
캐시는 최근에 사용하거나 자주 사용하는 데이터를 메모리에 저장하기 위해 애플리케이션에서 사용할 수 있는 최적화 기술입니다. 이를 통해 데이터에 접근하는 속도를 향상시킬 수 있습니다. 디스크 파일을 직접 읽는 것보다 훨씬 높습니다.
다양한 소스에서 뉴스를 가져온 다음 이를 집계하고 표시하는 Feedly와 유사한 뉴스 집계 웹사이트를 구축한다고 가정해 보겠습니다. 사용자가 뉴스를 탐색하면 백그라운드 프로그램이 기사를 다운로드하여 사용자 화면에 표시합니다. 캐싱 기술을 사용하지 않으면 사용자가 동일한 기사를 여러 번 탐색하기 위해 전환할 때 해당 기사를 여러 번 다운로드해야 하므로 비효율적이고 비우호적입니다.
더 나은 접근 방식은 각 기사를 가져온 후 데이터베이스와 같이 로컬에 콘텐츠를 저장하는 것입니다. 그러면 사용자가 다음에 동일한 기사를 열 때 백그라운드 프로그램이 대신 로컬 저장소에서 콘텐츠를 열 수 있습니다. 소스 파일을 다시 다운로드하는 기술을 캐싱이라고 합니다.
뉴스 집계 웹사이트를 예로 들겠습니다. 매번 기사 콘텐츠를 다운로드할 필요는 없으며 대신 해당 콘텐츠가 캐시 데이터에 있는지 먼저 확인합니다. 그렇지 않은 경우 서버 다운로드 기사가 표시됩니다.
다음 예제 프로그램은 Python 사전을 사용하여 기사의 URL을 키로 사용하고 해당 내용을 값으로 사용하여 캐싱을 구현합니다. get_article 함수가 두 번째 실행될 때 결과가
import requests
cache = dict()
def get_article_from_server(url):
print("Fetching article from server...")
response = requests.get(url)
return response.text
def get_article(url):
print("Getting article...")
if url not in cache:
cache[url] = get_article_from_server(url)
return cache[url]
get_article("https://www.escapelife.site/love-python.html")
get_article("https://www.escapelife.site/love-python.html")이 코드를 caching.py 파일에 저장하고 요청 라이브러리를 설치한 후 스크립트를 실행합니다.
# 安装依赖 $ pip install requests # 执行脚本 $ python python_caching.py Getting article... Fetching article from server... Getting article...
get_article()을 두 번(17행과 18행) 호출했음에도 불구하고 문자열 "서버에서 기사를 가져오는 중…"이지만 여전히 한 번만 출력합니다. 이는 기사에 처음 액세스한 후 해당 URL과 콘텐츠가 캐시 사전에 저장되고 두 번째에는 코드가 서버에서 항목을 다시 가져올 필요가 없기 때문에 발생합니다.
3 캐싱을 위해 사전을 사용하는 경우의 단점
위의 캐싱 구현에는 매우 큰 문제가 있습니다. 즉, 많은 수의 사용자가 지속적으로 기사를 탐색할 경우, 배경이 되는 사전의 내용이 무한히 늘어나게 됩니다. 프로그램은 저장해야 하는 콘텐츠를 계속해서 사전에 추가하고 서버의 메모리가 가득 차서 결국 애플리케이션이 중단됩니다.
위의 캐싱 구현에는 매우 큰 문제가 있습니다. 즉, 사전의 내용이 무한히 증가한다는 것입니다. 즉, 많은 수의 사용자가 지속적으로 기사를 탐색하면 백그라운드 프로그램이 계속해서 내용을 채울 것입니다. 사전에 저장해야 하고 서버 메모리가 가득 차서 결국 애플리케이션이 충돌하게 됩니다.
위 문제를 해결하려면 어떤 기사를 메모리에 남겨야 할지, 어떤 기사를 삭제할지 결정하는 전략이 필요합니다. 이러한 캐싱 전략은 실제로 캐시된 정보를 관리하고 어떤 항목을 폐기할지 선택하는 데 사용되는 알고리즘입니다. 새로운 물건을 위한 공간.
물론 캐시를 관리하기 위해 알고리즘을 구현할 필요는 없습니다. 캐시에서 항목을 제거하고 최대 크기 이상으로 커지는 것을 방지하기 위해 다양한 전략을 사용하기만 하면 됩니다. 다섯 가지 일반적인 캐싱 알고리즘은 다음과 같습니다.
| 캐싱 전략 | 영어 이름 | 제거 조건 | 가장 유용한 시기 |
|---|---|---|---|
| 선입선출 알고리즘(FIFO) | 선입/선출 | 가장 오래된 항목을 제거하세요 | 새로운 항목이 재사용될 가능성이 가장 높습니다 |
| 후입선출(LIFO) | 후입선출 | 최신 항목 | 오래된 항목이 재사용될 가능성이 가장 높습니다 |
| LRU(Least Recent Used) 알고리즘 | Least Recent Used | 최근에 가장 적게 사용된 항목을 제거합니다 | 가장 최근에 사용한 항목이 재사용될 가능성이 가장 높습니다 |
| 가장 최근에 사용한 알고리즘(MRU) | 가장 최근에 사용한 항목 | 가장 최근에 사용한 항목을 제거합니다. | 최근 사용하지 않은 항목은 재사용될 가능성이 높습니다. |
| 최근 적중 알고리즘(LFU) | 가장 자주 사용되지 않는 항목 | 가장 자주 액세스하지 않는 항목을 제거합니다. | 적중률이 높은 항목은 재사용 가능성이 높습니다 |
위 5가지 캐싱 알고리즘을 읽은 후 LRU와 LFU를 보면 조금 헷갈리시죠? 주된 이유는 해당하는 중국어 설명을 통해서는 그 진정한 의미를 이해하기 어렵기 때문입니다. . LRU와 LFU 알고리즘의 차이점은 다음과 같습니다.
