

Python과 Excel의 완벽한 조합: 일반적인 작업 요약(상세 사례 분석)


Text
과거에는 비즈니스 분석에 해당하는 영어 단어가 Business Analysis였고, 다들 사용하는 분석 도구는 Excel이었습니다. 나중에는 데이터 양이 늘어나서 Excel이 감당할 수 없게 되었습니다(최대 행 수). Excel에서 지원하는 행은 1048576행입니다. 사람들은 Python, R과 같은 분석 도구로 전환하기 시작했습니다. 이때 비즈니스 분석에 해당하는 단어는 Business Analytics입니다.
실제로 Python과 Excel의 사용 지침은 동일하며, 기계적 작업과 순수한 육체 노동을 최대한 더 편리한 작업으로 대체한다는 [우리는 반복하지 않습니다]입니다.
데이터 분석을 위해 Python을 사용하는 것은 유명한 pandas 패키지와 분리할 수 없습니다. 여러 버전의 반복 최적화를 거친 후 현재 pandas 생태계는 상당히 완성되었습니다. 공식 웹사이트에서는 Python과 다른 분석 도구 간의 비교도 제공합니다.

이 글에서는 주로 pandas를 사용합니다. 구현된 Excel의 일반적인 기능은 다음과 같습니다.
- Python과 Excel 간의 상호 작용
- vlookup 함수
- Pivot 테이블
- 그리기
앞으로도 계속해서 엑셀 기능을 업데이트하고 추가하도록 하겠습니다. 시작하기 전에 먼저 평소와 같이 pandas 패키지를 로드하세요.
import numpy as np
import pandas as pd
pd.set_option('max_columns', 10)
pd.set_option('max_rows', 20)
pd.set_option('display.float_format', lambda x: '%.2f' % x) # 禁用科学计数法Python과 Excel의 상호 작용
Pandas에서 Excel I/O와 관련하여 가장 일반적으로 사용되는 네 가지 함수는 read_csv/ read_excel/ to_csv/ to_excel이며 모두 특정 매개 변수를 가지고 있습니다. . 설정에서 원하는 읽기 및 내보내기 효과를 사용자 정의할 수 있습니다.
예를 들어, 다음과 같은 테이블의 왼쪽 상단 부분을 읽으려면
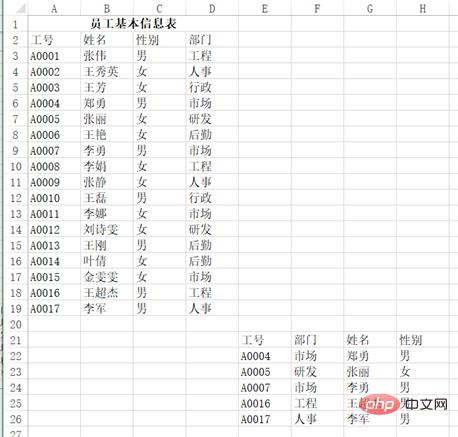
pd.read_excel("test.xlsx", header=1, nrows=17, usecols=3)을 사용할 수 있습니다. 결과가 반환됩니다.
df Out[]: 工号 姓名 性别部门 0 A0001 张伟男工程 1 A0002王秀英女人事 2 A0003 王芳女行政 3 A0004 郑勇男市场 4 A0005 张丽女研发 5 A0006 王艳女后勤 6 A0007 李勇男市场 7 A0008 李娟女工程 8 A0009 张静女人事 9 A0010 王磊男行政 10A0011 李娜女市场 11A0012刘诗雯女研发 12A0013 王刚男后勤 13A0014 叶倩女后勤 14A0015金雯雯女市场 15A0016王超杰男工程 16A0017 李军男人事
출력 함수에서도 마찬가지입니다. 사용할 열 수, 색인 여부, 제목 배치 방법을 제어할 수 있습니다.
vlookup 함수
vlookup은 Excel의 아티팩트 중 하나로 알려져 있으며 다양한 용도로 사용됩니다. 다음 예는 VLOOKUP 함수의 가장 일반적으로 사용되는 10가지 용도를 알고 있습니까?
