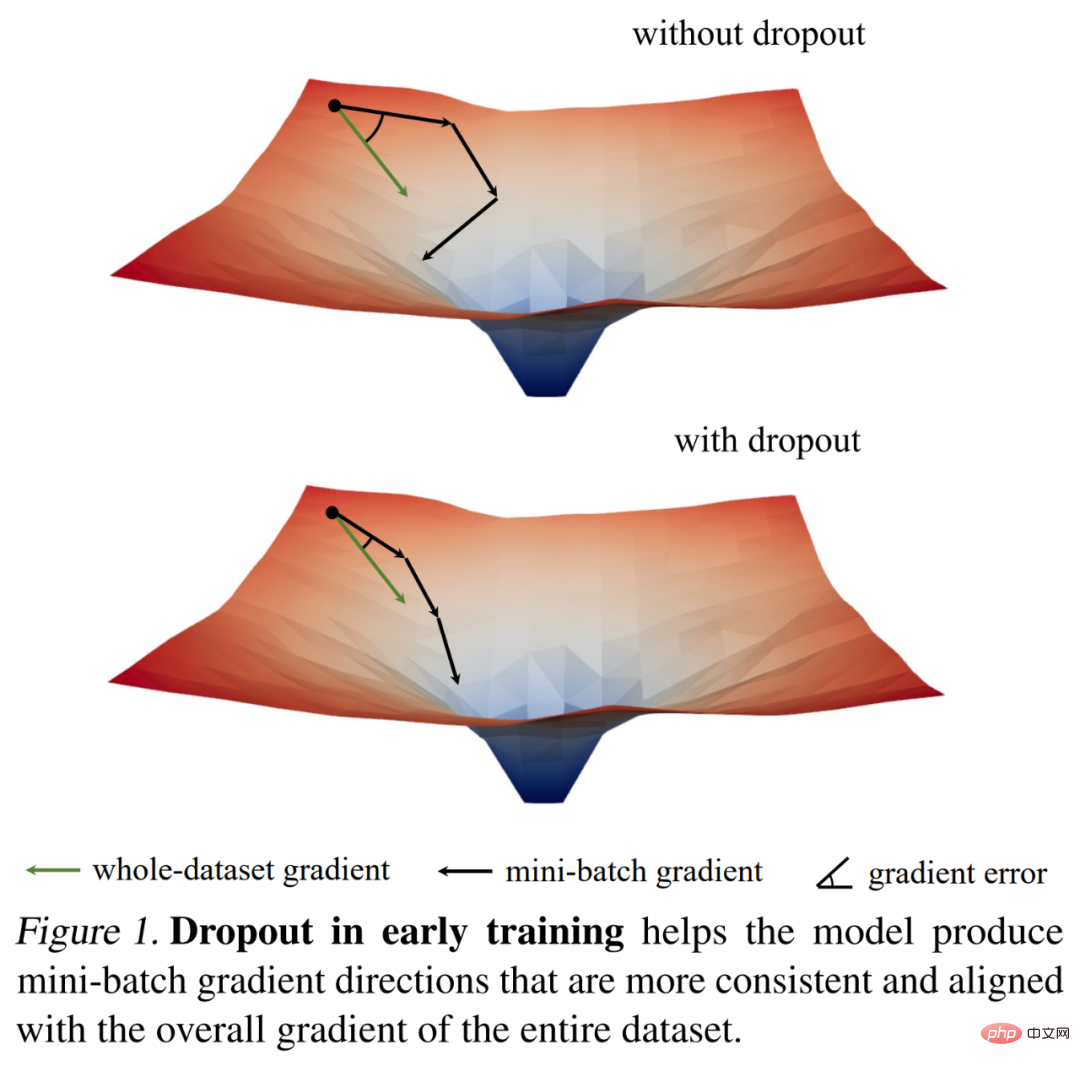
이 발견을 바탕으로 연구자들은 과소적합 모델이 더 잘 맞도록 돕기 위해 조기 드롭아웃(즉, 드롭아웃은 훈련의 초기 단계에서만 사용됨)을 제안했습니다. 조기 탈락은 탈락이 없는 경우와 표준 탈락에 비해 최종 훈련 손실을 줄입니다. 대조적으로, 이미 표준 드롭아웃을 사용하는 모델의 경우, 연구자들은 과적합을 줄이기 위해 초기 훈련 에포크에서 드롭아웃을 제거할 것을 권장합니다. 그들은 이 방법을 late dropout이라고 부르며 대형 모델의 일반화 정확도를 향상시킬 수 있음을 보여주었습니다. 아래 그림 2에서는 표준 탈락, 조기 탈락, 후기 탈락을 비교합니다.