LRU에는 액세스 시간을 기준으로 한 제거 규칙이 있습니다. 이는 데이터의 과거 액세스 기록을 기반으로 데이터를 제거합니다.
LFU 제거 규칙은 액세스 횟수를 기반으로 하며, 과거에 데이터에 여러 번 액세스한 경우 데이터를 더 자주 액세스합니다. 미래에는
예를 들어 10분은 노드가 1분마다 한 번씩 페이지 스케줄링을 수행하는 시간이며, 필요한 페이지 방향이 2 1 2 4 2 3 4이고 페이지 4가 조정될 때 페이지 오류 인터럽트가 발생합니다. ; LRU 알고리즘을 사용하는 경우 1페이지를 변경해야 하지만(1페이지가 가장 오랫동안 사용되지 않은 경우 10분), LFU 알고리즘에 따라 3페이지를 변경해야 합니다(3페이지는 10분 이내에 한 번만 사용됨). ).
LRU 전략을 사용하여 구현된 캐시는 항목에 액세스할 때마다 LRU 알고리즘이 이동합니다. 캐시 상단으로 이동하세요. 이런 방식으로 알고리즘은 목록 하단을 살펴보며 가장 오랫동안 사용되지 않은 항목을 빠르게 식별할 수 있습니다.
아래에 표시된 것처럼 LRU 정책은 사용자가 네트워크에서 요청한 첫 번째 기사에 대한 기록을 저장합니다.
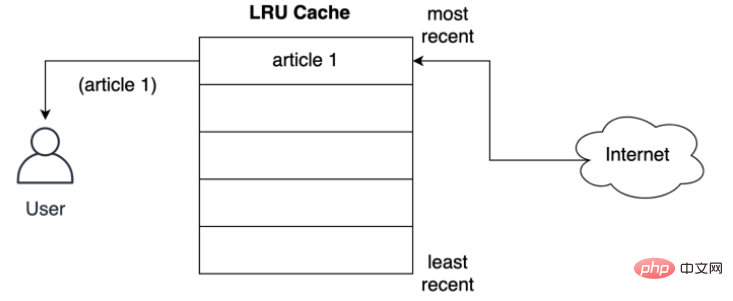
캐시는 기사를 사용자에게 제공하기 전에 가장 가까운 슬롯에 어떻게 저장합니까? 아래에 표시된 것처럼 사용자가 두 번째 기사를 요청하면 두 번째 기사가 최상위 위치에 저장됩니다. 즉, 두 번째 기사가 가장 최근 위치를 차지하고 첫 번째 기사를 목록 아래로 밀어냅니다.
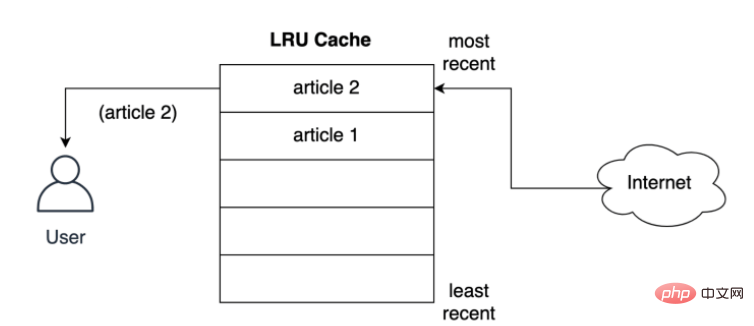
LRU 전략은 사용되는 객체가 최신일수록 나중에 사용될 가능성이 더 높다고 가정하여 가장 오랫동안 캐시에 객체를 유지하려고 시도합니다. 즉, 항목 제거가 발생하면 첫 번째 항목이 됩니다. 먼저 문서 저장 기록의 캐시를 제거했습니다.
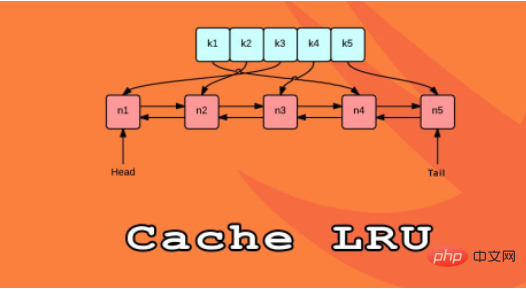
Python에서 LRU 캐시를 구현하는 한 가지 방법은 이중 연결 목록과 해시 맵을 사용하는 것입니다. 이중 연결 목록의 헤드 요소는 가장 최근에 사용된 항목을 가리킵니다. 꼬리는 가장 최근에 사용된 항목을 가리킵니다. LRU 캐시 구현 논리 구조는 다음과 같습니다.
