

Python 가상 머신 바이트를 구현하는 방법은 무엇입니까?

数据结构
typedef struct {
PyObject_VAR_HEAD
Py_hash_t ob_shash;
char ob_sval[1];
/* Invariants:
* ob_sval contains space for 'ob_size+1' elements.
* ob_sval[ob_size] == 0.
* ob_shash is the hash of the string or -1 if not computed yet.
*/
} PyBytesObject;
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
typedef struct _object {
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;上面的数据结构用图示如下所示:
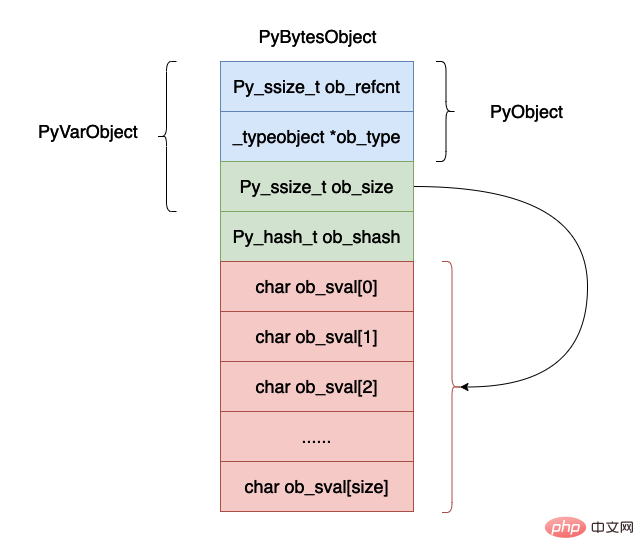
现在我们来解释一下上面的数据结构各个字段的含义:
ob_refcnt,这个还是对象的引用计数的个数,主要是在垃圾回收的时候有用。
ob_type,这个是对象的数据类型。
ob_size,表示这个对象当中字节的个数。
ob_shash,对象的哈希值,如果还没有计算,哈希值为 -1 。
ob_sval,一个数据存储一个字节的数据,需要注意的是 ob_sval[size] 一定等于 '\0' ,表示字符串的结尾。
可能你会有疑问上面的结构体当中并没有后面的那么多字节啊,数组只有一个字节的数据啊,这是因为在 cpython 的实现当中除了申请 PyBytesObject 大的小内存空间之外,还会在这个基础之上申请连续的额外的内存空间用于保存数据,在后续的源码分析当中可以看到这一点。
下面我们举几个例子来说明一下上面的布局:
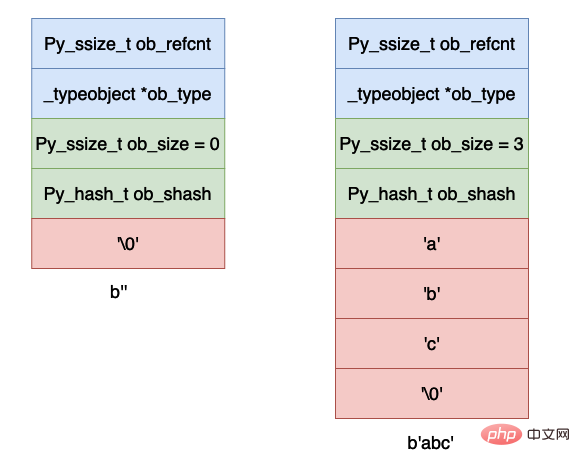
上面是空和字符串 abc 的字节表示。
创建字节对象
下面是在 cpython 当中通过字节数创建 PyBytesObject 对象的函数。下面的函数的主要功能是创建一个能够存储 size 个字节大小的数据的 PyBytesObject 对象,下面的函数最重要的一个步骤就是申请内存空间。
static PyObject *
_PyBytes_FromSize(Py_ssize_t size, int use_calloc)
{
PyBytesObject *op;
assert(size >= 0);
if (size == 0 && (op = nullstring) != NULL) {
#ifdef COUNT_ALLOCS
null_strings++;
#endif
Py_INCREF(op);
return (PyObject *)op;
}
if ((size_t)size > (size_t)PY_SSIZE_T_MAX - PyBytesObject_SIZE) {
PyErr_SetString(PyExc_OverflowError,
"byte string is too large");
return NULL;
}
/* Inline PyObject_NewVar */
// PyBytesObject_SIZE + size 就是实际申请的内存空间的大小 PyBytesObject_SIZE 就是表示 PyBytesObject 各个字段占用的实际的内存空间大小
if (use_calloc)
op = (PyBytesObject *)PyObject_Calloc(1, PyBytesObject_SIZE + size);
else
op = (PyBytesObject *)PyObject_Malloc(PyBytesObject_SIZE + size);
if (op == NULL)
return PyErr_NoMemory();
// 将对象的 ob_size 字段赋值成 size
(void)PyObject_INIT_VAR(op, &PyBytes_Type, size);
// 由于对象的哈希值还没有进行计算 因此现将哈希值赋值成 -1
op->ob_shash = -1;
if (!use_calloc)
op->ob_sval[size] = '\0';
/* empty byte string singleton */
if (size == 0) {
nullstring = op;
Py_INCREF(op);
}
return (PyObject *) op;
}我们可以使用一个写例子来看一下实际的 PyBytesObject 内存空间的大小。
>>> import sys >>> a = b"hello world" >>> sys.getsizeof(a) 44 >>>
上面的 44 = 32 + 11 + 1 。
其中 32 是 PyBytesObject 4 个字段所占用的内存空间,ob_refcnt、ob_type、ob_size和 ob_shash 各占 8 个字节。11 是表示字符串 "hello world" 占用 11 个字节,最后一个字节是 '\0' 。
查看字节长度
这个函数主要是返回 PyBytesObject 对象的字节长度,也就是直接返回 ob_size 的值。
static Py_ssize_t
bytes_length(PyBytesObject *a)
{
// (((PyVarObject*)(ob))->ob_size)
return Py_SIZE(a);
}字节拼接
