
CompletableFuture는 1.8에 도입된 새로운 기능입니다. 특히 여러 비동기 컴퓨팅 장치를 직렬로 연결해야 하는 좀 더 복잡한 비동기 컴퓨팅 시나리오는 CompletableFuture를 사용하여 구현할 수 있습니다.
실제 세계에서 우리가 해결해야 할 복잡한 문제는 여러 단계로 나누어져야 합니다. 우리 코드와 마찬가지로 복잡한 논리적 메서드에서는 이를 단계별로 구현하기 위해 여러 메서드가 호출됩니다.
식목일에 나무를 심어야 하는 경우를 상상해 보세요. 다음 단계로 나누어집니다.
10분 동안 구멍을 파고
5분 동안 묘목을 얻습니다.
식물을 심습니다. 묘목 20분
물 5분
그 중 1과 2가 병렬화 될 수 있는 것은 1과 2가 완성되어야만 3단계로 진행이 가능하고, 그 후 4단계로 진행이 가능합니다.
다음과 같은 구현 방법이 있습니다.
현재 한 사람만 나무를 심고 100그루의 나무를 심어야 한다면 다음 순서로만 수행할 수 있습니다.
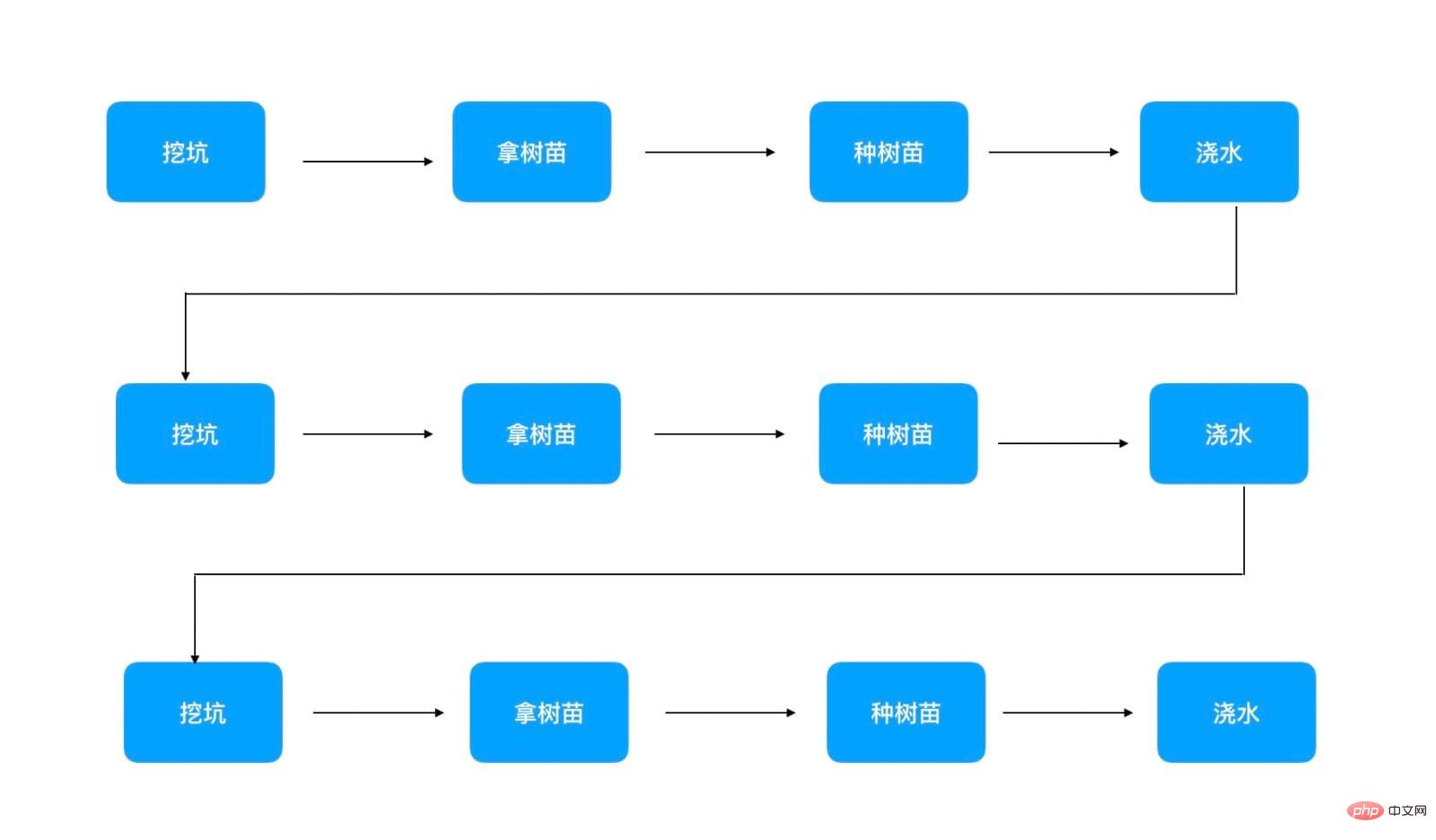
사진에는 수종만 기재되어 있습니다. 세 그루의 나무가 신호를 보냅니다. 순차적 실행에서는 나무 한 그루만 심을 수 있으므로 나무 100그루를 심는 데 40 * 100 = 4000 分钟가 걸린다는 것을 알 수 있습니다. 이 방법은 단일 스레드 동기 실행 프로그램에 해당합니다.