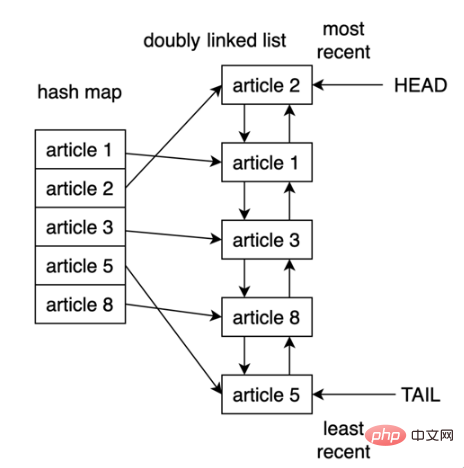
해시 맵을 사용하면 각 항목을 이중 연결 목록의 특정 위치에 매핑할 수 있으므로 캐시의 각 항목에 대한 액세스가 보장됩니다. 이 전략은 매우 빠르며, 최근에 가장 적게 사용된 항목에 액세스하고 캐시를 업데이트하는 것은 모두 O(1) 작업입니다.
Python 3.2부터 Python은 LRU 전략을 구현하기 위해 @lru_cache 데코레이터를 추가했습니다. 이제부터 이 데코레이터를 사용하여 함수를 장식하고 계산 결과를 캐시할 수 있습니다.
애플리케이션의 빠른 응답을 달성하는 방법에는 여러 가지가 있으며, 캐시를 사용하는 것이 매우 일반적인 방법입니다. 캐싱을 올바르게 사용하면 응답 속도가 빨라지고 컴퓨팅 리소스에 대한 추가 로드를 줄일 수 있습니다.
Python에서 functools 모듈은 캐싱을 위해 @lru_cache 데코레이터와 함께 제공됩니다. 이는 LRU(최근 사용 횟수) 전략을 사용하여 함수의 계산 결과를 캐시할 수 있는 간단하지만 강력한 기술입니다.
@lru_cache 데코레이터;
LRU 정책의 작동 방식을 이해하세요.
@lru_cache 데코레이터를 사용하여 성능을 향상하세요.
@lru_cache 데코레이터의 기능을 확장하고 특정 시간 후에 만료되도록 하세요.
이전에 구현한 캐싱 솔루션과 마찬가지로 Python의 @lru_cache 데코레이터 저장소도 사전을 저장소 개체로 사용하며 다음과 같이 구성된 사전의 키에 함수의 실행 결과를 캐시합니다. 이는 함수에 대한 호출(함수의 매개변수 포함)로 구성됩니다. 이는 데코레이터가 제대로 작동하려면 이러한 함수의 매개변수가 해시 가능해야 함을 의미합니다.
우리 모두는 피보나치 수열을 계산하는 방법을 알아야 합니다. 일반적인 해결책은 재귀를 사용하는 것입니다:
0, 1, 1, 2, 3, 5, 8 , 13, 21, 34. .. ;
5는 이전 두 항목의 합 ->
递归的计算简洁并且直观,但是由于存在大量重复计算,实际运行效率很低,并且会占用较多的内存。但是这里并不是需要关注的重点,只是来作为演示示例而已:
# 匿名函数 fib = lambda n: 1 if n <= 1 else fib(n-1) + fib(n-2) # 将时间复杂度降低到线性 fib = lambda n, a=1, b=1: a if n == 0 else fib(n-1, b, a+b) # 保证了匿名函数的匿名性 fib = lambda n, fib: 1 if n <= 1 else fib(n-1, fib) + fib(n-2, fib)
使用 @lru_cache 装饰器来缓存的话,可以将函数调用结果存储在内存中,以便再次请求时直接返回结果:
from functools import lru_cache
@lru_cache
def fib(n):
if n==1 or n==2:
return 1
else:
return fib(n-1) + fib(n-2)Python 的 @lru_cache 装饰器提供了一个 maxsize 属性,该属性定义了在缓存开始淘汰旧条目之前的最大条目数,默认情况下,maxsize 设置为 128。
如果将 maxsize 设置为 None 的话,则缓存将无限期增长,并且不会驱逐任何条目。
from functools import lru_cache
@lru_cache(maxsize=16)
def fib(n):
if n==1 or n==2:
return 1
else:
return fib(n-1) + fib(n-2)# 查看缓存列表 >>> print(steps_to.cache_info()) CacheInfo(hits=52, misses=30, maxsize=16, currsize=16)
就像在前面实现的缓存解决方案一样,@lru_cache 在底层使用一个字典,它将函数的结果缓存在一个键下,该键包含对函数的调用,包括提供的参数。这意味着这些参数必须是可哈希的,才能让 decorator 工作。
示例:玩楼梯:
想象一下,你想通过一次跳上一个、两个或三个楼梯来确定到达楼梯中的一个特定楼梯的所有不同方式,到第四个楼梯有多少条路?所有不同的组合如下所示:
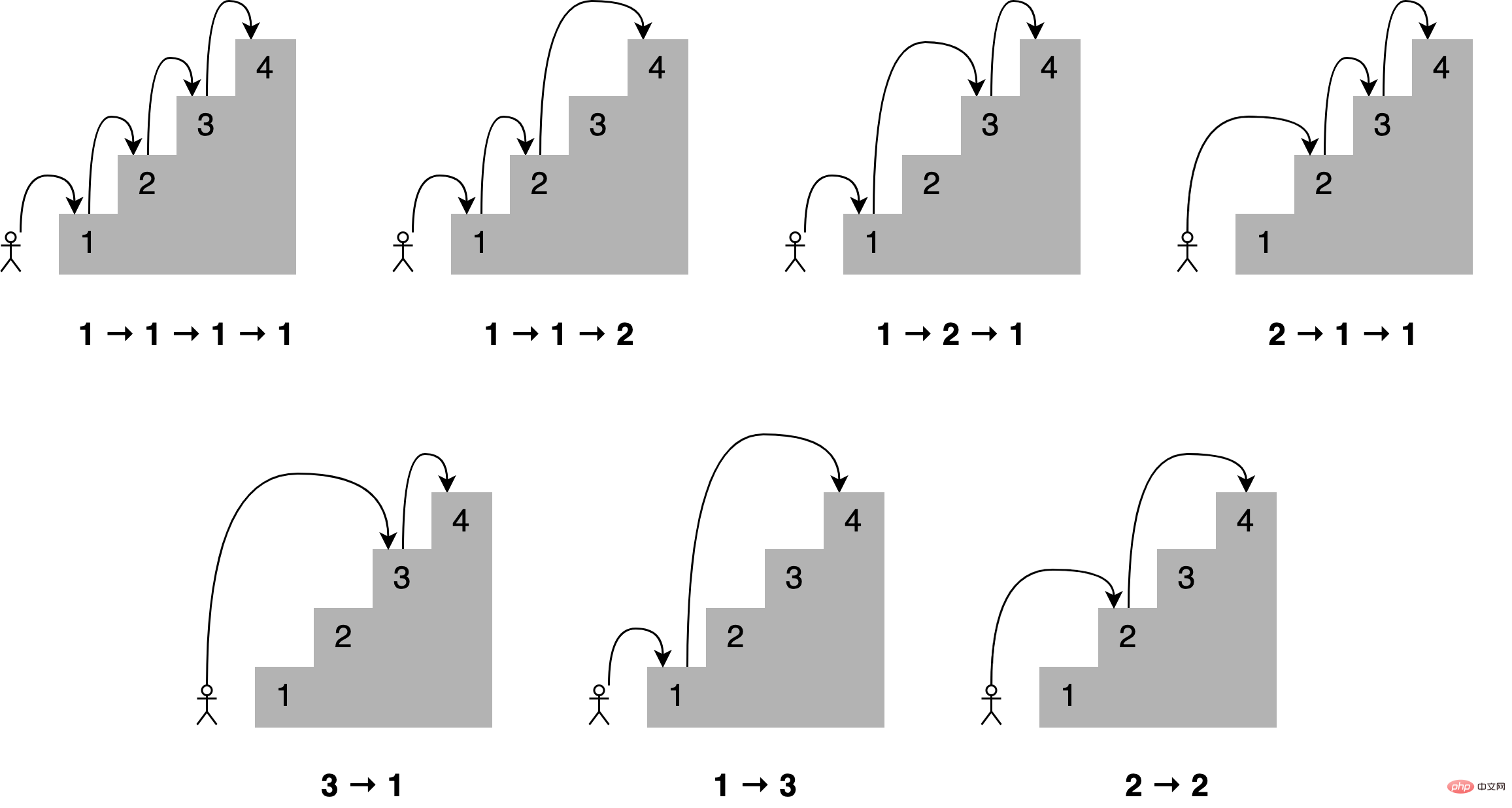
可以这样描述,为了到达当前的楼梯,你可以从下面的一个、两个或三个楼梯跳下去,将能够到达这些点的跳跃组合的数量相加,便能够获得到达当前位置的所有可能方法。
例如到达第四个楼梯的组合数量将等于你到达第三、第二和第一个楼梯的不同方式的总数。如下所示,有七种不同的方法可以到达第四层楼梯:
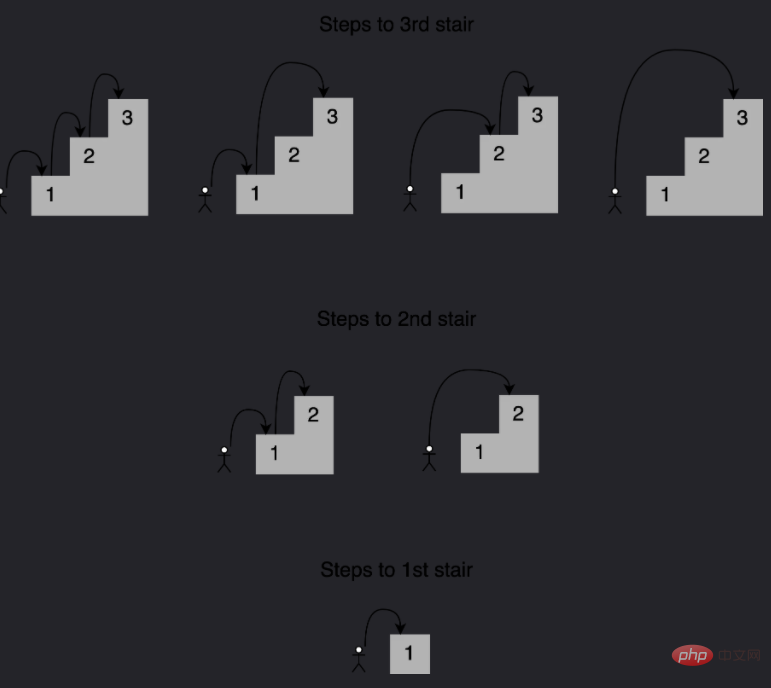
注意给定阶梯的解是如何建立在较小子问题的答案之上的,在这种情况下,为了确定到达第四个楼梯的不同路径,可以将到达第三个楼梯的四种路径、到达第二个楼梯的两种路径以及到达第一个楼梯的一种路径相加。 这种方法称为递归,下面是一个实现这个递归的函数:
def steps_to(stair):
if stair == 1:
# You can reach the first stair with only a single step
# from the floor.
return 1
elif stair == 2:
# You can reach the second stair by jumping from the
# floor with a single two-stair hop or by jumping a single
# stair a couple of times.
return 2
elif stair == 3:
# You can reach the third stair using four possible
# combinations:
# 1. Jumping all the way from the floor
# 2. Jumping two stairs, then one
# 3. Jumping one stair, then two
# 4. Jumping one stair three times
return 4
else:
# You can reach your current stair from three different places:
# 1. From three stairs down
# 2. From two stairs down
# 2. From one stair down
#
# If you add up the number of ways of getting to those
# those three positions, then you should have your solution.
return (
steps_to(stair - 3)
+ steps_to(stair - 2)
+ steps_to(stair - 1)
)
print(steps_to(4))将此代码保存到一个名为 stairs.py 的文件中,并使用以下命令运行它:
$ python stairs.py 7
太棒了,这个代码适用于 4 个楼梯,但是数一下要走多少步才能到达楼梯上更高的地方呢?将第 33 行中的楼梯数更改为 30,并重新运行脚本:
$ python stairs.py 53798080
可以看到结果超过 5300 万个组合,这可真的有点多。
时间代码:
当找到第 30 个楼梯的解决方案时,脚本花了相当多的时间来完成。要获得基线,可以度量代码运行的时间,要做到这一点,可以使用 Python 的 timeit module,在第 33 行之后添加以下代码:
setup_code = "from __main__ import steps_to"
36stmt = "steps_to(30)"
37times = repeat(setup=setup_code, stmt=stmt, repeat=3, number=10)
38print(f"Minimum execution time: {min(times)}")还需要在代码的顶部导入 timeit module:
from timeit import repeat
以下是对这些新增内容的逐行解释:
第 35 行导入 steps_to() 的名称,以便 time.com .repeat() 知道如何调用它;
第 36 行用希望到达的楼梯数(在本例中为 30)准备对函数的调用,这是将要执行和计时的语句;
第 37 行使用设置代码和语句调用 time.repeat(),这将调用该函数 10 次,返回每次执行所需的秒数;
第 38 行标识并打印返回的最短时间。 现在再次运行脚本:
$ python stairs.py 53798080 Minimum execution time: 40.014977024000004
可以看到的秒数取决于特定硬件,在我的系统上,脚本花了 40 秒,这对于 30 级楼梯来说是相当慢的。
使用记忆来改进解决方案:
这种递归实现通过将其分解为相互构建的更小的步骤来解决这个问题,如下所示是一个树,其中每个节点表示对 steps_to() 的特定调用:
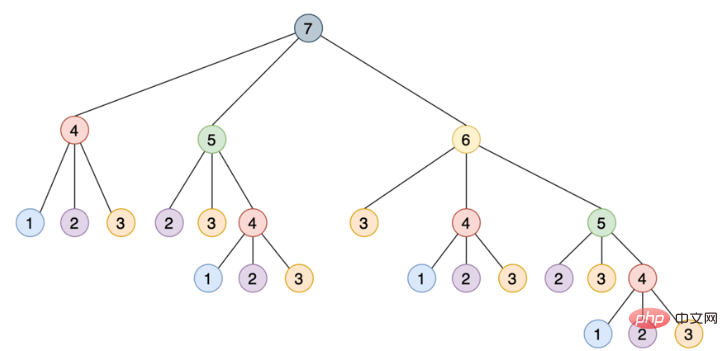
注意需要如何使用相同的参数多次调用 steps_to(),例如 steps_to(5) 计算两次,steps_to(4) 计算四次,steps_to(3) 计算七次,steps_to(2) 计算六次,多次调用同一个函数会增加不必要的计算周期,结果总是相同的。
为了解决这个问题,可以使用一种叫做记忆的技术,这种方法将函数的结果存储在内存中,然后在需要时引用它,从而确保函数不会为相同的输入运行多次,这个场景听起来像是使用 Python 的 @lru_cache 装饰器的绝佳机会。
只要做两个改变,就可以大大提高算法的运行时间:
从 functools module 导入 @lru_cache 装饰器;
使用 @lru_cache 装饰 steps_to()。
下面是两个更新后的脚本顶部的样子:
from functools import lru_cache from timeit import repeat @lru_cache def steps_to(stair): if stair == 1:
运行更新后的脚本产生如下结果:
$ python stairs.py 53798080 Minimum execution time: 7.999999999987184e-07
缓存函数的结果会将运行时从 40 秒降低到 0.0008 毫秒,这是一个了不起的进步。@lru_cache 装饰器存储了每个不同输入的 steps_to() 的结果,每次代码调用带有相同参数的函数时,它都直接从内存中返回正确的结果,而不是重新计算一遍答案,这解释了使用 @lru_cache 时性能的巨大提升。
有了@lru_cache 装饰器,就可以将每个调用和应答存储在内存中,以便以后再次请求时进行访问,但是在内存耗尽之前,可以节省多少次调用呢?
