

Python을 사용하여 텍스트 데이터를 조작하는 방법은 무엇입니까?

파이썬을 사용하여 텍스트 데이터 처리
실험 목적
파이썬의 기본 데이터 구조와 파일의 입출력을 익힙니다.
실험 데이터
XXXX의 xx 머신러닝 컨퍼런스에서 나온 평가 데이터와 평가 작업을 사용하세요. 데이터에는 훈련 세트와 테스트 세트가 포함되어 있습니다. 평가 작업은 테스트 세트의 관계가 긍정적인지 예측하는 것입니다. 주어진 훈련 데이터를 통해 부정적인 예를 들어, 각 샘플의 끝에 1 또는 0을 제공합니다.
데이터는 다음과 같이 설명됩니다. 첫 번째 열은 관계 유형, 두 번째와 세 번째 열은 사람 이름, 네 번째 열은 제목, 다섯 번째 열은 관계가 긍정적인지 부정적인지 여부입니다. 1은 긍정적인 예이고 0은 부정적인 예입니다. 여섯 번째 열은 훈련 세트를 나타냅니다. ㅋㅋㅋ 훈련 세트에서 유일한 차이점은 다섯 번째 열의 긍정적인 예인지 부정적인 예인지는 중요하지 않습니다.
| 관계 | 캐릭터 1 | 캐릭터 2 | 이벤트 |
실험 콘텐츠 처음 5개 열만 남기고 훈련 세트 데이터를 처리하면 출력 텍스트의 이름이 exp1_1.txt로 지정됩니다. 첫 번째 단계에서 얻은 데이터를 기반으로 19가지 관계 카테고리가 생성됩니다. 생성된 텍스트는 관계 카테고리가 나타나는 순서에 따라 1에 저장됩니다. txt. 두 번째 관계 카테고리는 19.txt까지 2.txt에 저장됩니다. 테스트 세트는 트레이닝 세트의 19개 카테고리 순서대로 각 샘플을 관계 카테고리에 따라 분류합니다. 즉, 동일한 관계 유형의 데이터를 텍스트 파일에 담고, 19개 카테고리의 테스트 파일도 형식은 테스트 파일과 동일하게 유지됩니다. exp1_test 폴더에 저장된 각 카테고리의 파일 이름은 여전히 1_test.txt, 2_test.txt...입니다. 동시에 원본 테스트 세트의 각 샘플 위치가 기록되며 19개의 테스트 파일에 해당합니다. 하나씩. 예를 들어 첫 번째 유형의 "소문 불화"의 각 샘플이 원본 텍스트에서 어떤 줄에 있는지 색인 파일에 기록되어 index1.txt, index2.txt... 문제 해결 아이디어 파일에 저장됩니다. 1. 첫 번째 질문은 파일 작업 및 목록에 대한 지식을 테스트하는 것입니다. 가장 어려운 점은 요구 사항에 따라 처리한 후 txt 파일이 생성되는 것입니다. 구현: import os
# 创建一个列表用来存储新的内容
list = []
with open("task1.trainSentence.new", "r",encoding='xxx') as file_input: # 打开.new文件,xxx根据自己的编码格式填写
with open("exp1_1.txt", "w", encoding='xxx') as file_output: # 打开exp1_1.txt,xxx根据自己的编码格式填写文件如果没有就创建一个
for Line in file_input: # 遍历每一行的文件
arr = Line.split('\t') # 以\t为分隔符读取
if arr[0] not in list: # if the word is not in the list
list.append(arr[0]) # add the word to the list
file_output.write(arr[0]+"\t"+arr[1]+"\t"+arr[2]+"\t"+arr[3]+"\t"+arr[4]+"\n") # write the line to the file
file_input.close() #关闭.new文件
file_output.close() #关闭创建的txt文件로그인 후 복사 2. 두 번째 질문은 여전히 파일 작업을 검사합니다. 질문 1에서 생성된 파일을 기반으로 이벤트를 동일한 유형으로 분류할 수 있는지 여부는 루프 조건을 사용하여 해결해야 합니다. 구체적인 코드를 살펴보겠습니다. import os
file_1 = open("exp1_1.txt", encoding='xxx') # 打开文件,xxx根据自己的编码格式填写
os.mkdir("exp1_train") # 创建目录