연구원들은 서로 다른 모델을 사용하여 이미지 분류 및 다운스트림 작업에 대한 조기 드롭아웃과 지연 드롭아웃을 평가했으며, 그 결과 둘 다 표준 드롭아웃과 드롭아웃 없음보다 지속적으로 더 나은 결과를 생성하는 것으로 나타났습니다. 그들은 이번 발견이 드롭아웃과 과적합에 대한 새로운 통찰력을 제공하고 신경망 정규화 프로그램의 추가 개발에 영감을 줄 수 있기를 바랍니다.
조기 드롭아웃과 지연 드롭아웃을 제안하기에 앞서, 본 연구에서는 드롭아웃이 과소적합을 줄이기 위한 도구로 사용될 수 있는지 탐색했습니다. 이 연구는 제안된 도구와 메트릭을 사용하여 드롭아웃의 훈련 역학에 대한 자세한 분석을 수행하고 ImageNet(Deng et al., 2009)에서 두 ViT-T/16의 훈련 프로세스를 비교했습니다. other One의 학습 중 탈락률은 0.1입니다.
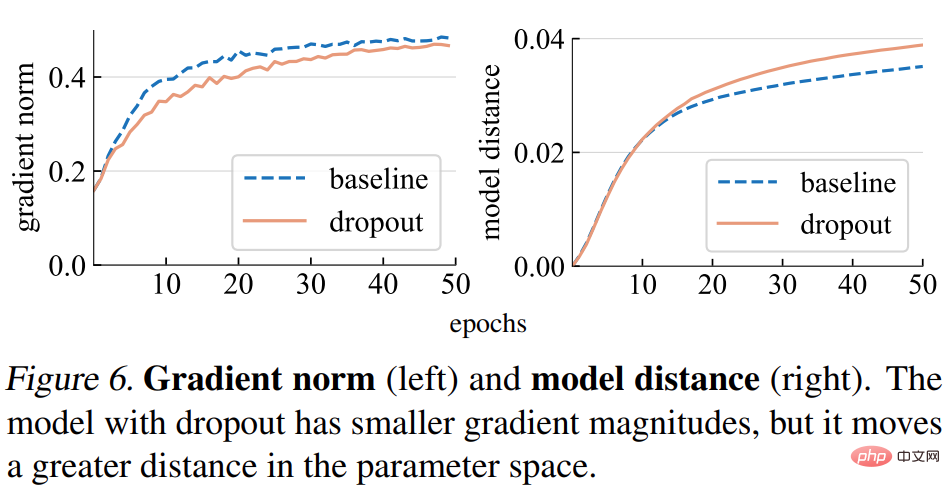
그라디언트 노름(norm). 본 연구에서는 먼저 드롭아웃이 기울기 g의 강도에 미치는 영향을 분석합니다. 아래 그림 6(왼쪽)에서 볼 수 있듯이 드롭아웃 모델은 더 작은 놈의 그래디언트를 생성합니다. 이는 각 그래디언트 업데이트마다 더 작은 단계를 수행함을 나타냅니다.
모델 거리. 그래디언트 단계 크기가 더 작기 때문에 드롭아웃 모델은 기준 모델보다 초기 지점을 기준으로 더 작은 거리를 이동할 것으로 예상됩니다. 아래 그림 6(오른쪽)에서 볼 수 있듯이 연구에서는 무작위 초기화로부터 각 모델의 거리를 표시합니다. 그러나 놀랍게도 드롭아웃 모델은 경사 표준을 기반으로 한 연구가 원래 예상했던 것과는 달리 실제로 기준 모델보다 더 큰 거리를 이동했습니다.