在 python 当中执行下面的代码就会执行字节拼接函数:
>>> b"abc" + b"edf"
下方就是具体的执行字节拼接的函数:
/* This is also used by PyBytes_Concat() */
static PyObject *
bytes_concat(PyObject *a, PyObject *b)
{
Py_buffer va, vb;
PyObject *result = NULL;
va.len = -1;
vb.len = -1;
// Py_buffer 当中有一个指针字段 buf 可以用户保存 PyBytesObject 当中字节数据的首地址
// PyObject_GetBuffer 函数的主要作用是将 对象 a 当中的字节数组赋值给 va 当中的 buf
if (PyObject_GetBuffer(a, &va, PyBUF_SIMPLE) != 0 ||
PyObject_GetBuffer(b, &vb, PyBUF_SIMPLE) != 0) {
PyErr_Format(PyExc_TypeError, "can't concat %.100s to %.100s",
Py_TYPE(b)->tp_name, Py_TYPE(a)->tp_name);
goto done;
}
/* Optimize end cases */
if (va.len == 0 && PyBytes_CheckExact(b)) {
result = b;
Py_INCREF(result);
goto done;
}
if (vb.len == 0 && PyBytes_CheckExact(a)) {
result = a;
Py_INCREF(result);
goto done;
}
if (va.len > PY_SSIZE_T_MAX - vb.len) {
PyErr_NoMemory();
goto done;
}
result = PyBytes_FromStringAndSize(NULL, va.len + vb.len);
// 下方就是将对象 a b 当中的字节数据拷贝到新的
if (result != NULL) {
// PyBytes_AS_STRING 宏定义在下方当中 主要就是使用 PyBytesObject 对象当中的
// ob_sval 字段 也就是将 buf 数据(也就是 a 或者 b 当中的字节数据)拷贝到 ob_sval当中
memcpy(PyBytes_AS_STRING(result), va.buf, va.len);
memcpy(PyBytes_AS_STRING(result) + va.len, vb.buf, vb.len);
}
done:
if (va.len != -1)
PyBuffer_Release(&va);
if (vb.len != -1)
PyBuffer_Release(&vb);
return result;
}#define PyBytes_AS_STRING(op) (assert(PyBytes_Check(op)), \
(((PyBytesObject *)(op))->ob_sval))我们修改一个这个函数,在其中加入一条打印语句,然后重新编译 python 执行结果如下所示:

Python 3.9.0b1 (default, Mar 23 2023, 08:35:33) [GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> b"abc" + b"edf" In concat function: abc <> edf b'abcedf' >>>
在上面的拼接函数当中会拷贝原来的两个字节对象,因此需要谨慎使用,一旦发生非常多的拷贝的话是非常耗费内存的。因此需要警惕使用循环内的内存拼接。比如对于 [b"a", b"b", b"c"] 来说,如果使用循环拼接的话,那么会将 b"a" 拷贝两次。
>>> res = b"" >>> for item in [b"a", b"b", b"c"]: ... res += item ... >>> res b'abc' >>>
因为 b"a", b"b" 在拼接的时候会将他们分别拷贝一次,在进行 b"ab",b"c" 拼接的时候又会将 ab 和 c 拷贝一次,那么具体的拷贝情况如下所示:
"a" 拷贝了一次。
"b" 拷贝了一次。
"ab" 拷贝了一次。
"c" 拷贝了一次。
但是实际上我们的需求是只需要对 [b"a", b"b", b"c"] 当中的数据各拷贝一次,如果我们要实现这一点可以使用 b"".join([b"a", b"b", b"c"]),直接将 [b"a", b"b", b"c"] 作为参数传递,然后各自只拷贝一次,具体的实现代码如下所示,在这个例子当中 sep 就是空串 b"",iterable 就是 [b"a", b"b", b"c"] 。
Py_LOCAL_INLINE(PyObject *)
STRINGLIB(bytes_join)(PyObject *sep, PyObject *iterable)
{
char *sepstr = STRINGLIB_STR(sep);
const Py_ssize_t seplen = STRINGLIB_LEN(sep);
PyObject *res = NULL;
char *p;
Py_ssize_t seqlen = 0;
Py_ssize_t sz = 0;
Py_ssize_t i, nbufs;
PyObject *seq, *item;
Py_buffer *buffers = NULL;
