

TSP(여행 세일즈맨 문제)를 해결하기 위해 Python을 사용하여 유전자 알고리즘을 구현하는 방법은 무엇입니까?

TSP 문제
그래서 시작하기 전에 이 TSP 문제에 대해 자세히 설명하겠습니다. 디지털 모델링을 해본 적이 있거나 지능형 최적화 또는 기계 학습에 노출된 친구들은 모두 이것을 알아야 합니다. 물론 이 기사의 보편적인 독자를 위해 우리는 이를 최대한 완벽하고 명확하게 만들기 위해 최선을 다할 것입니다. 여기서 실제로 문제를 해결할 수 있습니다.
문제는 실제로 간단합니다.

N차원 평면에서 오늘 우리가 이야기하고 있는 것은 이 2차원 평면에 많은 도시가 있습니다. 도시 도시들은 서로 연결되어 있습니다. 이제 모든 도시를 방문할 수 있는 최단 경로를 찾아야 합니다. 예를 들어 도시 A, B, C, D, E가 있습니다. 이제 도시 사이의 좌표를 알았으니, 이는 도시 사이의 거리를 아는 것과 같습니다. 이제 모든 도시 A, B, C, D, E까지 최단 경로를 만들 수 있는 시퀀스를 찾을 수 있습니다. 예를 들어 계산하면 B-->A-->C-->E-->D가 될 수 있다. 즉, 이 순서를 찾으십시오.
Enumeration
이 문제를 먼저 해결하려면 실제로 많은 솔루션이 있습니다. 직설적으로 말하면 경로의 합을 최소화할 수 있는 순서를 찾으면 됩니다. 그러면 가장 쉬운 방법은 열거입니다. 예를 들어, A를 먼저 이동시킨 다음 A에서 가장 가까운 거리가 B인지 확인한 다음 B로 이동한 다음 B에서 이동합니다. 물론 이것은 지역적 탐욕 전략이며 지역적 최적에 도달하기 쉽습니다. 그러면 이번에는 DP를 고려할 수 있습니다. 즉, 여전히 A에서 시작한다고 가정하고 2개의 도시가 다음과 같다는 것을 보장합니다. 3개 도시가 가장 짧고, 4개와 5개 도시가 가장 짧습니다. 마지막으로 B에서도 같은 일을 가정합니다. 아니면 모든 상황을 직접 열거하고 거리를 계산해 보세요. 그러나 어쨌든 도시의 수가 증가할수록 복잡성도 증가할 것이기 때문에 현시점에서 우리는 컴퓨팅이 인간의 전문 지식을 활용할 수 있는 방법을 찾아야 합니다. 나는 그것을 "실명"이라고 부릅니다.
지능형 알고리즘
이제 이 지능형 알고리즘과 이를 사용하는 이유에 대해 이야기해 보겠습니다. 이전 솔루션은 대용량 데이터에 대해 많은 계산이 필요하며 작성이 반드시 쉽지는 않다고 말했습니다. 그래서 이때 우선 TSP 문제에 대해서만 우리가 원하는 것은 시퀀스, 반복되지 않는 시퀀스입니다. 그렇다면 이때 더 간단한 해결책은 없을까요? 그리고 데이터가 충분히 크다면 가깝기만 하면 완전히 정확하고 완전히 최소한의 솔루션이 꼭 필요한 것은 아닙니다. 따라서 이때 기존 알고리즘을 사용하면 하나는 우리의 규칙에 따라서만 계산되며 표준 답이 무엇인지 실제로 알 수 없습니다. 전통적인 알고리즘 . 그러나 우리 인간에게는 '행운'이라는 것이 있습니다. 어떤 사람들은 너무 운이 좋아서 영혼에 들어오자마자 답이 혼란스러울 수도 있습니다. 따라서 우리의 지능형 알고리즘은 실제로 "원숭이"와 약간 유사합니다. 하지만 사람들은 실력에 주목합니다. 예를 들어, 경험에 따르면 긴 것 세 개와 짧은 것 한 개가 가장 짧습니다. 또는 블로거만큼 잘생긴 남자 친구를 찾을 때 이 기술을 사용할 수 있습니다. 40시리즈만 있으면 됩니다. (30개도 괜찮습니다.) 그래픽카드는 쉽게 빼낼 수 있습니다. Meng에는 기술이 필요하며 우리는 이것을 전략이라고 부릅니다.
