

ConcurrentHashMap을 사용하여 Java에서 스레드로부터 안전한 매핑을 구현하는 방법은 무엇입니까?

jdk1.7 버전
데이터 구조
/**
* The segments, each of which is a specialized hash table.
*/
final Segment<K,V>[] segments;주로 세그먼트 배열임을 알 수 있으며, 주석도 작성되어 있으며 각각은 특수한 해시 테이블입니다.
Segment가 무엇인지 살펴보겠습니다.
static final class Segment<K,V> extends ReentrantLock implements Serializable {
......
/**
* The per-segment table. Elements are accessed via
* entryAt/setEntryAt providing volatile semantics.
*/
transient volatile HashEntry<K,V>[] table;
transient int threshold;
final float loadFactor;
// 构造函数
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}
......
}위는 Segment가 ReentrantLock을 상속받은 것을 볼 수 있으므로 실제로 각 Segment는 잠금입니다.
내부에는 HashEntry 배열이 저장되어 있고, 변수는 휘발성으로 장식되어 있습니다. HashEntry는 해시맵의 노드와 유사하며 연결리스트의 노드이기도 합니다.
구체적인 코드를 살펴보면 멤버 변수가 휘발성으로 수정된다는 점에서 해시맵과 약간 다른 것을 알 수 있습니다.
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
......
}그래서 ConcurrentHashMap의 데이터 구조는 아래 그림과 거의 같습니다.
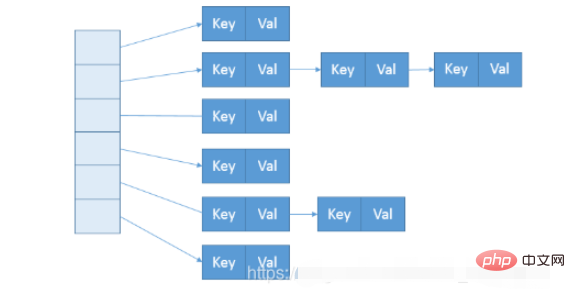
구성하는 동안 세그먼트 수는 소위 ConcurrentcyLevel에 의해 결정됩니다. 기본값은 16입니다. 해당 생성자에서 직접 지정할 수도 있습니다. Java에서는 2의 거듭제곱 값을 요구합니다. 입력이 15와 같이 거듭제곱이 아닌 값인 경우 자동으로 16과 같은 2의 거듭제곱 값으로 조정됩니다.
간단한 get 메소드부터 시작하여 소스 코드를 살펴보겠습니다.
get()
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 通过unsafe获取Segment数组的元素
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// 还是通过unsafe获取HashEntry数组的元素
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}get의 논리는 매우 간단합니다. 즉, Segment의 첨자에 해당하는 HashEntry 배열을 찾은 다음 HashEntry 배열의 첨자에 해당하는 연결 목록의 헤드를 검색한 다음 연결 목록 검색 데이터를 순회합니다.
배열의 데이터를 얻으려면 UNSAFE.getObjectVolatile(segments, u)를 사용하세요. Unsafe는 C 언어처럼 메모리에 직접 액세스하는 기능을 제공합니다. 이 방법을 사용하면 객체의 해당 오프셋 데이터를 얻을 수 있습니다. u는 계산된 오프셋이므로 세그먼트[i]와 동일하지만 더 효율적입니다.
put()
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}put 작업의 경우 Unsafe 호출 메서드를 통해 해당 Segment를 직접 얻은 후 스레드로부터 안전한 Put 작업이 수행됩니다.
주요 논리는 Segment 내부의 put 메서드에 있습니다
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// scanAndLockForPut会去查找是否有key相同Node
// 无论如何,确保获取锁
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// 更新已有value...
}
else {
// 放置HashEntry到特定位置,如果超过阈值,进行rehash
// ...
}
}
} finally {
unlock();
}
return oldValue;
}size()
주요 코드를 살펴보겠습니다.
for (;;) {
// 如果重试次数等于默认的2,就锁住所有的segment,来计算值
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
// 如果sum不再变化,就表示得到了一个确切的值
if (sum == last)
break;
last = sum;
}실제로는 모든 세그먼트의 개수의 합을 계산하기 위한 것입니다. 그 합이 지난번에 구한 값과 같다면 맵이 만들어진다는 뜻입니다. 조작된 적이 없으며 이 값은 비교적 정확합니다. 두 번 다시 시도한 후에도 여전히 통합된 값을 얻을 수 없는 경우 모든 세그먼트를 잠그고 값을 다시 가져옵니다.
Expansion
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
// 新表的大小是原来的两倍
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// 如果有多个节点
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
// 这里操作就是找到末尾的一段索引值都相同的链表节点,这段的头结点是lastRun.
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// 然后将lastRun结点赋值给数组位置,这样lastRun后面的节点也跟着过去了。
newTable[lastIdx] = lastRun;
// 之后就是复制开头到lastRun之间的节点
// Clone remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}jdk1.8 version
데이터 구조
ConcurrentHashmap의 1.8 버전은 전체적으로 Hashmap과 약간 비슷하지만 세그먼트가 제거되고 대신 노드 배열이 사용됩니다.
transient volatile Node<K,V>[] table;
1.8에도 여전히 Segment라는 내부 클래스가 있지만, 그 존재는 직렬화 호환성을 위해서만 존재하며 더 이상 사용되지 않습니다.
노드를 살펴보겠습니다. node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
......
}HashMap의 노드 노드와 유사하며 Map.Entry도 구현합니다. 차이점은 가시성을 보장하기 위해 val과 next를 휘발성으로 수정한다는 것입니다.
put()
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
// 初始化
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 利用CAS去进行无锁线程安全操作,如果bin是空的
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
// 细粒度的同步修改操作...
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 找到相同key就更新
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// 没有相同的就新增
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果是树节点,进行树的操作
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// Bin超过阈值,进行树化
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}동기화 로직에서 일반적으로 권장되는 ReentrantLock 등이 아닌 동기화를 사용하는 것을 볼 수 있습니다. 이제 JDK1.8에서는 동기화가 지속적으로 최적화되므로 더 이상 성능 차이에 대해 크게 걱정할 필요가 없습니다. 또한 ReentrantLock에 비해 메모리 소비를 줄일 수 있다는 점은 매우 큰 장점입니다.
동시에 Unsafe를 사용하여 보다 자세한 구현이 최적화되었습니다. 예를 들어 tabAt는 간접 호출의 오버헤드를 피하기 위해 getObjectAcquire를 직접 사용합니다.
그럼 크기가 어떻게 작용하는지 살펴볼까요?
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}여기서는 멤버 변수 counterCells를 가져오고 순회하여 총 개수를 가져오는 것입니다.
사실 CounterCell의 작동은 java.util.concurrent.atomic.LongAdder를 기반으로 합니다. 이는 Striped64 내부의 복잡한 로직을 활용하여 JVM이 더 높은 효율성을 위해 공간을 사용하는 방법입니다. 이는 매우 틈새 시장입니다. 대부분의 경우 대부분의 애플리케이션의 성능 요구 사항을 충족하기에 충분한 AtomicLong을 사용하는 것이 좋습니다.
Expansion
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
......
// 初始化
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// 是否继续处理下一个
boolean advance = true;
// 是否完成
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
// 首次循环才会进来这里
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
//扩容结束后做后续工作
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
//每当一条线程扩容结束就会更新一次 sizeCtl 的值,进行减 1 操作
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
// 如果是null,设置fwd
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// 说明该位置已经被处理过了,不需要再处理
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
// 真正的处理逻辑
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
// 树节点操作
else if (f instanceof TreeBin) {
......
}
}
}
}
}
} }
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
// 树节点操作
else if (f instanceof TreeBin) {
......
}
}
}
}
}
}핵심 논리는 두 개의 연결된 목록을 생성하는 HashMap과 동일하지만 lastRun을 가져오는 작업이 추가됩니다.
위 내용은 ConcurrentHashMap을 사용하여 Java에서 스레드로부터 안전한 매핑을 구현하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7563
7563
 15
1385
52
84
11
61
19
28
99
15
1385
52
84
11
61
19
28
99