나무 심는 시간을 단축하는 방법은 무엇일까요? 오랫동안 동시성을 연구해 본 결과, 나에게는 전혀 문제가 되지 않았습니다. 나무 100그루를 심고 싶지 않으신가요? 그러면 함께 심을 사람 100명을 찾아 각자 한 그루씩 나무를 심겠습니다. 그러면 나무 100그루를 심는 데 40분밖에 걸리지 않습니다.
예, 프로그램에 위의 네 부분이 포함된 plantTree라는 메서드가 있는 경우 스레드는 100개만 필요합니다. 다만, 100개의 스레드를 생성하고 소멸시키는 데에는 시스템 리소스가 많이 소모된다는 점을 참고하시기 바랍니다. 스레드를 생성하고 삭제하는 데는 시간이 걸립니다. 게다가 CPU 코어 수는 실제로 100개의 스레드를 동시에 지원할 수 없습니다. 나무 10,000그루를 심고 싶다면 어떻게 해야 할까요? 10,000개의 스레드를 가질 수는 없습니다. 그렇죠?
그래서 이는 이상적인 상황일 뿐입니다. 일반적으로 스레드 풀을 통해 실행하며 실제로 100개의 스레드를 시작하지는 않습니다.
각 나무를 심을 때 여러 사람이 독립적인 단계를 동시에 진행할 수 있습니다.