Strategy
그래서 우리가 방금 이야기한 이 기술, 이 트릭입니다. 지능형 알고리즘에서 이 마스크는 우리의 전략 중 하나입니다. 우리의 솔루션이 더욱 합리적이 되도록 어떻게 이를 제거할 수 있습니까? 그러면 이때 백 송이의 꽃이 피기 시작합니다. 여기서는 가장 고전적인 두 가지 알고리즘을 예로 들겠습니다. 하나는 유전자 알고리즘이고 다른 하나는 입자 떼 알고리즘(PSO)입니다. 예를 들어, 그들은 자연 선택을 시뮬레이션하여 처음에 여러 솔루션과 시퀀스를 무작위로 생성한 다음 자연 선택 전략을 사용하여 솔루션을 생성하는 등의 암호 해독 전략을 사용합니다. 그런 다음 이러한 솔루션을 사용하여 새롭고 더 나은 솔루션을 찾으십시오. 이렇게 왔다 갔다 하다가 좋은 해결책을 얻었습니다. 입자군집도 비슷합니다. 이 부분은 사용하면서 자세히 설명하겠습니다.
Algorithm
이제 우리는 이 전략을 알았습니다. 알고리즘이란 실제로 이러한 전략을 구현하는 단계이며, 이것이 바로 우리의 코드, 루프 및 데이터 구조입니다. 우리는 방금 언급한 TSP와 같은 자연 선택, 수많은 솔루션을 무작위로 생성하는 방법 등을 깨달아야 합니다.
데이터 샘플
자, 여기서는 몇 가지 기본 개념에 대해 이야기했습니다. 이제 이 TSP 문제를 어떻게 표현하는지 살펴보겠습니다. 우리 입장에서는 매우 간단합니다. 여기에 14개의 도시가 있다고 가정해 보겠습니다. 이 도시에 대한 데이터는 다음과 같습니다.
data = np.array([16.47, 96.10, 16.47, 94.44, 20.09, 92.54,
22.39, 93.37, 25.23, 97.24, 22.00, 96.05, 20.47, 97.02,
17.20, 96.29, 16.30, 97.38, 14.05, 98.12, 16.53, 97.38,
21.52, 95.59, 19.41, 97.13, 20.09, 92.55]).reshape((14, 2))이 데이터 세트를 나중에 테스트에 사용할 예정이며 이제 14개의 도시가 있습니다.
그럼 솔루션을 시작하겠습니다
유전자 알고리즘
좋아요, 그럼 우리의 유전자 알고리즘이 무엇인지 이야기한 다음 이를 사용하여 이 TSP 문제를 해결하겠습니다.
이제 우리의 유전자 알고리즘이 어떻게 속는지 살펴보겠습니다.
算法流程
遗传算法其实是在用计算机模拟我们的物种进化。其实更加通俗的说法是筛选,这个就和我们袁老爷爷种植水稻一样。有些个体发育良好,有些个体发育不好,那么我就先筛选出发育好的,然后让他们去繁衍后代,然后再筛选,最后得到高产水稻。其实也和我们社会一样,不努力就木有女朋友就不能保留自己的基因,然后剩下的人就是那些优秀的人和富二代的基因,这就是现实呀。所以得好好学习,天天向上!
那么回到主题,我们的遗传算法就是在模拟这一个过程,模拟一个物竞天择的过程。
所以在我们的算法里面也是分为几大块
繁殖
首先我们的种群需要先繁殖。这样才能不断产生优良基于,那么对应我们的算法,假设我们需要求取
Y = np.sin(10 * x) * x + np.cos(2 * x) * x
的最大值(在一个范围内)那么我们的个体就是一组(X1)的解。好的个体就会被保留,不好的就会被pass,选择标准就是我们的函数 Y 。那么问题来了如何模拟这个过程?我们都知道在繁殖后代的时候我们是通过DNA来保留我们的基因信息,在这个过程当中,父母的DNA交互,并且在这个过程当中会产生变异,这样一来,父母双方的优秀基于会被保存,并且产生的变异有可能诞生更加优秀的后代。
所以接下来我们需要模拟我们的DNA,进行交叉和变异。
交叉
这个交叉过程和我们的生物其实很像,当然我们在我们的计算机里面对于数字我们可以将其转化为二进制,当做我们的DNA
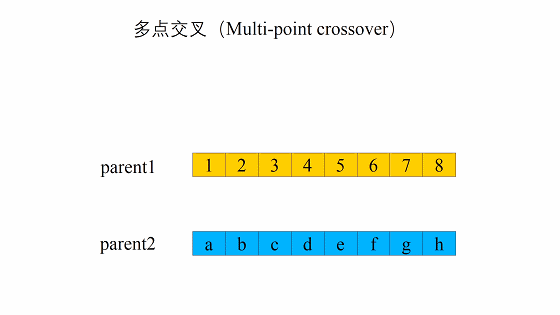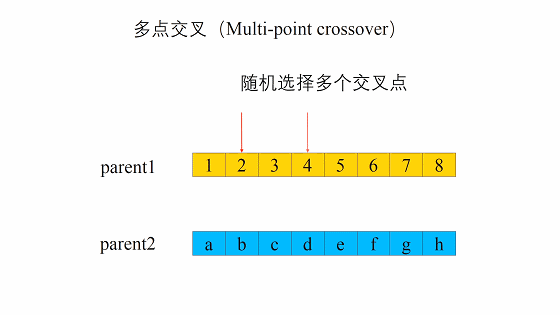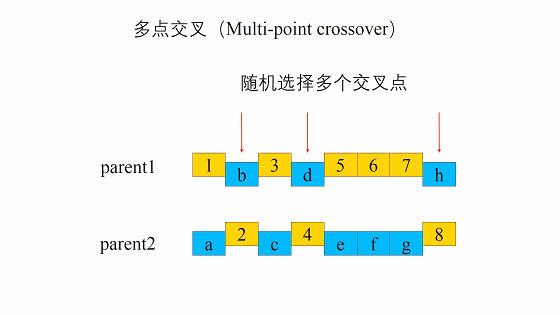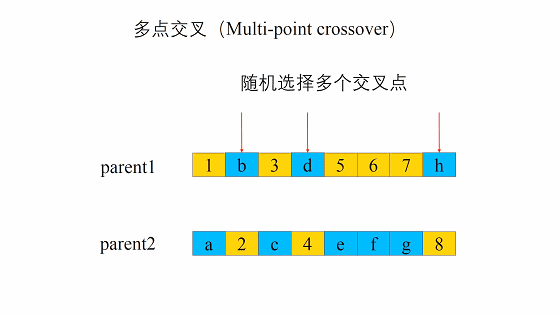
交叉的方式有很多,我们这边选择这一个,进行交叉。
变异
那这个在我们这里就更加简单了
我们只需要在交叉之后,再随机选择几个位置进行改变值就可以了。当然变异的概率是很小的,并且是随机的,这一点要注意。并且由于变异是随机的,所以不排除生成比原来还更加糟糕的个体。
选择