#define NB_STATIC_BUFFERS 10
Py_buffer static_buffers[NB_STATIC_BUFFERS];
seq = PySequence_Fast(iterable, "can only join an iterable");
if (seq == NULL) {
return NULL;
}
seqlen = PySequence_Fast_GET_SIZE(seq);
if (seqlen == 0) {
Py_DECREF(seq);
return STRINGLIB_NEW(NULL, 0);
}
#ifndef STRINGLIB_MUTABLE
if (seqlen == 1) {
item = PySequence_Fast_GET_ITEM(seq, 0);
if (STRINGLIB_CHECK_EXACT(item)) {
Py_INCREF(item);
Py_DECREF(seq);
return item;
}
}
#endif
if (seqlen > NB_STATIC_BUFFERS) {
buffers = PyMem_NEW(Py_buffer, seqlen);
if (buffers == NULL) {
Py_DECREF(seq);
PyErr_NoMemory();
return NULL;
}
}
else {
buffers = static_buffers;
}
/* Here is the general case. Do a pre-pass to figure out the total
* amount of space we'll need (sz), and see whether all arguments are
* bytes-like.
*/
for (i = 0, nbufs = 0; i < seqlen; i++) {
Py_ssize_t itemlen;
item = PySequence_Fast_GET_ITEM(seq, i);
if (PyBytes_CheckExact(item)) {
/* Fast path. */
Py_INCREF(item);
buffers[i].obj = item;
buffers[i].buf = PyBytes_AS_STRING(item);
buffers[i].len = PyBytes_GET_SIZE(item);
}
else if (PyObject_GetBuffer(item, &buffers[i], PyBUF_SIMPLE) != 0) {
PyErr_Format(PyExc_TypeError,
"sequence item %zd: expected a bytes-like object, "
"%.80s found",
i, Py_TYPE(item)->tp_name);
goto error;
}
nbufs = i + 1; /* for error cleanup */
itemlen = buffers[i].len;
if (itemlen > PY_SSIZE_T_MAX - sz) {
PyErr_SetString(PyExc_OverflowError,
"join() result is too long");
goto error;
}
sz += itemlen;
if (i != 0) {
if (seplen > PY_SSIZE_T_MAX - sz) {
PyErr_SetString(PyExc_OverflowError,
"join() result is too long");
goto error;
}
sz += seplen;
}
if (seqlen != PySequence_Fast_GET_SIZE(seq)) {
PyErr_SetString(PyExc_RuntimeError,
"sequence changed size during iteration");
goto error;
}
}
/* Allocate result space. */
res = STRINGLIB_NEW(NULL, sz);
if (res == NULL)
goto error;
/* Catenate everything. */
p = STRINGLIB_STR(res);
if (!seplen) {
/* fast path */
for (i = 0; i < nbufs; i++) {
Py_ssize_t n = buffers[i].len;
char *q = buffers[i].buf;
Py_MEMCPY(p, q, n);
p += n;
}
goto done;
}
// 具体的实现逻辑就是在这里
for (i = 0; i < nbufs; i++) {
Py_ssize_t n;
char *q;
if (i) {
// 首先现将 sepstr 拷贝到新的数组里面但是在我们举的例子当中是空串 b""
Py_MEMCPY(p, sepstr, seplen);
p += seplen;
}
n = buffers[i].len;
q = buffers[i].buf;
// 然后将列表当中第 i 个 bytes 的数据拷贝到 p 当中 这样就是实现了我们所需要的效果
Py_MEMCPY(p, q, n);
p += n;
}
goto done;
error:
res = NULL;
done:
Py_DECREF(seq);
for (i = 0; i < nbufs; i++)
PyBuffer_Release(&buffers[i]);
