
Catboost를 사용하여 예측을 위해 RNN, ARIMA 및 Prophet 모델에서 신호를 추출합니다.
다양한 약한 학습기를 통합하면 예측 정확도가 향상될 수 있지만 모델이 이미 매우 강력하다면 앙상블 학습이 금상첨화일 수 있습니다. 인기 있는 기계 학습 라이브러리 scikit-learn은 시계열 작업에 사용할 수 있는 StackingRegressor를 제공합니다. 그러나 StackingRegressor에는 다른 scikit-learn 모델 클래스와 API만 허용한다는 제한이 있습니다. 따라서 scikit-learn에서 사용할 수 없는 ARIMA와 같은 모델이나 심층 신경망의 모델은 사용할 수 없습니다. 이번 포스팅에서는 우리가 볼 수 있는 모델의 예측을 쌓는 방법을 보여드리겠습니다.

다음 패키지를 사용합니다:
pip install --upgrade scalecast conda install tensorflow conda install shap conda install -c conda-forge cmdstanpy pip install prophet
데이터 세트는 매시간 훈련 세트(관찰 700개)와 테스트 세트(관찰 48개)로 나뉩니다. 다음 코드는 데이터를 읽고 이를 Forecaster 개체에 저장합니다.
import pandas as pd import numpy as np from scalecast.Forecaster import Forecaster from scalecast.util import metrics import matplotlib.pyplot as plt import seaborn as sns def read_data(idx = 'H1', cis = True, metrics = ['smape']): info = pd.read_csv( 'M4-info.csv', index_col=0, parse_dates=['StartingDate'], dayfirst=True, ) train = pd.read_csv( f'Hourly-train.csv', index_col=0, ).loc[idx] test = pd.read_csv( f'Hourly-test.csv', index_col=0, ).loc[idx] y = train.values sd = info.loc[idx,'StartingDate'] fcst_horizon = info.loc[idx,'Horizon'] cd = pd.date_range( start = sd, freq = 'H', periods = len(y), ) f = Forecaster( y = y, # observed values current_dates = cd, # current dates future_dates = fcst_horizon, # forecast length test_length = fcst_horizon, # test-set length cis = cis, # whether to evaluate intervals for each model metrics = metrics, # what metrics to evaluate ) return f, test.values f, test_set = read_data() f # display the Forecaster object
결과는 다음과 같습니다.
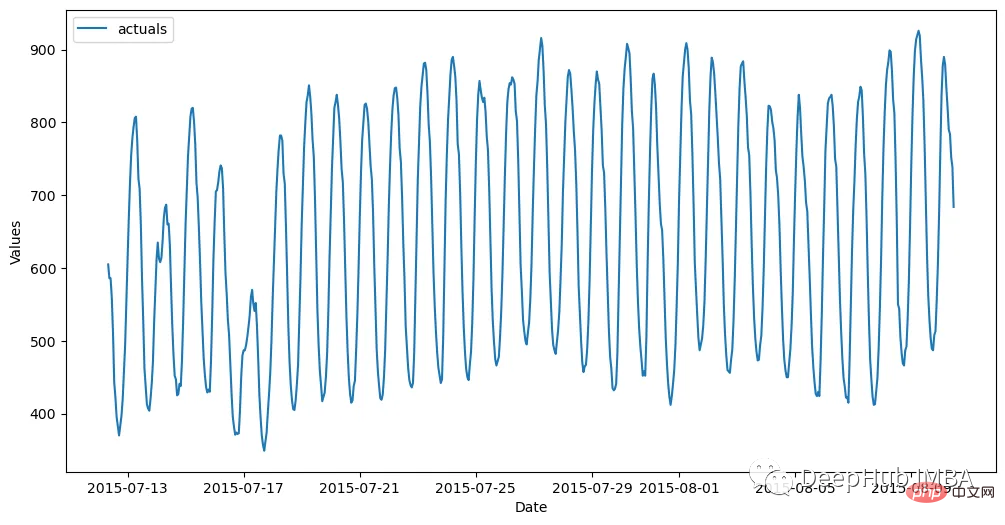
모델 구축을 시작하기 전에 모델에서 가장 간단한 예측을 생성해야 합니다. , 순진한 방법은 최신 24개의 관측치를 전달하는 것입니다.
f.set_estimator('naive')
f.manual_forecast(seasonal=True)그런 다음 ARIMA, LSTM 및 Prophet을 벤치마크로 사용하세요.
