

SpringBoot가 Caffeine을 사용하여 캐싱을 구현하는 방법

애플리케이션에 캐싱을 추가하는 이유
애플리케이션에 캐싱을 추가하는 방법을 알아보기 전에 가장 먼저 떠오르는 질문은 애플리케이션에서 캐싱을 사용해야 하는 이유입니다.
고객 데이터가 포함된 애플리케이션이 있고 사용자가 고객의 데이터(id=100)를 가져오기 위해 두 가지 요청을 한다고 가정합니다.
캐싱 없이 이런 일이 발생합니다.
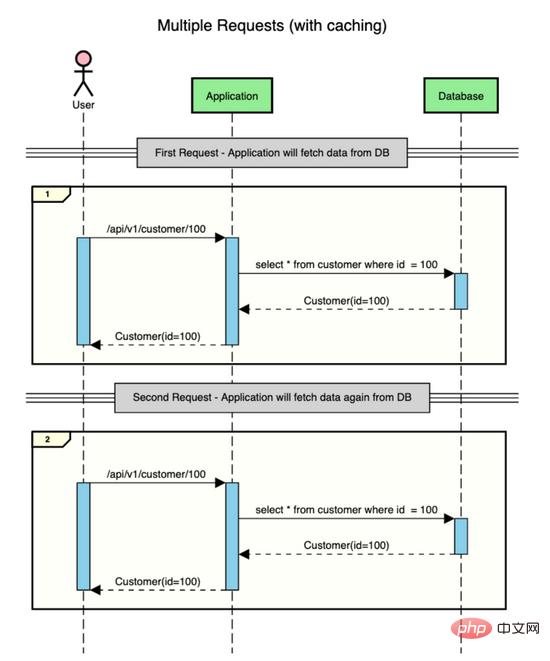
보시다시피, 모든 요청에 대해 애플리케이션은 데이터를 가져오기 위해 데이터베이스로 이동합니다. 데이터베이스에서 데이터를 가져오는 작업에는 IO가 포함되므로 비용이 많이 드는 작업입니다.
하지만 중간에 짧은 시간 동안 데이터를 임시로 저장할 수 있는 캐시 스토어가 있다면 이러한 왕복을 데이터베이스에 저장하여 IO 시간에 절약할 수 있습니다.
캐싱을 사용할 때 위의 상호 작용은 다음과 같습니다.
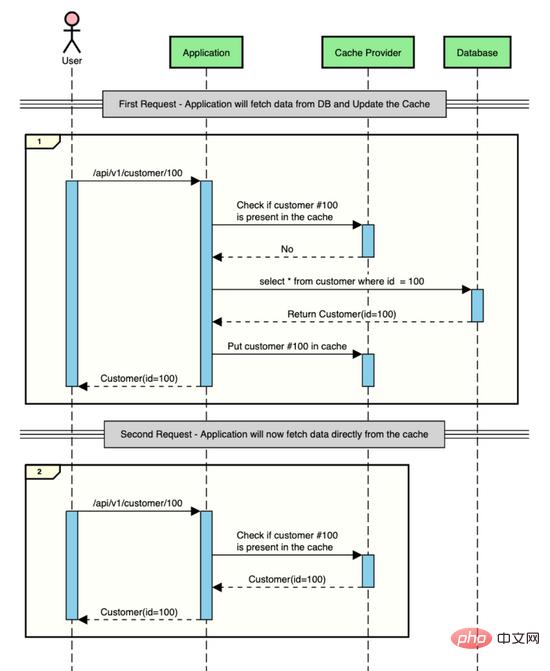
Spring Boot 애플리케이션에서 캐싱 구현
SpringBoot는 어떤 캐싱 지원을 제공합니까?
SpringBoot는 Spring 애플리케이션에 캐시를 투명하고 쉽게 추가하는 데 사용할 수 있는 캐시 추상화만 제공합니다.
실제 캐시 저장 공간을 제공하지 않습니다.
그러나 Ehcache, Hazelcast, Redis, Caffee 등과 같은 다양한 유형의 캐시 공급자와 함께 작동할 수 있습니다.
SpringBoot의 캐싱 추상화를 메소드에 추가할 수 있습니다(주석 사용).
기본적으로 메소드를 실행하기 전에 Spring 프레임워크는 메소드 데이터가 이미 캐시되어 있는지 확인합니다.
