

Python Celery를 사용하여 예약된 작업을 동적으로 추가하는 방법

1. 배경
실제 작업에서는 이메일 보내기, 데이터 가져오기, 예약된 스크립트 실행 등 예약해야 하는 시간이 많이 걸리는 비동기 작업이 있을 것입니다
구현의 주요 아이디어 celery를 통한 예약은 중간자 redis를 도입하고 작업 실행을 위해 작업자를 시작하며 celery-beat는 예약된 작업 데이터 저장을 수행합니다
2. 예약된 작업을 동적으로 추가하기 위한 Celery 공식 문서
celery 문서: https://docs.celeryproject. org/en/latest/userguide/ periodic-tasks.html#beat-custom-schedulers
celery 사용자 정의 스케줄링 클래스 설명:
사용자 정의 스케줄러 클래스는 명령줄에서 지정할 수 있습니다(--scheduler 매개변수)
django-celery -beat 문서: https:// pypi.org/project/django-celery-beat/
django-celery-beat 플러그인에 대한 참고 사항:
이 확장 기능을 사용하면 주기적인 작업 일정을 데이터베이스에 저장할 수 있습니다. Django 관리 인터페이스에서 관리할 수 있습니다. 정기적인 작업과 실행 빈도를 생성, 편집 및 삭제할 수 있습니다
3. Celery는 간단하고 실용적입니다.
3.1 기본 환경 구성
1 최신 버전의 Django를 설치합니다.
pip3 install django #当前我安装的版本是 3.0.6
2. 프로젝트 만들기
django-admin startproject typeidea django-admin startapp blog
3. celery 설치
pip3 install django-celery pip3 install -U Celery pip3 install "celery[librabbitmq,redis,auth,msgpack]" pip3 install django-celery-beat # 用于动态添加定时任务 pip3 install django-celery-results pip3 install redis
3.2 Celery 애플리케이션을 사용하여 테스트
1. 블로그 디렉터리를 만들고 task.py
먼저 블로그 폴더를 만듭니다. Django 프로젝트를 실행하고 blog 폴더 아래에 작업을 생성합니다.
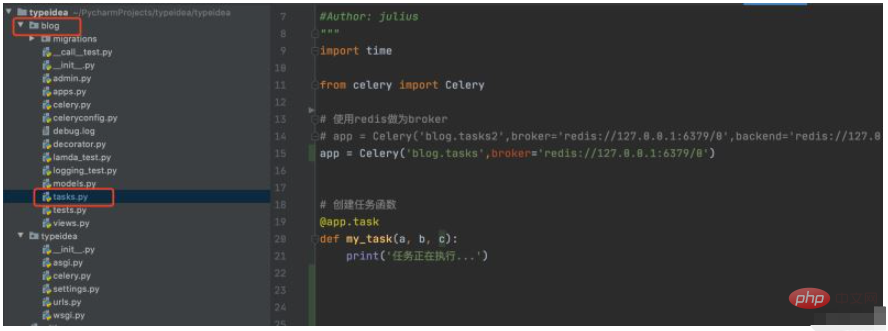
task.py 코드는 다음과 같습니다.
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
#File: tasks.py
#Time: 2022/3/30 2:26 下午
#Author: julius
"""
from celery import Celery
# 使用redis做为broker
app = Celery('blog.tasks2',broker='redis://127.0.0.1:6379/0')
# 创建任务函数
@app.task
def my_task():
print('任务正在执行...')Celery 첫 번째 매개변수는 이름을 설정하는 것입니다. 중개인 브로커를 설정합니다. 여기서는 Redis를 중개자로 사용합니다. my_task 함수는 우리가 작성한 task 함수로 app.task 데코레이터를 추가하면 브로커의 대기열에 등록됩니다.