이 방법은 첫 번째 단계가 구멍을 파는 것이므로 나무 심는 시간을 더욱 단축할 수 있습니다. 두 번째 단계는 구멍을 파는 것입니다. 두 사람이 동시에 할 수 있으므로 나무 한 그루당 35분밖에 걸리지 않습니다. 아래와 같이:
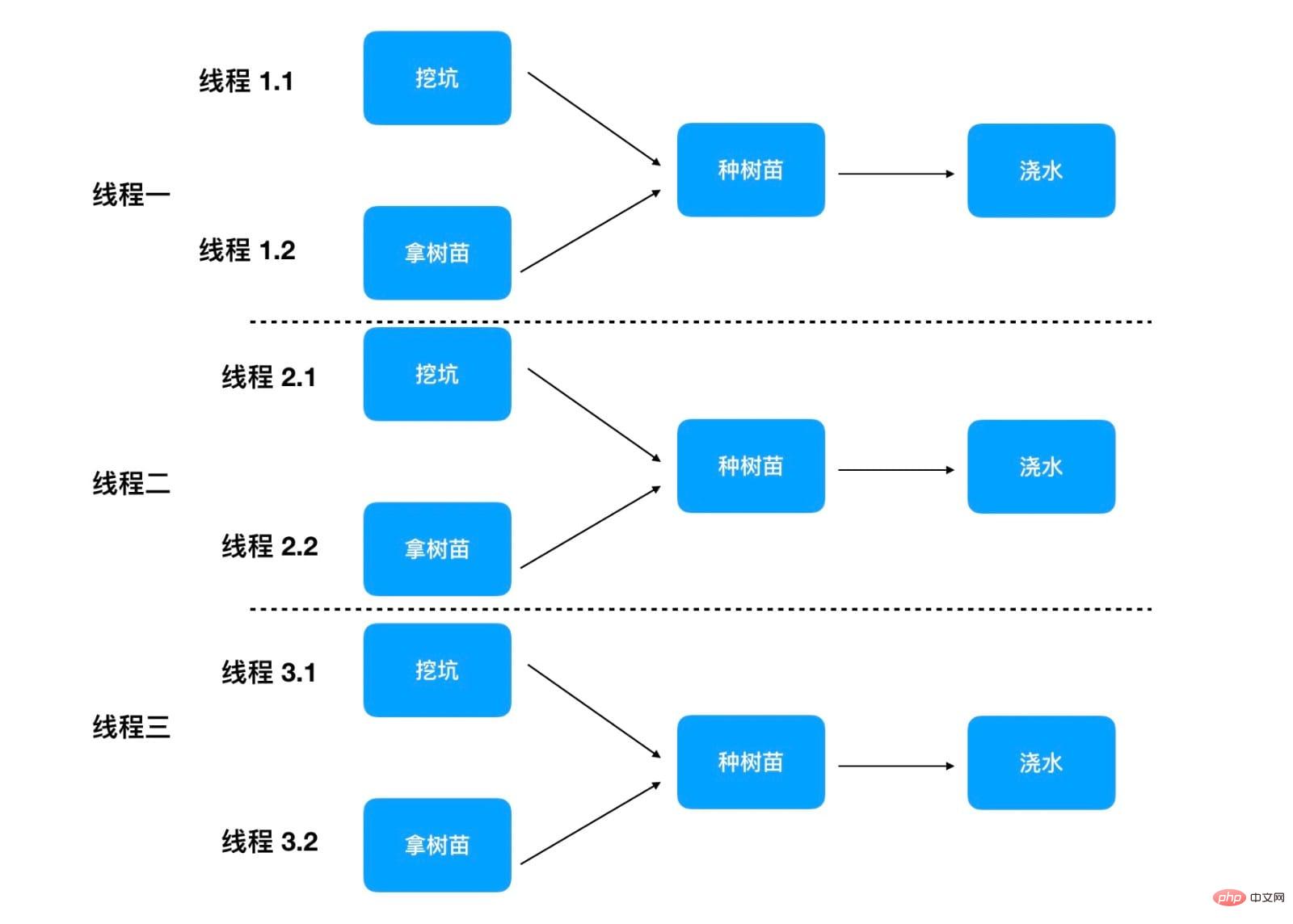
프로그램에 plantTree 메소드를 동시에 실행하는 100개의 메인 스레드가 있다면 나무 100그루를 심는 데 35분 밖에 걸리지 않습니다. 여기서는 1단계와 2단계를 동시에 수행하는 두 개의 스레드가 있으므로 각 스레드에 주의해야 합니다. 실제 작업에서는 100 x 3 = 300개의 스레드가 나무 심기에 참여하게 됩니다. 그러나 1단계와 2단계를 담당하는 스레드는 잠시만 참여하고 유휴 상태가 됩니다.
이 방법과 두 번째 방법 역시 스레드가 많이 생성되는 문제가 있습니다. 그래서 그것은 이상적인 상황입니다.