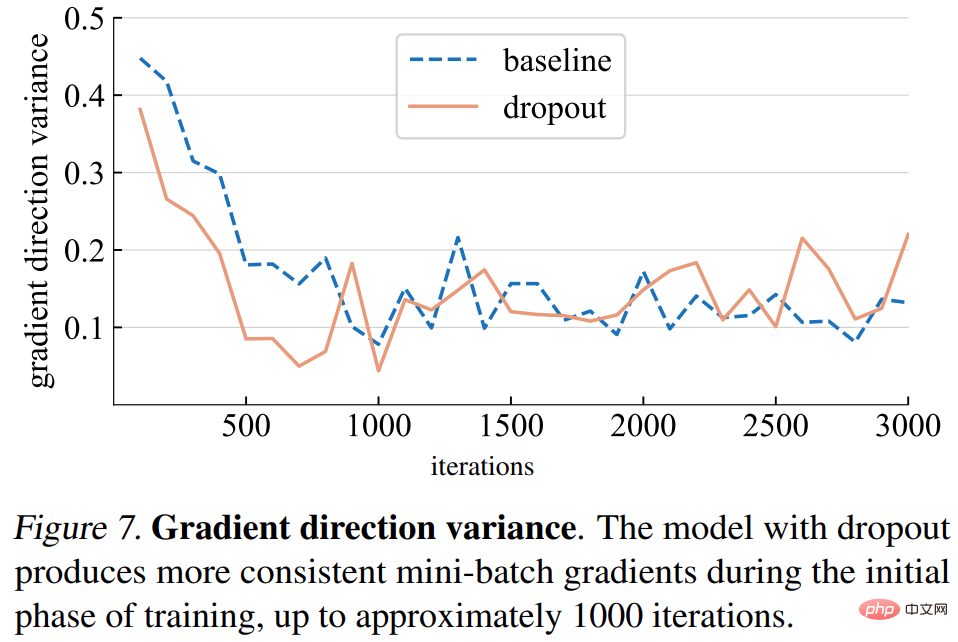
경사 방향 변화. 이 연구는 먼저 드롭아웃 모델이 미니 배치 전체에서 보다 일관된 경사 방향을 생성한다는 가설을 세웠습니다. 아래 그림 7에 표시된 차이는 일반적으로 가정과 일치합니다. 특정 반복 횟수(약 1000회)까지 드롭아웃 모델과 기준 모델의 기울기 분산은 낮은 수준에서 변동합니다.
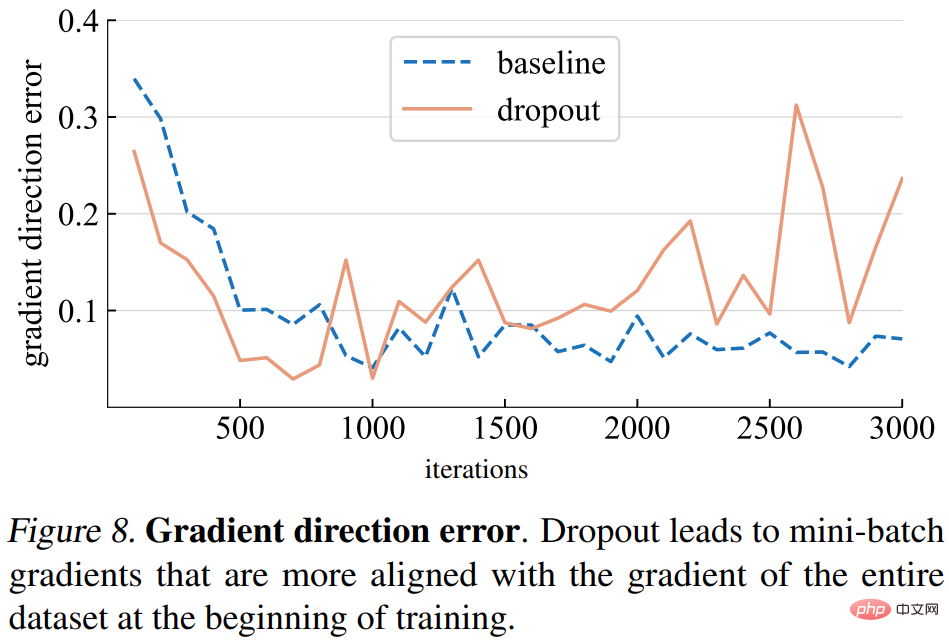
경사 방향 오류입니다. 그러나 올바른 그라데이션 방향은 무엇입니까? 훈련 데이터를 피팅하기 위한 기본 목표는 하나의 미니 배치 손실뿐만 아니라 전체 훈련 세트의 손실을 최소화하는 것입니다. 이 연구에서는 전체 모델의 기울기를 캡처하기 위해 추론 모드로 설정된 드롭아웃을 사용하여 전체 훈련 세트에 대해 특정 모델의 기울기를 계산합니다. 기울기 방향 오류는 아래 그림 8에 나와 있습니다.