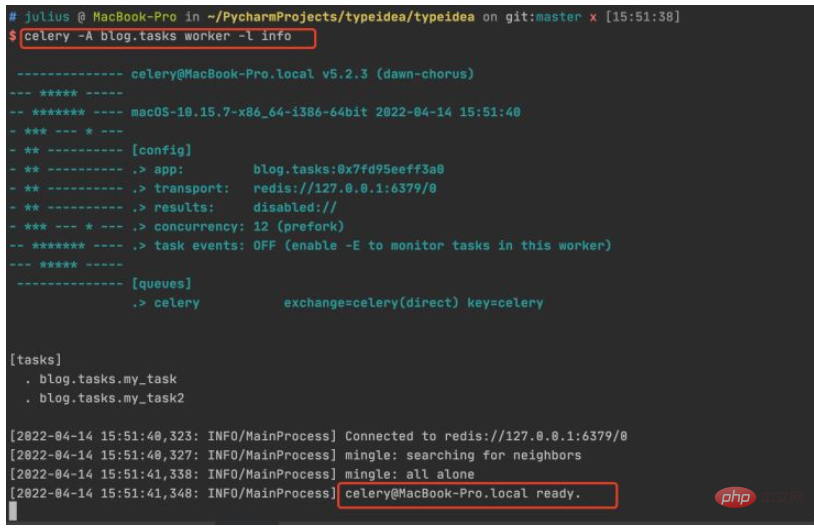
2. Redis 시작 및 작업자 생성
이제 작업자를 생성하고 대기열에서 작업을 처리하기를 기다리고 있습니다.
프로젝트의 루트 디렉터리에 들어가서 다음 명령을 실행합니다: celery -A celery_tasks.tasks 작업자 -l info
3 작업 호출
함수를 테스트하고 작업을 생성하고 추가해 보겠습니다. 작업 대기열을 생성하고 작업자 실행을 제공합니다.
파이썬 터미널에 들어가서 다음 코드를 실행하세요:
$ python manage.py shell >>> from blog.tasks import my_task >>> my_task.delay() <AsyncResult: 83484dfe-f729-417b-8e51-6c7ae32a1377>
작업 함수를 호출하면 AsyncResult 개체가 반환됩니다. 이 개체는 작업 상태를 확인하거나 작업의 반환 값을 얻는 데 사용할 수 있습니다.
4. 결과 확인
작업자 터미널에서 작업 실행 상태를 확인하면 83484dfe-f729-417b-8e51-6c7ae32a1377 작업이 수신되고 작업 실행 정보가 인쇄된 것을 확인할 수 있습니다

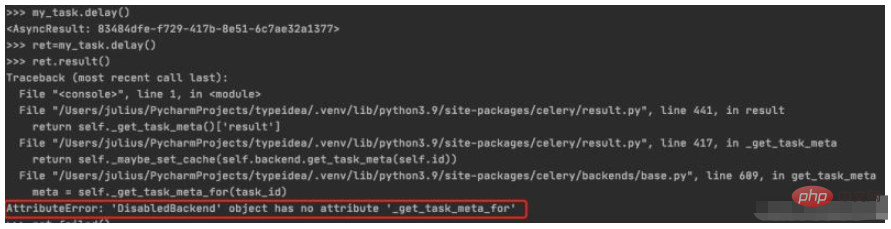
5. 작업 실행 상태 저장 및 보기
작업 실행 결과를 ret에 할당한 후 result()를 호출하면 비활성화된Backend 오류가 발생하는 경우를 볼 수 있습니다. 백엔드 저장소가 구성되지 않았습니다. 다음 섹션에서 설명하겠습니다. 작업 실행 결과를 저장하도록 백엔드를 구성하는 방법으로 이동하세요
$ python manage.py shell >>> from blog.tasks import my_task >>> ret=my_task.delay() >>> ret.result()
4. 작업 실행 결과를 저장하도록 백엔드를 구성하세요
작업 상태에 따라 Celery는 결과를 어딘가에 저장해야 합니다. SQLAlchemy, Django ORM, Memcached, Redis, RPC(RabbitMQ/AMQP) 등 여러 가지 스토리지 옵션을 사용할 수 있습니다.
1. 백엔드 매개변수 추가
이 예에서는 Redis를 결과 저장 솔루션으로 사용하고 Celery의 백엔드 매개변수를 통해 작업 결과 저장 주소를 설정합니다. 작업 모듈을 다음과 같이 수정했습니다.
from celery import Celery
# 使用redis作为broker以及backend
app = Celery('celery_tasks.tasks',
broker='redis://127.0.0.1:6379/8',
backend='redis://127.0.0.1:6379/9')
# 创建任务函数
@app.task
def my_task(a, b):
print("任务函数正在执行....")
return a + bCelery에 백엔드 매개변수를 추가하고, 결과 저장소로 redis를 지정하고, 작업 함수를 두 개의 매개변수와 반환 값으로 수정했습니다.
