

TSP 문제를 해결하기 위해 Python을 사용하여 PSO 알고리즘을 구현하는 방법은 무엇입니까?

PSO 알고리즘
그럼 시작하기 전에 기본적인 PSO 알고리즘에 대해 이야기해보겠습니다. 핵심은 단 하나입니다.

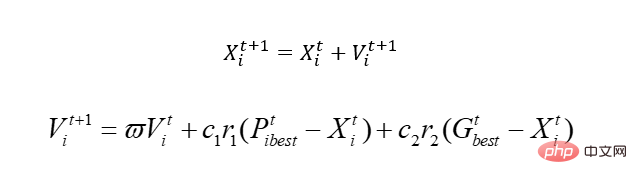
이 공식을 설명하면 이해하게 될 것입니다.
기존 규칙: 우리는 방정식 y=sin(x1)+cos(x2)
PSO 알고리즘이 새 이동을 시뮬레이션하여 최적화를 달성한다고 가정합니다. 이것이 어떻게 발생했는지는 다루지 않겠습니다. 핵심 .
방금 우리가 준 방정식에는 x1과 x2라는 두 개의 변수가 있습니다. 모의 새이기 때문에 블라인드 방식을 구현하기 위해 여기서는 속도 개념을 도입하고, x는 당연히 우리의 실현 가능 영역인 해 공간이다. 속도를 변경하면 x가 이동합니다. 즉, x의 값이 변경됩니다. 그 중 Pbest는 새가 걸어온 위치에서의 최적 솔루션을 나타내고, Gbest는 전체 개체군에 대한 최적 솔루션을 나타냅니다. 무슨 뜻입니까? 즉, 이 새가 움직일 때 더 나쁜 위치로 이동할 수 있다는 것입니다. 왜냐하면 유전학과는 달리 이 새는 나쁘면 죽겠지만 이 새는 그렇지 않기 때문입니다. 물론, 관련된 많은 지역적 문제가 있으므로 여기서는 논의하지 않겠습니다. 어떤 알고리즘도 완벽하지 않으며 이것이 옳습니다.
알고리즘 프로세스
알고리즘의 주요 프로세스:
1단계: 입자 떼의 무작위 위치와 속도를 초기화하고 반복 횟수를 설정합니다.
2단계: 각 입자의 적합도 값을 계산합니다.
3단계: 각 입자에 대해 자신의 체력 값을 내가 경험한 최고의 위치의 체력 값과 비교합니다. 더 좋으면 현재 개인의 최적 위치로 사용합니다.
4단계: 각 입자에 대해 해당 적합도 값을 gbestg가 경험한 전 세계 최고 위치의 적합도 값과 비교합니다. 더 나은 경우 현재 전역 최적 위치로 사용합니다.
5단계: 속도 및 위치 공식에 따라 입자의 속도와 위치를 최적화하여 입자 위치를 업데이트합니다.
6단계: 종료 조건(일반적으로 최대 사이클 수 또는 최소 오류 요구 사항)에 도달하지 않으면 두 번째 단계로 돌아갑니다.

장점:
PSO 알고리즘에는 교차 및 돌연변이 연산이 없습니다. 검색을 완료하기 위해 입자 속도에 의존하며, 반복적인 진화에서는 최적의 입자만이 다른 입자에 정보를 전달하며 검색 속도가 빠릅니다.
PSO 알고리즘에는 메모리가 있으며, 입자 그룹의 역사적 최고 위치를 기억하여 다른 입자에 전달할 수 있습니다.
조정해야 할 매개변수가 적고 구조가 간단하며 엔지니어링에서 구현하기 쉽습니다.
실수 인코딩을 사용하여 문제 풀이의 변수 수를 입자의 차원으로 직접 사용합니다.
단점:
속도의 동적 조정이 부족하고 쉽게 지역적 최적성에 빠지기 때문에 수렴 정확도가 낮고 수렴이 어렵습니다.
