
jieba는 중국어 단어 분할을 위한 탁월한 타사 라이브러리입니다. 중국어 텍스트의 각 한자는 연속적으로 작성되므로 각 단어를 얻으려면 특정 방법을 사용해야 합니다. 이 방법을 단어 분할이라고 합니다. Jieba는 Python 컴퓨팅 생태계에서 중국어 단어 분할을 위한 매우 뛰어난 타사 라이브러리입니다. 사용하려면 설치해야 합니다.
jieba 라이브러리는 세 가지 단어 분할 모드를 제공하지만 실제로 단어 분할 효과를 얻으려면 한 가지 기능만 익히면 충분하므로 매우 간단하고 효과적입니다.
타사 라이브러리를 설치하려면 pip 도구를 사용하고 명령줄(IDLE 아님)에서 설치 명령을 실행해야 합니다. 참고: Python 디렉터리와 그 아래의 Scripts 디렉터리를 환경 변수에 추가해야 합니다.
pip install jieba 명령을 사용하여 타사 라이브러리를 설치하면 설치 성공 여부를 알려주는 성공적으로 설치되었다는 메시지가 표시됩니다.
단어 분할 원리: 간단히 말하면 jieba 라이브러리는 중국어 어휘 라이브러리를 통해 단어 분할을 식별합니다. 먼저 한자 어휘를 이용하여 어휘를 통해 한자 간 단어의 연관 확률을 계산하므로, 한자 간 확률을 계산하여 단어 분할 결과를 도출할 수 있다. 물론 jieba의 자체 중국어 어휘 라이브러리 외에도 사용자는 사용자 정의 문구를 추가할 수도 있으므로 jieba의 단어 분할을 특정 특정 분야에서 사용하는 데 더 가깝게 만들 수 있습니다.
jieba는 Python용 중국어 단어 분할 라이브러리입니다. 사용 방법은 다음과 같습니다.
方式1: pip install jieba 方式2: 先下载 http://pypi.python.org/pypi/jieba/ 然后解压,运行 python setup.py install
jieba의 세 가지 일반적으로 사용되는 모드:
정확 모드, 문장을 가장 정확하게 자르려고 노력함, 텍스트 분석에 적합함
전체 모드, 모든 단어 자르기 문장 속 문장 단어로 구성될 수 있는 모든 단어를 스캔합니다. 속도는 매우 빠르지만 모호성을 해결할 수는 없습니다.
검색 엔진 모드는 정확한 모드를 기반으로 긴 단어를 다시 분할하여 회상률을 높입니다. 검색 엔진에 적합합니다.
단어 분할을 위해 jieba.cut 및 jieba.cut_for_search 메서드를 사용할 수 있습니다. 두 가지 모두에서 반환되는 구조는 for 루프를 사용할 수 있습니다. 단어 분할 후 얻은 각 단어(유니코드)를 가져오거나 jieba.lcut 및 jieba.lcut_for_search를 직접 사용하여 목록을 반환합니다. jieba.cut 和 jieba.cut_for_search 方法进行分词,两者所返回的结构都是一个可迭代的 generator,可使用 for 循环来获得分词后得到的每一个词语(unicode),或者直接使用 jieba.lcut 以及 jieba.lcut_for_search 返回 list。
jieba.Tokenizer(dictionary=DEFAULT_DICT) :使用该方法可以自定义分词器,可以同时使用不同的词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
jieba.cut 和 jieba.lcut 可接受的参数如下:
需要分词的字符串(unicode 或 UTF-8 字符串、GBK 字符串)
cut_all:是否使用全模式,默认值为 False
HMM:用来控制是否使用 HMM 模型,默认值为 True
jieba.cut_for_search 和 jieba.lcut_for_search 接受 2 个参数:
需要分词的字符串(unicode 或 UTF-8 字符串、GBK 字符串)
HMM:用来控制是否使用 HMM 模型,默认值为 True
jieba.Tokenizer(dictionary=DEFAULT_DICT): 토크나이저를 사용자 정의하고 동시에 다양한 사전을 사용하려면 이 방법을 사용하세요. jieba.dt는 기본 단어 분할기이며 모든 전역 단어 분할 관련 기능은 이 단어 분할기의 매핑입니다. jieba.cut 및 jieba.lcut은 다음과 같은 매개변수를 허용합니다. 단어 분할이 필요한 문자열(유니코드 또는 UTF-8 문자열, GBK 문자열)
cut_all : 풀 모드 사용 여부, 기본값은 False
HMM : HMM 모델 사용 여부를 제어하는데 사용, 기본값은 True</code ></p><p> </p><p><code>jieba.cut_for_search 및 jieba.lcut_for_search는 2개의 매개변수를 허용합니다:
단어 분할이 필요한 문자열(유니코드 또는 UTF-8 문자열, GBK 문자열)HMM: HMM 모델 사용 여부를 제어하는 데 사용됩니다. 기본값은
TrueGBK 문자열을 사용하지 않도록 주의해야 합니다. GBK 문자열은 예측 불가능하고 부정확할 수 있습니다. UTF-8로 디코딩됩니다. 세 가지 단어 분할 모드 비교: # 全匹配
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=True)
print(list(seg_list)) # ['今天', '哪里', '都', '没去', '', '', '在家', '家里', '睡', '了', '一天']
# 精确匹配 默认模式
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=False)
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']
# 精确匹配
seg_list = jieba.cut_for_search("今天哪里都没去,在家里睡了一天")
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']사용법: jieba.load_userdict(dict_path)
dict_path: 사용자 정의 사전 파일의 경로입니다.