사례 1
질문: A3: 셀 영역 B7은 문자 등급 조회 테이블로, 60점 미만은 E등급, 60~69점은 D등급, 70~79점은 C등급, 80~89점은 B등급, 90점 이상이면 A등급입니다. 1급 2급 중국어 시험 성적표에 D:G가 기재되어 있습니다. 중국어 성적을 기준으로 문자 등급을 어떻게 반환하나요?
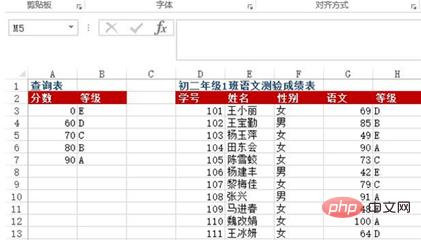
방법: H3:H13 셀 영역에 =VLOOKUP(G3, $A$3:$B$7, 2)을 입력합니다.
Python 구현:
df = pd.read_excel("test.xlsx", sheet_name=0)
def grade_to_point(x):
if x >= 90:
return 'A'
elif x >= 80:
return 'B'
elif x >= 70:
return 'C'
elif x >= 60:
return 'D'
else:
return 'E'
df['等级'] = df['语文'].apply(grade_to_point)
df
Out[]:
学号 姓名 性别 语文 等级
0 101王小丽女 69D
1 102王宝勤男 85B
2 103杨玉萍女 49E
3 104田东会女 90A
4 105陈雪蛟女 73C
5 106杨建丰男 42E
6 107黎梅佳女 79C
7 108 张兴 男 91A
8 109马进春女 48E
9 110魏改娟女100A
10111王冰研女 64D사례 2
질문: Sheet1에서 검색하는 방법 What 감가상각표의 해당 숫자에 해당하는 월별 감가상각 금액이 있습니까? (교차 테이블 쿼리).


방법: 시트1의 C2:C4 셀에 =VLOOKUP(A2, Depreciation Schedule!A$2:$G$12, 7, 0)을 입력합니다.
Python 구현: 병합을 사용하여 숫자에 따라 두 테이블을 연결하면 됩니다.
df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表')
df2 = pd.read_excel("test.xlsx", sheet_name=1) #题目里的sheet1
df2.merge(df1[['编号', '月折旧额']], how='left', on='编号')
Out[]:
编号 资产名称月折旧额
0YT001电动门 1399
1YT005桑塔纳轿车1147
2YT008打印机51Case Three
문제: Case 2와 유사하지만 이번에는 대략적인 검색을 사용해야 합니다.
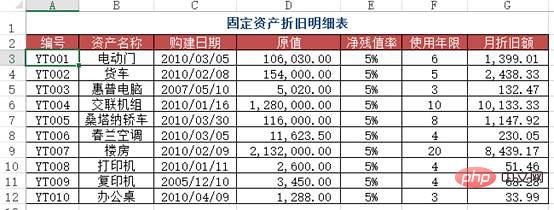
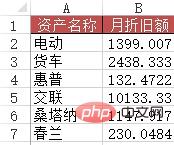
방법: B2:B7 영역에 =VLOOKUP(A2&"*", 감가상각 일정!$B$2:$G$12, 6, 0) 수식을 입력합니다.
Python 구현: 이것은 이전 구현보다 더 까다롭고 팬더 사용 기술이 필요합니다.
df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表')
df3 = pd.read_excel("test.xlsx", sheet_name=3) #含有资产名称简写的表
df3['月折旧额'] = 0
for i in range(len(df3['资产名称'])):
df3['月折旧额'][i] = df1[df1['资产名称'].map(lambda x:df3['资产名称'][i] in x)]['月折旧额']
df3
Out[]:
资产名称 月折旧额
0 电动 1399
1 货车 2438
2 惠普132
3 交联10133
4桑塔纳 1147
5 春兰230사례 4
문제: 엑셀에서 데이터 정보를 입력할 때, 업무 효율성을 높이기 위해 사용자가 데이터의 키워드를 입력하여 자동으로 레코드의 나머지 정보를 표시하기를 원합니다. 사원번호는 사원번호로 자동 표시됩니다. 자재번호를 입력하면 자재의 제품명, 단가 등이 자동으로 표시됩니다.