본 연구에서는 위의 분석을 바탕으로 드롭아웃을 가능한 한 빨리 사용하면 모델의 훈련 데이터 적합 능력이 잠재적으로 향상될 수 있다는 사실을 발견했습니다. 훈련 데이터에 더 잘 맞는 것이 필요한지 여부는 모델이 과소적합인지 과대적합인지에 따라 달라지며, 이는 정확하게 정의하기 어려울 수 있습니다. 연구에서는 다음 기준을 사용했습니다.
모델 상태는 모델 아키텍처뿐만 아니라 사용된 데이터 세트 및 기타 훈련 매개변수에 따라 달라집니다.
그리고 연구에서는 조기 중퇴와 지연 중퇴
조기 중퇴라는 두 가지 방법을 제안했습니다. 기본적으로 과소적합 모델은 드롭아웃을 사용하지 않습니다. 훈련 데이터에 적응하는 능력을 향상시키기 위해 이 연구에서는 조기 드롭아웃을 제안합니다. 즉, 특정 반복 전에 드롭아웃을 사용하고 나머지 훈련 프로세스 동안에는 드롭아웃을 비활성화합니다. 연구 실험에서는 조기 탈락이 최종 훈련 손실을 줄이고 정확도를 향상시키는 것으로 나타났습니다.
늦은 자퇴. 표준 드롭아웃은 모델 과적합에 대한 훈련 설정에 이미 포함되어 있습니다. 훈련 초기 단계에서 드롭아웃으로 인해 의도치 않게 과적합이 발생할 수 있으며 이는 바람직하지 않습니다. 과적합을 줄이기 위해 이 연구에서는 늦은 드롭아웃을 제안합니다. 즉, 드롭아웃은 특정 반복 이전에는 사용되지 않고 나머지 훈련에서는 사용됩니다.
본 연구에서 제안한 방법은 그림 2와 같이 개념과 구현이 간단하다. 구현에는 두 개의 하이퍼파라미터가 필요합니다. 1) 드롭아웃을 켜거나 끄기 전에 기다려야 하는 에포크 수 2) 표준 드롭아웃 비율과 유사한 드롭율 p. 본 연구는 이 두 가지 하이퍼파라미터가 제안된 방법의 견고성을 보장할 수 있음을 보여줍니다.
연구원들은 1000개의 클래스와 120만 개의 훈련 이미지를 사용하여 ImageNet-1K 분류 데이터 세트에 대한 실증적 평가를 수행하고 상위 1개의 검증 정확도를 보고했습니다.