이산 및 조합 최적화 문제를 효과적으로 해결할 수 없습니다.
매개변수 제어, 다양한 문제에 대해 최적의 결과를 얻기 위해 적절한 매개변수를 선택하는 방법.
일부 비데카르트 좌표계 설명 문제를 효과적으로 해결할 수 없습니다.
간단한 구현
좋습니다. 가장 간단한 구현을 살펴보겠습니다.
import numpy as np
import random
class PSO_model:
def __init__(self,w,c1,c2,r1,r2,N,D,M):
self.w = w # 惯性权值
self.c1=c1
self.c2=c2
self.r1=r1
self.r2=r2
self.N=N # 初始化种群数量个数
self.D=D # 搜索空间维度
self.M=M # 迭代的最大次数
self.x=np.zeros((self.N,self.D)) #粒子的初始位置
self.v=np.zeros((self.N,self.D)) #粒子的初始速度
self.pbest=np.zeros((self.N,self.D)) #个体最优值初始化
self.gbest=np.zeros((1,self.D)) #种群最优值
self.p_fit=np.zeros(self.N)
self.fit=1e8 #初始化全局最优适应度
# 目标函数,也是适应度函数(求最小化问题)
def function(self,x):
A = 10
x1=x[0]
x2=x[1]
Z = 2 * A + x1 ** 2 - A * np.cos(2 * np.pi * x1) + x2 ** 2 - A * np.cos(2 * np.pi * x2)
return Z
# 初始化种群
def init_pop(self):
for i in range(self.N):
for j in range(self.D):
self.x[i][j] = random.random()
self.v[i][j] = random.random()
self.pbest[i] = self.x[i] # 初始化个体的最优值
aim=self.function(self.x[i]) # 计算个体的适应度值
self.p_fit[i]=aim # 初始化个体的最优位置
if aim < self.fit: # 对个体适应度进行比较,计算出最优的种群适应度
self.fit = aim
self.gbest = self.x[i]
# 更新粒子的位置与速度
def update(self):
for t in range(self.M): # 在迭代次数M内进行循环
for i in range(self.N): # 对所有种群进行一次循环
aim=self.function(self.x[i]) # 计算一次目标函数的适应度
if aim<self.p_fit[i]: # 比较适应度大小,将小的负值给个体最优
self.p_fit[i]=aim
self.pbest[i]=self.x[i]
if self.p_fit[i]<self.fit: # 如果是个体最优再将和全体最优进行对比
self.gbest=self.x[i]
self.fit = self.p_fit[i]
for i in range(self.N): # 更新粒子的速度和位置
self.v[i]=self.w*self.v[i]+self.c1*self.r1*(self.pbest[i]-self.x[i])+ self.c2*self.r2*(self.gbest-self.x[i])
self.x[i]=self.x[i]+self.v[i]
print("最优值:",self.fit,"位置为:",self.gbest)
if __name__ == '__main__':
# w,c1,c2,r1,r2,N,D,M参数初始化
w=random.random()
c1=c2=2#一般设置为2
r1=0.7
r2=0.5
N=30
D=2
M=200
pso_object=PSO_model(w,c1,c2,r1,r2,N,D,M)#设置初始权值
pso_object.init_pop()
pso_object.update()TSP
데이터 표현
해결
우선 PSO를 사용하는 경우 , 실제로는 동일합니다. 이전의 유전학 사용은 유사합니다. 우리는 여전히 행렬을 통해 인구를 나타내고 행렬은 도시 간 거리를 나타냅니다.