最后我们按照一定的规则去筛选这个些个体就可以了,然后淘汰原来的个体。那么在我们的计算机里面是使用了两个东西,首先我们要把原来二进制的玩意,给转化为我们原来的十进制然后带入我们的函数运算,然后保存起来,之后再每一轮统一筛选一下就好了。
逆转
这个咋说呢,说好听点叫逆转,难听点就算,对于一些新的生成的不好的解,我们是要舍弃的。
代码
那么这部分用代码描述的话就是这样的:
import numpy as np
import matplotlib.pyplot as plt
Population_Size = 100
Iteration_Number = 200
Cross_Rate = 0.8
Mutation_Rate = 0.003
Dna_Size = 10
X_Range=[0,5]
def F(x):
'''
目标函数,需要被优化的函数
:param x:
:return:
'''
return np.sin(10 * x) * x + np.cos(2 * x) * x
def CrossOver(Parent,PopSpace):
'''
交叉DNA,我们直接在种群里面选择一个交配
然后就生出孩子了
:param parent:
:param PopSpace:
:return:
'''
if(np.random.rand()) < Cross_Rate:
cross_place = np.random.randint(0, 2, size=Dna_Size).astype(np.bool)
cross_one = np.random.randint(0, Population_Size, size=1) #选择一位男/女士交配
Parent[cross_place] = PopSpace[cross_one,cross_place]
return Parent
def Mutate(Child):
'''
变异
:param Child:
:return:
'''
for point in range(Dna_Size):
if np.random.rand() < Mutation_Rate:
Child[point] = 1 if Child[point] == 0 else 0
return Child
def TranslateDNA(PopSpace):
'''
把二进制转化为十进制方便计算
:param PopSpace:
:return:
'''
return PopSpace.dot(2 ** np.arange(Dna_Size)[::-1]) / float(2 ** Dna_Size - 1) * X_Range[1]
def Fitness(pred):
'''
这个其实是对我们得到的F(x)进行换算,其实就是选择的时候
的概率,我们需要处理负数,因为概率不能为负数呀
pred 这是一个二维矩阵
:param pred:
:return:
'''
return pred + 1e-3 - np.min(pred)
def Select(PopSpace,Fitness):
'''
选择
:param PopSpace:
:param Fitness:
:return:
'''
'''
这里注意的是,我们先按照权重去选择我们的优良个体,所以我们这里选择的时候允许重复的元素出现
之后我们就可以去掉这些重复的元素,这样才能实现保留良种去除劣种。100--》70(假设有30个重复)
如果不允许重复的话,那你相当于没有筛选
'''
Better_Ones = np.random.choice(np.arange(Population_Size), size=Population_Size, replace=True,
p=Fitness / Fitness.sum())
# np.unique(Better_Ones) #这个是我后面加的
return PopSpace[Better_Ones]
if __name__ == '__main__':
PopSpace = np.random.randint(2, size=(Population_Size, Dna_Size)) # initialize the PopSpace DNA
plt.ion()
x = np.linspace(X_Range, 200)
# plt.plot(x, F(x))
plt.xticks([0,10])
plt.yticks([0,10])
for _ in range(Iteration_Number):
F_values = F(TranslateDNA(PopSpace))
# something about plotting
if 'sca' in globals():