if (buffers != static_buffers)
PyMem_FREE(buffers);
return res;
}单字节字符
在 cpython 的内部实现当中给单字节的字符做了一个小的缓冲池:
static PyBytesObject *characters[UCHAR_MAX + 1]; // UCHAR_MAX 在 64 位系统当中等于 255
当创建的 bytes 只有一个字符的时候就可以检查是否 characters 当中已经存在了,如果存在就直接返回这个已经创建好的 PyBytesObject 对象,否则再进行创建。新创建的 PyBytesObject 对象如果长度等于 1 的话也会被加入到这个数组当中。下面是 PyBytesObject 的另外一个创建函数:
PyObject *
PyBytes_FromStringAndSize(const char *str, Py_ssize_t size)
{
PyBytesObject *op;
if (size < 0) {
PyErr_SetString(PyExc_SystemError,
"Negative size passed to PyBytes_FromStringAndSize");
return NULL;
}
// 如果创建长度等于 1 而且对象在 characters 当中存在的话那么就直接返回
if (size == 1 && str != NULL &&
(op = characters[*str & UCHAR_MAX]) != NULL)
{
#ifdef COUNT_ALLOCS
one_strings++;
#endif
Py_INCREF(op);
return (PyObject *)op;
}
op = (PyBytesObject *)_PyBytes_FromSize(size, 0);
if (op == NULL)
return NULL;
if (str == NULL)
return (PyObject *) op;
Py_MEMCPY(op->ob_sval, str, size);
/* share short strings */
// 如果创建的对象的长度等于 1 那么久将这个对象保存到 characters 当中
if (size == 1) {
characters[*str & UCHAR_MAX] = op;
Py_INCREF(op);
}
return (PyObject *) op;
}我们可以使用下面的代码进行验证:
>>> a = b"a" >>> b =b"a" >>> a == b True >>> a is b True >>> a = b"aa" >>> b = b"aa" >>> a == b True >>> a is b False
从上面的代码可以知道,确实当我们创建的 bytes 的长度等于 1 的时候对象确实是同一个对象。
위 내용은 Python 가상 머신 바이트를 구현하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7546
7546
 15
1381
52
83
11
57
19
21
89
15
1381
52
83
11
57
19
21
89

 PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP와 Python은 고유 한 장점과 단점이 있으며 선택은 프로젝트 요구와 개인 선호도에 달려 있습니다. 1.PHP는 대규모 웹 애플리케이션의 빠른 개발 및 유지 보수에 적합합니다. 2. Python은 데이터 과학 및 기계 학습 분야를 지배합니다.
 Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
CentOS 시스템에서 Pytorch GPU 가속도를 활성화하려면 Cuda, Cudnn 및 GPU 버전의 Pytorch를 설치해야합니다. 다음 단계는 프로세스를 안내합니다. CUDA 및 CUDNN 설치 CUDA 버전 호환성 결정 : NVIDIA-SMI 명령을 사용하여 NVIDIA 그래픽 카드에서 지원하는 CUDA 버전을보십시오. 예를 들어, MX450 그래픽 카드는 CUDA11.1 이상을 지원할 수 있습니다. Cudatoolkit 다운로드 및 설치 : NVIDIACUDATOOLKIT의 공식 웹 사이트를 방문하여 그래픽 카드에서 지원하는 가장 높은 CUDA 버전에 따라 해당 버전을 다운로드하여 설치하십시오. CUDNN 라이브러리 설치 :
 Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker는 Linux 커널 기능을 사용하여 효율적이고 고립 된 응용 프로그램 실행 환경을 제공합니다. 작동 원리는 다음과 같습니다. 1. 거울은 읽기 전용 템플릿으로 사용되며, 여기에는 응용 프로그램을 실행하는 데 필요한 모든 것을 포함합니다. 2. Union 파일 시스템 (Unionfs)은 여러 파일 시스템을 스택하고 차이점 만 저장하고 공간을 절약하고 속도를 높입니다. 3. 데몬은 거울과 컨테이너를 관리하고 클라이언트는 상호 작용을 위해 사용합니다. 4. 네임 스페이스 및 CGroup은 컨테이너 격리 및 자원 제한을 구현합니다. 5. 다중 네트워크 모드는 컨테이너 상호 연결을 지원합니다. 이러한 핵심 개념을 이해 함으로써만 Docker를 더 잘 활용할 수 있습니다.
 Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python과 JavaScript는 커뮤니티, 라이브러리 및 리소스 측면에서 고유 한 장점과 단점이 있습니다. 1) Python 커뮤니티는 친절하고 초보자에게 적합하지만 프론트 엔드 개발 리소스는 JavaScript만큼 풍부하지 않습니다. 2) Python은 데이터 과학 및 기계 학습 라이브러리에서 강력하며 JavaScript는 프론트 엔드 개발 라이브러리 및 프레임 워크에서 더 좋습니다. 3) 둘 다 풍부한 학습 리소스를 가지고 있지만 Python은 공식 문서로 시작하는 데 적합하지만 JavaScript는 MDNWebDocs에서 더 좋습니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 미니 오펜 센토 호환성
Apr 14, 2025 pm 05:45 PM
미니 오펜 센토 호환성
Apr 14, 2025 pm 05:45 PM
Minio Object Storage : Centos System Minio 하의 고성능 배포는 Go Language를 기반으로 개발 한 고성능 분산 객체 저장 시스템입니다. Amazons3과 호환됩니다. Java, Python, JavaScript 및 Go를 포함한 다양한 클라이언트 언어를 지원합니다. 이 기사는 CentOS 시스템에 대한 Minio의 설치 및 호환성을 간단히 소개합니다. CentOS 버전 호환성 Minio는 다음을 포함하되 이에 국한되지 않는 여러 CentOS 버전에서 확인되었습니다. CentOS7.9 : 클러스터 구성, 환경 준비, 구성 파일 설정, 디스크 파티셔닝 및 미니를 다루는 완전한 설치 안내서를 제공합니다.
 Centos에서 Pytorch의 분산 교육을 운영하는 방법
Apr 14, 2025 pm 06:36 PM
Centos에서 Pytorch의 분산 교육을 운영하는 방법
Apr 14, 2025 pm 06:36 PM
CentOS 시스템에 대한 Pytorch 분산 교육에는 다음 단계가 필요합니다. Pytorch 설치 : 전제는 Python과 PIP가 CentOS 시스템에 설치된다는 것입니다. CUDA 버전에 따라 Pytorch 공식 웹 사이트에서 적절한 설치 명령을 받으십시오. CPU 전용 교육의 경우 다음 명령을 사용할 수 있습니다. PipinStalltorchtorchvisiontorchaudio GPU 지원이 필요한 경우 CUDA 및 CUDNN의 해당 버전이 설치되어 있는지 확인하고 해당 PyTorch 버전을 설치하려면 설치하십시오. 분산 환경 구성 : 분산 교육에는 일반적으로 여러 기계 또는 단일 기계 다중 GPU가 필요합니다. 장소
 Centos에 nginx를 설치하는 방법
Apr 14, 2025 pm 08:06 PM
Centos에 nginx를 설치하는 방법
Apr 14, 2025 pm 08:06 PM
Centos Nginx를 설치하려면 다음 단계를 수행해야합니다. 개발 도구, PCRE-DEVEL 및 OPENSSL-DEVEL과 같은 종속성 설치. nginx 소스 코드 패키지를 다운로드하고 압축을 풀고 컴파일하고 설치하고 설치 경로를/usr/local/nginx로 지정하십시오. nginx 사용자 및 사용자 그룹을 만들고 권한을 설정하십시오. 구성 파일 nginx.conf를 수정하고 청취 포트 및 도메인 이름/IP 주소를 구성하십시오. Nginx 서비스를 시작하십시오. 종속성 문제, 포트 충돌 및 구성 파일 오류와 같은 일반적인 오류는주의를 기울여야합니다. 캐시를 켜고 작업자 프로세스 수 조정과 같은 특정 상황에 따라 성능 최적화를 조정해야합니다.
 Centos에서 Pytorch 버전을 선택하는 방법
Apr 14, 2025 pm 06:51 PM
Centos에서 Pytorch 버전을 선택하는 방법
Apr 14, 2025 pm 06:51 PM
CentOS 시스템에 Pytorch를 설치할 때는 적절한 버전을 신중하게 선택하고 다음 주요 요소를 고려해야합니다. 1. 시스템 환경 호환성 : 운영 체제 : CentOS7 이상을 사용하는 것이 좋습니다. Cuda 및 Cudnn : Pytorch 버전 및 Cuda 버전은 밀접하게 관련되어 있습니다. 예를 들어, pytorch1.9.0은 cuda11.1을 필요로하고 Pytorch2.0.1은 cuda11.3을 필요로합니다. CUDNN 버전도 CUDA 버전과 일치해야합니다. Pytorch 버전을 선택하기 전에 호환 CUDA 및 CUDNN 버전이 설치되었는지 확인하십시오. 파이썬 버전 : Pytorch 공식 지점