자동회귀 통합 이동 평균은 계열의 지연 및 오류를 사용하여 선형 방식으로 미래를 예측하는 인기 있고 간단한 시계열 기술입니다. EDA를 통해 우리는 이 시리즈가 계절성이 높다는 것을 확인했습니다. 그래서 저는 마침내 (5,1,4) x(1,1,1,24) 순서의 계절성 ARIMA 모델을 적용하기로 결정했습니다.
f.set_estimator('arima')
f.manual_forecast(
order = (5,1,4),
seasonal_order = (1,1,1,24),
call_me = 'manual_arima',
)ARIMA가 상대적으로 단순한 유형의 시계열 모델이라면 LSTM은 더욱 발전된 방법 중 하나입니다. 이는 순차 데이터에서 장기 및 단기 패턴을 발견하는 메커니즘을 포함하여 많은 매개변수가 있는 딥러닝 기술로, 이론적으로 시계열에 이상적입니다. 여기에는 tensorflow를 사용하여 이 모델을 구축합니다.
f.set_estimator('rnn')
f.manual_forecast(
lags = 48,
layers_struct=[
('LSTM',{'units':100,'activation':'tanh'}),
('LSTM',{'units':100,'activation':'tanh'}),
('LSTM',{'units':100,'activation':'tanh'}),
],
optimizer = 'Adam',
epochs = 15,
plot_loss = True,
validation_split=0.2,
call_me = 'rnn_tanh_activation',
)
f.manual_forecast(
lags = 48,
layers_struct=[
('LSTM',{'units':100,'activation':'relu'}),
('LSTM',{'units':100,'activation':'relu'}),
('LSTM',{'units':100,'activation':'relu'}),
],
optimizer = 'Adam',
epochs = 15,
plot_loss = True,
validation_split=0.2,
call_me = 'rnn_relu_activation',
)인기에도 불구하고 일부에서는 정확성이 인상적이지 않다고 주장합니다. 주로 추세 추론이 때때로 비현실적이며 자동 회귀를 통해 지역적 패턴을 고려하지 않기 때문입니다. 모델링. 그러나 그것은 또한 그 자체의 특징을 가지고 있습니다. 1. 모델에 휴일 효과를 자동으로 적용하고 여러 유형의 계절성을 고려합니다. 이 모든 작업은 사용자가 요구하는 최소한으로 수행할 수 있으므로 최종 예측보다는 신호로 사용하는 것을 선호합니다.
f.set_estimator('prophet')
f.manual_forecast()이제 각 모델에 대한 예측을 생성했으므로 훈련 세트의 마지막 48개 관찰인 검증 세트에서 모델이 어떻게 수행되는지 살펴보겠습니다.
results = f.export(determine_best_by='TestSetSMAPE') ms = results['model_summaries'] ms[ [ 'ModelNickname', 'TestSetLength', 'TestSetSMAPE', 'InSampleSMAPE', ] ]
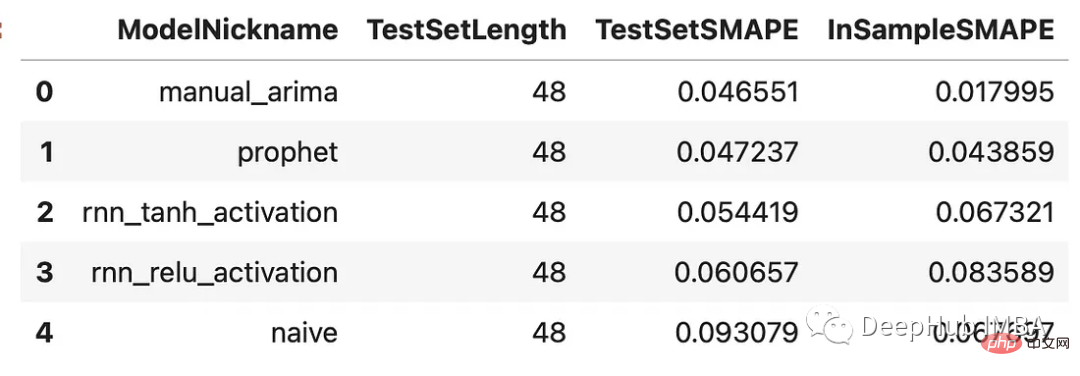
모든 모델은 순진한 방법보다 성능이 뛰어납니다. ARIMA 모델은 4.7%의 백분율 오차로 가장 좋은 성능을 보였으며 Prophet 모델이 그 뒤를 이었습니다. 모든 예측과 검증 세트를 살펴보겠습니다.
f.plot(order_by="TestSetSMAPE",ci=True) plt.show()

이 모든 모델은 이 시계열에서 합리적으로 좋은 성능을 발휘하며, 모델 사이에는 큰 차이가 없습니다.
