

Python 내장 유형 str 소스 코드 분석

1 Unicode
컴퓨터 저장의 기본 단위는 8비트로 구성된 바이트입니다. 영어는 26개의 문자와 여러 개의 기호로만 구성되므로 영어 문자를 바이트 단위로 직접 저장할 수 있습니다. 하지만 다른 언어(예: 중국어, 일본어, 한국어 등)는 문자 수가 많기 때문에 인코딩에 여러 바이트를 사용해야 합니다.
컴퓨터 기술이 확산됨에 따라 비라틴어 문자 인코딩 기술이 계속 발전하고 있지만 여전히 두 가지 주요 제한 사항이 있습니다.
다중 언어를 지원하지 않습니다. 한 언어의 인코딩 체계를 다른 언어에 사용할 수 없습니다.
통일된 표준이 없습니다. 예를 들어 중국어에는 GBK, GB2312, GB18030 등과 같은 여러 인코딩 표준이 있습니다.
인코딩 방법이 통일되지 않기 때문에 개발자는 서로 다른 인코딩 간에 앞뒤로 변환해야 합니다. , 이는 필연적으로 발생합니다. 실수가 많습니다. 이러한 불일치 문제를 해결하기 위해 유니코드 표준이 제안되었습니다. 유니코드는 컴퓨터가 통일된 방식으로 텍스트를 처리할 수 있도록 전 세계 대부분의 쓰기 시스템을 구성하고 인코딩합니다. 유니코드는 현재 140,000개 이상의 문자를 포함하며 자연스럽게 여러 언어를 지원합니다. (유니코드의 uni는 "통일"의 루트입니다.)
2 Python의 Unicode
2.1 Unicode 객체의 장점
Python 3 이후에는 str 객체가 내부적으로 Unicode로 표현되므로 소스코드에서는 Unicode 객체가 됩니다. 유니코드 표현을 사용하면 프로그램의 핵심 논리가 유니코드를 균일하게 사용하고 입력 및 출력 레이어에서만 디코딩 및 인코딩하면 되므로 다양한 인코딩 문제를 최대한 피할 수 있다는 장점이 있습니다.
다이어그램은 다음과 같습니다.

2.2 Python의 유니코드 최적화
문제: 유니코드에는 140,000자 이상이 포함되어 있으므로 각 문자를 저장하려면 최소 4바이트가 필요합니다(2자 섹션이 충분하지 않기 때문에 그래야 합니다). 이므로 3바이트 대신 4바이트가 사용됩니다.) 영어 문자에 대한 ASCII 코드에는 1바이트만 필요합니다. 유니코드를 사용하면 자주 사용되는 영어 문자에 비해 비용이 4배가 됩니다.
먼저 Python에서 다양한 형태의 str 개체의 크기 차이를 살펴보겠습니다.
>>> sys.getsizeof('ab') - sys.getsizeof('a') 1 >>> sys.getsizeof('一二') - sys.getsizeof('一') 2 >>> sys.getsizeof('????????') - sys.getsizeof('????') 4
Python이 내부적으로 유니코드 개체를 최적화하는 것을 볼 수 있습니다. 텍스트 내용을 기반으로 기본 저장 단위가 선택됩니다.
유니코드 개체의 기본 저장소는 텍스트 문자의 유니코드 코드 포인트 범위에 따라 세 가지 범주로 나뉩니다.
PyUnicode_1BYTE_KIND: 모든 문자 코드 포인트는 U+0000에서 U+00FF 사이입니다.
PyUnicode_2BYTE_KIND: 모두 문자 코드 포인트는 U +0000에서 U+FFFF 사이이고 적어도 한 문자의 코드 포인트는 U+00FF
PyUnicode_1BYTE_KIND보다 큽니다: 모든 문자 코드 포인트는 U+0000에서 U+10FFFF 사이에 있으며 다음과 같습니다. 최소 한 문자의 코드 포인트가 U+FFFF보다 큼
해당 열거형은 다음과 같습니다.
enum PyUnicode_Kind {
/* String contains only wstr byte characters. This is only possible
when the string was created with a legacy API and _PyUnicode_Ready()
has not been called yet. */
PyUnicode_WCHAR_KIND = 0,
/* Return values of the PyUnicode_KIND() macro: */
PyUnicode_1BYTE_KIND = 1,
PyUnicode_2BYTE_KIND = 2,
PyUnicode_4BYTE_KIND = 4
};다른 분류에 따라 다른 저장 단위를 선택합니다.