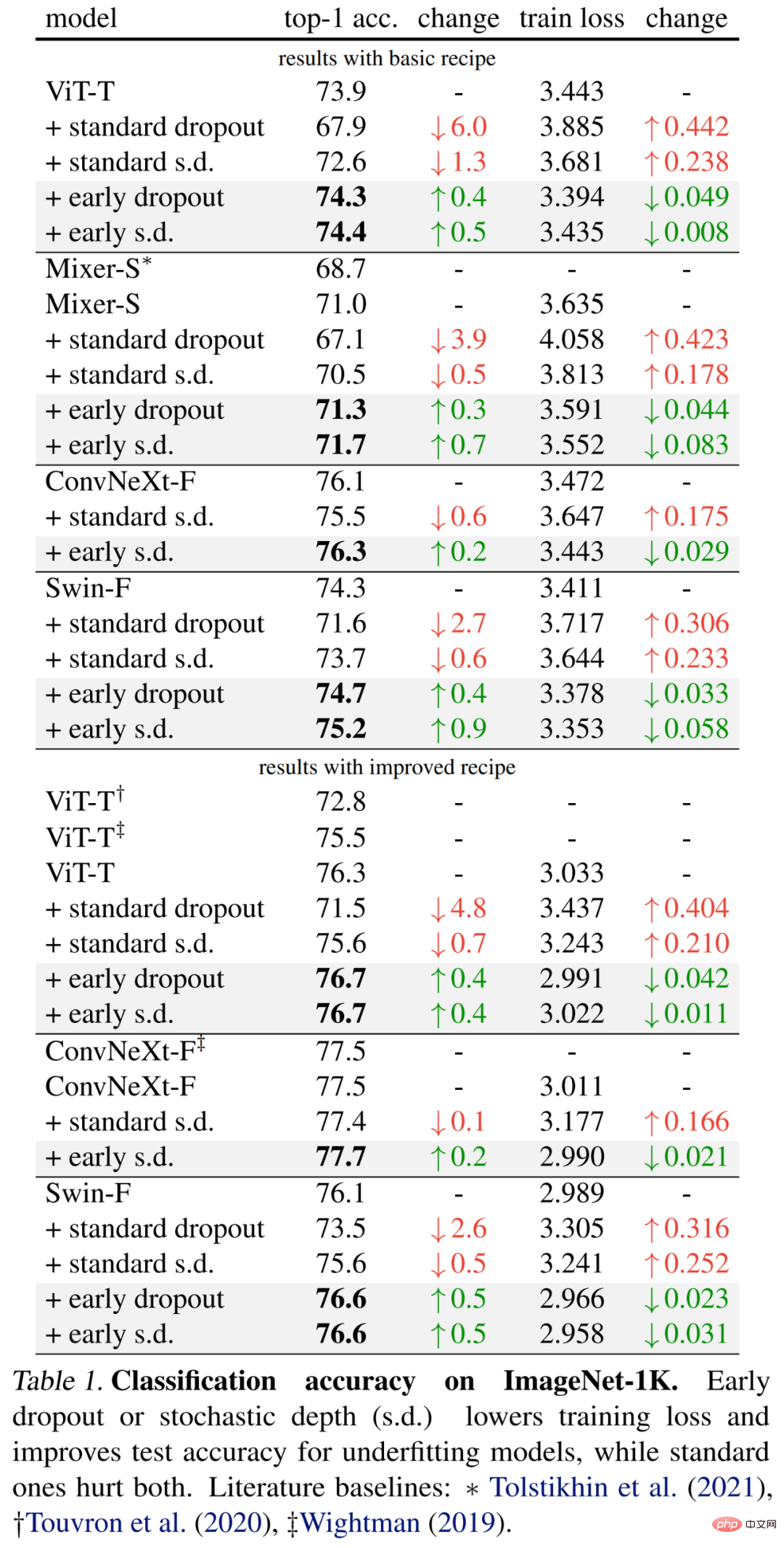
구체적인 결과는 먼저 아래 표 1(상단)에 나와 있습니다. 조기 드롭아웃은 계속해서 테스트 정확도를 향상시키고 훈련 손실을 줄여줍니다. 이는 초기 단계의 드롭아웃이 모델이 데이터에 더 잘 맞는 데 도움이 된다는 것을 나타냅니다. 연구원들은 또한 모델에 부정적인 영향을 미치는 0.1의 드롭률을 사용하여 표준 드롭아웃 및 확률론적 깊이(sd)와의 비교를 보여줍니다.
또한 연구원들은 훈련 시대를 두 배로 늘리고 혼합 및 컷 혼합 강도를 줄여 이러한 작은 모델에 대한 방법을 개선했습니다. 아래 표 1(하단)의 결과는 기준 정확도가 크게 향상되었으며 때로는 이전 작업 결과를 크게 초과하는 경우도 있습니다.