한 단어는 한 줄을 차지합니다: 단어, 단어 빈도. (생략 가능) 품사 (생략 가능) 생략), 공백으로 구분되며 순서는 바뀔 수 없습니다.
사용자 정의 사전 user_dict.txt:
심층 학습
import jieba
test_sent = """
数学是一门基础性的大学课程,深度学习是基于数学的,尤其是线性代数课程
"""
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学', '课程', ',', '深度',
# '学习', '是', '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n']
words = jieba.cut(test_sent, cut_all=True)
print(list(words))
# ['\n', '数学', '是', '一门', '基础', '基础性', '的', '大学', '课程', '', '', '深度',
# '学习', '是', '基于', '数学', '的', '', '', '尤其', '是', '线性', '线性代数', '代数', '课程', '\n']
jieba.load_userdict("userdict.txt")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是',
# '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n']
jieba.add_word("尤其是")
jieba.add_word("线性代数课程")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是',
# '基于', '数学', '的', ',', '尤其是', '线性代数课程', '\n']也可以使用 jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件。
基于 TF-IDF 算法和TextRank算法的关键词抽取:
import jieba.analyse file = "sanguo.txt" topK = 12 content = open(file, 'rb').read() # 使用tf-idf算法提取关键词 tags = jieba.analyse.extract_tags(content, topK=topK) print(tags) # ['玄德', '程远志', '张角', '云长', '张飞', '黄巾', '封谞', '刘焉', '邓茂', '邹靖', '姓名', '招军'] # 使用textrank算法提取关键词 tags2 = jieba.analyse.textrank(content, topK=topK) # withWeight=True:将权重值一起返回 tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=True) print(tags) # [('玄德', 0.1038549799467099), ('程远志', 0.07787459004363208), ('张角', 0.0722532891360849), # ('云长', 0.07048801593691037), ('张飞', 0.060972692853113214), ('黄巾', 0.058227157790330185), # ('封谞', 0.0563904127495283), ('刘焉', 0.05470798376886792), ('邓茂', 0.04917692565566038), # ('邹靖', 0.04427258239705188), ('姓名', 0.04219704283997642), ('招军', 0.04182041076757075)]
上面的代码是读取文件,提取出现频率最高的前12个词。
词性标注主要是标记文本分词后每个词的词性,使用例子如下:
import jieba
import jieba.posseg as pseg
# 默认模式
seg_list = pseg.cut("今天哪里都没去,在家里睡了一天")
for word, flag in seg_list:
print(word + " " + flag)
"""
使用 jieba 默认模式的输出结果是:
我 r
Prefix dict has been built successfully.
今天 t
吃 v
早饭 n
了 ul
"""
# paddle 模式
words = pseg.cut("我今天吃早饭了",use_paddle=True)
"""
使用 paddle 模式的输出结果是:
我 r
今天 TIME
吃 v
早饭 n
了 xc
"""paddle模式的词性对照表如下:
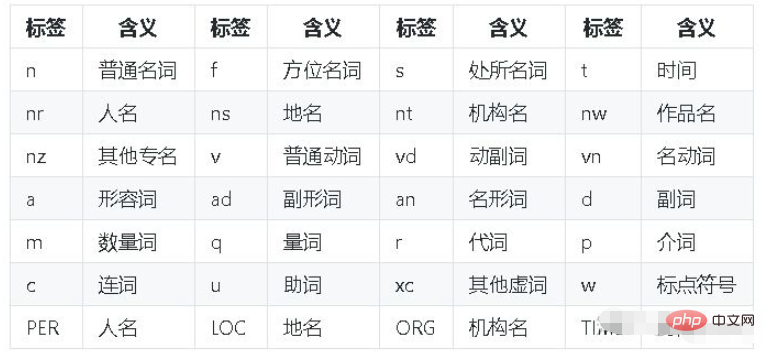
jieba分词有三种模式:精确模式、全模式和搜索引擎模式。
简单说,精确模式就是把一段文本精确的切分成若干个中文单词,若干个中文单词之间经过组合就精确的还原为之前的文本,其中不存在冗余单词。精确模式是最常用的分词模式。
进一步jieba又提供了全模式,全模式是把一段中文文本中所有可能的词语都扫描出来,可能有一段文本它可以切分成不同的模式或者有不同的角度来切分变成不同的词语,那么jieba在全模式下把这样的不同的组合都挖掘出来,所以如果用全模式来进行分词,分词的信息组合起来并不是精确的原有文本,会有很多的冗余。
而搜索引擎模式更加智能,它是在精确模式的基础上对长词进行再次切分,将长的词语变成更短的词语,进而适合搜索引擎对短词语的索引和搜索,在一些特定场合用的比较多。
jieba.lcut(s)
精确模式,能够对一个字符串精确地返回分词结果,而分词的结果使用列表形式来组织。例如:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家")
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 2.489 seconds.
Prefix dict has been built successfully.
['中国', '是', '一个', '伟大', '的', '国家']jieba.lcut(s,cut_all=True)
全模式,能够返回一个列表类型的分词结果,但结果存在冗余。例如:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家",cut_all=True)
['中国', '国是', '一个', '伟大', '的', '国家']jieba.lcut_for_search(s)
搜索引擎模式,能够返回一个列表类型的分词结果,也存在冗余。例如:
>>> import jieba
>>> jieba.lcut_for_search("中华人民共和国是伟大的")
['中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '是', '伟大', '的']jieba.add_word(w)
向分词词库添加新词w
最重要的就是jieba.lcut(s)函数,完成精确的中文分词。
위 내용은 Python에서 jieba 라이브러리를 사용하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