os.chdir("exp1_train") # 修改进程的工作目录(使用该目录)
a = file.readline() # 按行读取exp1_1.txt文件
arr = a.split("\t") # 按\t间隔符作为分割
b = 1 #设置分组文件的序列
file_2 = open("{}.txt".format(b), "w", encoding="xxx") # 打开文件,xxx根据自己的编码格式填写
for line in file_1: # 按行读取文件
arr_1 = line.split("\t") # 按\t间隔符作为分割
if arr[0] != arr_1[0]: # 如果读取文件的第一列内容与存入新文件的第一列类型不同
file_2.close() # 关掉该文件
b += 1 # 文件序列加一
f_2 = open("{}.txt".format(b), "w", encoding="xxx") # 创建新文件,以另一种类型分类,xxx根据自己的编码格式填写
arr = line.split("\t") # 按\t间隔符作为分割
f_2.write(arr[0]+"\t"+arr[1]+"\t"+arr[2]+"\t"+arr[3]+"t"+arr[4]+"\t""\n") # 将相同类型的文件写入
f_1.close() # 关闭题目一创建的exp1_1.txt文件
f_2.close() # 关闭创建的最后一个类型的文件로그인 후 복사 3. 문자 간의 관계에 따라 훈련 세트의 19개 카테고리를 추가로 분류하고, 사전을 통해 데이터를 탐색하고, 동일한 관계의 콘텐츠를 폴더에 넣고, 다른 경우 새 콘텐츠를 만듭니다. import os
with open("exp1_1.txt", encoding='xxx') as file_in1: # 打开文件,xxx根据自己的编码格式填写
i = 1 # 类型序列
arr2 = {} # 创建字典
for line in file_in1: # 按行遍历
arr3 = line[0:2] # 读取关系
if arr3 not in arr2.keys():
arr2[arr3] = i
i += 1 # 类型+1
file_in = open("task1.test.new") # 打开文件task1.test.new
os.mkdir("exp1_test") # 创建目录
os.chdir("exp1_test") # 修改进程的工作目录(使用该目录)
for line in file_in:
arr = line[0:2]
with open("{}_test.txt".format(arr2[arr]), "a", encoding='xxx') as file_out:
arr = line.split('\t')
file_out.write(line)
i = 1
file_in.seek(0)
os.mkdir("exp1_index")
os.chdir("exp1_index")
for line in file_in:
arr = line[0:2]
with open("index{}.txt".format(arr2[arr]), "a", encoding='xxx') as file_out:
arr = line.split('\t')
line = line[0:-1]
file_out.write(line + '\t' + "{}".format(i) + "\n")
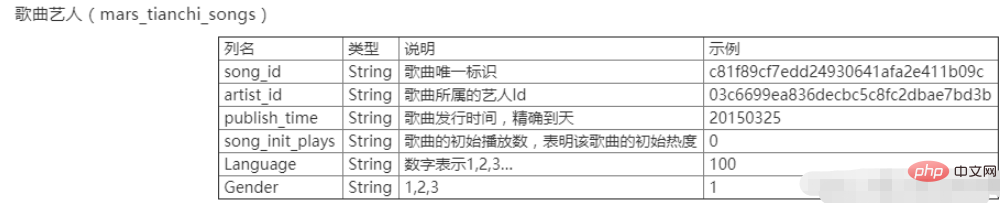
i += 1로그인 후 복사 파이썬을 사용하여 수치 데이터 처리실험 목적 파이썬의 기본 데이터 구조와 파일의 입출력을 숙지하세요. 실험 데이터 xxxx의 xx Tianchi 대회는 중국 대학의 x번째 빅데이터 챌린지의 데이터이기도 합니다. 데이터에는 두 개의 테이블, 즉 사용자 행동 테이블 mars_tianchi_user_actions.csv와 노래 아티스트 테이블 mars_tianchi_songs.csv가 포함됩니다. 본 대회에서는 샘플링된 가수 데이터와 해당 아티스트와 관련된 6개월 이내(20150301~20150831)의 사용자 행동 이력 기록을 공개합니다. 참가자는 향후 2개월, 즉 60일(20150901~20151030) 동안 아티스트의 재생 데이터를 예측해야 합니다.