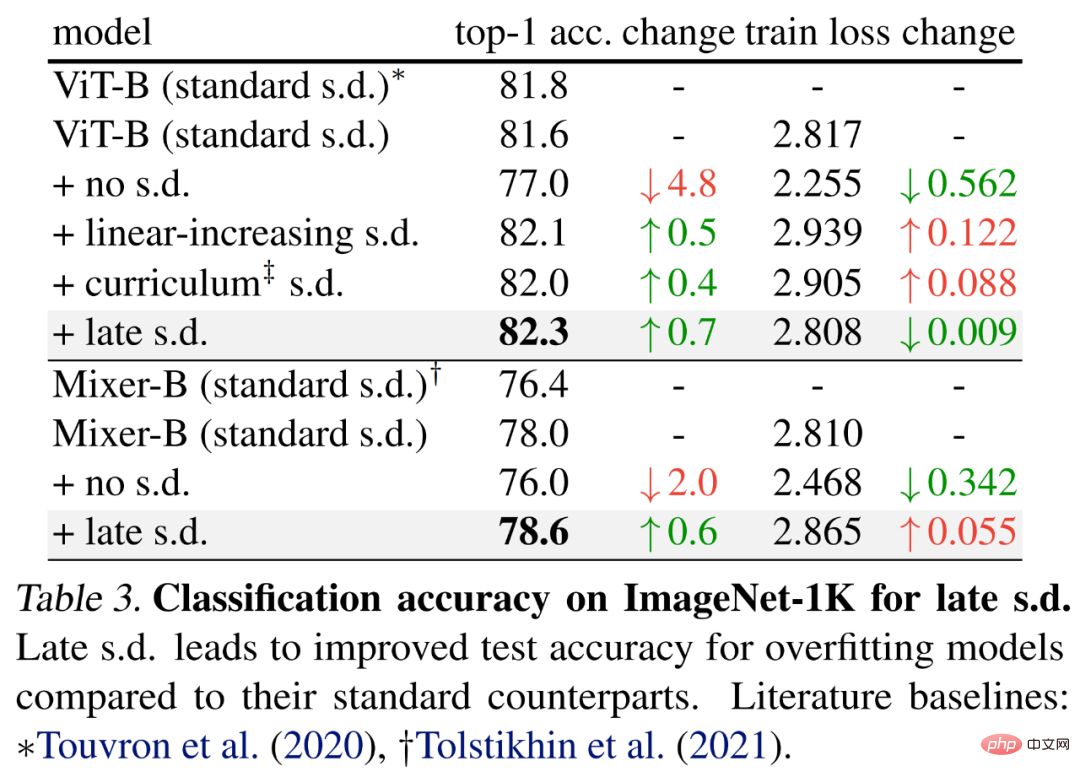
늦은 드롭아웃을 평가하기 위해 연구원들은 기본 훈련 방법을 사용하여 각각 59M 및 86M 매개변수를 갖는 더 큰 모델, 즉 ViT-B 및 Mixer-B를 선택했습니다.
아래 표 3에 결과가 나와 있습니다. 표준 s.d.와 비교하면 늦은 s.d.가 테스트 정확도를 향상시킵니다. 이러한 개선은 ViT-B를 유지하거나 Mixer-B 훈련 손실을 증가시키면서 달성되며, 이는 늦은 sd가 과적합을 효과적으로 감소시킨다는 것을 나타냅니다.