# 群体的初始化和路径的初始化
self.population = np.array([0] * self.num_pop * self.num).reshape(
self.num_pop, self.num)
self.fitness = [0] * self.num_pop
"""
计算城市的距离,我们用矩阵表示城市间的距离
"""
self.__matrix_distance = self.__matrix_dis()와 원래 PSO의 가장 큰 차이점은 무엇인가요? 이는 실제로 간단하며 업데이트 속도와 관련이 있습니다. 지속적인 문제를 다룰 때 실제로는 다음과 같습니다. 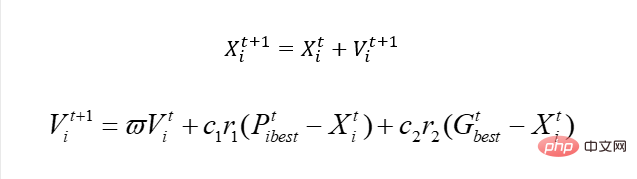
마찬가지로 X를 사용하여 도시의 수를 나타낼 수 있지만 분명히 이 솔루션을 사용하여 속도를 업데이트할 수는 없습니다.
이때 속도를 업데이트하려면 새로운 솔루션을 사용해야 합니다. 따라서 이 솔루션은 실제로 유전자 알고리즘을 사용한 X 업데이트입니다. 직설적으로 말하면, 속도가 필요한 이유는 X를 업데이트하여 X를 좋은 방향으로 움직이게 하기 위해서입니다. 이제는 더 이상 단순히 속도 업데이트를 사용하는 것이 불가능하므로 어차피 X를 업데이트하고 있으니 그냥 이 X를 잘 업데이트할 수 있는 솔루션을 선택하면 되지 않을까요? 따라서 여기서 유전학을 직접 사용할 수 있습니다. 우리의 속도 업데이트는 Pbest와 Gbest를 기반으로 한 다음 특정 가중치에 따라 "학습"됩니다. 이러한 방식으로 이 V는 Pbest와 Gbest의 "특성"을 갖습니다. 그렇다면, 유전자 교배를 직접 모방해서 베스트와 교배시키면 그에 상응하는 "특징"을 배울 수는 없는 걸까요?
def cross_1(self, path, best_path):
r1 = np.random.randint(self.num)
r2 = np.random.randint(self.num)
while r2 == r1:
r2 = np.random.randint(self.num)
left, right = min(r1, r2), max(r1, r2)
cross = best_path[left:right + 1]
for i in range(right - left + 1):
for k in range(self.num):
if path[k] == cross[i]:
path[k:self.num - 1] = path[k + 1:self.num]
path[-1] = 0
path[self.num - right + left - 1:self.num] = cross
return path동시에 돌연변이를 도입할 수도 있습니다.
def mutation(self,path):
r1 = np.random.randint(self.num)
r2 = np.random.randint(self.num)
while r2 == r1:
r2 = np.random.randint(self.num)
path[r1],path[r2] = path[r2],path[r1]
return path전체 코드
🎜좋아, 이제 전체 코드를 살펴보자:🎜import numpy as np
import matplotlib.pyplot as plt
class HybridPsoTSP(object):
def __init__(self ,data ,num_pop=200):
self.num_pop = num_pop # 群体个数
self.data = data # 城市坐标
self.num =len(data) # 城市个数
# 群体的初始化和路径的初始化
self.population = np.array([0] * self.num_pop * self.num).reshape(
self.num_pop, self.num)
self.fitness = [0] * self.num_pop
"""
计算城市的距离,我们用矩阵表示城市间的距离
"""
self.__matrix_distance = self.__matrix_dis()
def __matrix_dis(self):
"""
计算14个城市的距离,将这些距离用矩阵存起来
:return:
"""
res = np.zeros((self.num, self.num))
for i in range(self.num):
for j in range(i + 1, self.num):
res[i, j] = np.linalg.norm(self.data[i, :] - self.data[j, :])
res[j, i] = res[i, j]
return res
def cross_1(self, path, best_path):