sca.remove()
sca = plt.scatter(TranslateDNA(PopSpace), F_values, s=200, lw=0, c='red', alpha=0.5)
plt.pause(0.05)
# GA part (evolution)
fitness = Fitness(F_values)
print("Most fitted DNA: ", PopSpace[np.argmax(fitness)])
PopSpace = Select(PopSpace, fitness)
PopSpace_copy = PopSpace.copy()
for parent in PopSpace:
child = CrossOver(parent, PopSpace_copy)
child = Mutate(child)
parent[:] = child
plt.ioff()
plt.show()这个代码是以前写的,逆转没有写上(下面的有)
TSP遗传算法
ok,刚刚的例子是拿的解方程,也就是说是一个连续问题吧,当然那个连续处理的话并不是很好,只是一个演示。那么我们这个的话其实类似的。首先我们的DNA,是城市的路径,也就是A-B-C-D等等,当然我们用下标表示城市。
种群表示
首先我们确定了使用城市的序号作为我们的个体DNA,例如咱们种群大小为100,有ABCD四个城市,那么他就是这样的,我们先随机生成种群,长这个样:
1 2 3 4
2 3 4 5
3 2 1 4
...
那个1,2,3,4是ABCD的序号。
交叉与变异
这里面的话,值得一提的就是,由于暂定城市需要是不能重复的,且必须是完整的,所以如果像刚刚那样进行交叉或者变异的话,那么实际上会出点问题,我们不允许出现重复,且必须完整,对于我们的DNA,也就是咱们瞎蒙的个体。
代码
由于咱们每一步在代码里面都有注释,所以的话咱们在这里就不再进行复述了。
from math import floor
import numpy as np
import matplotlib.pyplot as plt
class Gena_TSP(object):
"""
使用遗传算法解决TSP问题
"""
def __init__(self, data, maxgen=200,
size_pop=200, cross_prob=0.9,
pmuta_prob=0.01, select_prob=0.8
):
self.maxgen = maxgen # 最大迭代次数
self.size_pop = size_pop # 群体个数,(一次性瞎蒙多少个解)
self.cross_prob = cross_prob # 交叉概率
self.pmuta_prob = pmuta_prob # 变异概率
self.select_prob = select_prob # 选择概率
self.data = data # 城市的坐标数据
self.num = len(data) # 有多少个城市,对应多少个坐标,对应染色体的长度(我们的解叫做染色体)
"""
计算城市的距离,我们用矩阵表示城市间的距离
"""
self.__matrix_distance = self.__matrix_dis()
self.select_num = int(self.size_pop * self.select_prob)
# 通过选择概率确定子代的选择个数
"""
初始化子代和父代种群,两者相互交替
"""
self.parent = np.array([0] * self.size_pop * self.num).reshape(self.size_pop, self.num)
self.child = np.array([0] * self.select_num * self.num).reshape(self.select_num, self.num)
"""
负责计算每一个个体的(瞎蒙的解)最后需要多少距离
"""
self.fitness = np.zeros(self.size_pop)
self.best_fit = []
self.best_path = []
# 保存每一步的群体的最优路径和距离
def __matrix_dis(self):
"""
计算14个城市的距离,将这些距离用矩阵存起来
:return:
"""
res = np.zeros((self.num, self.num))
for i in range(self.num):
for j in range(i + 1, self.num):
res[i, j] = np.linalg.norm(self.data[i, :] - self.data[j, :])