예인 경우 검색합니다. 캐시에서 데이터를 가져옵니다.
그렇지 않으면 메서드를 실행하고 데이터를 캐시합니다.
또한 캐시에서 데이터를 업데이트하거나 삭제하는 추상화도 제공합니다.
현재 블로그에서는 Java 8 기반의 고성능, 최적에 가까운 캐싱 라이브러리인 Caffeine을 사용하여 캐싱을 추가하는 방법을 알아봅니다.
spring.cache.type 속성을 설정하여 application.yaml 파일에서 사용할 캐시 공급자를 지정할 수 있습니다. application.yaml 文件中指定使用哪个缓存提供程序来设置 spring.cache.type 属性。
但是,如果没有提供属性,Spring将根据添加的库自动检测缓存提供程序。
添加生成依赖项
现在假设您已经启动并运行了基本的Spring boot应用程序,让我们添加缓存依赖项。
打开 build.gradle 文件,并添加以下依赖项以启用Spring Boot的缓存
compile('org.springframework.boot:spring-boot-starter-cache')
接下来我们将添加对Caffeine的依赖
compile group: 'com.github.ben-manes.caffeine', name: 'caffeine', version: '2.8.5'
缓存配置
现在我们需要在Spring Boot应用程序中启用缓存。
为此,我们需要创建一个配置类并提供注释 @EnableCaching 。
@Configuration
@EnableCaching
public class CacheConfig {
}现在这个类是一个空类,但是我们可以向它添加更多配置(如果需要)。
现在我们已经启用了缓存,让我们提供缓存名称和缓存属性的配置,如缓存大小、缓存过期时间等
最简单的方法是在 application.yaml 中添加配置
spring:
cache:
cache-names: customers, users, roles
caffeine:
spec: maximumSize=500, expireAfterAccess=60s上述配置执行以下操作
将可用缓存名称限制为客户、用户和角色。将最大缓存大小设置为500。
当缓存中的对象数达到此限制时,将根据缓存逐出策略从缓存中删除对象。将缓存过期时间设置为1分钟。
这意味着项目将在添加到缓存1分钟后从缓存中删除。
还有另一种配置缓存的方法,而不是在 application.yaml 文件中配置缓存。
您可以在缓存配置类中添加并提供一个 CacheManager Bean,该Bean可以完成与上面在 application.yaml 中的配置完全相同的工作
@Bean
public CacheManager cacheManager() {
Caffeine<Object, Object> caffeineCacheBuilder =
Caffeine.newBuilder()
.maximumSize(500)
.expireAfterAccess(
1, TimeUnit.MINUTES);
CaffeineCacheManager cacheManager =
new CaffeineCacheManager(
"customers", "roles", "users");
cacheManager.setCaffeine(caffeineCacheBuilder);
return cacheManager;
}在我们的代码示例中,我们将使用Java配置。
我们可以在Java中做更多的事情,比如配置 RemovalListener ,当一个项从缓存中删除时执行 RemovalListener ,或者启用缓存统计记录,等等。