/* Py_UCS4 and Py_UCS2 are typedefs for the respective unicode representations. */ typedef uint32_t Py_UCS4; typedef uint16_t Py_UCS2; typedef uint8_t Py_UCS1;
해당 관계는 다음과 같습니다.
| 텍스트 type | 문자 저장 단위 | 문자 저장 단위 크기(바이트) |
|---|---|---|
| PyUnicode_1BYTE_KIND | Py_UCS1 | 1 |
| PyUnicode_2BYTE_KIND | Py_UCS2 | 2 |
| PyUnicode_4BYTE_KIND | Py_UCS4 | 4 |
유니코드의 내부 저장 구조로 인해 텍스트 유형이 다양하므로 유형 종류를 유니코드 객체 공개 필드로 저장해야 합니다. Python은 내부적으로 일부 플래그 비트를 유니코드 공개 필드로 정의합니다. (저자의 제한된 수준으로 인해 여기에 있는 모든 필드는 후속 콘텐츠에서 소개되지 않습니다. 나중에 직접 배울 수 있습니다. 주먹을 쥐세요~)
interned: 인터닝 여부 메커니즘 유지보수
kind: 유형, 기본 문자 저장 단위의 크기를 구분하는 데 사용
compact: 메모리 할당 방법, 개체와 텍스트 버퍼가 분리되어 있는지 여부
asscii: 텍스트가 모두 순수 ASCII인지 여부
PyUnicode_New 함수를 사용하여 텍스트 문자 수 크기와 최대 문자 maxchar에 따라 유니코드 객체를 초기화합니다. 이 기능은 주로 maxchar를 기반으로 유니코드 객체에 대한 가장 컴팩트한 문자 저장 단위와 기본 구조를 선택합니다. (소스 코드는 상대적으로 길어서 여기에 나열되지 않습니다. 스스로 이해할 수 있습니다. 아래 표 형식으로 표시됩니다.)
| maxchar < 128 | 128 <= maxchar < 256 | 256 <= maxchar < 65536 | 65536 <= maxchar < MAX_UNICODE | |
|---|---|---|---|---|
| kind | PyUnicode_1BYTE_KIND | PyUnicode_1BYTE_KIND | PyUnicode_2BYTE_KIND | PyUnicode_4BYTE_KIND |
| ascii | 1 | 0 | 0 | 0 |
| 문자 저장 단위 크기(바이트) | 1 | 1 | 2 | 4 |
| 하단 구조 | PyASCIIObject | PyCompactUnicodeObject | PyCompactUnicodeObject | PyCompactUnicodeObject |
3 Unicode对象的底层结构体
3.1 PyASCIIObject
C源码:
typedef struct {
