

Java Stream API에서 터미널 동작 예시 분석

1. Java Stream 파이프라인 데이터 처리 작업
이번 호 이전에 쓴 글에서 Java Stream 파이프라인 스트림은 컬렉션 클래스 요소의 처리를 단순화하는 데 사용되는 Java API라고 소개한 적이 있습니다. 사용과정은 3단계로 나누어집니다. 이 기사를 시작하기 전에 그림에 표시된 대로 이 세 단계를 새로운 친구들에게 소개해야 한다고 생각합니다.
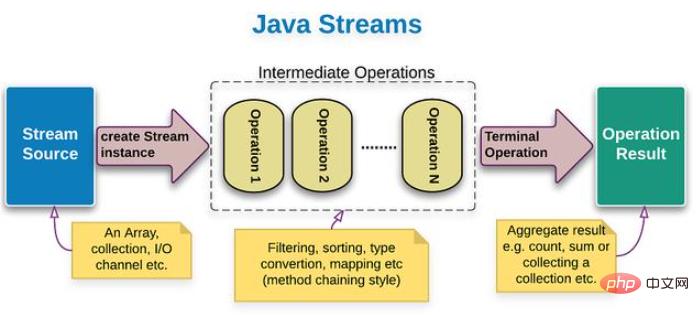
첫 번째 단계(그림의 파란색): 컬렉션, 배열 또는 라인 변환 텍스트 파일 Java Stream 파이프라인 흐름
의 두 번째 단계(그림에서 점선 부분): 파이프라인 스트리밍 데이터 처리 작업, 파이프라인의 각 요소를 처리합니다. 이전 파이프의 출력 요소는 다음 파이프의 입력 요소로 사용됩니다.
세 번째 단계(그림에서 녹색): 이 글의 핵심 내용인 파이프라인 흐름 결과 처리 작업입니다.
학습을 시작하기 전에 이전에 말씀드린 예제를 검토해야 합니다.
List<String> nameStrs = Arrays.asList("Monkey", "Lion", "Giraffe","Lemur");
List<String> list = nameStrs.stream()
.filter(s -> s.startsWith("L"))
.map(String::toUpperCase)
.sorted()
.collect(toList());
System.out.println(list);먼저 stream() 메서드를 사용하여 문자열 List를 파이프라인 스트림 Stream으로 변환합니다
그런 다음 파이프라인 데이터 처리 작업을 수행합니다. , 먼저 필터 함수를 사용하여 대문자 L로 시작하는 모든 문자열을 필터링한 다음 파이프라인의 문자열을 대문자 toUpperCase로 변환한 다음 sorted 메서드를 호출하여 정렬합니다. 이러한 API의 사용법은 이 문서의 이전 문서에서 소개되었습니다. 람다 표현식과 함수 참조도 사용됩니다.
마지막으로 결과 처리를 위해 수집 기능을 사용하여 Java Stream 파이프라인 스트림을 목록으로 변환합니다. 목록의 최종 출력은 다음과 같습니다. [LEMUR, LION][LEMUR, LION]
如果你不使用java Stream管道流的话,想一想你需要多少行代码完成上面的功能呢?回到正题,这篇文章就是要给大家介绍第三阶段:对管道流处理结果都可以做哪些操作呢?下面开始吧!