 자바의 웨카
Aug 30, 2024 pm 04:28 PM
자바의 웨카
Aug 30, 2024 pm 04:28 PM
Java의 Weka 가이드. 여기에서는 소개, weka java 사용 방법, 플랫폼 유형 및 장점을 예제와 함께 설명합니다.
 Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 Smith Number 가이드. 여기서는 정의, Java에서 스미스 번호를 확인하는 방법에 대해 논의합니다. 코드 구현의 예.
 Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
이 기사에서는 가장 많이 묻는 Java Spring 면접 질문과 자세한 답변을 보관했습니다. 그래야 면접에 합격할 수 있습니다.
 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
 Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 TimeStamp to Date 안내. 여기서는 소개와 예제와 함께 Java에서 타임스탬프를 날짜로 변환하는 방법에 대해서도 설명합니다.
 캡슐의 양을 찾기위한 Java 프로그램
Feb 07, 2025 am 11:37 AM
캡슐의 양을 찾기위한 Java 프로그램
Feb 07, 2025 am 11:37 AM
캡슐은 3 차원 기하학적 그림이며, 양쪽 끝에 실린더와 반구로 구성됩니다. 캡슐의 부피는 실린더의 부피와 양쪽 끝에 반구의 부피를 첨가하여 계산할 수 있습니다. 이 튜토리얼은 다른 방법을 사용하여 Java에서 주어진 캡슐의 부피를 계산하는 방법에 대해 논의합니다. 캡슐 볼륨 공식 캡슐 볼륨에 대한 공식은 다음과 같습니다. 캡슐 부피 = 원통형 볼륨 2 반구 볼륨 안에, R : 반구의 반경. H : 실린더의 높이 (반구 제외). 예 1 입력하다 반경 = 5 단위 높이 = 10 단위 산출 볼륨 = 1570.8 입방 단위 설명하다 공식을 사용하여 볼륨 계산 : 부피 = π × r2 × h (4
 Spring Tool Suite에서 첫 번째 Spring Boot 응용 프로그램을 실행하는 방법은 무엇입니까?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suite에서 첫 번째 Spring Boot 응용 프로그램을 실행하는 방법은 무엇입니까?
Feb 07, 2025 pm 12:11 PM
Spring Boot는 강력하고 확장 가능하며 생산 가능한 Java 응용 프로그램의 생성을 단순화하여 Java 개발에 혁명을 일으킨다. Spring Ecosystem에 내재 된 "구성에 대한 협약"접근 방식은 수동 설정, Allo를 최소화합니다.