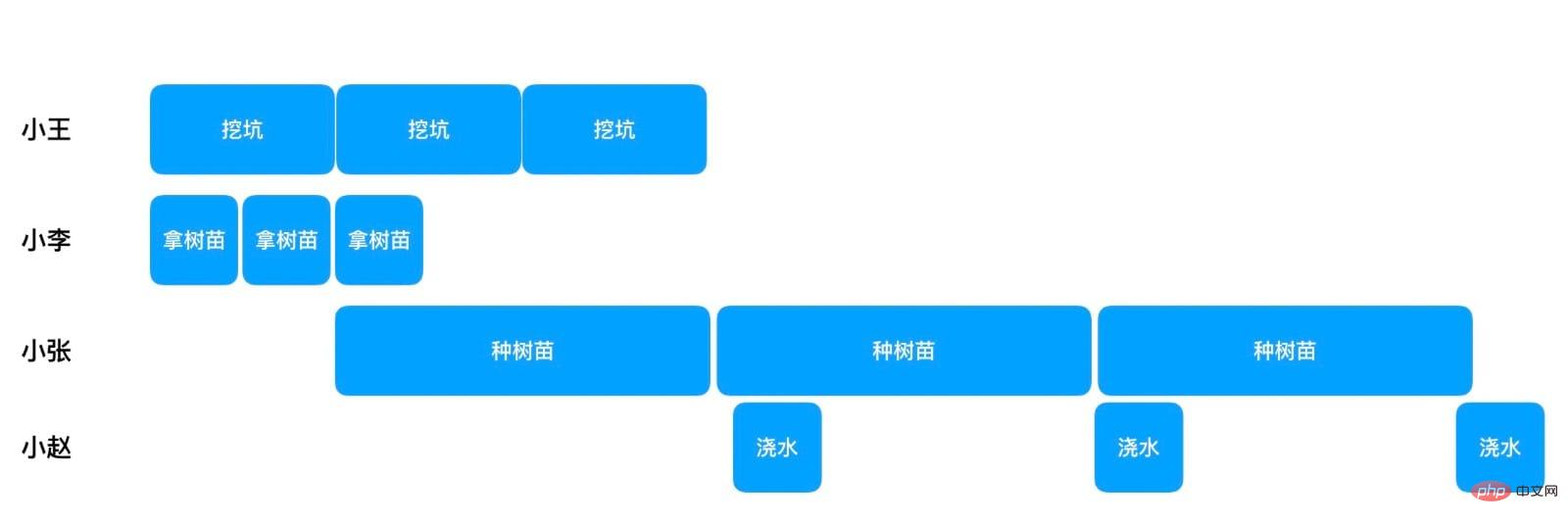
Xiao Wang이 첫 번째 구멍을 파고 난 후 Xiao Li가 이미 두 그루의 묘목을 되찾았지만 이때 Xiao는 Zhang은 첫 번째 묘목 심기를 시작할 수 있습니다. 그때부터 Xiao Zhang은 묘목을 하나씩 심을 수 있고, 묘목을 심을 때 Xiao Zhao는 동시에 물을 줄 수 있습니다. 이 과정을 따르면 묘목 100개를 심는 데 10+20x100+5=2015분이 소요됩니다. 단일 스레드의 4000분보다는 훨씬 낫지만, 100개의 스레드가 동시에 나무를 심는 속도보다는 훨씬 느리다. 하지만 동시에 100개의 스레드가 이상적인 상황일 뿐이며 이 방법은 4개의 스레드만 사용한다는 점을 잊지 마십시오.