二、ForEach和ForEachOrdered
如果我们只是希望将Stream管道流的处理结果打印出来,而不是进行类型转换,我们就可以使用forEach()方法或forEachOrdered()方法。
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEach(System.out::println);
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEachOrdered(System.out::println);parallel()函数表示对管道中的元素进行并行处理,而不是串行处理,这样处理速度更快。但是这样就有可能导致管道流中后面的元素先处理,前面的元素后处理,也就是元素的顺序无法保证
forEachOrdered从名字上看就可以理解,虽然在数据处理顺序上可能无法保障,但是forEachOrdered方法可以在元素输出的顺序上保证与元素进入管道流的顺序一致。也就是下面的样子(forEach方法则无法保证这个顺序):
Monkey
Lion
Giraffe
Lemur
Lion
三、元素的收集collect
java Stream 最常见的用法就是:一将集合类转换成管道流,二对管道流数据处理,三将管道流处理结果在转换成集合类。那么collect()方法就为我们提供了这样的功能:将管道流处理结果在转换成集合类。
3.1.收集为Set
通过Collectors.toSet()方法收集Stream的处理结果,将所有元素收集到Set集合中。
Set<String> collectToSet = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ) .collect(Collectors.toSet()); //最终collectToSet 中的元素是:[Monkey, Lion, Giraffe, Lemur],注意Set会去重。
3.2.收集到List
同样,可以将元素收集到List使用toList()收集器中。
List<String> collectToList = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ).collect(Collectors.toList()); // 最终collectToList中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
3.3.通用的收集方式
上面为大家介绍的元素收集方式,都是专用的。比如使用Collectors.toSet()收集为Set类型集合;使用Collectors.toList()收集为List类型集合。那么,有没有一种比较通用的数据元素收集方式,将数据收集为任意的Collection接口子类型。 所以,这里就像大家介绍一种通用的元素收集方式,你可以将数据元素收集到任意的Collection类型:即向所需Collection类型提供构造函数的方式。
LinkedList<String> collectToCollection = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ).collect(Collectors.toCollection(LinkedList::new)); //最终collectToCollection中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
注意:代码中使用了LinkedList::new,实际是调用LinkedList的构造函数,将元素收集到Linked List。当然你还可以使用诸如LinkedHashSet::new和PriorityQueue::new将数据元素收集为其他的集合类型,这样就比较通用了。
3.4.收集到Array
通过toArray(String[]::new)方法收集Stream的处理结果,将所有元素收集到字符串数组中。
String[] toArray = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ) .toArray(String[]::new); //最终toArray字符串数组中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
3.5.收集到Map
使用Collectors.toMap()方法将数据元素收集到Map里面,但是出现一个问题:那就是管道中的元素是作为key,还是作为value。我们用到了一个Function.identity()方法,该方法很简单就是返回一个“ t -> t ”(输入就是输出的lambda表达式)。另外使用管道流处理函数distinct()
Map<String, Integer> toMap = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.distinct()
.collect(Collectors.toMap(
Function.identity(), //元素输入就是输出,作为key
s -> (int) s.chars().distinct().count()// 输入元素的不同的字母个数,作为value
));
// 最终toMap的结果是: {Monkey=6, Lion=4, Lemur=5, Giraffe=6}🎜Monkey🎜Three elementscollect🎜🎜java Stream의 가장 일반적인 사용법은 다음과 같습니다. 첫째, 컬렉션 클래스를 파이프라인 스트림으로 변환하고, 둘째, 파이프라인 스트림 데이터를 처리하고, 셋째, 파이프라인 스트림 처리 결과를 컬렉션 클래스로 변환합니다. 그런 다음 Collect() 메서드는 파이프라인 스트림 처리 결과를 컬렉션 클래스로 변환하는 기능을 제공합니다. 🎜🎜3.1. Collect as Set🎜🎜 Collectors.toSet() 메서드를 통해 Stream의 처리 결과를 수집하고 모든 요소를 Set 컬렉션으로 수집합니다. 🎜
Lion
Giraffe
Lemur
Lion🎜
Map<Character, List<String>> groupingByList = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.collect(Collectors.groupingBy(
s -> s.charAt(0) , //根据元素首字母分组,相同的在一组
// counting() // 加上这一行代码可以实现分组统计
));
// 最终groupingByList内的元素: {G=[Giraffe], L=[Lion, Lemur, Lion], M=[Monkey]}
//如果加上counting() ,结果是: {G=1, L=3, M=1}toList() 수집기를 사용하여 요소를 List로 수집할 수 있습니다. 🎜boolean containsTwo = IntStream.of(1, 2, 3).anyMatch(i -> i == 2);
// 判断管道中是否包含2,结果是: true
long nrOfAnimals = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur"
).count();