그림과 같이 특정 단위의 모든 직원의 기본 정보에 대한 데이터 소스 테이블이 있습니다. "2010년 3월 직원 휴가 통계 테이블" 워크시트에서 A열에 직원 번호를 입력하면 어떻게 구현되는지 알 수 있습니다. 해당 직원의 이름, 주민등록번호, 부서, 직위, 입사일 등의 정보가 자동으로 입력되나요? 또한, 공개 계정인 리눅스를 검색하고 백그라운드에서 "git books"라고 답하면 깜짝 선물 패키지를 얻을 수 있다.
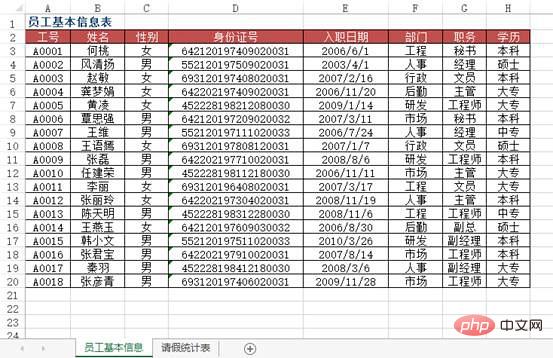
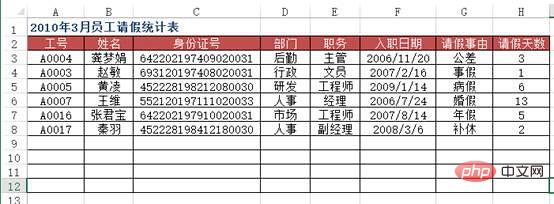
方法:使用VLOOKUP+MATCH函数,在“2010年3月员工请假统计表”工作表中选择B3:F8单元格区域,输入下列公式=IF($A3="","",VLOOKUP($A3,员工基本信息!$A:$H,MATCH(B$2,员工基本信息!$2:$2,0),0)),按下【Ctrl+Enter】组合键结束。
python实现:上面的Excel的方法用得很灵活,但是pandas的想法和操作更简单方便些。
df4 = pd.read_excel("test.xlsx", sheet_name='员工基本信息表')
df5 = pd.read_excel("test.xlsx", sheet_name='请假统计表')
df5.merge(df4[['工号', '姓名', '部门', '职务', '入职日期']], on='工号')
Out[]:
工号 姓名部门 职务 入职日期
0A0004龚梦娟后勤 主管 2006-11-20
1A0003 赵敏行政 文员 2007-02-16
2A0005 黄凌研发工程师 2009-01-14
3A0007 王维人事 经理 2006-07-24
4A0016张君宝市场工程师 2007-08-14
5A0017 秦羽人事副经理 2008-03-06案例五
问题:用VLOOKUP函数实现批量查找,VLOOKUP函数一般情况下只能查找一个,那么多项应该怎么查找呢?如下图,如何把张一的消费额全部列出?
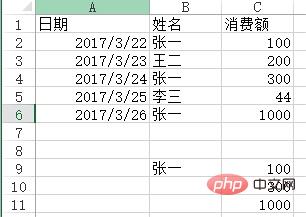
方法:在C9:C11单元格里面输入公式=VLOOKUP(B$9&ROW(A1),IF({1,0},$B$2:$B$6&COUNTIF(INDIRECT("b2:b"&ROW($2:$6)),B$9),$C$2:$C$6),2,),按SHIFT+CTRL+ENTER键结束。
python实现:vlookup函数有两个不足(或者算是特点吧),一个是被查找的值一定要在区域里的第一列,另一个是只能查找一个值,剩余的即便能匹配也不去查找了,这两点都能通过灵活应用if和indirect函数来解决,不过pandas能做得更直白一些。
df6 = pd.read_excel("test.xlsx", sheet_name='消费额')
df6[df6['姓名'] == '张一'][['姓名', '消费额']]
Out[]:
姓名 消费额
0张一 100
2张一 300
4张一1000数据透视表
数据透视表是Excel的另一个神器,本质上是一系列的表格重组整合的过程。这里用的案例来自知乎,Excel数据透视表有什么用途:(https://www.zhihu.com/question/22484899/answer/39933218 )
问题:需要汇总各个区域,每个月的销售额与成本总计,并同时算出利润。
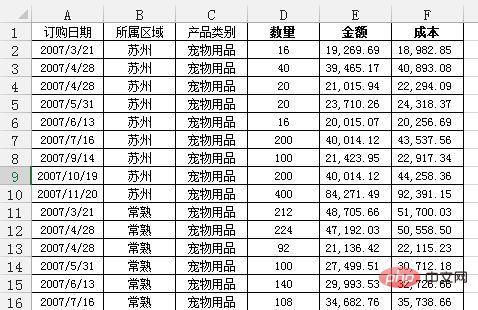
通过Excel的数据透视表的操作最终实现了下面这样的效果:
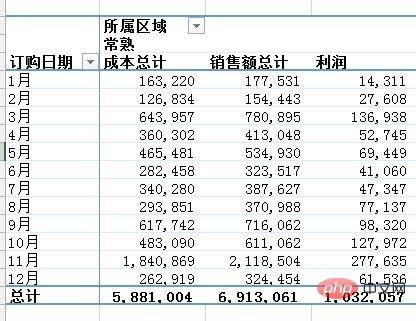
python实现:对于这样的分组的任务,首先想到的就是pandas的groupby,代码写起来也简单,思路就是把刚才Excel的点鼠标的操作反映到代码命令上:
df = pd.read_excel('test.xlsx', sheet_name='销售统计表')