res[j, i] = res[i, j]
return res
def rand_parent(self):
"""
初始化种群
:return:
"""
rand_ch = np.array(range(self.num))
for i in range(self.size_pop):
np.random.shuffle(rand_ch)
self.parent[i, :] = rand_ch
self.fitness[i] = self.comp_fit(rand_ch)
def comp_fit(self, one_path):
"""
计算,咱们这个路径的长度,例如A-B-C-D
:param one_path:
:return:
"""
res = 0
for i in range(self.num - 1):
res += self.__matrix_distance[one_path[i], one_path[i + 1]]
res += self.__matrix_distance[one_path[-1], one_path[0]]
return res
def out_path(self, one_path):
"""
输出我们的路径顺序
:param one_path:
:return:
"""
res = str(one_path[0] + 1) + '-->'
for i in range(1, self.num):
res += str(one_path[i] + 1) + '-->'
res += str(one_path[0] + 1) + '\n'
print(res)
def Select(self):
"""
通过我们的这个计算的距离来计算出概率,也就是当前这些个体DNA也就瞎蒙的解
之后我们在通过概率去选择个体,放到child里面
:return:
"""
fit = 1. / (self.fitness) # 适应度函数
cumsum_fit = np.cumsum(fit)
pick = cumsum_fit[-1] / self.select_num * (np.random.rand() + np.array(range(self.select_num)))
i, j = 0, 0
index = []
while i < self.size_pop and j < self.select_num:
if cumsum_fit[i] >= pick[j]:
index.append(i)
j += 1
else:
i += 1
self.child = self.parent[index, :]
def Cross(self):
"""
模仿DNA交叉嘛,就是交换两个瞎蒙的解的部分的解例如
A-B-C-D
C-D-A-B
我们选几个交叉例如这样
A-D-C-B
1,3号交换了位置,当然这里注意可不能重复啊
:return:
"""
if self.select_num % 2 == 0:
num = range(0, self.select_num, 2)
else:
num = range(0, self.select_num - 1, 2)
for i in num:
if self.cross_prob >= np.random.rand():
self.child[i, :], self.child[i + 1, :] = self.intercross(self.child[i, :],
self.child[i + 1, :])
def intercross(self, ind_a, ind_b):
"""
这个是我们两两交叉的具体实现
:param ind_a:
:param ind_b:
:return:
"""
r1 = np.random.randint(self.num)
r2 = np.random.randint(self.num)
while r2 == r1:
r2 = np.random.randint(self.num)
left, right = min(r1, r2), max(r1, r2)
ind_a1 = ind_a.copy()
ind_b1 = ind_b.copy()
for i in range(left, right + 1):
ind_a2 = ind_a.copy()
ind_b2 = ind_b.copy()
ind_a[i] = ind_b1[i]
ind_b[i] = ind_a1[i]
x = np.argwhere(ind_a == ind_a[i])
y = np.argwhere(ind_b == ind_b[i])