r1 = np.random.randint(self.num)
r2 = np.random.randint(self.num)
while r2 == r1:
r2 = np.random.randint(self.num)
left, right = min(r1, r2), max(r1, r2)
cross = best_path[left:right + 1]
for i in range(right - left + 1):
for k in range(self.num):
if path[k] == cross[i]:
path[k:self.num - 1] = path[k + 1:self.num]
path[-1] = 0
path[self.num - right + left - 1:self.num] = cross
return path
def mutation(self,path):
r1 = np.random.randint(self.num)
r2 = np.random.randint(self.num)
while r2 == r1:
r2 = np.random.randint(self.num)
path[r1],path[r2] = path[r2],path[r1]
return path
def comp_fit(self, one_path):
"""
计算,咱们这个路径的长度,例如A-B-C-D
:param one_path:
:return:
"""
res = 0
for i in range(self.num - 1):
res += self.__matrix_distance[one_path[i], one_path[i + 1]]
res += self.__matrix_distance[one_path[-1], one_path[0]]
return res
def out_path(self, one_path):
"""
输出我们的路径顺序
:param one_path:
:return:
"""
res = str(one_path[0] + 1) + '-->'
for i in range(1, self.num):
res += str(one_path[i] + 1) + '-->'
res += str(one_path[0] + 1) + '\n'
print(res)
def init_population(self):
"""
初始化种群
:return:
"""
rand_ch = np.array(range(self.num))
for i in range(self.num_pop):
np.random.shuffle(rand_ch)
self.population[i, :] = rand_ch
self.fitness[i] = self.comp_fit(rand_ch)
def main(data, max_n=200, num_pop=200):
Path_short = HybridPsoTSP(data, num_pop=num_pop) # 混合粒子群算法类
Path_short.init_population() # 初始化种群
# 初始化路径绘图
fig, ax = plt.subplots()
x = data[:, 0]
y = data[:, 1]
ax.scatter(x, y, linewidths=0.1)
for i, txt in enumerate(range(1, len(data) + 1)):
ax.annotate(txt, (x[i], y[i]))
res0 = Path_short.population[0]
x0 = x[res0]
y0 = y[res0]
for i in range(len(data) - 1):
plt.quiver(x0[i], y0[i], x0[i + 1] - x0[i], y0[i + 1] - y0[i], color='r', width=0.005, angles='xy', scale=1,
scale_units='xy')
plt.quiver(x0[-1], y0[-1], x0[0] - x0[-1], y0[0] - y0[-1], color='r', width=0.005, angles='xy', scale=1,
scale_units='xy')
plt.show()
print('初始染色体的路程: ' + str(Path_short.fitness[0]))
# 存储个体极值的路径和距离
best_P_population = Path_short.population.copy()
best_P_fit = Path_short.fitness.copy()
min_index = np.argmin(Path_short.fitness)
# 存储当前种群极值的路径和距离
best_G_population = Path_short.population[min_index, :]