분업을 일부 조정할 예정입니다. 모든 사람은 자신의 일을 할 뿐만 아니라, 자신의 일이 끝나면 다른 일을 할 수 있는지 살펴봅니다. 예를 들어, Xiao Wang은 구멍을 파서 묘목을 심을 수 있다는 것을 알게 된 후 묘목을 심었습니다. Xiao Li는 묘목 수집을 마친 후 구멍을 파거나 묘목을 심을 수도 있습니다. 이러한 방식으로 전반적인 효율성이 높아집니다. 이 아이디어를 바탕으로 실제로 작업을 4개의 범주로 나누고 각 범주에 100개의 작업이 있으므로 총 400개의 작업이 됩니다. 400개의 작업이 모두 완료되면 전체 작업이 완료되었음을 의미합니다. 그러면 작업 참가자는 작업의 종속성만 알고 실행 가능한 작업을 지속적으로 수신하면 됩니다. 이 효율성은 가장 높을 것입니다.
앞서 언급했듯이 100개의 스레드를 통해 작업을 동시에 실행하는 것은 불가능하므로 일반적인 상황에서는 위의 설계 아이디어와 일치하는 스레드 풀을 사용합니다. 스레드 풀을 사용한 후 네 번째 방법은 단계를 더 세밀하게 나누어 동시성 가능성을 높입니다. 따라서 속도는 두 번째 방법보다 빠릅니다. 그렇다면 세 번째 유형과 비교하면 어느 것이 더 빠를까요? 스레드 수가 무한할 수 있는 경우 이 두 방법이 달성할 수 있는 최소 시간은 35분으로 동일합니다. 그러나 스레드가 제한된 경우 네 번째 방법은 각 단계가 병렬로 실행될 수 있기 때문에 스레드를 더 효율적으로 사용합니다(나무 심기에 참여한 사람들은 작업 완료 후 다른 사람을 도울 수 있음). 스레드 스케줄링이 더 유연하므로 스레드의 스레드는 스레드 풀은 유휴 상태가 되어 계속 실행되기 어렵습니다. 그래요, 누구도 게으를 수는 없습니다. 세 번째 방법은 plantTree 방법과 병행해서만 사용할 수 있어 구멍을 파고 묘목을 얻을 수 있기 때문에 네 번째 방법만큼 유연하지 않습니다.
위에서 많이 말했는데 주로 CompletableFuture가 등장한 이유를 설명하기 위한 것입니다. 복잡한 작업을 연결된 비동기 실행 단계로 분할하여 전반적인 효율성을 향상시키는 데 사용됩니다. 섹션의 주제로 돌아가 보겠습니다. 누구도 게으를 수 없습니다. 예, 이것이 CompletableFuture의 목표입니다. 컴퓨팅 장치를 추상화하면 스레드가 각 단계에 효율적으로 동시에 참여할 수 있습니다. CompletableFuture를 통해 동기 코드를 비동기 코드로 완전히 변환할 수 있습니다. CompletableFuture를 사용하는 방법을 살펴보겠습니다.
CompletableFuture를 사용하여 Future 인터페이스를 구현하고 CompletionStage 인터페이스를 구현합니다. 우리는 이미 Future 인터페이스에 익숙하며 CompletionStage 인터페이스는 비동기 계산 단계 사이의 사양을 설정하여 단계적으로 연결될 수 있도록 합니다. CompletionStage는 비동기 계산 단계 간의 연결을 위한 38개의 공개 메서드를 정의합니다. 다음으로 일반적으로 사용되는 방법과 비교적 자주 사용되는 방법을 선택하여 사용 방법을 살펴보겠습니다.
CompletableFuture의 계산 결과를 이미 알고 있다면, CompleteFuture 정적 메서드를 사용할 수 있습니다. 계산 결과를 전달하고 CompletableFuture 객체를 선언합니다. get 메소드가 호출되면 다음 코드와 같이 들어오는 계산 결과가 차단되지 않고 즉시 반환됩니다.
public static void main(String[] args) throws Exception{
CompletableFuture<String> completableFuture = CompletableFuture.completedFuture("Hello World");
System.out.println("result is " + completableFuture.get());
}
// result is Hello World이 사용법이 의미가 없다고 생각하십니까? 이제 계산 결과를 알았으니 직접 사용하면 됩니다. 왜 CompletableFuture로 패키징해야 할까요? 비동기 컴퓨팅 유닛은 CompletableFuture를 통해 연결되어야 하기 때문에 때로는 계산 결과를 이미 알고 있더라도 이를 CompletableFuture로 패키징하여 비동기 컴퓨팅 프로세스에 통합해야 하는 경우가 있습니다.