缓存方法结果
在我们使用的示例Spring boot应用程序中,我们已经有了以下API GET /API/v1/customer/{id} 来检索客户记录。
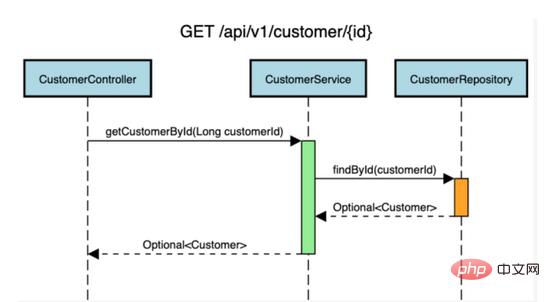
我们将向CustomerService类的 getCustomerByd(longCustomerId) 方法添加缓存。
要做到这一点,我们只需要做两件事
1. 将注释 @CacheConfig(cacheNames=“customers”) 添加到 CustomerService 类
提供此选项将确保 CustomerService
build.gradle 파일을 열고 다음 종속성을 추가하여 Spring Boot의 캐시를 활성화하세요🎜@Service
@Log4j2
@CacheConfig(cacheNames = "customers")
public class CustomerService {
@Autowired
private CustomerRepository customerRepository;
@Cacheable
public Optional<Customer> getCustomerById(Long customerId) {
log.info("Fetching customer by id: {}", customerId);
return customerRepository.findById(customerId);
}
} 代码如下:log.info("Fetching customer by id: {}", customerId);@EnableCaching 주석을 제공해야 합니다. 🎜@CachePut @cacheexecute
application.yamlapplication.yaml 🎜 @Cacheable( value = "persons", unless = "#result?.id") public Optional<Person> getPerson(Long personId)
application.yaml 파일에서 캐시를 구성하는 대신 캐시를 구성하는 또 다른 방법이 있습니다. 🎜🎜캐시 구성 클래스에 CacheManager Bean을 추가하고 제공할 수 있습니다. 이는 application.yaml의 위 구성과 정확히 동일한 작업을 수행할 수 있습니다. 🎜@Cacheable(value = "persons", condition="#fetchFromCache") public Optional<Person> getPerson(long personId, boolean fetchFromCache)
RemovalListener 구성, 항목이 캐시에서 제거될 때 RemovalListener 실행, 캐시 통계 로깅 활성화 등 Java에서 더 많은 작업을 수행할 수 있습니다. 🎜🎜캐시 메소드 결과🎜🎜우리가 사용하고 있는 샘플 Spring 부트 애플리케이션에는 고객 레코드를 검색하기 위한 다음 API GET /API/v1/customer/{id}가 이미 있습니다. 🎜🎜🎜🎜우리는 CustomerService 클래스 getCustomerByd(longCustomerId) 메서드는 캐싱을 추가합니다. 🎜🎜이렇게 하려면 두 가지만 하면 됩니다🎜🎜1. CustomerService 클래스에 @CacheConfig(cacheNames="customers") 주석을 추가합니다🎜🎜 이 옵션을 사용하면 CustomerService의 캐시 가능한 모든 메소드가 캐시 이름 "customers"를 사용하게 됩니다 🎜2. 向方法 Optional getCustomerById(Long customerId) 添加注释 @Cacheable