best_G_fit = Path_short.fitness[min_index]
# 存储每一步迭代后的最优路径和距离
best_population = [best_G_population]
best_fit = [best_G_fit]
# 复制当前群体进行交叉变异
x_new = Path_short.population.copy()
for i in range(max_n):
# 更新当前的个体极值
for j in range(num_pop):
if Path_short.fitness[j] < best_P_fit[j]:
best_P_fit[j] = Path_short.fitness[j]
best_P_population[j, :] = Path_short.population[j, :]
# 更新当前种群的群体极值
min_index = np.argmin(Path_short.fitness)
best_G_population = Path_short.population[min_index, :]
best_G_fit = Path_short.fitness[min_index]
# 更新每一步迭代后的全局最优路径和解
if best_G_fit < best_fit[-1]:
best_fit.append(best_G_fit)
best_population.append(best_G_population)
else:
best_fit.append(best_fit[-1])
best_population.append(best_population[-1])
# 将每个个体与个体极值和当前的群体极值进行交叉
for j in range(num_pop):
# 与个体极值交叉
x_new[j, :] = Path_short.cross_1(x_new[j, :], best_P_population[j, :])
fit = Path_short.comp_fit(x_new[j, :])
# 判断是否保留
if fit < Path_short.fitness[j]:
Path_short.population[j, :] = x_new[j, :]
Path_short.fitness[j] = fit
# 与当前极值交叉
x_new[j, :] = Path_short.cross_1(x_new[j, :], best_G_population)
fit = Path_short.comp_fit(x_new[j, :])
if fit < Path_short.fitness[j]:
Path_short.population[j, :] = x_new[j, :]
Path_short.fitness[j] = fit
# 变异
x_new[j, :] = Path_short.mutation(x_new[j, :])
fit = Path_short.comp_fit(x_new[j, :])
if fit <= Path_short.fitness[j]:
Path_short.population[j] = x_new[j, :]
Path_short.fitness[j] = fit
if (i + 1) % 20 == 0:
print('第' + str(i + 1) + '步后的最短的路程: ' + str(Path_short.fitness[min_index]))
print('第' + str(i + 1) + '步后的最优路径:')
Path_short.out_path(Path_short.population[min_index, :]) # 显示每一步的最优路径
Path_short.best_population = best_population
Path_short.best_fit = best_fit
return Path_short # 返回结果类
if __name__ == '__main__':
data = np.array([16.47, 96.10, 16.47, 94.44, 20.09, 92.54,
22.39, 93.37, 25.23, 97.24, 22.00, 96.05, 20.47, 97.02,
17.20, 96.29, 16.30, 97.38, 14.05, 98.12, 16.53, 97.38,
21.52, 95.59, 19.41, 97.13, 20.09, 92.55]).reshape((14, 2))
main(data)初始染色体的路程: 71.30211569672313
第20步后的最短的路程: 29.340520066994223
第20步后的最优路径:
9-->10-->1-->2-->14-->3-->4-->5-->6-->12-->7-->13-->8-->11-->9
第40步后的最短的路程: 29.340520066994223
第40步后的最优路径:
9-->10-->1-->2-->14-->3-->4-->5-->6-->12-->7-->13-->8-->11-->9