Python 的 @lru_cache 装饰器提供了一个 maxsize 属性,它定义了在缓存开始清除旧条目之前的最大条目数,缺省情况下,maxsize 设置为 128,如果将 maxsize 设置为 None,那么缓存将无限增长,并且不会驱逐任何条目。如果在内存中存储大量不同的调用,这可能会成为一个问题。
如下是 @lru_cache 使用 maxsize 属性:
from functools import lru_cache
from timeit import repeat
@lru_cache(maxsize=16)
def steps_to(stair):
if stair == 1:在本例中,将缓存限制为最多 16 个条目,当一个新调用传入时,decorator 的实现将会从现有的 16 个条目中删除最近最少使用的条目,为新条目腾出位置。
要查看添加到代码中的新内容会发生什么,可以使用 @lru_cache 装饰器提供的 cache_info() 来检查命中和未命中的次数以及当前缓存的大小。为了清晰起见,删除乘以函数运行时的代码,以下是修改后的最终脚本:
from functools import lru_cache
from timeit import repeat
@lru_cache(maxsize=16)
def steps_to(stair):
if stair == 1:
# You can reach the first stair with only a single step
# from the floor.
return 1
elif stair == 2:
# You can reach the second stair by jumping from the
# floor with a single two-stair hop or by jumping a single
# stair a couple of times.
return 2
elif stair == 3:
# You can reach the third stair using four possible
# combinations:
# 1. Jumping all the way from the floor
# 2. Jumping two stairs, then one
# 3. Jumping one stair, then two
# 4. Jumping one stair three times
return 4
else:
# You can reach your current stair from three different places:
# 1. From three stairs down
# 2. From two stairs down
# 2. From one stair down
#
# If you add up the number of ways of getting to those
# those three positions, then you should have your solution.
return (
steps_to(stair - 3)
+ steps_to(stair - 2)
+ steps_to(stair - 1)
)
print(steps_to(30))
print(steps_to.cache_info())如果再次调用脚本,可以看到如下结果:
$ python stairs.py 53798080 CacheInfo(hits=52, misses=30, maxsize=16, currsize=16)
可以使用 cache_info() 返回的信息来了解缓存是如何执行的,并对其进行微调,以找到速度和存储之间的适当平衡。下面是 cache_info() 提供的属性的详细说明:
hits=52 是 @lru_cache 直接从内存中返回的调用数,因为它们存在于缓存中;
misses =30 是被计算的不是来自内存的调用数,因为试图找到到达第 30 级楼梯的台阶数,所以每次调用都在第一次调用时错过了缓存是有道理的;
maxsize =16 是用装饰器的 maxsize 属性定义的缓存的大小;
currsize =16 是当前缓存的大小,在本例中它表明缓存已满。
如果需要从缓存中删除所有条目,那么可以使用 @lru_cache 提供的 cache_clear()。
假设想要开发一个脚本来监视 Real Python 并在任何包含单词 Python 的文章中打印字符数。真正的 Python 提供了一个 Atom feed,因此可以使用 feedparser 库来解析提要,并使用请求库来加载本文的内容。
如下是监控脚本的实现:
import feedparser
import requests
import ssl
import time
if hasattr(ssl, "_create_unverified_context"):
ssl._create_default_https_context = ssl._create_unverified_context
def get_article_from_server(url):
print("Fetching article from server...")
response = requests.get(url)
return response.text
def monitor(url):
maxlen = 45
while True:
print("\nChecking feed...")
feed = feedparser.parse(url)
for entry in feed.entries[:5]:
if "python" in entry.title.lower():
truncated_title = (
entry.title[:maxlen] + "..."