이것이 가장 일반적으로 사용되는 방법입니다. 비동기 계산이 필요한 로직을 계산 단위로 캡슐화하고 CompletableFuture에 전달하여 실행합니다. 다음 코드와 같습니다.
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成");
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成여기에서는 CompletableFuture의 SupplyAsync 메서드를 사용하고 이를 람다 식 형식으로 공급자 인터페이스 구현에 전달합니다.
completableFuture.get()으로 얻은 계산 결과는 전달한 함수가 실행된 후의 반환 값임을 알 수 있습니다. 그런 다음 비동기식 계산이 필요한 논리가 있는 경우 이를 SupplyAsync에서 전달한 함수 본문에 넣을 수 있습니다. 이 함수는 어떻게 비동기적으로 실행되나요? 코드를 따라가다 보면, 실제로 SupplyAsync가 스레드 풀인 Executor를 통해 이 함수를 실행하는 것을 볼 수 있습니다. completableFuture는 기본적으로 ForkJoinPool을 사용합니다. 물론, SupplyAsync에 대해 다른 Excutor를 지정하고 두 번째 매개변수를 통해 이를 SupplyAsync 메서드에 전달할 수도 있습니다.
supplyAsync에는 다양한 사용 시나리오가 있습니다. 간단한 예를 들어, 기본 프로그램은 여러 마이크로서비스의 인터페이스를 호출하여 데이터를 요청해야 하며 여러 CompletableFuture를 호출할 수 있습니다. 함수 본문에는 다양한 인터페이스에 대한 호출 논리가 포함되어 있습니다. 이러한 방식으로 서로 다른 인터페이스 요청이 비동기식으로 동시에 실행될 수 있으며, 마지막으로 모든 인터페이스가 반환되면 후속 논리가 실행됩니다.
supplyAsync에서 수신한 함수에는 반환 값이 있습니다. 어떤 경우에는 단지 계산 프로세스일 뿐이므로 값을 반환할 필요가 없습니다. 이는 값을 반환하지 않는 Runnable의 run 메서드와 같습니다. 이 경우 다음 코드와 같이 runAsync 메서드를 사용할 수 있습니다.
public static void main(String[] args) throws Exception {
CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> System.out.println("挖坑完成"));
completableFuture.get();
}
// 挖坑完成runAsync는 실행 가능한 인터페이스의 기능을 받습니다. 따라서 반환 값이 없습니다. Chestnut의 로직은 "Digming done"을 인쇄합니다.
supplyAsync를 통해 비동기 계산을 완료하고 CompletableFuture를 반환하면 다음 코드와 같이 반환된 결과를 계속 처리할 수 있습니다.
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenApply(s -> s + ", 并且归还铁锹")
.thenApply(s -> s + ", 全部完成。");
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成, 并且归还铁锹, 全部完成。Call SupplyAsync 마지막으로 우리는 thenApply 메서드를 두 번 체인 호출합니다. s는 이전 단계에서 SupplyAsync가 반환한 계산 결과입니다. 계산 결과를 두 번 다시 처리했습니다. thenApply를 통해 계산 결과를 지속적으로 처리할 수 있습니다. thenApply의 로직을 비동기식으로 실행하려면 thenApplyAsync를 사용할 수 있습니다. 사용법은 동일하지만 스레드 풀을 통해 비동기적으로 실행됩니다.