df['订购月份'] = df['订购日期'].apply(lambda x:x.month)
df2 = df.groupby(['订购月份', '所属区域'])[['销售额', '成本']].agg('sum')
df2['利润'] = df2['销售额'] - df2['成本']
df2
Out[]:
销售额 成本利润
订购月份 所属区域
1南京134313.61 94967.8439345.77
常熟177531.47163220.0714311.40
无锡316418.09231822.2884595.81
昆山159183.35145403.3213780.03
苏州287253.99238812.0348441.96
2南京187129.13138530.4248598.71
常熟154442.74126834.3727608.37
无锡464012.20376134.9887877.22
昆山102324.46 86244.5216079.94
苏州105940.34 91419.5414520.80
...... ...
11 南京286329.88221687.1164642.77
常熟 2118503.54 1840868.53 277635.01
无锡633915.41536866.7797048.64
昆山351023.24342420.18 8603.06
苏州 1269351.39 1144809.83 124541.56
12 南京894522.06808959.3285562.74
常熟324454.49262918.8161535.68
无锡 1040127.19856816.72 183310.48
昆山 1096212.75951652.87 144559.87
苏州347939.30302154.2545785.05
[60 rows x 3 columns]也可以使用pandas里的pivot_table函数来实现:
df3 = pd.pivot_table(df, values=['销售额', '成本'], index=['订购月份', '所属区域'] , aggfunc='sum') df3['利润'] = df3['销售额'] - df3['成本'] df3 Out[]: 成本销售额利润 订购月份 所属区域 1南京 94967.84134313.6139345.77 常熟163220.07177531.4714311.40 无锡231822.28316418.0984595.81 昆山145403.32159183.3513780.03 苏州238812.03287253.9948441.96 2南京138530.42187129.1348598.71 常熟126834.37154442.7427608.37 无锡376134.98464012.2087877.22 昆山 86244.52102324.4616079.94 苏州 91419.54105940.3414520.80 ...... ... 11 南京221687.11286329.8864642.77 常熟 1840868.53 2118503.54 277635.01 无锡536866.77633915.4197048.64 昆山342420.18351023.24 8603.06 苏州 1144809.83 1269351.39 124541.56 12 南京808959.32894522.0685562.74 常熟262918.81324454.4961535.68 无锡856816.72 1040127.19 183310.48 昆山951652.87 1096212.75 144559.87 苏州302154.25347939.3045785.05 [60 rows x 3 columns]
pandas的pivot_table的参数index/ columns/ values和Excel里的参数是对应上的(当然,我这话说了等于没说,数据透视表里不就是行/列/值吗还能有啥。)
但是我个人还是更喜欢用groupby,因为它运算速度非常快。我在打kaggle比赛的时候,有一张表是贷款人的行为信息,大概有2700万行,用groupby算了几个聚合函数,几秒钟就完成了。