@Service
@Log4j2
@CacheConfig(cacheNames = "customers")
public class CustomerService {
@Autowired
private CustomerRepository customerRepository;
@Cacheable
public Optional<Customer> getCustomerById(Long customerId) {
log.info("Fetching customer by id: {}", customerId);
return customerRepository.findById(customerId);
}
}另外,在方法 getCustomerById() 中添加一个 LOGGER 语句,以便我们知道服务方法是否得到执行,或者值是否从缓存返回。
代码如下:log.info("Fetching customer by id: {}", customerId);测试缓存是否正常工作
这就是缓存工作所需的全部内容。现在是测试缓存的时候了。
启动您的应用程序,并点击客户获取url
http://localhost:8080/api/v1/customer/
在第一次API调用之后,您将在日志中看到以下行—“ Fetching customer by id ”。
但是,如果再次点击API,您将不会在日志中看到任何内容。这意味着该方法没有得到执行,并且从缓存返回客户记录。
现在等待一分钟(因为缓存过期时间设置为1分钟)。
一分钟后再次点击GETAPI,您将看到下面的语句再次被记录——“通过id获取客户”。
这意味着客户记录在1分钟后从缓存中删除,必须再次从数据库中获取。
为什么缓存有时会很危险
缓存更新/失效
通常我们缓存 GET 调用,以提高性能。
但我们需要非常小心的是缓存对象的更新/删除。
@CachePut @cacheexecute
如果未将 @CachePut/@cacheexecute 放入更新/删除方法中,GET调用中缓存返回的对象将与数据库中存储的对象不同。考虑下面的示例场景。
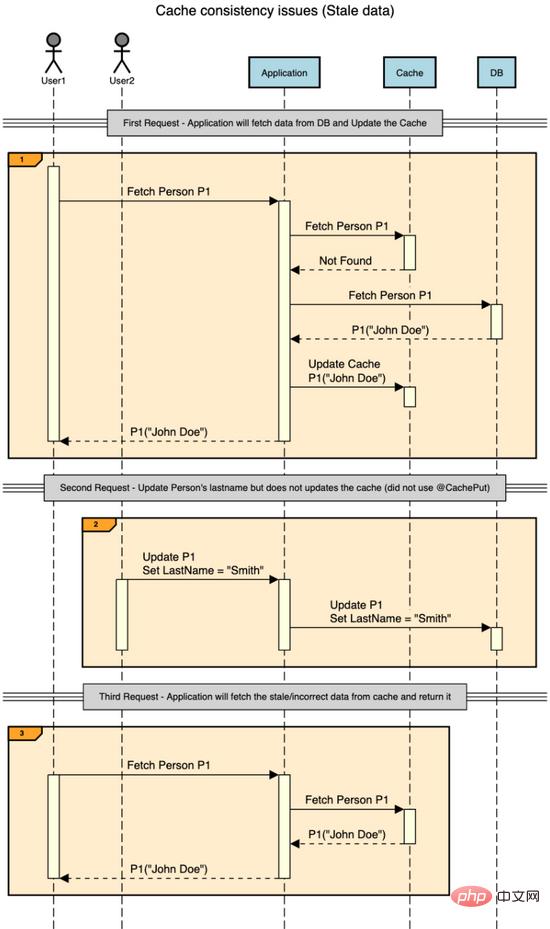
如您所见,第二个请求已将人名更新为“ John Smith ”。但由于它没有更新缓存,因此从此处开始的所有请求都将从缓存中获取过时的个人记录(“ John Doe ”),直到该项在缓存中被删除/更新。
缓存复制
大多数现代web应用程序通常有多个应用程序节点,并且在大多数情况下都有一个负载平衡器,可以将用户请求重定向到一个可用的应用程序节点。
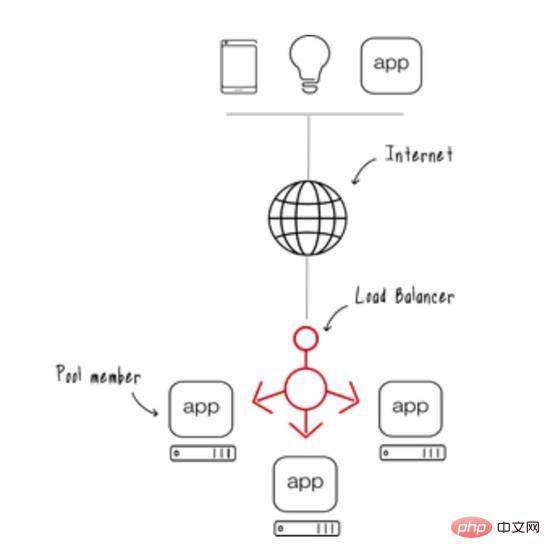
这种类型的部署为应用程序提供了可伸缩性,任何用户请求都可以由任何一个可用的应用程序节点提供服务。
在这些分布式环境(具有多个应用服务器节点)中,缓存可以通过两种方式实现
应用服务器中的嵌入式缓存(正如我们现在看到的)
远程缓存服务器
嵌入式缓存
嵌入式缓存驻留在应用程序服务器中,它随应用程序服务器启动/停止。由于每台服务器都有自己的缓存副本,因此对其缓存的任何更改/更新都不会自动反映在其他应用程序服务器的缓存中。
考虑具有嵌入式缓存的多节点应用服务器的下面场景,其中用户可以根据应用服务器为其请求服务而得到不同的结果。
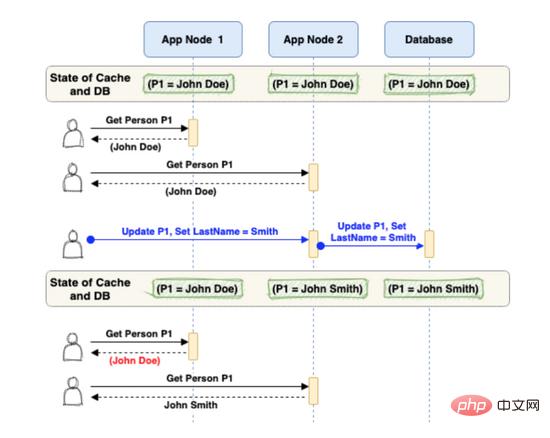
正如您在上面的示例中所看到的,更新请求更新了 Application Node2 的数据库和嵌入式缓存。