if len(x) == 2:
ind_a[x[x != i]] = ind_a2[i]
if len(y) == 2:
ind_b[y[y != i]] = ind_b2[i]
return ind_a, ind_b
def Mutation(self):
"""
之后是变异模块,这个就是按照某个概率,去替换瞎蒙的解里面的其中几个元素。
:return:
"""
for i in range(self.select_num):
if np.random.rand() <= self.cross_prob:
r1 = np.random.randint(self.num)
r2 = np.random.randint(self.num)
while r2 == r1:
r2 = np.random.randint(self.num)
self.child[i, [r1, r2]] = self.child[i, [r2, r1]]
def Reverse(self):
"""
近化逆转,就是说下一次瞎蒙的解如果没有更好的话就不进入下一代,同时也是随机选择一个部分的
我们不是一次性全部替换
:return:
"""
for i in range(self.select_num):
r1 = np.random.randint(self.num)
r2 = np.random.randint(self.num)
while r2 == r1:
r2 = np.random.randint(self.num)
left, right = min(r1, r2), max(r1, r2)
sel = self.child[i, :].copy()
sel[left:right + 1] = self.child[i, left:right + 1][::-1]
if self.comp_fit(sel) < self.comp_fit(self.child[i, :]):
self.child[i, :] = sel
def Born(self):
"""
替换,子代变成新的父代
:return:
"""
index = np.argsort(self.fitness)[::-1]
self.parent[index[:self.select_num], :] = self.child
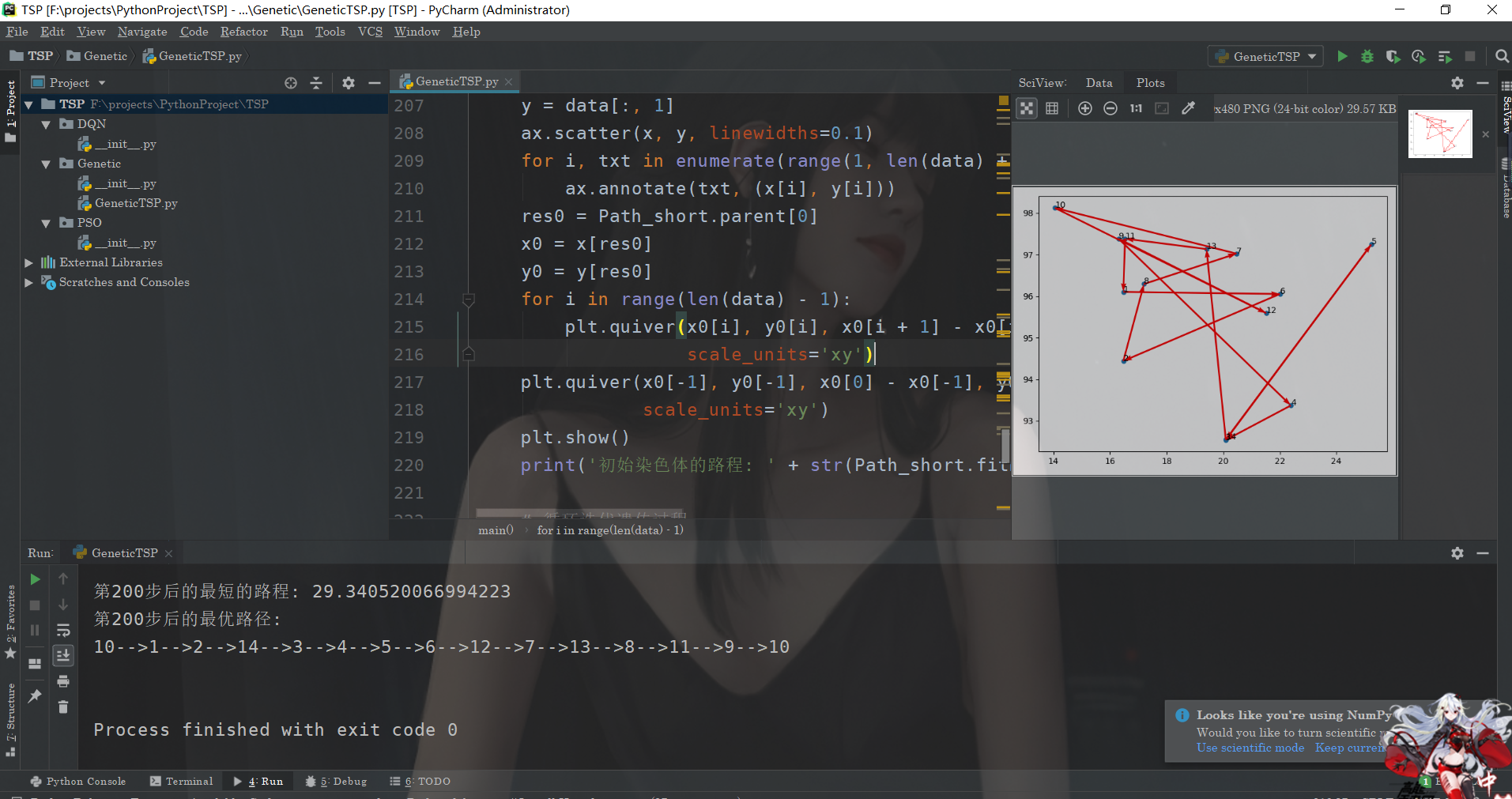
def main(data):
Path_short = Gena_TSP(data) # 根据位置坐标,生成一个遗传算法类
Path_short.rand_parent() # 初始化父类
## 绘制初始化的路径图
fig, ax = plt.subplots()
x = data[:, 0]
y = data[:, 1]
ax.scatter(x, y, linewidths=0.1)
for i, txt in enumerate(range(1, len(data) + 1)):
ax.annotate(txt, (x[i], y[i]))
res0 = Path_short.parent[0]
x0 = x[res0]
y0 = y[res0]
for i in range(len(data) - 1):
plt.quiver(x0[i], y0[i], x0[i + 1] - x0[i], y0[i + 1] - y0[i], color='r', width=0.005, angles='xy', scale=1,
scale_units='xy')
plt.quiver(x0[-1], y0[-1], x0[0] - x0[-1], y0[0] - y0[-1], color='r', width=0.005, angles='xy', scale=1,
scale_units='xy')
plt.show()
print('初始染色体的路程: ' + str(Path_short.fitness[0]))
# 循环迭代遗传过程
for i in range(Path_short.maxgen):
Path_short.Select() # 选择子代
Path_short.Cross() # 交叉
Path_short.Mutation() # 变异
Path_short.Reverse() # 进化逆转
Path_short.Born() # 子代插入
# 重新计算新群体的距离值
for j in range(Path_short.size_pop):
Path_short.fitness[j] = Path_short.comp_fit(Path_short.parent[j, :])