第60步后的最短的路程: 29.340520066994223
第60步后的最优路径:
9-->10-->1-->2-->14-->3-->4-->5-->6-->12-->7-->13-->8-->11-->9
第80步后的最短的路程: 29.340520066994223
第80步后的最优路径:
9-->10-->1-->2-->14-->3-->4-->5-->6-->12-->7-->13-->8-->11-->9
第100步后的最短的路程: 29.340520066994223
第100步后的最优路径:
9-->10-->1-->2-->14-->3-->4-->5-->6-->12-->7-->13-->8-->11-->9
第120步后的最短的路程: 29.340520066994223
第120步后的最优路径:
9-->10-->1-->2-->14-->3-->4-->5-->6-->12-->7-->13-->8-->11-->9
第140步后的最短的路程: 29.340520066994223
第140步后的最优路径:
9-->10-->1-->2-->14-->3-->4-->5-->6-->12-->7-->13-->8-->11-->9
第160步后的最短的路程: 29.340520066994223
第160步后的最优路径:
9-->10-->1-->2-->14-->3-->4-->5-->6-->12-->7-->13-->8-->11-->9
第180步后的最短的路程: 29.340520066994223
第180步后的最优路径:
9-->10-->1-->2-->14-->3-->4-->5-->6-->12-->7-->13-->8-->11-->9
第200步后的最短的路程: 29.340520066994223
第200步后的最优路径:
9-->10-->1-->2-->14-->3-->4-->5-->6-->12-->7-->13-->8-->11-->9
可以看到收敛速度还是很快的。
特点分析
ok,到目前为止的话,我们介绍了两个算法去解决TSP或者是优化问题。我们来分析一下,这些算法有什么特点,为啥可以达到我们需要的优化效果。其实不管是遗传还是PSO,你其实都可以发现,有一个东西,我们可以暂且叫它环境压力。我们通过物竞天择,或者鸟类迁移,进行模拟寻优。而之所以需要这样做,是因为我们指定了一个规则,在我们的规则之下。我们让模拟的种群有一种压力去靠拢,其中物竞天择和鸟类迁移只是我们的一种手段,去应对这样的“压力”。所以的对于这种算法而言,最核心的点就两个:
设计环境压力
我们需要做优化问题,所以我们必须要能够让我们的解往那个方向走,需要一个驱动,需要一个压力。因此我们需要设计这样的一个环境,在遗传算法,粒子群算法是通过种群当中的生存,来进行设计的它的压力是我们的目标函数。由种群和目标函数(目标指标)构成了一个环境和压力。
设计压力策略
之后的话,我们设计好了一个环境和压力,那么未来应对这种压力,我们需要去设计一种策略,来应付这种压力。遗传算法是通过PUA自己,也就是种群的优胜略汰。PSO是通过学习,学习种群的优秀粒子和过去自己家的优秀“祖先”来应对这种压力的。
强化学习
所以的话,我们是否可以使用别的方案来实现这种优化效果。,在强化学习的算法框架里面的话,我们明确的知道了为什么他们可以实现优化,是环境压力+压力策略。恰好咱们强化学习是有环境的,适应函数和环境恰好可以组成环境+压力。本身的算法收敛过程就是我们的压力策略。所以我们完全是可以直接使用强化学习进行这个处理的。那么在这里咱们就来使用强化学习在下一篇文章当中。
위 내용은 TSP 문제를 해결하기 위해 Python을 사용하여 PSO 알고리즘을 구현하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7469
7469
 15
1376
52
77
11
48
19
19
29
15
1376
52
77
11
48
19
19
29

 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
이 기사는 MySQL 데이터베이스의 작동을 소개합니다. 먼저 MySQLworkBench 또는 명령 줄 클라이언트와 같은 MySQL 클라이언트를 설치해야합니다. 1. MySQL-Uroot-P 명령을 사용하여 서버에 연결하고 루트 계정 암호로 로그인하십시오. 2. CreateABase를 사용하여 데이터베이스를 작성하고 데이터베이스를 선택하십시오. 3. CreateTable을 사용하여 테이블을 만들고 필드 및 데이터 유형을 정의하십시오. 4. InsertInto를 사용하여 데이터를 삽입하고 데이터를 쿼리하고 업데이트를 통해 데이터를 업데이트하고 DELETE를 통해 데이터를 삭제하십시오. 이러한 단계를 마스터하고 일반적인 문제를 처리하는 법을 배우고 데이터베이스 성능을 최적화하면 MySQL을 효율적으로 사용할 수 있습니다.