각 누적 모델에는 다른 모델의 다양한 추정치를 필터링하여 새로운 예측 세트를 생성하는 최종 추정기가 필요합니다. 이전 결과를 Catboost 추정기로 오버레이하겠습니다. Catboost는 강력한 프로그램이며 적용된 각 모델에서 최고의 신호를 풍부하게 해줄 것으로 기대됩니다.
f.add_signals(
f.history.keys(), # add signals from all previously evaluated models
)
f.add_ar_terms(48)
f.set_estimator('catboost')위의 코드는 평가된 각 모델의 예측을 Forecaster 개체에 추가합니다. 이러한 예측을 '신호'라고 부릅니다. 이는 동일한 개체에 저장된 다른 공변량과 동일하게 처리됩니다. Catboost 모델이 예측을 수행하는 데 사용할 수 있는 추가 회귀 변수로 마지막 48개의 시차 계열도 여기에 추가됩니다. 이제 세 가지 Catboost 모델을 호출해 보겠습니다. 하나는 사용 가능한 모든 신호와 지연을 사용하고, 하나는 신호만 사용하고, 다른 하나는 지연만 사용합니다.
f.manual_forecast(
Xvars='all',
call_me='catboost_all_reg',
verbose = False,
)
f.manual_forecast(
Xvars=[x for x in f.get_regressor_names() if x.startswith('AR')],
call_me = 'catboost_lags_only',
verbose = False,
)
f.manual_forecast(
Xvars=[x for x in f.get_regressor_names() if not x.startswith('AR')],
call_me = 'catboost_signals_only',
verbose = False,
)아래에서는 모든 모델의 결과를 비교할 수 있습니다. SMPE와 MASE(평균 절대 크기 오류)라는 두 가지 측정항목을 살펴보겠습니다. 이는 실제 M4 대회에서 사용되는 두 가지 지표입니다.
test_results = pd.DataFrame(index = f.history.keys(),columns = ['smape','mase'])
for k, v in f.history.items():
test_results.loc[k,['smape','mase']] = [
metrics.smape(test_set,v['Forecast']),
metrics.mase(test_set,v['Forecast'],m=24,obs=f.y),
]
test_results.sort_values('smape')
可以看到,通过组合来自不同类型模型的信号生成了两个优于其他估计器的估计器:使用所有信号训练的Catboost模型和只使用信号的Catboost模型。这两种方法的样本误差都在2.8%左右。下面是对比图:
fig, ax = plt.subplots(figsize=(12,6)) f.plot( models = ['catboost_all_reg','catboost_signals_only'], ci=True, ax = ax ) sns.lineplot( x = f.future_dates, y = test_set, ax = ax, label = 'held out actuals', color = 'darkblue', alpha = .75, ) plt.show()

为了完善分析,我们可以使用shapley评分来确定哪些信号是最重要的。Shapley评分被认为是确定给定机器学习模型中输入的预测能力的最先进的方法之一。得分越高,意味着输入在特定模型中越重要。
f.export_feature_importance('catboost_all_reg')
上面的图只显示了前几个最重要的预测因子,但我们可以从中看出,ARIMA信号是最重要的,其次是序列的第一个滞后,然后是Prophet。RNN模型的得分也高于许多滞后模型。如果我们想在未来训练一个更轻量的模型,这可能是一个很好的起点。
在这篇文章中,我展示了在时间序列上下文中集成模型的力量,以及如何使用不同的模型在时间序列上获得更高的精度。这里我们使用scalecast包,这个包的功能还是很强大的,如果你喜欢,可以去它的主页看看:https://github.com/mikekeith52/scalecast
本文的数据集是M4的时序竞赛:https://github.com/Mcompetitions/M4-methods
使用代码在这里:https://scalecast-examples.readthedocs.io/en/latest/misc/stacking/custom_stacking.html
위 내용은 시계열 모델을 통합하여 예측 정확도 향상의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