但是, Application Node1 的嵌入式缓存未更新,并且包含过时数据。因此, Application Node1 的任何请求都将继续服务于旧数据。
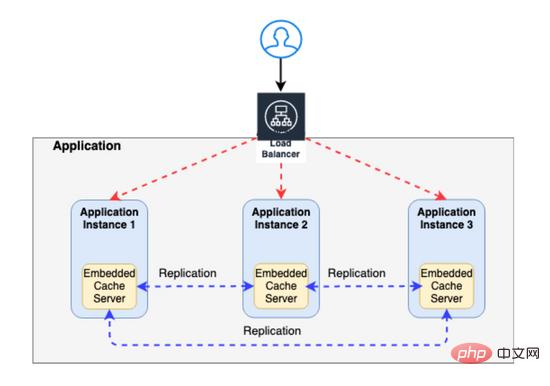
要解决这个问题,您需要实现 CACHE REPLICATION —其中任何一个缓存中的任何更新都会自动复制到其他缓存(下图中显示为蓝色虚线)
远程缓存服务器
解决上述问题的另一种方法是使用远程缓存服务器(如下所示)。

然而,这种方法的最大缺点是增加了响应时间——这是由于从远程缓存服务器获取数据时的网络延迟(与内存缓存相比)
缓存自定义
到目前为止,我们看到的缓存示例是向应用程序添加基本缓存所需的唯一代码。
然而,现实世界的场景可能不是那么简单,可能需要进行一些定制。在本节中,我们将看到几个这样的例子
缓存密钥
我们知道缓存是密钥、值对的存储。
示例1:默认缓存键–具有单参数的方法
最简单的缓存键是当方法只有一个参数,并且该参数成为缓存键时。在下面的示例中, Long customerId 是缓存键

示例2:默认缓存键–具有多个参数的方法
在下面的示例中,缓存键是所有三个参数的SimpleKey– countryId 、 regionId 、 personId 。

示例3:自定义缓存密钥
在下面的示例中,我们将此人的 emailAddress 指定为缓存的密钥

示例4:使用 KeyGenerator 的自定义缓存密钥
让我们看看下面的示例–如果要缓存当前登录用户的所有角色,该怎么办。

该方法中没有提供任何参数,该方法在内部获取当前登录用户并返回其角色。
为了实现这个需求,我们需要创建一个如下所示的自定义密钥生成器

然后我们可以在我们的方法中使用这个键生成器,如下所示。

条件缓存
在某些用例中,我们只希望在满足某些条件的情况下缓存结果
示例1(支持 java.util.Optional –仅当存在时才缓存)
仅当结果中存在 person 对象时,才缓存 person 对象。
@Cacheable( value = "persons", unless = "#result?.id") public Optional<Person> getPerson(Long personId)
示例2(如果需要,by-pass缓存)
@Cacheable(value = "persons", condition="#fetchFromCache") public Optional<Person> getPerson(long personId, boolean fetchFromCache)
仅当方法参数“ fetchFromCache ”为true时,才从缓存中获取人员。通过这种方式,方法的调用方有时可以决定绕过缓存并直接从数据库获取值。
示例3(基于对象属性的条件计算)
仅当价格低于500且产品有库存时,才缓存产品。
@Cacheable( value="products", condition="#product.price<500", unless="#result.outOfStock") public Product findProduct(Product product)
@CachePut
我们已经看到 @Cacheable 用于将项目放入缓存。
但是,如果该对象被更新,并且我们想要更新缓存,该怎么办?
我们已经在前面的一节中看到,不更新缓存post任何更新操作都可能导致从缓存返回错误的结果。
@CachePut(key = "#person.id") public Person update(Person person)
但是如果 @Cacheable 和 @CachePut 都将一个项目放入缓存,它们之间有什么区别?