PyObject_HEAD
Py_ssize_t length; /* Number of code points in the string */
Py_hash_t hash; /* Hash value; -1 if not set */
struct {
unsigned int interned:2;
unsigned int kind:3;
unsigned int compact:1;
unsigned int ascii:1;
unsigned int ready:1;
unsigned int :24;
} state;
wchar_t *wstr; /* wchar_t representation (null-terminated) */
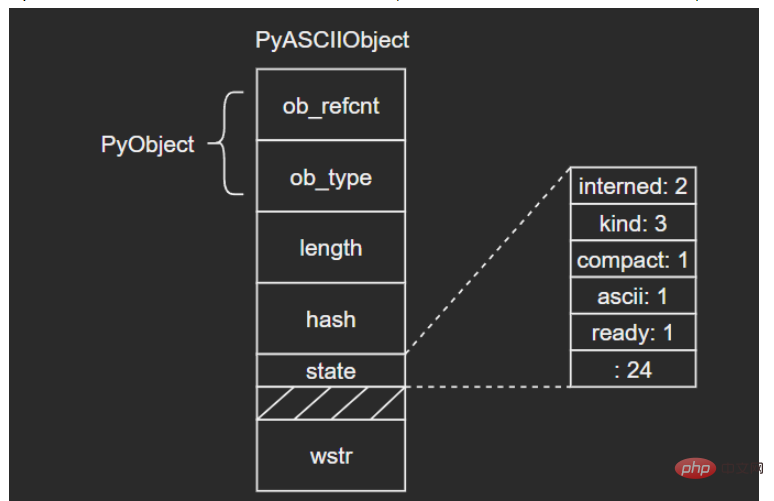
} PyASCIIObject;源码分析:
length:文本长度
hash:文本哈希值
state:Unicode对象标志位
wstr:缓存C字符串的一个wchar_t指针,以“\0”结束(这里和我看的另一篇文章讲得不太一样,另一个描述是:ASCII文本紧接着位于PyASCIIObject结构体后面,我个人觉得现在的这种说法比较准确,毕竟源码结构体后面没有别的字段了)
图示如下:
(注意这里state字段后面有一个4字节大小的空洞,这是结构体字段内存对齐造成的现象,主要是为了优化内存访问效率)
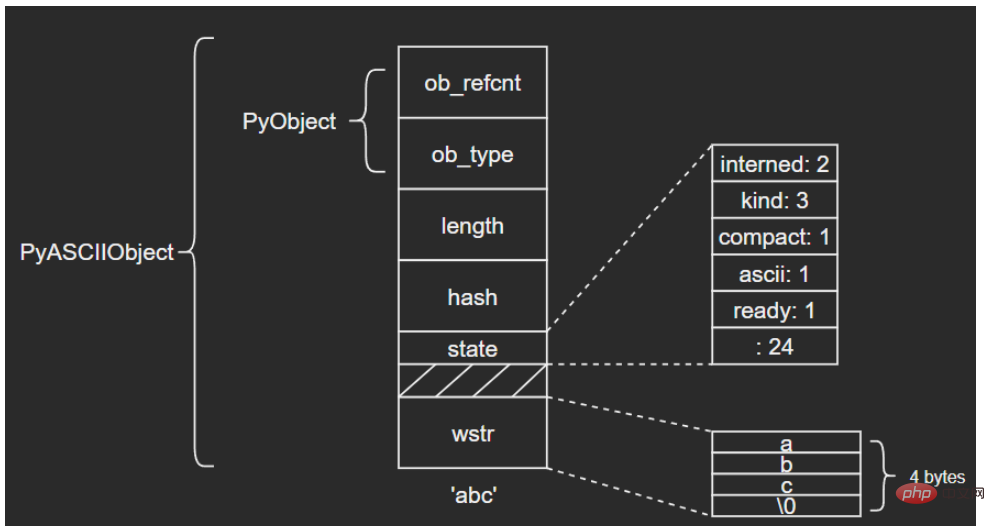
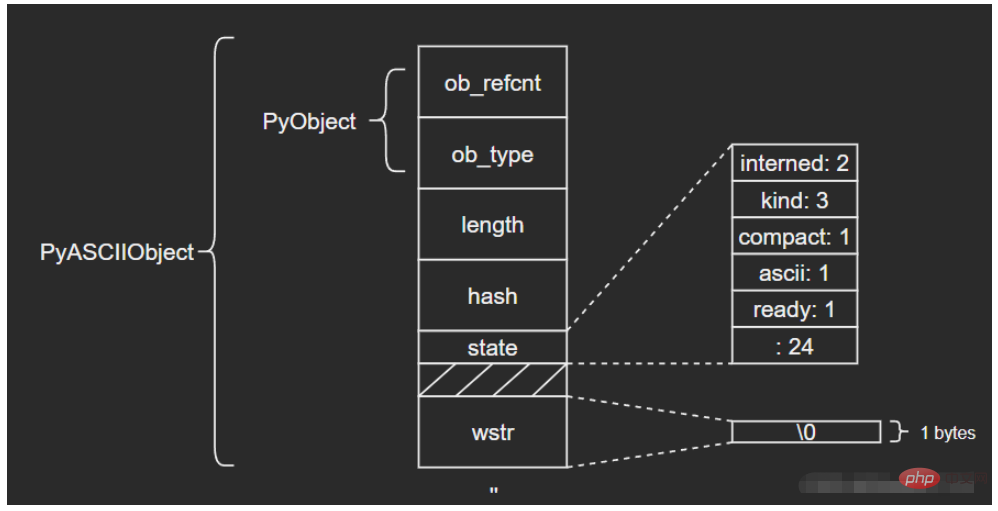
ASCII文本由wstr指向,以’abc’和空字符串对象’'为例:
3.2 PyCompactUnicodeObject
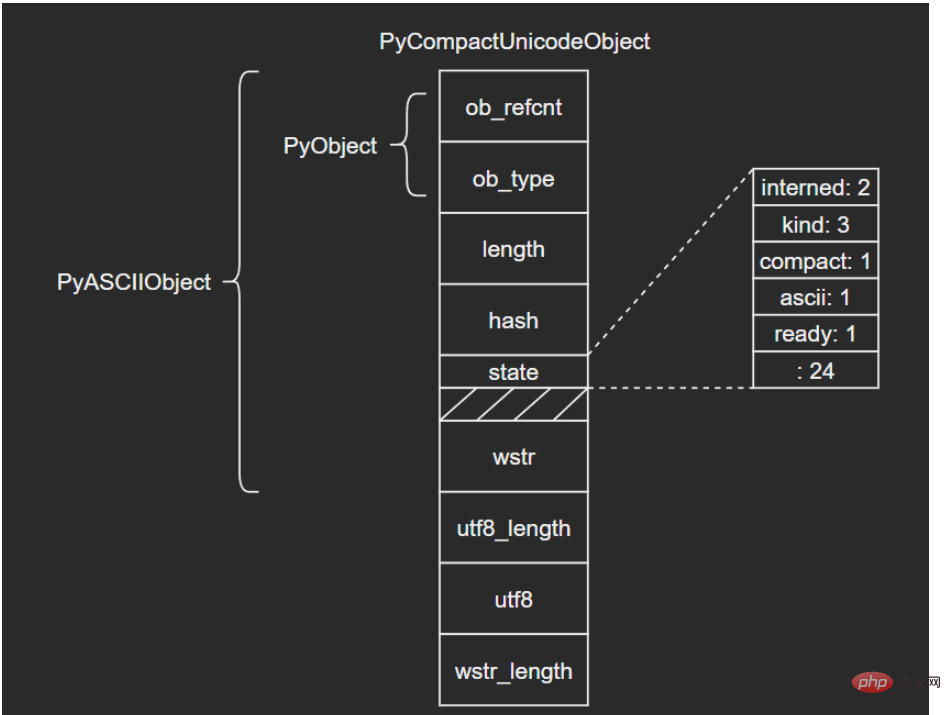
如果文本不全是ASCII,Unicode对象底层便由PyCompactUnicodeObject结构体保存。C源码如下:
/* Non-ASCII strings allocated through PyUnicode_New use the
PyCompactUnicodeObject structure. state.compact is set, and the data
immediately follow the structure. */
typedef struct {
PyASCIIObject _base;
Py_ssize_t utf8_length; /* Number of bytes in utf8, excluding the
* terminating \0. */
char *utf8; /* UTF-8 representation (null-terminated) */
Py_ssize_t wstr_length; /* Number of code points in wstr, possible
* surrogates count as two code points. */