这种场景你可以使用thenApply。这个方法可以让你处理上一步的返回结果,但无返回值。参照如下代码:
public static void main(String[] args) throws Exception {
CompletableFuture<Void> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenAccept(s -> System.out.println(s + ", 并且归还铁锹"));
completableFuture.get();
}这里可以看到 thenAccept 接收的函数没有返回值,只有业务逻辑。处理后返回 CompletableFuture 类型对象。
此时你可以使用 thenRun 方法,他接收 Runnable 的函数,没有输入也没有输出,仅仅是在异步计算结束后回调一段逻辑,比如记录 log 等。参照下面代码:
public static void main(String[] args) throws Exception {
CompletableFuture<Void> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenAccept(s -> System.out.println(s + ", 并且归还铁锹"))
.thenRun(() -> System.out.println("挖坑工作已经全部完成"));
completableFuture.get();
}
// 挖坑完成, 并且归还铁锹
// 挖坑工作已经全部完成可以看到在 thenAccept 之后继续调用了 thenRun,仅仅是打印了日志而已
我们可以把两个 CompletableFuture 组合起来使用,如下面的代码:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenCompose(s -> CompletableFuture.supplyAsync(() -> s + ", 并且归还铁锹"));
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成, 并且归还铁锹thenApply 和 thenCompose 的关系就像 stream中的 map 和 flatmap。从上面的例子来看,thenApply 和thenCompose 都可以实现同样的功能。但是如果你使用一个第三方的库,有一个API返回的是CompletableFuture 类型,那么你就只能使用 thenCompose方法。
如果你有两个异步操作互相没有依赖,但是第三步操作依赖前两部计算的结果,那么你可以使用 thenCombine 方法来实现,如下面代码:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenCombine(CompletableFuture.supplyAsync(() -> ", 拿树苗完成"), (x, y) -> x + y + "植树完成");
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成, 拿树苗完成植树完成挖坑和拿树苗可以同时进行,但是第三步植树则祖尧前两步完成后才能进行。
可以看到符合我们的预期。使用场景之前也提到过。我们调用多个微服务的接口时,可以使用这种方式进行组合。处理接口调用间的依赖关系。 当你需要两个 Future 的结果,但是不需要再加工后向下游传递计算结果时,可以使用 thenAcceptBoth,用法一样,只不过接收的函数没有返回值。
假如我们对微服务接口的调用不止两个,并且还有一些其它可以异步执行的逻辑。主流程需要等待这些所有的异步操作都返回时,才能继续往下执行。此时我们可以使用 CompletableFuture.allOf 方法。它接收 n 个 CompletableFuture,返回一个 CompletableFuture。对其调用 get 方法后,只有所有的 CompletableFuture 全完成时才会继续后面的逻辑。我们看下面示例代码:
public static void main(String[] args) throws Exception {
CompletableFuture<Void> future1 = CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("挖坑完成");
});
CompletableFuture<Void> future2 = CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("取树苗完成");
});
CompletableFuture<Void> future3 = CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("取肥料完成");
});
CompletableFuture.allOf(future1, future2, future3).get();
System.out.println("植树准备工作完成!");
}
// 挖坑完成
// 取肥料完成
// 取树苗完成
// 植树准备工作完成!在异步计算链中的异常处理可以采用 handle 方法,它接收两个参数,第一个参数是计算及过,第二个参数是异步计算链中抛出的异常。使用方法如下:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> {
if (1 == 1) {
throw new RuntimeException("Computation error");
}
return "挖坑完成";
}).handle((result, throwable) -> {
if (result == null) {
return "挖坑异常";
}
return result;
});
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑异常代码中会抛出一个 RuntimeException,抛出这个异常时 result 为 null,而 throwable 不为null。根据这些信息你可以在 handle 中进行处理,如果抛出的异常种类很多,你可以判断 throwable 的类型,来选择不同的处理逻辑。
위 내용은 Java 멀티스레딩은 CompletableFuture를 통해 비동기 컴퓨팅 장치를 어떻게 조립합니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