主要区别在于实际的方法执行
@Cacheable @CachePut
缓存失效
缓存失效与将对象放入缓存一样重要。
当我们想要从缓存中删除一个或多个对象时,有很多场景。让我们看一些例子。
例1
假设我们有一个用于批量导入个人记录的API。
我们希望在调用此方法之前,应该清除整个 person 缓存(因为大多数 person 记录可能会在导入时更新,而缓存可能会过时)。我们可以这样做如下
@CacheEvict( value = "persons", allEntries = true, beforeInvocation = true) public void importPersons()
例2
我们有一个Delete Person API,我们希望它在删除时也能从缓存中删除 Person 记录。
@CacheEvict( value = "persons", key = "#person.emailAddress") public void deletePerson(Person person)
默认情况下 @CacheEvict 在方法调用后运行。
위 내용은 SpringBoot가 Caffeine을 사용하여 캐싱을 구현하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7476
7476
 15
1377
52
77
11
49
19
19
32
15
1377
52
77
11
49
19
19
32

 Springboot가 Jasypt를 통합하여 구성 파일 암호화를 구현하는 방법
Jun 01, 2023 am 08:55 AM
Springboot가 Jasypt를 통합하여 구성 파일 암호화를 구현하는 방법
Jun 01, 2023 am 08:55 AM
Jasypt 소개 Jasypt는 개발자가 최소한의 노력으로 프로젝트에 기본 암호화 기능을 추가할 수 있게 해주며 암호화 작동 방식에 대한 깊은 이해가 필요하지 않은 단방향 및 양방향 암호화에 대한 높은 보안을 제공합니다. 표준 기반 암호화 기술. 비밀번호, 텍스트, 숫자, 바이너리 암호화... Spring 기반 애플리케이션, 개방형 API와의 통합에 적합하며 모든 JCE 공급자와 함께 사용할 수 있습니다... 다음 종속성을 추가합니다: com.github.ulisesbocchiojasypt-spring-boot-starter2. Jasypt의 이점은 코드가 유출되더라도 데이터 소스를 보장할 수 있어 시스템 보안을 보호합니다.
 SpringBoot가 Redisson을 통합하여 지연 대기열을 구현하는 방법
May 30, 2023 pm 02:40 PM
SpringBoot가 Redisson을 통합하여 지연 대기열을 구현하는 방법
May 30, 2023 pm 02:40 PM
사용 시나리오 1. 주문이 성공적으로 이루어졌으나 30분 이내에 결제가 이루어지지 않았습니다. 결제 시간이 초과되어 주문이 자동으로 취소되었습니다. 2. 주문이 서명되었으며 서명 후 7일 동안 평가가 수행되지 않았습니다. 주문 시간이 초과되어 평가되지 않으면 시스템은 기본적으로 긍정적 평가로 설정됩니다. 3. 판매자가 5분 동안 주문을 받지 않으면 주문이 취소됩니다. 문자 메시지 알림이 전송됩니다... 지연이 길고 실시간 성능이 낮은 시나리오의 경우 작업 예약을 사용하여 정기적인 폴링 처리를 수행할 수 있습니다. 예: xxl-job 오늘은 다음을 선택하겠습니다.
 Redis를 사용하여 SpringBoot에서 분산 잠금을 구현하는 방법
Jun 03, 2023 am 08:16 AM
Redis를 사용하여 SpringBoot에서 분산 잠금을 구현하는 방법
Jun 03, 2023 am 08:16 AM
1. Redis는 분산 잠금 원칙과 분산 잠금이 필요한 이유를 구현합니다. 분산 잠금에 대해 이야기하기 전에 분산 잠금이 필요한 이유를 설명해야 합니다. 분산 잠금의 반대는 독립형 잠금입니다. 다중 스레드 프로그램을 작성할 때 공유 변수를 동시에 작동하여 발생하는 데이터 문제를 방지하기 위해 일반적으로 잠금을 사용하여 공유 변수를 상호 제외합니다. 공유 변수의 사용 범위는 동일한 프로세스에 있습니다. 동시에 공유 리소스를 운영해야 하는 여러 프로세스가 있는 경우 어떻게 상호 배타적일 수 있습니까? 오늘날의 비즈니스 애플리케이션은 일반적으로 마이크로서비스 아키텍처입니다. 이는 하나의 애플리케이션이 여러 프로세스를 배포한다는 의미이기도 합니다. 여러 프로세스가 MySQL에서 동일한 레코드 행을 수정해야 하는 경우 잘못된 작업으로 인해 발생하는 더티 데이터를 방지하려면 배포가 필요합니다. 현재 소개할 스타일은 잠겨 있습니다. 포인트를 얻고 싶다
 springboot가 파일을 jar 패키지로 읽은 후 파일에 액세스할 수 없는 문제를 해결하는 방법
Jun 03, 2023 pm 04:38 PM
springboot가 파일을 jar 패키지로 읽은 후 파일에 액세스할 수 없는 문제를 해결하는 방법
Jun 03, 2023 pm 04:38 PM
Springboot가 파일을 읽지만 jar 패키지로 패키징한 후 최신 개발에 액세스할 수 없습니다. springboot가 파일을 jar 패키지로 패키징한 후 파일을 읽을 수 없는 상황이 발생합니다. 그 이유는 패키징 후 파일의 가상 경로 때문입니다. 유효하지 않으며 읽기를 통해서만 액세스할 수 있습니다. 파일은 리소스 publicvoidtest(){Listnames=newArrayList();InputStreamReaderread=null;try{ClassPathResourceresource=newClassPathResource("name.txt");Input 아래에 있습니다.
