

Python Matplotlib 라이브러리를 사용하여 차트를 그리는 단계와 방법은 무엇입니까?

중국어 글꼴 설정:
# 字体设置 plt.rcParams['font.sans-serif'] = ["SimHei"] plt.rcParams["axes.unicode_minus"] = False
1. 기본 사용법
Matplotlib: Python 2D 도면 라이브러리입니다. Matplotlib을 통해 개발자는 단 몇 줄의 코드로 선형 차트와 히스토그램을 생성할 수 있습니다. 차트, 원형 차트, 분산형 차트 등 plot是一个画图的函数,他的参数:plot([x],y,[fmt],data=None,**kwargs)
1.1, 선 스타일 및 색상
(1) 점선 형태
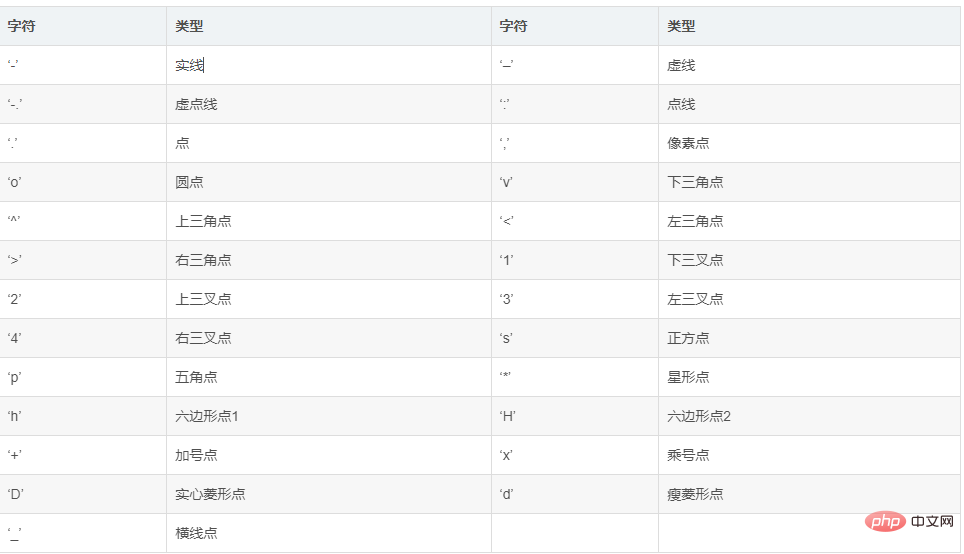
(2) 선 색상
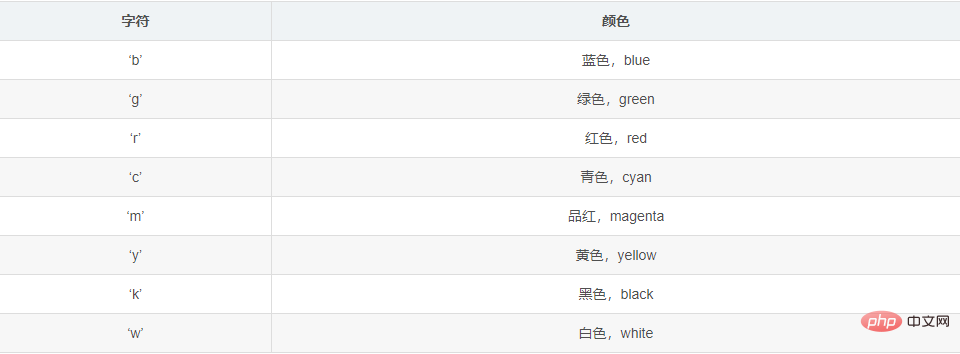
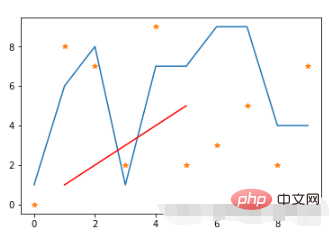
import matplotlib.pyplot as plt import numpy as np # 原始线图 plt.plot(range(10),[np.random.randint(0,10) for x in range(10)]) # 点线图 plt.plot(range(10),[np.random.randint(0,10) for x in range(10)],"*") # 线条颜色 plt.plot([1,2,3,4,5],[1,2,3,4,5],'r') #将颜色线条设置成红色
실행 결과:
1.2 축 및 제목
1. 그림 제목 설정: plt.title
2. 축 제목 설정: plt.xlabel & plt.ylabel - 제목 이름
3. 축 배율 설정: plt.xticks & plt. yticks - 척도 길이, 척도 제목
예:
x = range(10)
y = [np.random.randint(0,10) for x in range(10)]
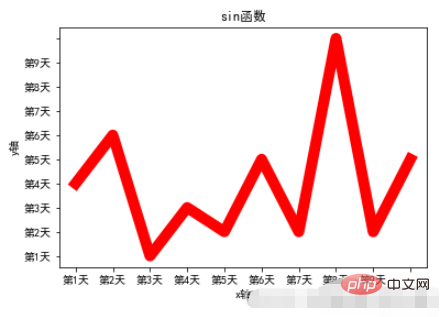
plt.plot(x,y,linewidth=10,color='red')
# 设置图标题
plt.title("sin函数")
# 设置轴标题
plt.xlabel("x轴")
plt.ylabel("y轴")
# 设置轴刻度
plt.xticks(range(10),["第%d天"%x for x in range(1,10)])
plt.yticks(range(10),["第%d天"%x for x in range(1,10)])