 MySQL 다운로드 파일이 손상되어 설치할 수 없습니다. 수리 솔루션
Apr 08, 2025 am 11:21 AM
MySQL 다운로드 파일이 손상되어 설치할 수 없습니다. 수리 솔루션
Apr 08, 2025 am 11:21 AM
MySQL 다운로드 파일은 손상되었습니다. 어떻게해야합니까? 아아, mySQL을 다운로드하면 파일 손상을 만날 수 있습니다. 요즘 정말 쉽지 않습니다! 이 기사는 모든 사람이 우회를 피할 수 있도록이 문제를 해결하는 방법에 대해 이야기합니다. 읽은 후 손상된 MySQL 설치 패키지를 복구 할 수있을뿐만 아니라 향후에 갇히지 않도록 다운로드 및 설치 프로세스에 대해 더 깊이 이해할 수 있습니다. 파일 다운로드가 손상된 이유에 대해 먼저 이야기합시다. 이에 대한 많은 이유가 있습니다. 네트워크 문제는 범인입니다. 네트워크의 다운로드 프로세스 및 불안정성의 중단으로 인해 파일 손상이 발생할 수 있습니다. 다운로드 소스 자체에도 문제가 있습니다. 서버 파일 자체가 고장 났으며 물론 다운로드하면 고장됩니다. 또한 일부 안티 바이러스 소프트웨어의 과도한 "열정적 인"스캔으로 인해 파일 손상이 발생할 수 있습니다. 진단 문제 : 파일이 실제로 손상되었는지 확인하십시오
 다운로드 후 MySQL을 설치할 수 없습니다
Apr 08, 2025 am 11:24 AM
다운로드 후 MySQL을 설치할 수 없습니다
Apr 08, 2025 am 11:24 AM
MySQL 설치 실패의 주된 이유는 다음과 같습니다. 1. 권한 문제, 관리자로 실행하거나 Sudo 명령을 사용해야합니다. 2. 종속성이 누락되었으며 관련 개발 패키지를 설치해야합니다. 3. 포트 충돌, 포트 3306을 차지하는 프로그램을 닫거나 구성 파일을 수정해야합니다. 4. 설치 패키지가 손상되어 무결성을 다운로드하여 확인해야합니다. 5. 환경 변수가 잘못 구성되었으며 운영 체제에 따라 환경 변수를 올바르게 구성해야합니다. 이러한 문제를 해결하고 각 단계를 신중하게 확인하여 MySQL을 성공적으로 설치하십시오.
 MySQL 설치 후 시작할 수없는 서비스에 대한 솔루션
Apr 08, 2025 am 11:18 AM
MySQL 설치 후 시작할 수없는 서비스에 대한 솔루션
Apr 08, 2025 am 11:18 AM
MySQL이 시작을 거부 했습니까? 당황하지 말고 확인합시다! 많은 친구들이 MySQL을 설치 한 후 서비스를 시작할 수 없다는 것을 알았으며 너무 불안했습니다! 걱정하지 마십시오.이 기사는 침착하게 다루고 그 뒤에있는 마스터 마인드를 찾을 수 있습니다! 그것을 읽은 후에는이 문제를 해결할뿐만 아니라 MySQL 서비스에 대한 이해와 문제 해결 문제에 대한 아이디어를 향상시키고보다 강력한 데이터베이스 관리자가 될 수 있습니다! MySQL 서비스는 시작되지 않았으며 간단한 구성 오류에서 복잡한 시스템 문제에 이르기까지 여러 가지 이유가 있습니다. 가장 일반적인 측면부터 시작하겠습니다. 기본 지식 : 서비스 시작 프로세스 MySQL 서비스 시작에 대한 간단한 설명. 간단히 말해서 운영 체제는 MySQL 관련 파일을로드 한 다음 MySQL 데몬을 시작합니다. 여기에는 구성이 포함됩니다
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 성능 최적화는 설치 구성, 인덱싱 및 쿼리 최적화, 모니터링 및 튜닝의 세 가지 측면에서 시작해야합니다. 1. 설치 후 innodb_buffer_pool_size 매개 변수와 같은 서버 구성에 따라 my.cnf 파일을 조정해야합니다. 2. 과도한 인덱스를 피하기 위해 적절한 색인을 작성하고 Execution 명령을 사용하여 실행 계획을 분석하는 것과 같은 쿼리 문을 최적화합니다. 3. MySQL의 자체 모니터링 도구 (showprocesslist, showstatus)를 사용하여 데이터베이스 건강을 모니터링하고 정기적으로 백업 및 데이터베이스를 구성하십시오. 이러한 단계를 지속적으로 최적화함으로써 MySQL 데이터베이스의 성능을 향상시킬 수 있습니다.
 MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 기본 데이터 저장 및 관리를위한 네트워크 연결없이 실행할 수 있습니다. 그러나 다른 시스템과의 상호 작용, 원격 액세스 또는 복제 및 클러스터링과 같은 고급 기능을 사용하려면 네트워크 연결이 필요합니다. 또한 보안 측정 (예 : 방화벽), 성능 최적화 (올바른 네트워크 연결 선택) 및 데이터 백업은 인터넷에 연결하는 데 중요합니다.