groupby的功能很全面,内置了很多aggregate函数,能够满足大部分的基本需求,如果你需要一些其他的函数,可以搭配使用apply和lambda。
不过pandas的官方文档说了,groupby之后用apply速度非常慢,aggregate内部做过优化,所以很快,apply是没有优化的,所以建议有问题先想想别的方法,实在不行的时候再用apply。
我打比赛的时候,为了生成一个新变量,用了groupby的apply,写了这么一句:ins['weight'] = ins[['SK_ID_PREV', 'DAYS_ENTRY_PAYMENT']].groupby('SK_ID_PREV').apply(lambda x: 1-abs(x)/x.sum().abs()).iloc[:,1],1000万行的数据,足足算了十多分钟,等得我心力交瘁。
绘图
因为Excel画出来的图能够交互,能够在图上进行一些简单操作,所以这里用的python的可视化库是plotly,案例就用我这个学期发展经济学课上的作业吧,当时的图都是用Excel画的,现在用python再画一遍。开始之前,首先加载plotly包。
import plotly.offline as off import plotly.graph_objs as go off.init_notebook_mode()
柱状图
当时用Excel画了很多的柱状图,其中的一幅图是:
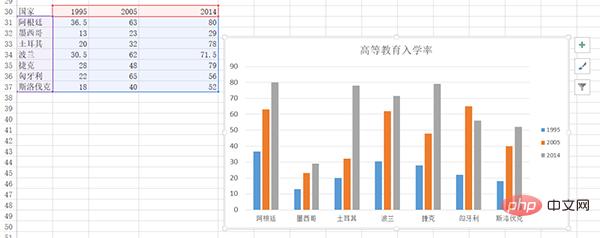
下面用plotly来画一下:
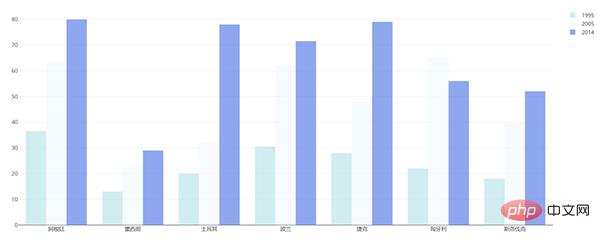
df = pd.read_excel("plot.xlsx", sheet_name='高等教育入学率')
trace1 = go.Bar(
x=df['国家'],
y=df[1995],
name='1995',
opacity=0.6,
marker=dict(
color='powderblue'
)
)
trace2 = go.Bar(
x=df['国家'],
y=df[2005],
name='2005',
opacity=0.6,
marker=dict(
color='aliceblue',
)
)
trace3 = go.Bar(
x=df['国家'],
y=df[2014],
name='2014',
opacity=0.6,
marker=dict(
color='royalblue'
)
)
layout = go.Layout(barmode='group')
data = [trace1, trace2, trace3]
fig = go.Figure(data, layout)
off.plot(fig)雷达图
用Excel画的:
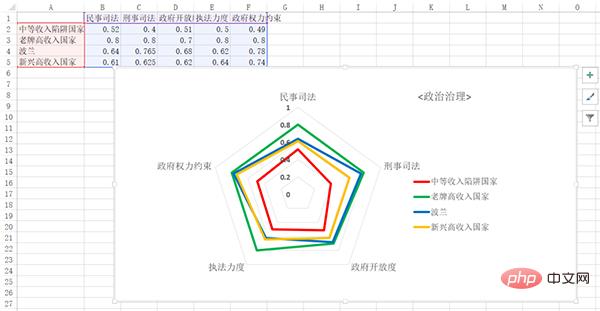
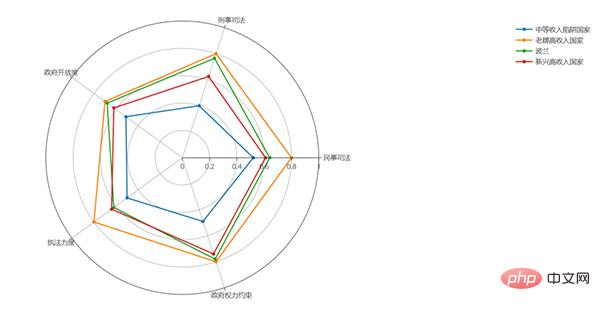
用python画的:
df = pd.read_excel('plot.xlsx', sheet_name='政治治理')
theta = df.columns.tolist()
theta.append(theta[0])
names = df.index
df[''] = df.iloc[:,0]
df = np.array(df)
trace1 = go.Scatterpolar(
r=df[0],
theta=theta,
name=names[0]
)
trace2 = go.Scatterpolar(
r=df[1],
theta=theta,
name=names[1]
)
trace3 = go.Scatterpolar(
r=df[2],
theta=theta,
name=names[2]
)
trace4 = go.Scatterpolar(
r=df[3],
theta=theta,
name=names[3]
)
data = [trace1, trace2, trace3, trace4]