index = Path_short.fitness.argmin()
if (i + 1) % 50 == 0:
print('第' + str(i + 1) + '步后的最短的路程: ' + str(Path_short.fitness[index]))
print('第' + str(i + 1) + '步后的最优路径:')
Path_short.out_path(Path_short.parent[index, :]) # 显示每一步的最优路径
# 存储每一步的最优路径及距离
Path_short.best_fit.append(Path_short.fitness[index])
Path_short.best_path.append(Path_short.parent[index, :])
return Path_short # 返回遗传算法结果类
if __name__ == '__main__':
data = np.array([16.47, 96.10, 16.47, 94.44, 20.09, 92.54,
22.39, 93.37, 25.23, 97.24, 22.00, 96.05, 20.47, 97.02,
17.20, 96.29, 16.30, 97.38, 14.05, 98.12, 16.53, 97.38,
21.52, 95.59, 19.41, 97.13, 20.09, 92.55]).reshape((14, 2))
main(data)运行结果
ok,我们来看看运行的结果:
위 내용은 TSP(여행 세일즈맨 문제)를 해결하기 위해 Python을 사용하여 유전자 알고리즘을 구현하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7451
7451
 15
1374
52
77
11
40
19
14
9
15
1374
52
77
11
40
19
14
9

 PS가 계속 로딩을 보여주는 이유는 무엇입니까?
Apr 06, 2025 pm 06:39 PM
PS가 계속 로딩을 보여주는 이유는 무엇입니까?
Apr 06, 2025 pm 06:39 PM
PS "로드"문제는 자원 액세스 또는 처리 문제로 인한 것입니다. 하드 디스크 판독 속도는 느리거나 나쁘다 : CrystalDiskinfo를 사용하여 하드 디스크 건강을 확인하고 문제가있는 하드 디스크를 교체하십시오. 불충분 한 메모리 : 고해상도 이미지 및 복잡한 레이어 처리에 대한 PS의 요구를 충족시키기 위해 메모리 업그레이드 메모리. 그래픽 카드 드라이버는 구식 또는 손상됩니다. 운전자를 업데이트하여 PS와 그래픽 카드 간의 통신을 최적화하십시오. 파일 경로는 너무 길거나 파일 이름에는 특수 문자가 있습니다. 짧은 경로를 사용하고 특수 문자를 피하십시오. PS 자체 문제 : PS 설치 프로그램을 다시 설치하거나 수리하십시오.
 PS가 시작될 때 로딩 문제를 해결하는 방법은 무엇입니까?
Apr 06, 2025 pm 06:36 PM
PS가 시작될 때 로딩 문제를 해결하는 방법은 무엇입니까?
Apr 06, 2025 pm 06:36 PM
부팅 할 때 "로드"에 PS가 붙어있는 여러 가지 이유로 인해 발생할 수 있습니다. 손상되거나 충돌하는 플러그인을 비활성화합니다. 손상된 구성 파일을 삭제하거나 바꾸십시오. 불충분 한 메모리를 피하기 위해 불필요한 프로그램을 닫거나 메모리를 업그레이드하십시오. 하드 드라이브 독서 속도를 높이기 위해 솔리드 스테이트 드라이브로 업그레이드하십시오. 손상된 시스템 파일 또는 설치 패키지 문제를 복구하기 위해 PS를 다시 설치합니다. 시작 오류 로그 분석의 시작 과정에서 오류 정보를 봅니다.
 PS의 로딩 속도 속도를 높이는 방법?
Apr 06, 2025 pm 06:27 PM
PS의 로딩 속도 속도를 높이는 방법?
Apr 06, 2025 pm 06:27 PM
느린 Photoshop 스타트 업 문제를 해결하려면 다음을 포함한 다중 프론트 접근 방식이 필요합니다. 하드웨어 업그레이드 (메모리, 솔리드 스테이트 드라이브, CPU); 구식 또는 양립 할 수없는 플러그인 제거; 정기적으로 시스템 쓰레기 및 과도한 배경 프로그램 청소; 주의를 기울여 관련없는 프로그램 폐쇄; 시작하는 동안 많은 파일을 열지 않도록합니다.