// 管道中元素数据总计结果nrOfAnimals: 4
int sum = IntStream.of(1, 2, 3).sum();
// 管道中元素数据累加结果sum: 6
OptionalDouble average = IntStream.of(1, 2, 3).average();
//管道中元素数据平均值average: OptionalDouble[2.0]
int max = IntStream.of(1, 2, 3).max().orElse(0);
//管道中元素数据最大值max: 3
IntSummaryStatistics statistics = IntStream.of(1, 2, 3).summaryStatistics();
// 全面的统计结果statistics: IntSummaryStatistics{count=3, sum=6, min=1, average=2.000000, max=3}LinkedHashSet::new 및 PriorityQueue::new와 같은 메서드를 사용하여 데이터 요소를 다른 컬렉션 유형으로 수집할 수도 있으며 이는 보다 다양한 용도로 사용할 수 있습니다. 🎜🎜3.4. Array로 수집🎜🎜 toArray(String[]::new) 메소드를 통해 Stream의 처리 결과를 수집하고 모든 요소를 문자열 배열로 수집합니다. 🎜rrreee🎜3.5. Map으로 수집🎜🎜 Collectors.toMap() 메서드를 사용하여 데이터 요소를 Map으로 수집하지만 문제가 있습니다. 파이프라인의 요소가 키로 사용되는지 아니면 값으로 사용되는지입니다. 우리는 단순히 "t -> t"를 반환하는 Function.identity() 메서드를 사용했습니다(입력은 출력의 람다 표현식임). 또한 파이프라인 스트림 처리 함수 distinct()를 사용하여 맵 키 값의 고유성을 보장합니다. 🎜rrreee🎜3.6. GroupingBy🎜🎜Collectors.groupingBy는 요소의 그룹화 컬렉션을 구현하는 데 사용됩니다. 다음 코드는 첫 글자를 기반으로 다양한 데이터 요소를 다양한 목록으로 수집하고 이를 지도로 캡슐화하는 방법을 보여줍니다. 🎜Map<Character, List<String>> groupingByList = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.collect(Collectors.groupingBy(
s -> s.charAt(0) , //根据元素首字母分组,相同的在一组
// counting() // 加上这一行代码可以实现分组统计
));
// 最终groupingByList内的元素: {G=[Giraffe], L=[Lion, Lemur, Lion], M=[Monkey]}
//如果加上counting() ,结果是: {G=1, L=3, M=1}这是该过程的说明:groupingBy第一个参数作为分组条件,第二个参数是子收集器。
四、其他常用方法
boolean containsTwo = IntStream.of(1, 2, 3).anyMatch(i -> i == 2);
// 判断管道中是否包含2,结果是: true
long nrOfAnimals = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur"
).count();
// 管道中元素数据总计结果nrOfAnimals: 4
int sum = IntStream.of(1, 2, 3).sum();
// 管道中元素数据累加结果sum: 6
OptionalDouble average = IntStream.of(1, 2, 3).average();
//管道中元素数据平均值average: OptionalDouble[2.0]
int max = IntStream.of(1, 2, 3).max().orElse(0);
//管道中元素数据最大值max: 3
IntSummaryStatistics statistics = IntStream.of(1, 2, 3).summaryStatistics();
// 全面的统计结果statistics: IntSummaryStatistics{count=3, sum=6, min=1, average=2.000000, max=3}위 내용은 Java Stream API에서 터미널 동작 예시 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7517
7517
 15
1378
52
79
11
53
19
21
66
15
1378
52
79
11
53
19
21
66


 Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기 안내. 여기서는 예제를 통해 Java의 함수와 예제를 통해 두 가지 다른 생성기에 대해 설명합니다.
 자바의 웨카
Aug 30, 2024 pm 04:28 PM
자바의 웨카
Aug 30, 2024 pm 04:28 PM
Java의 Weka 가이드. 여기에서는 소개, weka java 사용 방법, 플랫폼 유형 및 장점을 예제와 함께 설명합니다.
 Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 Smith Number 가이드. 여기서는 정의, Java에서 스미스 번호를 확인하는 방법에 대해 논의합니다. 코드 구현의 예.
 Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
이 기사에서는 가장 많이 묻는 Java Spring 면접 질문과 자세한 답변을 보관했습니다. 그래야 면접에 합격할 수 있습니다.
 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
 Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 TimeStamp to Date 안내. 여기서는 소개와 예제와 함께 Java에서 타임스탬프를 날짜로 변환하는 방법에 대해서도 설명합니다.
 캡슐의 양을 찾기위한 Java 프로그램
Feb 07, 2025 am 11:37 AM
캡슐의 양을 찾기위한 Java 프로그램
Feb 07, 2025 am 11:37 AM
캡슐은 3 차원 기하학적 그림이며, 양쪽 끝에 실린더와 반구로 구성됩니다. 캡슐의 부피는 실린더의 부피와 양쪽 끝에 반구의 부피를 첨가하여 계산할 수 있습니다. 이 튜토리얼은 다른 방법을 사용하여 Java에서 주어진 캡슐의 부피를 계산하는 방법에 대해 논의합니다. 캡슐 볼륨 공식 캡슐 볼륨에 대한 공식은 다음과 같습니다. 캡슐 부피 = 원통형 볼륨 2 반구 볼륨 안에, R : 반구의 반경. H : 실린더의 높이 (반구 제외). 예 1 입력하다 반경 = 5 단위 높이 = 10 단위 산출 볼륨 = 1570.8 입방 단위 설명하다 공식을 사용하여 볼륨 계산 : 부피 = π × r2 × h (4