layout = go.Layout(
polar=dict(
radialaxis=dict(
visible=True,
range=[0,1]
)
),
showlegend=True
)
fig = go.Figure(data, layout)
off.plot(fig)画起来比Excel要麻烦得多。
总体而言,如果画简单基本的图形,用Excel是最方便的,如果要画高级一些的或者是需要更多定制化的图形,使用python更合适。
위 내용은 Python과 Excel의 완벽한 조합: 일반적인 작업 요약(상세 사례 분석)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7552
7552
 15
1382
52
83
11
59
19
22
96
15
1382
52
83
11
59
19
22
96

 PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP와 Python은 고유 한 장점과 단점이 있으며 선택은 프로젝트 요구와 개인 선호도에 달려 있습니다. 1.PHP는 대규모 웹 애플리케이션의 빠른 개발 및 유지 보수에 적합합니다. 2. Python은 데이터 과학 및 기계 학습 분야를 지배합니다.
 Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
CentOS 시스템에서 Pytorch GPU 가속도를 활성화하려면 Cuda, Cudnn 및 GPU 버전의 Pytorch를 설치해야합니다. 다음 단계는 프로세스를 안내합니다. CUDA 및 CUDNN 설치 CUDA 버전 호환성 결정 : NVIDIA-SMI 명령을 사용하여 NVIDIA 그래픽 카드에서 지원하는 CUDA 버전을보십시오. 예를 들어, MX450 그래픽 카드는 CUDA11.1 이상을 지원할 수 있습니다. Cudatoolkit 다운로드 및 설치 : NVIDIACUDATOOLKIT의 공식 웹 사이트를 방문하여 그래픽 카드에서 지원하는 가장 높은 CUDA 버전에 따라 해당 버전을 다운로드하여 설치하십시오. CUDNN 라이브러리 설치 :
 Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python과 JavaScript는 커뮤니티, 라이브러리 및 리소스 측면에서 고유 한 장점과 단점이 있습니다. 1) Python 커뮤니티는 친절하고 초보자에게 적합하지만 프론트 엔드 개발 리소스는 JavaScript만큼 풍부하지 않습니다. 2) Python은 데이터 과학 및 기계 학습 라이브러리에서 강력하며 JavaScript는 프론트 엔드 개발 라이브러리 및 프레임 워크에서 더 좋습니다. 3) 둘 다 풍부한 학습 리소스를 가지고 있지만 Python은 공식 문서로 시작하는 데 적합하지만 JavaScript는 MDNWebDocs에서 더 좋습니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker는 Linux 커널 기능을 사용하여 효율적이고 고립 된 응용 프로그램 실행 환경을 제공합니다. 작동 원리는 다음과 같습니다. 1. 거울은 읽기 전용 템플릿으로 사용되며, 여기에는 응용 프로그램을 실행하는 데 필요한 모든 것을 포함합니다. 2. Union 파일 시스템 (Unionfs)은 여러 파일 시스템을 스택하고 차이점 만 저장하고 공간을 절약하고 속도를 높입니다. 3. 데몬은 거울과 컨테이너를 관리하고 클라이언트는 상호 작용을 위해 사용합니다. 4. 네임 스페이스 및 CGroup은 컨테이너 격리 및 자원 제한을 구현합니다. 5. 다중 네트워크 모드는 컨테이너 상호 연결을 지원합니다. 이러한 핵심 개념을 이해 함으로써만 Docker를 더 잘 활용할 수 있습니다.