 PS가 파일을 열 때로드 문제를 해결하는 방법은 무엇입니까?
Apr 06, 2025 pm 06:33 PM
PS가 파일을 열 때로드 문제를 해결하는 방법은 무엇입니까?
Apr 06, 2025 pm 06:33 PM
"로드"는 PS에서 파일을 열 때 말더듬이 발생합니다. 그 이유에는 너무 크거나 손상된 파일, 메모리 불충분, 하드 디스크 속도가 느리게, 그래픽 카드 드라이버 문제, PS 버전 또는 플러그인 충돌이 포함될 수 있습니다. 솔루션은 다음과 같습니다. 파일 크기 및 무결성 확인, 메모리 증가, 하드 디스크 업그레이드, 그래픽 카드 드라이버 업데이트, 의심스러운 플러그인 제거 또는 비활성화 및 PS를 다시 설치하십시오. 이 문제는 PS 성능 설정을 점차적으로 확인하고 잘 활용하고 우수한 파일 관리 습관을 개발함으로써 효과적으로 해결할 수 있습니다.
 PS가 항상 로딩되고 있음을 보여줄 때 로딩 문제를 해결하는 방법은 무엇입니까?
Apr 06, 2025 pm 06:30 PM
PS가 항상 로딩되고 있음을 보여줄 때 로딩 문제를 해결하는 방법은 무엇입니까?
Apr 06, 2025 pm 06:30 PM
PS 카드가 "로드"되어 있습니까? 솔루션에는 컴퓨터 구성 (메모리, 하드 디스크, 프로세서) 확인, 하드 디스크 조각 청소, 그래픽 카드 드라이버 업데이트, PS 설정 조정, PS 재설치 및 우수한 프로그래밍 습관 개발이 포함됩니다.
 PS 페더 링은 어떻게 전환의 부드러움을 제어합니까?
Apr 06, 2025 pm 07:33 PM
PS 페더 링은 어떻게 전환의 부드러움을 제어합니까?
Apr 06, 2025 pm 07:33 PM
깃털 통제의 열쇠는 점진적인 성격을 이해하는 것입니다. PS 자체는 그라디언트 곡선을 직접 제어하는 옵션을 제공하지 않지만 여러 깃털, 일치하는 마스크 및 미세 선택으로 반경 및 구배 소프트를 유연하게 조정하여 자연스럽게 전이 효과를 달성 할 수 있습니다.
 설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
이 기사는 MySQL 데이터베이스의 작동을 소개합니다. 먼저 MySQLworkBench 또는 명령 줄 클라이언트와 같은 MySQL 클라이언트를 설치해야합니다. 1. MySQL-Uroot-P 명령을 사용하여 서버에 연결하고 루트 계정 암호로 로그인하십시오. 2. CreateABase를 사용하여 데이터베이스를 작성하고 데이터베이스를 선택하십시오. 3. CreateTable을 사용하여 테이블을 만들고 필드 및 데이터 유형을 정의하십시오. 4. InsertInto를 사용하여 데이터를 삽입하고 데이터를 쿼리하고 업데이트를 통해 데이터를 업데이트하고 DELETE를 통해 데이터를 삭제하십시오. 이러한 단계를 마스터하고 일반적인 문제를 처리하는 법을 배우고 데이터베이스 성능을 최적화하면 MySQL을 효율적으로 사용할 수 있습니다.
 PS 카드가 로딩 인터페이스에 있으면 어떻게해야합니까?
Apr 06, 2025 pm 06:54 PM
PS 카드가 로딩 인터페이스에 있으면 어떻게해야합니까?
Apr 06, 2025 pm 06:54 PM
PS 카드의로드 인터페이스는 소프트웨어 자체 (파일 손상 또는 플러그인 충돌), 시스템 환경 (DIFE 드라이버 또는 시스템 파일 손상) 또는 하드웨어 (하드 디스크 손상 또는 메모리 스틱 고장)로 인해 발생할 수 있습니다. 먼저 컴퓨터 자원이 충분한 지 확인하고 배경 프로그램을 닫고 메모리 및 CPU 리소스를 릴리스하십시오. PS 설치를 수정하거나 플러그인의 호환성 문제를 확인하십시오. PS 버전을 업데이트하거나 폴백합니다. 그래픽 카드 드라이버를 확인하고 업데이트하고 시스템 파일 확인을 실행하십시오. 위의 문제를 해결하면 하드 디스크 감지 및 메모리 테스트를 시도 할 수 있습니다.