# 加载字体
plt.rcParams['font.sans-serif'] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False실행 결과:
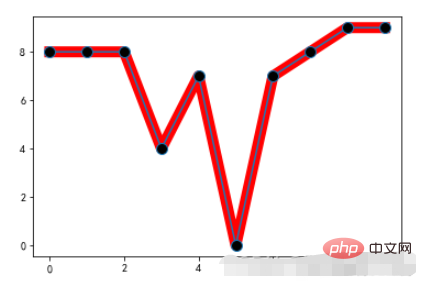
1.3, 마커 설정
marker:关键点重点标记
예:
x = range(10) y = [np.random.randint(0,10) for x in range(10)] plt.plot(x,y,linewidth=10,color='red') # 重点标记 plt.plot(x,y,marker="o",markerfacecolor='k',markersize=10)
실행 결과:
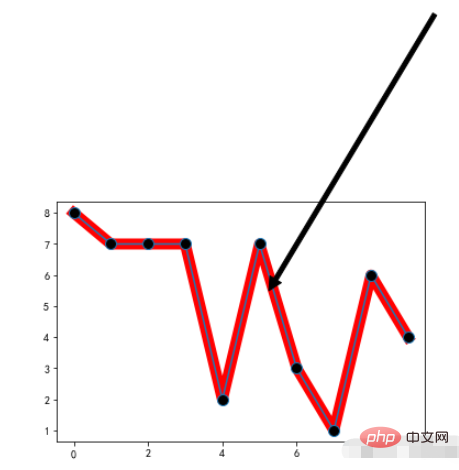
1.4. 댓글 텍스트
annotate:注释文本
예:
x = range(10)
y = [np.random.randint(0,10) for x in range(10)]
plt.plot(x,y,linewidth=10,color='red')
# 重点标记
plt.plot(x,y,marker="o",markerfacecolor='k',markersize=10)
# 注释文本设置
plt.annotate('local max', xy=(5, 5), xytext=(10,15),
arrowprops=dict(facecolor='black',shrink=0.05),
)실행 결과:
1.5 그래픽 스타일 설정
plt.figure:调整图片的大小和像素 `num`:图的编号, `figsize`:单位是英寸, `dpi`:每英寸的像素点, `facecolor`:图片背景颜色, `edgecolor`:边框颜色, `frameon`:是否绘制画板。
예:
x = range(10) y = [np.random.randint(0,10) for x in range(10)] # 设置图形样式 plt.figure(figsize=(20,10),dpi=80) plt.plot(x,y,linewidth=10,color='red')
실행 결과:
2, 막대 차트
응용 시나리오:
1.
2. 빈도 통계.
관련 매개변수:
barh: 막대 차트
1. `x`: 그릴 막대 차트의 X축 좌표 지점을 나타내는 배열 또는 목록입니다.
2. `height`: 그릴 막대 차트의 y축 좌표 지점을 나타내는 배열 또는 목록입니다.
3. `너비`: 각 막대 차트의 너비, 기본값은 0.8 너비입니다.