 미니 오펜 센토 호환성
Apr 14, 2025 pm 05:45 PM
미니 오펜 센토 호환성
Apr 14, 2025 pm 05:45 PM
Minio Object Storage : Centos System Minio 하의 고성능 배포는 Go Language를 기반으로 개발 한 고성능 분산 객체 저장 시스템입니다. Amazons3과 호환됩니다. Java, Python, JavaScript 및 Go를 포함한 다양한 클라이언트 언어를 지원합니다. 이 기사는 CentOS 시스템에 대한 Minio의 설치 및 호환성을 간단히 소개합니다. CentOS 버전 호환성 Minio는 다음을 포함하되 이에 국한되지 않는 여러 CentOS 버전에서 확인되었습니다. CentOS7.9 : 클러스터 구성, 환경 준비, 구성 파일 설정, 디스크 파티셔닝 및 미니를 다루는 완전한 설치 안내서를 제공합니다.
 Centos에서 Pytorch의 분산 교육을 운영하는 방법
Apr 14, 2025 pm 06:36 PM
Centos에서 Pytorch의 분산 교육을 운영하는 방법
Apr 14, 2025 pm 06:36 PM
CentOS 시스템에 대한 Pytorch 분산 교육에는 다음 단계가 필요합니다. Pytorch 설치 : 전제는 Python과 PIP가 CentOS 시스템에 설치된다는 것입니다. CUDA 버전에 따라 Pytorch 공식 웹 사이트에서 적절한 설치 명령을 받으십시오. CPU 전용 교육의 경우 다음 명령을 사용할 수 있습니다. PipinStalltorchtorchvisiontorchaudio GPU 지원이 필요한 경우 CUDA 및 CUDNN의 해당 버전이 설치되어 있는지 확인하고 해당 PyTorch 버전을 설치하려면 설치하십시오. 분산 환경 구성 : 분산 교육에는 일반적으로 여러 기계 또는 단일 기계 다중 GPU가 필요합니다. 장소
 Centos에서 Pytorch 버전을 선택하는 방법
Apr 14, 2025 pm 06:51 PM
Centos에서 Pytorch 버전을 선택하는 방법
Apr 14, 2025 pm 06:51 PM
CentOS 시스템에 Pytorch를 설치할 때는 적절한 버전을 신중하게 선택하고 다음 주요 요소를 고려해야합니다. 1. 시스템 환경 호환성 : 운영 체제 : CentOS7 이상을 사용하는 것이 좋습니다. Cuda 및 Cudnn : Pytorch 버전 및 Cuda 버전은 밀접하게 관련되어 있습니다. 예를 들어, pytorch1.9.0은 cuda11.1을 필요로하고 Pytorch2.0.1은 cuda11.3을 필요로합니다. CUDNN 버전도 CUDA 버전과 일치해야합니다. Pytorch 버전을 선택하기 전에 호환 CUDA 및 CUDNN 버전이 설치되었는지 확인하십시오. 파이썬 버전 : Pytorch 공식 지점
 Centos에 nginx를 설치하는 방법
Apr 14, 2025 pm 08:06 PM
Centos에 nginx를 설치하는 방법
Apr 14, 2025 pm 08:06 PM
Centos Nginx를 설치하려면 다음 단계를 수행해야합니다. 개발 도구, PCRE-DEVEL 및 OPENSSL-DEVEL과 같은 종속성 설치. nginx 소스 코드 패키지를 다운로드하고 압축을 풀고 컴파일하고 설치하고 설치 경로를/usr/local/nginx로 지정하십시오. nginx 사용자 및 사용자 그룹을 만들고 권한을 설정하십시오. 구성 파일 nginx.conf를 수정하고 청취 포트 및 도메인 이름/IP 주소를 구성하십시오. Nginx 서비스를 시작하십시오. 종속성 문제, 포트 충돌 및 구성 파일 오류와 같은 일반적인 오류는주의를 기울여야합니다. 캐시를 켜고 작업자 프로세스 수 조정과 같은 특정 상황에 따라 성능 최적화를 조정해야합니다.