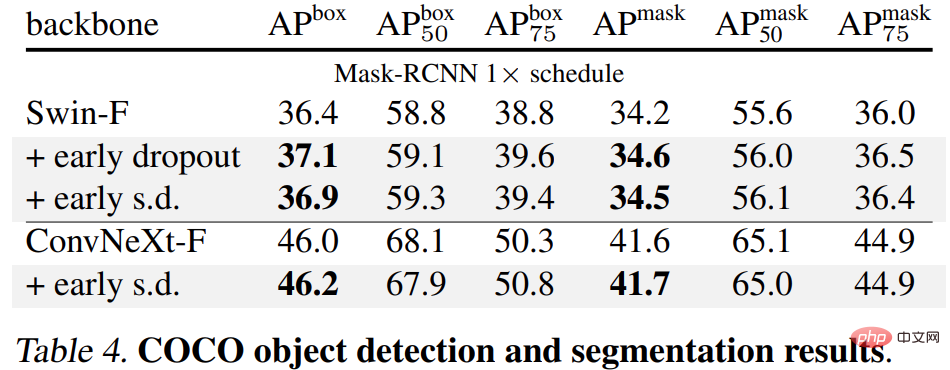
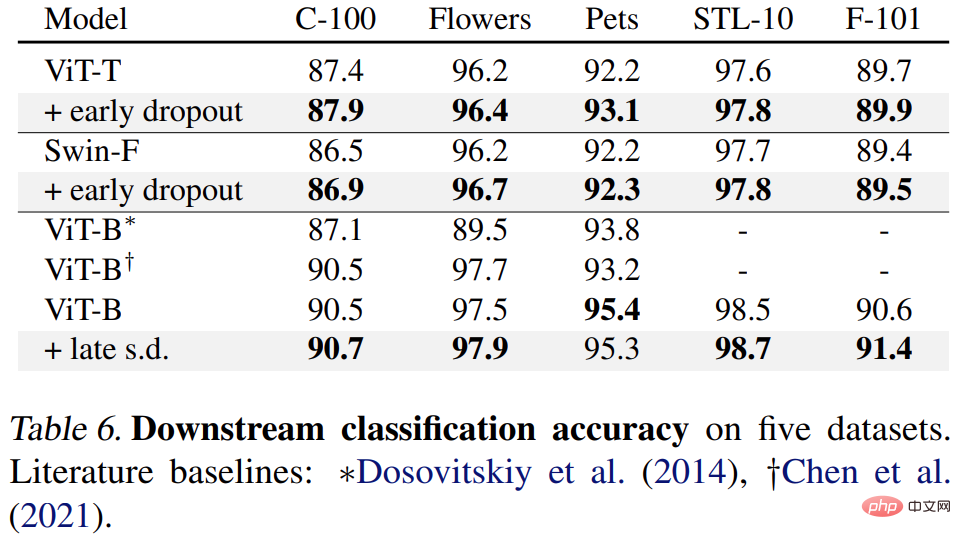
마지막으로 연구원들은 사전 훈련된 ImageNet-1K 모델을 다운스트림 작업에 대해 미세 조정하고 평가했습니다. 다운스트림 작업에는 COCO 객체 감지 및 세분화, ADE20K 의미론적 세분화, C-100을 포함한 5개 데이터 세트에 대한 다운스트림 분류가 포함됩니다. 목표는 조기 드롭아웃이나 늦은 드롭아웃을 사용하지 않고 미세 조정 단계에서 학습된 표현을 평가하는 것입니다.
결과는 아래 표 4, 5, 6에 나와 있습니다. 첫째, COCO에서 미세 조정하면 Early Dropout 또는 s.d를 사용하여 사전 훈련된 모델이 항상 이점을 유지합니다.
둘째, ADE20K 의미론적 분할 작업의 경우 이 방법을 사용하여 사전 훈련된 모델이 기준 모델보다 낫습니다.
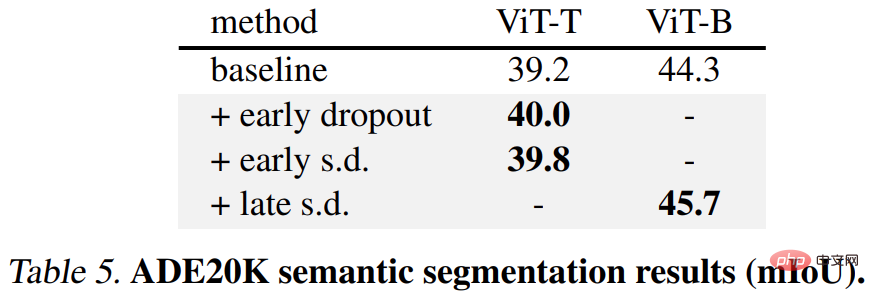
마지막으로 다운스트림 분류 작업이 있습니다. 이 방법은 대부분의 분류 작업에서 일반화 성능을 향상시킵니다.
자세한 기술적 세부 사항과 실험 결과는 원본 논문을 참조하세요.
위 내용은 향상된 드롭아웃은 과소적합 문제를 완화하는 데 사용될 수 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