4. `bottom`: `y`축의 기준선, 기본값은 0, 즉 하단으로부터의 거리가 0입니다.
5. `align`: 정렬, 기본값은 `입니다. 지정된 `x` 좌표는 중앙에 정렬되고, `edge`는 가장자리에 정렬됩니다. 오른쪽인지 왼쪽인지는 `width`의 양수 또는 음수 값에 따라 달라집니다.
6. `color`: 막대 차트의 색상입니다.
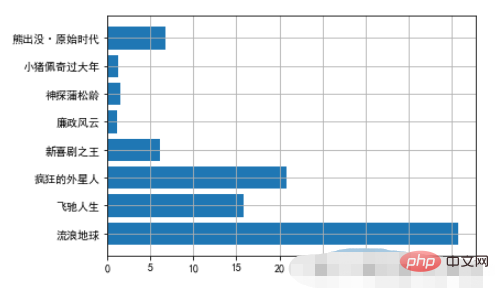
2.1. 가로 막대 차트 예시
movies = {
"流浪地球":40.78,
"飞驰人生":15.77,
"疯狂的外星人":20.83,
"新喜剧之王":6.10,
"廉政风云":1.10,
"神探蒲松龄":1.49,
"小猪佩奇过大年":1.22,
"熊出没·原始时代":6.71
}
plt.barh(np.arange(len(movies)),list(movies.values()))
plt.yticks(np.arange(len(movies)),list(movies.keys()),fontproperties=font)
plt.grid()실행 결과
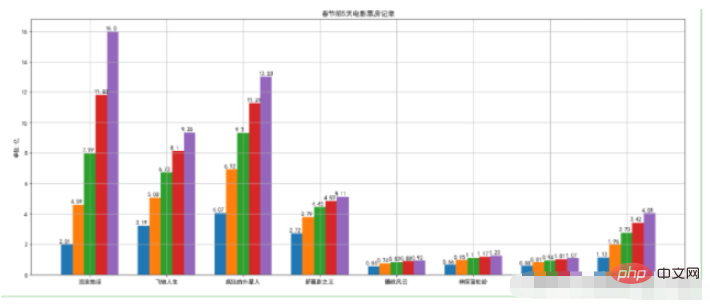
2.2. 그룹 막대 차트
예:
movies = {
"流浪地球":[2.01,4.59,7.99,11.83,16],
"飞驰人生":[3.19,5.08,6.73,8.10,9.35],
"疯狂的外星人":[4.07,6.92,9.30,11.29,13.03],
"新喜剧之王":[2.72,3.79,4.45,4.83,5.11],
"廉政风云":[0.56,0.74,0.83,0.88,0.92],
"神探蒲松龄":[0.66,0.95,1.10,1.17,1.23],
"小猪佩奇过大年":[0.58,0.81,0.94,1.01,1.07],
"熊出没·原始时代":[1.13,1.96,2.73,3.42,4.05]
}
plt.figure(figsize=(20,8))
width = 0.75
bin_width = width/5
movie_pd = pd.DataFrame(movies)
ind = np.arange(0,len(movies))
# 第一种方案
for index in movie_pd.index:
day_tickets = movie_pd.iloc[index]
xs = ind-(bin_width*(2-index))
plt.bar(xs,day_tickets,width=bin_width,label="第%d天"%(index+1))
for ticket,x in zip(day_tickets,xs):
plt.annotate(ticket,xy=(x,ticket),xytext=(x-0.1,ticket+0.1))
# 设置图例
plt.ylabel("单位:亿")
plt.title("春节前5天电影票房记录")
# 设置x轴的坐标
plt.xticks(ind,movie_pd.columns)
plt.xlim
plt.grid(True)
plt.show()실행 결과:
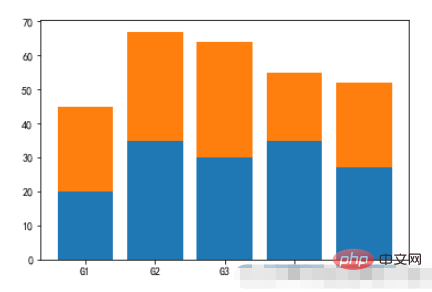
2.3, 누적 막대 모양 그래프
예:
menMeans = (20, 35, 30, 35, 27) womenMeans = (25, 32, 34, 20, 25) groupNames = ('G1','G2','G3','G4','G5') xs = np.arange(len(menMeans)) plt.bar(xs,menMeans) plt.bar(xs,womenMeans,bottom=menMeans) plt.xticks(xs,groupNames) plt.show()
실행 결과:
3, Histogram
plt.hist: Histogram
1. 반복됨
-
2. bins: 숫자 또는 시퀀스(배열/목록 등);
3. 범위: 튜플 또는 None, 분할할 `x`의 최대값과 최소값을 지정합니다. 간격;
4. 기본값은 'False'이며, 'True'와 같으면 빈도 분포 히스토그램이 사용됩니다.