 SpringBoot와 SpringMVC의 비교 및 차이점 분석
Dec 29, 2023 am 11:02 AM
SpringBoot와 SpringMVC의 비교 및 차이점 분석
Dec 29, 2023 am 11:02 AM
SpringBoot와 SpringMVC는 모두 Java 개발에서 일반적으로 사용되는 프레임워크이지만 둘 사이에는 몇 가지 분명한 차이점이 있습니다. 이 기사에서는 이 두 프레임워크의 기능과 용도를 살펴보고 차이점을 비교할 것입니다. 먼저 SpringBoot에 대해 알아봅시다. SpringBoot는 Spring 프레임워크를 기반으로 하는 애플리케이션의 생성 및 배포를 단순화하기 위해 Pivotal 팀에서 개발되었습니다. 독립 실행형 실행 파일을 구축하는 빠르고 가벼운 방법을 제공합니다.
 여러 테이블을 추가하기 위해 SQL 문을 사용하지 않고 Springboot+Mybatis-plus를 구현하는 방법
Jun 02, 2023 am 11:07 AM
여러 테이블을 추가하기 위해 SQL 문을 사용하지 않고 Springboot+Mybatis-plus를 구현하는 방법
Jun 02, 2023 am 11:07 AM
Springboot+Mybatis-plus가 다중 테이블 추가 작업을 수행하기 위해 SQL 문을 사용하지 않을 때 내가 직면한 문제는 테스트 환경에서 생각을 시뮬레이션하여 분해됩니다. 매개 변수가 있는 BrandDTO 개체를 생성하여 배경으로 매개 변수 전달을 시뮬레이션합니다. Mybatis-plus에서 다중 테이블 작업을 수행하는 것은 매우 어렵다는 것을 Mybatis-plus-join과 같은 도구를 사용하지 않으면 해당 Mapper.xml 파일을 구성하고 냄새나고 긴 ResultMap만 구성하면 됩니다. 해당 SQL 문을 작성합니다. 이 방법은 번거로워 보이지만 매우 유연하며 다음을 수행할 수 있습니다.
 SpringBoot가 Redis를 사용자 정의하여 캐시 직렬화를 구현하는 방법
Jun 03, 2023 am 11:32 AM
SpringBoot가 Redis를 사용자 정의하여 캐시 직렬화를 구현하는 방법
Jun 03, 2023 am 11:32 AM
1. RedisAPI 기본 직렬화 메커니즘인 RedisTemplate1.1을 사용자 정의합니다. API 기반 Redis 캐시 구현은 데이터 캐싱 작업에 RedisTemplate 템플릿을 사용합니다. 여기서 RedisTemplate 클래스를 열고 클래스의 소스 코드 정보를 봅니다. 키 선언, 값의 다양한 직렬화 방법, 초기 값은 비어 있음 @NullableprivateRedisSe
 springboot에서 application.yml의 값을 얻는 방법
Jun 03, 2023 pm 06:43 PM
springboot에서 application.yml의 값을 얻는 방법
Jun 03, 2023 pm 06:43 PM
프로젝트에서는 일부 구성 정보가 필요한 경우가 많습니다. 이 정보는 테스트 환경과 프로덕션 환경에서 구성이 다를 수 있으며 실제 비즈니스 상황에 따라 나중에 수정해야 할 수도 있습니다. 이러한 구성은 코드에 하드 코딩할 수 없습니다. 예를 들어 이 정보를 application.yml 파일에 작성할 수 있습니다. 그렇다면 코드에서 이 주소를 어떻게 얻거나 사용합니까? 2가지 방법이 있습니다. 방법 1: @Value 주석이 달린 ${key}를 통해 구성 파일(application.yml)의 키에 해당하는 값을 가져올 수 있습니다. 이 방법은 마이크로서비스가 상대적으로 적은 상황에 적합합니다. 프로젝트, 업무가 복잡할 때는 논리