} PyCompactUnicodeObject;PyCompactUnicodeObject在PyASCIIObject的基础上增加了3个字段:
utf8_length:文本UTF8编码长度
utf8:文本UTF8编码形式,缓存以避免重复编码运算
wstr_length:wstr的“长度”(这里所谓的长度没有找到很准确的说法,笔者也不太清楚怎么能打印出来,大家可以自行研究下)
注意到,PyASCIIObject中并没有保存UTF8编码形式,这是因为ASCII本身就是合法的UTF8,这也是ASCII文本底层由PyASCIIObject保存的原因。
结构图示:
3.3 PyUnicodeObject
PyUnicodeObject则是Python中str对象的具体实现。C源码如下:
/* Strings allocated through PyUnicode_FromUnicode(NULL, len) use the
PyUnicodeObject structure. The actual string data is initially in the wstr
block, and copied into the data block using _PyUnicode_Ready. */
typedef struct {
PyCompactUnicodeObject _base;
union {
void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data; /* Canonical, smallest-form Unicode buffer */
} PyUnicodeObject;3.4 示例
在日常开发时,要结合实际情况注意字符串拼接前后的内存大小差别:
>>> import sys >>> text = 'a' * 1000 >>> sys.getsizeof(text) 1049 >>> text += '????' >>> sys.getsizeof(text) 4080
4 interned机制
如果str对象的interned标志位为1,Python虚拟机将为其开启interned机制,
源码如下:(相关信息在网上可以看到很多说法和解释,这里笔者能力有限,暂时没有找到最确切的答案,之后补充。抱拳~但是我们通过分析源码应该是能看出一些门道的)
/* This dictionary holds all interned unicode strings. Note that references
to strings in this dictionary are *not* counted in the string's ob_refcnt.
When the interned string reaches a refcnt of 0 the string deallocation
function will delete the reference from this dictionary.