5. 'True'와 같으면 반환 값의 첫 번째 매개변수가 계속 누적되어 최종적으로 '1'과 같습니다.
응용 시나리오:
1. 각 그룹의 데이터 수 분포를 표시합니다.
2. 비정상적이거나 고립된 데이터를 관찰하는 데 사용됩니다.
3.추출된 표본 수가 너무 적으면 큰 오류가 발생하고 신뢰도가 낮아지며 통계적 유의성이 상실됩니다. 따라서 샘플 수는 50개 이상이어야 합니다.
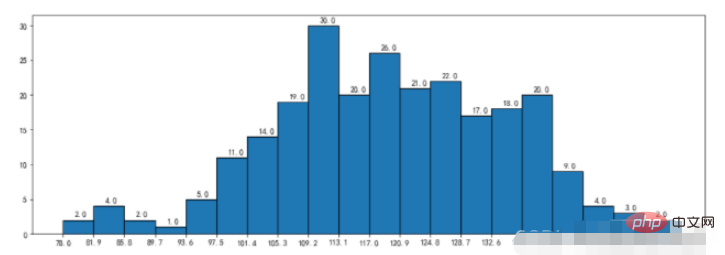
3.1, 히스토그램
예:
durations = [131, 98, 125, 131, 124, 139, 131, 117, 128, 108, 135, 138, 131, 102, 107, 114, 119, 128, 121, 142, 127, 130, 124, 101, 110, 116, 117, 110, 128, 128, 115, 99, 136, 126, 134, 95, 138, 117, 111,78, 132, 124, 113, 150, 110, 117, 86, 95, 144, 105, 126, 130,126, 130, 126, 116, 123, 106, 112, 138, 123, 86, 101, 99, 136,123, 117, 119, 105, 137, 123, 128, 125, 104, 109, 134, 125, 127,105, 120, 107, 129, 116, 108, 132, 103, 136, 118, 102, 120, 114,105, 115, 132, 145, 119, 121, 112, 139, 125, 138, 109, 132, 134,156, 106, 117, 127, 144, 139, 139, 119, 140, 83, 110, 102,123,107, 143, 115, 136, 118, 139, 123, 112, 118, 125, 109, 119, 133,112, 114, 122, 109, 106, 123, 116, 131, 127, 115, 118, 112, 135,115, 146, 137, 116, 103, 144, 83, 123, 111, 110, 111, 100, 154,136, 100, 118, 119, 133, 134, 106, 129, 126, 110, 111, 109, 141,120, 117, 106, 149, 122, 122, 110, 118, 127, 121, 114, 125, 126,114, 140, 103, 130, 141, 117, 106, 114, 121, 114, 133, 137, 92,121, 112, 146, 97, 137, 105, 98, 117, 112, 81, 97, 139, 113,134, 106, 144, 110, 137, 137, 111, 104, 117, 100, 111, 101, 110,105, 129, 137, 112, 120, 113, 133, 112, 83, 94, 146, 133, 101,131, 116, 111, 84, 137, 115, 122, 106, 144, 109, 123, 116, 111,111, 133, 150]