if len(entry.title) > maxlen
else entry.title
)
print(
"Match found:",
truncated_title,
len(get_article_from_server(entry.link)),
)
time.sleep(5)
monitor("https://realpython.com/atom.xml")将此脚本保存到一个名为 monitor.py 的文件中,安装 feedparser 和请求库,然后运行该脚本,它将持续运行,直到在终端窗口中按 Ctrl+C 停止它:
$ pip install feedparser requests $ python monitor.py Checking feed... Fetching article from server... The Real Python Podcast – Episode #28: Using ... 29520 Fetching article from server... Python Community Interview With David Amos 54256 Fetching article from server... Working With Linked Lists in Python 37099 Fetching article from server... Python Practice Problems: Get Ready for Your ... 164888 Fetching article from server... The Real Python Podcast – Episode #27: Prepar... 30784 Checking feed... Fetching article from server... The Real Python Podcast – Episode #28: Using ... 29520 Fetching article from server... Python Community Interview With David Amos 54256 Fetching article from server... Working With Linked Lists in Python 37099 Fetching article from server... Python Practice Problems: Get Ready for Your ... 164888 Fetching article from server... The Real Python Podcast – Episode #27: Prepar... 30784
代码解释:
第 6 行和第 7 行:当 feedparser 试图访问通过 HTTPS 提供的内容时,这是一个解决方案;
第 16 行:monitor() 将无限循环;
第 18 行:使用 feedparser,代码从真正的 Python 加载并解析提要;
第 20 行:循环遍历列表中的前 5 个条目;
第 21 到 31 行:如果单词 python 是标题的一部分,那么代码将连同文章的长度一起打印它;
第 33 行:代码在继续之前休眠了 5 秒钟;
第 35 行:这一行通过将 Real Python 提要的 URL 传递给 monitor() 来启动监视过程。
每当脚本加载一篇文章时,“Fetching article from server…”的消息就会打印到控制台,如果让脚本运行足够长的时间,那么将看到这条消息是如何反复显示的,即使在加载相同的链接时也是如此。
这是一个很好的机会来缓存文章的内容,并避免每五秒钟访问一次网络,可以使用 @lru_cache 装饰器,但是如果文章的内容被更新,会发生什么呢?第一次访问文章时,装饰器将存储文章的内容,并在以后每次返回相同的数据;如果更新了帖子,那么监视器脚本将永远无法实现它,因为它将提取存储在缓存中的旧副本。要解决这个问题,可以将缓存条目设置为过期。
from functools import lru_cache, wraps
from datetime import datetime, timedelta
def timed_lru_cache(seconds: int, maxsize: int = 128):
def wrapper_cache(func):
func = lru_cache(maxsize=maxsize)(func)
func.lifetime = timedelta(seconds=seconds)
func.expiration = datetime.utcnow() + func.lifetime
@wraps(func)
def wrapped_func(*args, **kwargs):
if datetime.utcnow() >= func.expiration:
func.cache_clear()
func.expiration = datetime.utcnow() + func.lifetime
return func(*args, **kwargs)
return wrapped_func
return wrapper_cache
@timed_lru_cache(10)
def get_article_from_server(url):
...代码解释:
第 4 行:@timed_lru_cache 装饰器将支持缓存中条目的生命周期(以秒为单位)和缓存的最大大小;
第 6 行:代码用 lru_cache 装饰器包装了装饰函数,这允许使用 lru_cache 已经提供的缓存功能;
第 7 行和第 8 行:这两行用两个表示缓存生命周期和它将过期的实际日期的属性来修饰函数;
第 12 到 14 行:在访问缓存中的条目之前,装饰器检查当前日期是否超过了过期日期,如果是这种情况,那么它将清除缓存并重新计算生存期和过期日期。
请注意,当条目过期时,此装饰器如何清除与该函数关联的整个缓存,生存期适用于整个缓存,而不适用于单个项目,此策略的更复杂实现将根据条目的单个生存期将其逐出。
在程序中,如果想要实现不同缓存策略,可以查看 cachetools 这个库,该库提供了几个集合和修饰符,涵盖了一些最流行的缓存策略。
使用新装饰器缓存文章:
现在可以将新的 @timed_lru_cache 装饰器与监视器脚本一起使用,以防止每次访问时获取文章的内容。为了简单起见,把代码放在一个脚本中,可以得到以下结果:
import feedparser
import requests
import ssl
import time
from functools import lru_cache, wraps
from datetime import datetime, timedelta
if hasattr(ssl, "_create_unverified_context"):
ssl._create_default_https_context = ssl._create_unverified_context
def timed_lru_cache(seconds: int, maxsize: int = 128):
def wrapper_cache(func):
func = lru_cache(maxsize=maxsize)(func)
func.lifetime = timedelta(seconds=seconds)
func.expiration = datetime.utcnow() + func.lifetime
@wraps(func)
def wrapped_func(*args, **kwargs):
if datetime.utcnow() >= func.expiration:
func.cache_clear()
func.expiration = datetime.utcnow() + func.lifetime
return func(*args, **kwargs)
return wrapped_func
return wrapper_cache
@timed_lru_cache(10)
def get_article_from_server(url):
print("Fetching article from server...")
response = requests.get(url)
return response.text
def monitor(url):
maxlen = 45
while True:
print("\nChecking feed...")
feed = feedparser.parse(url)
for entry in feed.entries[:5]:
if "python" in entry.title.lower():
truncated_title = (
entry.title[:maxlen] + "..."