실험 콘텐츠
문제 해결 아이디어: (pandas 라이브러리 사용) 1. (1) .drop_duplicates()를 사용하여 중복 값 삭제 (2) .loc[:,‘artist_id’] 사용 .value_counts() 가수가 반복한 횟수, 즉 각 가수의 노래 수를 알아보세요 (3) .loc[:,‘songs_id’].value_counts()를 사용하여 노래가 몇 곡인지 알아보세요. 반복되지 않습니다 import pandas as pd data = pd.read_csv(r"C:\mars_tianchi_songs.csv") # 读取数据 Newdata = data.drop_duplicates(subset=['artist_id']) # 删除重复值 artist_sum = Newdata['artist_id'].count() #artistChongFu_count = data.duplicated(subset=['artist_id']).count() artistChongFu_count = data.loc[:,'artist_id'].value_counts() 重复次数,即每个歌手的歌曲数目 songChongFu_count = data.loc[:,'songs_id'].value_counts() # 没有重复(歌手) artistChongFu_count.loc['artist_sum'] = artist_sum # 没有重复(歌曲)artistChongFu_count.to_csv('exp2_1.csv') # 输出文件格式为exp2_1.csv 로그인 후 복사 두 테이블을 병합하려면 merge()를 사용하세요 import pandas as pd import os data = pd.read_csv(r"C:\mars_tianchi_songs.csv") data_two = pd.read_csv(r"C:\mars_tianchi_user_actions.csv") num=pd.merge(data_two, data) num.to_csv('exp2_2.csv') 로그인 후 복사 반복 추가에는 groupby()[].sum()을 사용하세요 import pandas as pd data =pd.read_csv('exp2_2.csv') DataCHongfu = data.groupby(['artist_id','Ds'])['gmt_create'].sum()#重复项相加DataCHongfu.to_csv('exp2_3.csv') 로그인 후 복사 |
|---|


위 내용은 Python을 사용하여 텍스트 데이터를 조작하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7476
7476
 15
1377
52
77
11
49
19
19
32
15
1377
52
77
11
49
19
19
32

 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
이 기사는 MySQL 데이터베이스의 작동을 소개합니다. 먼저 MySQLworkBench 또는 명령 줄 클라이언트와 같은 MySQL 클라이언트를 설치해야합니다. 1. MySQL-Uroot-P 명령을 사용하여 서버에 연결하고 루트 계정 암호로 로그인하십시오. 2. CreateABase를 사용하여 데이터베이스를 작성하고 데이터베이스를 선택하십시오. 3. CreateTable을 사용하여 테이블을 만들고 필드 및 데이터 유형을 정의하십시오. 4. InsertInto를 사용하여 데이터를 삽입하고 데이터를 쿼리하고 업데이트를 통해 데이터를 업데이트하고 DELETE를 통해 데이터를 삭제하십시오. 이러한 단계를 마스터하고 일반적인 문제를 처리하는 법을 배우고 데이터베이스 성능을 최적화하면 MySQL을 효율적으로 사용할 수 있습니다.
 다운로드 후 MySQL을 설치할 수 없습니다
Apr 08, 2025 am 11:24 AM
다운로드 후 MySQL을 설치할 수 없습니다
Apr 08, 2025 am 11:24 AM
MySQL 설치 실패의 주된 이유는 다음과 같습니다. 1. 권한 문제, 관리자로 실행하거나 Sudo 명령을 사용해야합니다. 2. 종속성이 누락되었으며 관련 개발 패키지를 설치해야합니다. 3. 포트 충돌, 포트 3306을 차지하는 프로그램을 닫거나 구성 파일을 수정해야합니다. 4. 설치 패키지가 손상되어 무결성을 다운로드하여 확인해야합니다. 5. 환경 변수가 잘못 구성되었으며 운영 체제에 따라 환경 변수를 올바르게 구성해야합니다. 이러한 문제를 해결하고 각 단계를 신중하게 확인하여 MySQL을 성공적으로 설치하십시오.