plt.figure(figsize=(15,5))
nums,bins,patches = plt.hist(durations,bins=20,edgecolor='k')
plt.xticks(bins,bins)
for num,bin in zip(nums,bins):
plt.annotate(num,xy=(bin,num),xytext=(bin+1.5,num+0.5))
plt.show()실행 결과:
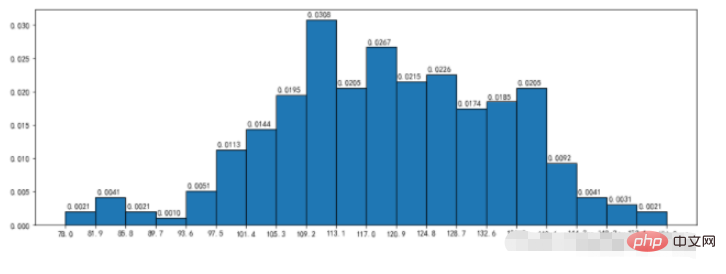
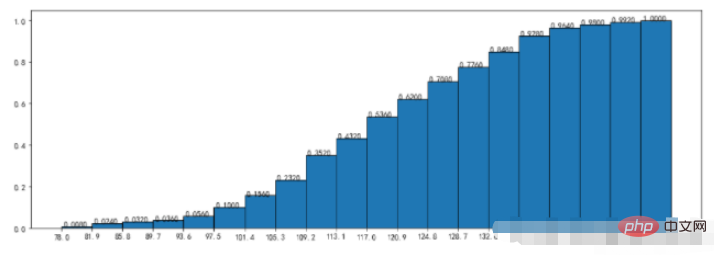
3.2、频率直方图
density:频率直方分布图
范例:
nums,bins,patches = plt.hist(durations,bins=20,edgecolor='k',density=True,cumulative=True)
plt.xticks(bins,bins)
for num,bin in zip(nums,bins):
plt.annotate("%.4f"%num,xy=(bin,num),xytext=(bin+0.2,num+0.0005))运行结果:
3.3、直方图
cumulative参数:nums的总和为1
范例:
plt.figure(figsize=(15,5))
nums,bins,patches = plt.hist(durations,bins=20,edgecolor='k',density=True,cumulative=True)
plt.xticks(bins,bins)
for num,bin in zip(nums,bins):
plt.annotate("%.4f"%num,xy=(bin,num),xytext=(bin+0.2,num+0.0005))运行结果:
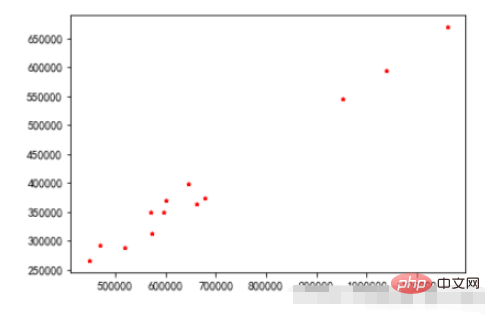
4、散点图
plt.scatter:散点图绘制:
1. x,y:分别是x轴和y轴的数据集。两者的数据长度必须一致。
2. s:点的尺寸。
3. c:点的颜色。
4. marker:标记点,默认是圆点,也可以换成其他的。
范例:
plt.scatter(x =data_month_sum["sumprice"] #传入X变量数据
,y=data_month_sum["Quantity"] #传入Y变量数据
,marker='*' #点的形状
,s=10 #点的大小
,c='r' #点的颜色
)
plt.show()运行结果:
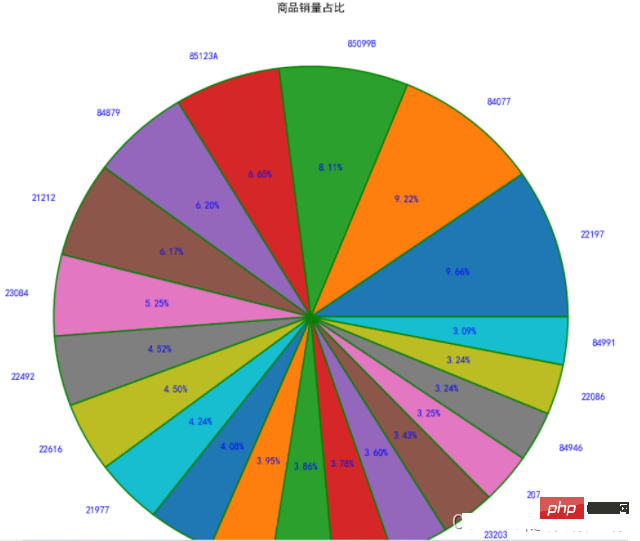
5、饼图
饼图:一个划分为几个扇形的圆形统计图表,用于描述量、频率或百分比之间的相对关系的。
在matplotlib中,可以通过plt.pie来实现,其中的参数如下:
x:饼图的比例序列。labels:饼图上每个分块的名称文字。explode:设置某几个分块是否要分离饼图。autopct:设置比例文字的展示方式。比如保留几个小数等。shadow:是否显示阴影。textprops:文本的属性(颜色,大小等)。 范例
plt.figure(figsize=(8,8),dpi=100,facecolor='white')
plt.pie(x = StockCode.values, #数据传入