if len(entry.title) > maxlen
else entry.title
)
print(
"Match found:",
truncated_title,
len(get_article_from_server(entry.link)),
)
time.sleep(5)
monitor("https://realpython.com/atom.xml")请注意第 30 行如何使用 @timed_lru_cache 装饰 get_article_from_server() 并指定 10 秒的有效性。在获取文章后的 10 秒内,任何试图从服务器访问同一篇文章的尝试都将从缓存中返回内容,而不会到达网络。
运行脚本并查看结果:
$ python monitor.py Checking feed... Fetching article from server... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Fetching article from server... Match found: Python Community Interview With David Amos 54254 Fetching article from server... Match found: Working With Linked Lists in Python 37100 Fetching article from server... Match found: Python Practice Problems: Get Ready for Your ... 164887 Fetching article from server... Match found: The Real Python Podcast – Episode #27: Prepar... 30783 Checking feed... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Match found: Python Community Interview With David Amos 54254 Match found: Working With Linked Lists in Python 37100 Match found: Python Practice Problems: Get Ready for Your ... 164887 Match found: The Real Python Podcast – Episode #27: Prepar... 30783 Checking feed... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Match found: Python Community Interview With David Amos 54254 Match found: Working With Linked Lists in Python 37100 Match found: Python Practice Problems: Get Ready for Your ... 164887 Match found: The Real Python Podcast – Episode #27: Prepar... 30783 Checking feed... Fetching article from server... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Fetching article from server... Match found: Python Community Interview With David Amos 54254 Fetching article from server... Match found: Working With Linked Lists in Python 37099 Fetching article from server... Match found: Python Practice Problems: Get Ready for Your ... 164888 Fetching article from server... Match found: The Real Python Podcast – Episode #27: Prepar... 30783
请注意,代码在第一次访问匹配的文章时是如何打印“Fetching article from server…”这条消息的。之后,根据网络速度和计算能力,脚本将从缓存中检索文章一两次,然后再次访问服务器。
该脚本试图每 5 秒访问这些文章,缓存每 10 秒过期一次。对于实际的应用程序来说,这些时间可能太短,因此可以通过调整这些配置来获得显著的改进。
简单理解,其实就是一个装饰器:
def lru_cache(maxsize=128, typed=False):
if isinstance(maxsize, int):
if maxsize < 0:
maxsize = 0
elif callable(maxsize) and isinstance(typed, bool):
user_function, maxsize = maxsize, 128
wrapper = _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo)
return update_wrapper(wrapper, user_function)
elif maxsize is not None:
raise TypeError('Expected first argument to be an integer, a callable, or None')
def decorating_function(user_function):
wrapper = _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo)
return update_wrapper(wrapper, user_function)
return decorating_function_CacheInfo = namedtuple("CacheInfo", ["hits", "misses", "maxsize", "currsize"])
def _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo):
sentinel = object() # unique object used to signal cache misses
make_key = _make_key # build a key from the function arguments
PREV, NEXT, KEY, RESULT = 0, 1, 2, 3 # names for the link fields
cache = {} # 存储也使用的字典
hits = misses = 0
full = False
cache_get = cache.get
cache_len = cache.__len__
lock = RLock() # 因为双向链表的更新不是线程安全的所以需要加锁
root = [] # 双向链表
root[:] = [root, root, None, None] # 初始化双向链表
if maxsize == 0:
def wrapper(*args, **kwds):
# No caching -- just a statistics update
nonlocal misses
misses += 1
result = user_function(*args, **kwds)
return result
elif maxsize is None:
def wrapper(*args, **kwds):
# Simple caching without ordering or size limit
nonlocal hits, misses
key = make_key(args, kwds, typed)
result = cache_get(key, sentinel)
if result is not sentinel:
hits += 1
return result
misses += 1
result = user_function(*args, **kwds)
cache[key] = result
return result
else:
def wrapper(*args, **kwds):
# Size limited caching that tracks accesses by recency
nonlocal root, hits, misses, full
key = make_key(args, kwds, typed)
with lock:
link = cache_get(key)
if link is not None:
# Move the link to the front of the circular queue
link_prev, link_next, _key, result = link
link_prev[NEXT] = link_next
link_next[PREV] = link_prev
last = root[PREV]
last[NEXT] = root[PREV] = link
link[PREV] = last
link[NEXT] = root
hits += 1
return result
misses += 1
result = user_function(*args, **kwds)
with lock:
if key in cache:
pass
elif full:
oldroot = root
oldroot[KEY] = key
oldroot[RESULT] = result
root = oldroot[NEXT]
oldkey = root[KEY]
oldresult = root[RESULT]
root[KEY] = root[RESULT] = None
del cache[oldkey]
cache[key] = oldroot
else:
last = root[PREV]
link = [last, root, key, result]
last[NEXT] = root[PREV] = cache[key] = link
full = (cache_len() >= maxsize)
return result
def cache_info():
"""Report cache statistics"""
with lock:
return _CacheInfo(hits, misses, maxsize, cache_len())
def cache_clear():
"""Clear the cache and cache statistics"""
nonlocal hits, misses, full
with lock:
cache.clear()
root[:] = [root, root, None, None]
hits = misses = 0
full = False
wrapper.cache_info = cache_info
wrapper.cache_clear = cache_clear
return wrapper위 내용은 Python이 캐싱을 위해 LRU 캐시 전략을 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