 MySQL 다운로드 파일이 손상되어 설치할 수 없습니다. 수리 솔루션
Apr 08, 2025 am 11:21 AM
MySQL 다운로드 파일이 손상되어 설치할 수 없습니다. 수리 솔루션
Apr 08, 2025 am 11:21 AM
MySQL 다운로드 파일은 손상되었습니다. 어떻게해야합니까? 아아, mySQL을 다운로드하면 파일 손상을 만날 수 있습니다. 요즘 정말 쉽지 않습니다! 이 기사는 모든 사람이 우회를 피할 수 있도록이 문제를 해결하는 방법에 대해 이야기합니다. 읽은 후 손상된 MySQL 설치 패키지를 복구 할 수있을뿐만 아니라 향후에 갇히지 않도록 다운로드 및 설치 프로세스에 대해 더 깊이 이해할 수 있습니다. 파일 다운로드가 손상된 이유에 대해 먼저 이야기합시다. 이에 대한 많은 이유가 있습니다. 네트워크 문제는 범인입니다. 네트워크의 다운로드 프로세스 및 불안정성의 중단으로 인해 파일 손상이 발생할 수 있습니다. 다운로드 소스 자체에도 문제가 있습니다. 서버 파일 자체가 고장 났으며 물론 다운로드하면 고장됩니다. 또한 일부 안티 바이러스 소프트웨어의 과도한 "열정적 인"스캔으로 인해 파일 손상이 발생할 수 있습니다. 진단 문제 : 파일이 실제로 손상되었는지 확인하십시오
 MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 기본 데이터 저장 및 관리를위한 네트워크 연결없이 실행할 수 있습니다. 그러나 다른 시스템과의 상호 작용, 원격 액세스 또는 복제 및 클러스터링과 같은 고급 기능을 사용하려면 네트워크 연결이 필요합니다. 또한 보안 측정 (예 : 방화벽), 성능 최적화 (올바른 네트워크 연결 선택) 및 데이터 백업은 인터넷에 연결하는 데 중요합니다.
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 MySQL 설치 후 시작할 수없는 서비스에 대한 솔루션
Apr 08, 2025 am 11:18 AM
MySQL 설치 후 시작할 수없는 서비스에 대한 솔루션
Apr 08, 2025 am 11:18 AM
MySQL이 시작을 거부 했습니까? 당황하지 말고 확인합시다! 많은 친구들이 MySQL을 설치 한 후 서비스를 시작할 수 없다는 것을 알았으며 너무 불안했습니다! 걱정하지 마십시오.이 기사는 침착하게 다루고 그 뒤에있는 마스터 마인드를 찾을 수 있습니다! 그것을 읽은 후에는이 문제를 해결할뿐만 아니라 MySQL 서비스에 대한 이해와 문제 해결 문제에 대한 아이디어를 향상시키고보다 강력한 데이터베이스 관리자가 될 수 있습니다! MySQL 서비스는 시작되지 않았으며 간단한 구성 오류에서 복잡한 시스템 문제에 이르기까지 여러 가지 이유가 있습니다. 가장 일반적인 측면부터 시작하겠습니다. 기본 지식 : 서비스 시작 프로세스 MySQL 서비스 시작에 대한 간단한 설명. 간단히 말해서 운영 체제는 MySQL 관련 파일을로드 한 다음 MySQL 데몬을 시작합니다. 여기에는 구성이 포함됩니다
 MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 성능 최적화는 설치 구성, 인덱싱 및 쿼리 최적화, 모니터링 및 튜닝의 세 가지 측면에서 시작해야합니다. 1. 설치 후 innodb_buffer_pool_size 매개 변수와 같은 서버 구성에 따라 my.cnf 파일을 조정해야합니다. 2. 과도한 인덱스를 피하기 위해 적절한 색인을 작성하고 Execution 명령을 사용하여 실행 계획을 분석하는 것과 같은 쿼리 문을 최적화합니다. 3. MySQL의 자체 모니터링 도구 (showprocesslist, showstatus)를 사용하여 데이터베이스 건강을 모니터링하고 정기적으로 백업 및 데이터베이스를 구성하십시오. 이러한 단계를 지속적으로 최적화함으로써 MySQL 데이터베이스의 성능을 향상시킬 수 있습니다.