radius=1.5, #半径
autopct='%.2f%%' #百分比显示
,pctdistance=0.6, #百分比距离圆心比例
labels=StockCode.index, #标签
labeldistance=1.1, #标签距离圆心比例
wedgeprops ={'linewidth':1.5,'edgecolor':'green'}, #边框的线宽和颜色
textprops={'fontsize':10,'color':'blue'}) #文本字体大小和颜色
plt.title('商品销量占比',pad=100) #设置标题及距离坐标轴的位置
plt.show()运行结果:
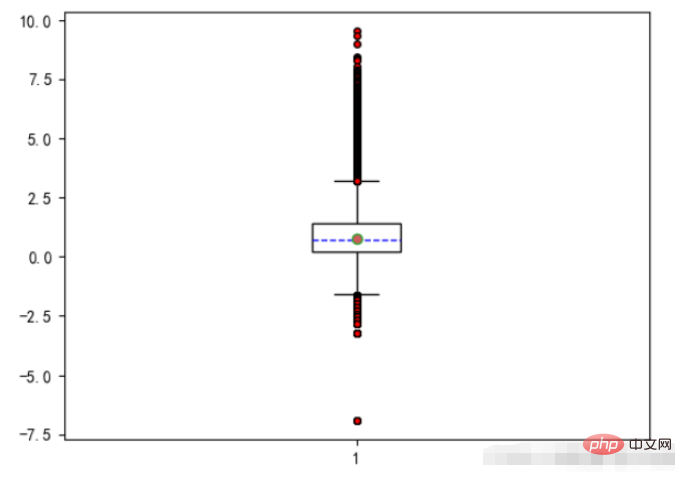
6、箱线图
箱图的绘制方法是:
:1、先找出一组数据的上限值、下限值、中位数(Q2)和下四分位数(Q1)以及上四分位数(Q3)
:2、然后连接两个四分位数画出箱子
:3、再将最大值和最小值与箱子相连接,中位数在箱子中间。
中位数:把数据按照从小到大的顺序排序,然后最中间的那个值为中位数,如果数据的个数为偶数,那么就是最中间的两个数的平均数为中位数。
上下四分位数:同样把数据排好序后,把数据等分为4份。出现在`25%`位置的叫做下四分位数,出现在`75%`位置上的数叫做上四分位数。但是四分位数位置的确定方法不是固定的,有几种算法,每种方法得到的结果会有一定差异,但差异不会很大。
上下限的计算规则是:
IQR=Q3-Q1
上限=Q3+1.5IQR
下限=Q1-1.5IQR
在matplotlib中有plt.boxplot来绘制箱线图,这个方法的相关参数如下:
x:需要绘制的箱线图的数据。notch:是否展示置信区间,默认是False。如果设置为True,那么就会在盒子上展示一个缺口。sym:代表异常点的符号表示,默认是小圆点。vert:是否是垂直的,默认是True,如果设置为False那么将水平方向展示。whis:上下限的系数,默认是1.5,也就是上限是Q3+1.5IQR,可以改成其他的。也可以为一个序列,如果是序列,那么序列中的两个值分别代表的就是下限和上限的值,而不是再需要通过IQR来计算。positions:设置每个盒子的位置。widths:设置每个盒子的宽度。labels:每个盒子的label。meanline和showmeans:如果这两个都为True,那么将会绘制平均值的的线条。
范例:
#箱线图 - 主要观察数据是否有异常(离群点)
#箱须-75%和25%的分位数+/-1.5倍分位差
plt.figure(figsize=(6.4,4.8),dpi=100)
#是否填充箱体颜色,是否展示均值,是否展示异常值,箱体设置,异常值设置,均值设置,中位数设置
plt.boxplot(x=UnitPrice #传入数据
,patch_artist=True #是否填充箱体颜色
,showmeans=True #是否展示均值
,showfliers=True #是否展示异常值
,boxprops={'color':'black','facecolor':'white'} #箱体设置
,flierprops={'marker':'o','markersize':4,'markerfacecolor':'red'} #异常值设置