Another way to look at this is that to say that the actual reference
count of a string is: s->ob_refcnt + (s->state ? 2 : 0)
*/
static PyObject *interned = NULL;
void
PyUnicode_InternInPlace(PyObject **p)
{
PyObject *s = *p;
PyObject *t;
#ifdef Py_DEBUG
assert(s != NULL);
assert(_PyUnicode_CHECK(s));
#else
if (s == NULL || !PyUnicode_Check(s))
return;
#endif
/* If it's a subclass, we don't really know what putting
it in the interned dict might do. */
if (!PyUnicode_CheckExact(s))
return;
if (PyUnicode_CHECK_INTERNED(s))
return;
if (interned == NULL) {
interned = PyDict_New();
if (interned == NULL) {
PyErr_Clear(); /* Don't leave an exception */
return;
}
}
Py_ALLOW_RECURSION
t = PyDict_SetDefault(interned, s, s);
Py_END_ALLOW_RECURSION
if (t == NULL) {
PyErr_Clear();
return;
}
if (t != s) {
Py_INCREF(t);
Py_SETREF(*p, t);
return;
}
/* The two references in interned are not counted by refcnt.
The deallocator will take care of this */
Py_REFCNT(s) -= 2;
_PyUnicode_STATE(s).interned = SSTATE_INTERNED_MORTAL;
}可以看到,源码前面还是做一些基本的检查。我们可以看一下37行和50行:将s添加到interned字典中时,其实s同时是key和value(这里我不太清楚为什么会这样做),所以s对应的引用计数是+2了的(具体可以看PyDict_SetDefault()的源码),所以在50行时会将计数-2,保证引用计数的正确。
考虑下面的场景:
>>> class User:
def __init__(self, name, age):
self.name = name
self.age = age
>>> user = User('Tom', 21)
>>> user.__dict__
{'name': 'Tom', 'age': 21}由于对象的属性由dict保存,这意味着每个User对象都要保存一个str对象‘name’,这会浪费大量的内存。而str是不可变对象,因此Python内部将有潜在重复可能的字符串都做成单例模式,这就是interned机制。Python具体做法就是在内部维护一个全局dict对象,所有开启interned机制的str对象均保存在这里,后续需要使用的时候,先创建,如果判断已经维护了相同的字符串,就会将新创建的这个对象回收掉。
示例:
由不同运算生成’abc’,最后都是同一个对象:
>>> a = 'abc' >>> b = 'ab' + 'c' >>> id(a), id(b), a is b (2752416949872, 2752416949872, True)
위 내용은 Python 내장 유형 str 소스 코드 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
Sublime 텍스트로 Python 코드를 실행하려면 먼저 Python 플러그인을 설치 한 다음 .py 파일을 작성하고 코드를 작성한 다음 CTRL B를 눌러 코드를 실행하면 콘솔에 출력이 표시됩니다.
 vscode에서 코드를 작성하는 위치
Apr 15, 2025 pm 09:54 PM
vscode에서 코드를 작성하는 위치
Apr 15, 2025 pm 09:54 PM
Visual Studio Code (VSCODE)에서 코드를 작성하는 것은 간단하고 사용하기 쉽습니다. vscode를 설치하고, 프로젝트를 만들고, 언어를 선택하고, 파일을 만들고, 코드를 작성하고, 저장하고 실행합니다. VSCODE의 장점에는 크로스 플랫폼, 무료 및 오픈 소스, 강력한 기능, 풍부한 확장 및 경량 및 빠른가 포함됩니다.
 Golang vs. Python : 성능 및 확장 성
Apr 19, 2025 am 12:18 AM
Golang vs. Python : 성능 및 확장 성
Apr 19, 2025 am 12:18 AM
Golang은 성능과 확장 성 측면에서 Python보다 낫습니다. 1) Golang의 컴파일 유형 특성과 효율적인 동시성 모델은 높은 동시성 시나리오에서 잘 수행합니다. 2) 해석 된 언어로서 파이썬은 천천히 실행되지만 Cython과 같은 도구를 통해 성능을 최적화 할 수 있습니다.
 메모장으로 파이썬을 실행하는 방법
Apr 16, 2025 pm 07:33 PM
메모장으로 파이썬을 실행하는 방법
Apr 16, 2025 pm 07:33 PM
메모장에서 Python 코드를 실행하려면 Python 실행 파일 및 NPPEXEC 플러그인을 설치해야합니다. Python을 설치하고 경로를 추가 한 후 nppexec 플러그인의 명령 "Python"및 매개 변수 "{current_directory} {file_name}"을 구성하여 Notepad의 단축키 "F6"을 통해 Python 코드를 실행하십시오.