,meanprops={'marker':'o','markersize':6,'markerfacecolor':'indianred'} #均值设置
,medianprops={'linestyle':'--','color':'blue'} #中位数设置
)
plt.show()运行结果:
7、雷达图
雷达图:又被叫做蜘蛛网图,适用于显示三个或更多的维度的变量的强弱情况
plt.polar来绘制雷达图,x轴的坐标点应该为弧度(2*PI=360°)
范例:
import numpy as np properties = ['输出','KDA','发育','团战','生存'] values = [40,91,44,90,95,40] theta = np.linspace(0,np.pi*2,6) plt.polar(theta,values) plt.xticks(theta,properties) plt.fill(theta,values)
运行结果:
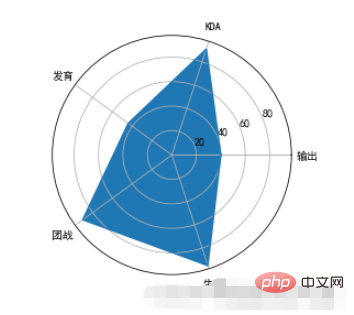
注意事项:
폴라는 선의 닫힌 그림을 완성하지 못하기 때문에 그림을 그릴 때 끝에세타와값을 넣어야 합니다. 0번째 위치의 값을 반복적으로 입력한 후 그릴 때 첫 번째 점으로 닫을 수 있습니다.polar并不会完成线条的闭合绘制,所以我们在绘制的时候需要在theta中和values中在最后多重复添加第0个位置的值,然后在绘制的时候就可以和第1个点进行闭合了。polar只是绘制线条,所以如果想要把里面进行颜色填充,那么需要调用fill函数来实现。polar默认的圆圈的坐标是角度,如果我们想要改成文字显示,那么可以通过xticks
pole은 선만 그리는 것이므로 색상으로 채우려면 fill 함수를 호출해야 합니다. 🎜🎜🎜🎜극좌표기본 원 좌표는 각도입니다. 텍스트 표시로 변경하려면 xticks를 통해 설정할 수 있습니다. 🎜🎜🎜위 내용은 Python Matplotlib 라이브러리를 사용하여 차트를 그리는 단계와 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7470
7470
 15
1377
52
77
11
48
19
19
29
15
1377
52
77
11
48
19
19
29

 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
이 기사는 MySQL 데이터베이스의 작동을 소개합니다. 먼저 MySQLworkBench 또는 명령 줄 클라이언트와 같은 MySQL 클라이언트를 설치해야합니다. 1. MySQL-Uroot-P 명령을 사용하여 서버에 연결하고 루트 계정 암호로 로그인하십시오. 2. CreateABase를 사용하여 데이터베이스를 작성하고 데이터베이스를 선택하십시오. 3. CreateTable을 사용하여 테이블을 만들고 필드 및 데이터 유형을 정의하십시오. 4. InsertInto를 사용하여 데이터를 삽입하고 데이터를 쿼리하고 업데이트를 통해 데이터를 업데이트하고 DELETE를 통해 데이터를 삭제하십시오. 이러한 단계를 마스터하고 일반적인 문제를 처리하는 법을 배우고 데이터베이스 성능을 최적화하면 MySQL을 효율적으로 사용할 수 있습니다.
 MySQL 다운로드 파일이 손상되어 설치할 수 없습니다. 수리 솔루션
Apr 08, 2025 am 11:21 AM
MySQL 다운로드 파일이 손상되어 설치할 수 없습니다. 수리 솔루션
Apr 08, 2025 am 11:21 AM
MySQL 다운로드 파일은 손상되었습니다. 어떻게해야합니까? 아아, mySQL을 다운로드하면 파일 손상을 만날 수 있습니다. 요즘 정말 쉽지 않습니다! 이 기사는 모든 사람이 우회를 피할 수 있도록이 문제를 해결하는 방법에 대해 이야기합니다. 읽은 후 손상된 MySQL 설치 패키지를 복구 할 수있을뿐만 아니라 향후에 갇히지 않도록 다운로드 및 설치 프로세스에 대해 더 깊이 이해할 수 있습니다. 파일 다운로드가 손상된 이유에 대해 먼저 이야기합시다. 이에 대한 많은 이유가 있습니다. 네트워크 문제는 범인입니다. 네트워크의 다운로드 프로세스 및 불안정성의 중단으로 인해 파일 손상이 발생할 수 있습니다. 다운로드 소스 자체에도 문제가 있습니다. 서버 파일 자체가 고장 났으며 물론 다운로드하면 고장됩니다. 또한 일부 안티 바이러스 소프트웨어의 과도한 "열정적 인"스캔으로 인해 파일 손상이 발생할 수 있습니다. 진단 문제 : 파일이 실제로 손상되었는지 확인하십시오
 다운로드 후 MySQL을 설치할 수 없습니다
Apr 08, 2025 am 11:24 AM
다운로드 후 MySQL을 설치할 수 없습니다
Apr 08, 2025 am 11:24 AM
MySQL 설치 실패의 주된 이유는 다음과 같습니다. 1. 권한 문제, 관리자로 실행하거나 Sudo 명령을 사용해야합니다. 2. 종속성이 누락되었으며 관련 개발 패키지를 설치해야합니다. 3. 포트 충돌, 포트 3306을 차지하는 프로그램을 닫거나 구성 파일을 수정해야합니다. 4. 설치 패키지가 손상되어 무결성을 다운로드하여 확인해야합니다. 5. 환경 변수가 잘못 구성되었으며 운영 체제에 따라 환경 변수를 올바르게 구성해야합니다. 이러한 문제를 해결하고 각 단계를 신중하게 확인하여 MySQL을 성공적으로 설치하십시오.
 MySQL 설치 후 시작할 수없는 서비스에 대한 솔루션
Apr 08, 2025 am 11:18 AM
MySQL 설치 후 시작할 수없는 서비스에 대한 솔루션
Apr 08, 2025 am 11:18 AM
MySQL이 시작을 거부 했습니까? 당황하지 말고 확인합시다! 많은 친구들이 MySQL을 설치 한 후 서비스를 시작할 수 없다는 것을 알았으며 너무 불안했습니다! 걱정하지 마십시오.이 기사는 침착하게 다루고 그 뒤에있는 마스터 마인드를 찾을 수 있습니다! 그것을 읽은 후에는이 문제를 해결할뿐만 아니라 MySQL 서비스에 대한 이해와 문제 해결 문제에 대한 아이디어를 향상시키고보다 강력한 데이터베이스 관리자가 될 수 있습니다! MySQL 서비스는 시작되지 않았으며 간단한 구성 오류에서 복잡한 시스템 문제에 이르기까지 여러 가지 이유가 있습니다. 가장 일반적인 측면부터 시작하겠습니다. 기본 지식 : 서비스 시작 프로세스 MySQL 서비스 시작에 대한 간단한 설명. 간단히 말해서 운영 체제는 MySQL 관련 파일을로드 한 다음 MySQL 데몬을 시작합니다. 여기에는 구성이 포함됩니다
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 성능 최적화는 설치 구성, 인덱싱 및 쿼리 최적화, 모니터링 및 튜닝의 세 가지 측면에서 시작해야합니다. 1. 설치 후 innodb_buffer_pool_size 매개 변수와 같은 서버 구성에 따라 my.cnf 파일을 조정해야합니다. 2. 과도한 인덱스를 피하기 위해 적절한 색인을 작성하고 Execution 명령을 사용하여 실행 계획을 분석하는 것과 같은 쿼리 문을 최적화합니다. 3. MySQL의 자체 모니터링 도구 (showprocesslist, showstatus)를 사용하여 데이터베이스 건강을 모니터링하고 정기적으로 백업 및 데이터베이스를 구성하십시오. 이러한 단계를 지속적으로 최적화함으로써 MySQL 데이터베이스의 성능을 향상시킬 수 있습니다.
 MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 기본 데이터 저장 및 관리를위한 네트워크 연결없이 실행할 수 있습니다. 그러나 다른 시스템과의 상호 작용, 원격 액세스 또는 복제 및 클러스터링과 같은 고급 기능을 사용하려면 네트워크 연결이 필요합니다. 또한 보안 측정 (예 : 방화벽), 성능 최적화 (올바른 네트워크 연결 선택) 및 데이터 백업은 인터넷에 연결하는 데 중요합니다.