2. 태스크 호출/태스크 실행 결과 보기
태스크를 다시 호출해서 살펴보겠습니다.
$ python manage.py shell >>> from blog.tasks import my_task >>> res=my_task.delay(10,40) >>> res.result 50 >>> res.failed() False
다음과 같이 워커의 실행을 살펴보겠습니다.

셀러리 작업이 성공적으로 실행된 것을 확인할 수 있습니다.
하지만 이것은 시작일 뿐이며 다음 단계는 예약된 작업을 추가하는 방법을 살펴보는 것입니다.
4. Celery 디렉토리 구조 최적화
위에서는 모든 Celery 애플리케이션 생성, 구성 및 작업 작업을 하나의 파일에 직접 작성하므로 나중에 프로젝트가 점점 커지는 데 불편을 겪습니다. 이를 분석하고 일반적으로 사용되는 몇 가지 매개변수를 추가해 보겠습니다.
기본 구조는 다음과 같습니다
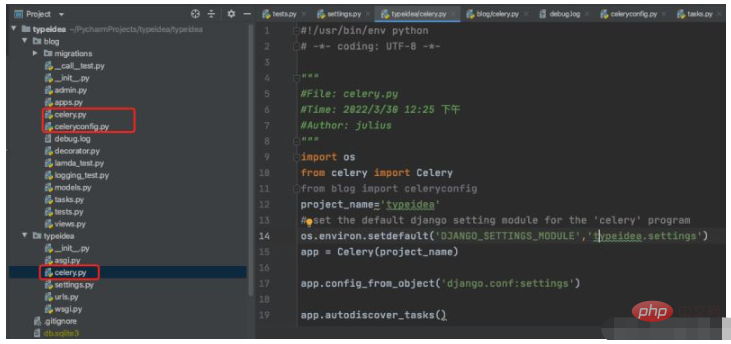
$ vim typeidea/celery.py (셀러리 애플리케이션 파일)
#!/usr/bin/env python # -*- coding: UTF-8 -*- """ #File: celery.py #Time: 2022/3/30 12:25 下午 #Author: julius """ import os from celery import Celery from blog import celeryconfig project_name='typeidea' # set the default django setting module for the 'celery' program os.environ.setdefault('DJANGO_SETTINGS_MODULE','typeidea.settings') app = Celery(project_name) app.config_from_object('django.conf:settings') app.autodiscover_tasks()
vim blog/celeryconfig.py (配置Celery的参数文件)
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
#File: celeryconfig.py
#Time: 2022/3/30 2:54 下午
#Author: julius
"""
# 设置结果存储
from typeidea import settings
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "typeidea.settings")
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/0'
# 设置代理人broker
BROKER_URL = 'redis://127.0.0.1:6379/1'
# celery 的启动工作数量设置
CELERY_WORKER_CONCURRENCY = 20
# 任务预取功能,就是每个工作的进程/线程在获取任务的时候,会尽量多拿 n 个,以保证获取的通讯成本可以压缩。
CELERYD_PREFETCH_MULTIPLIER = 20
# 非常重要,有些情况下可以防止死锁
CELERYD_FORCE_EXECV = True
# celery 的 worker 执行多少个任务后进行重启操作
CELERY_WORKER_MAX_TASKS_PER_CHILD = 100
# 禁用所有速度限制,如果网络资源有限,不建议开足马力。
CELERY_DISABLE_RATE_LIMITS = True
CELERY_ENABLE_UTC = False
CELERY_TIMEZONE = settings.TIME_ZONE
DJANGO_CELERY_BEAT_TZ_AWARE = False
CELERY_BEAT_SCHEDULER = 'django_celery_beat.schedulers:DatabaseScheduler'vim blog/tasks.py (tasks 任务文件)
import time
from blog.celery import app
# 创建任务函数
@app.task
def my_task(a, b, c):
print('任务正在执行...')
print('任务1函数休眠10s')
time.sleep(10)
return a + b + c五、开始使用django-celery-beat调度器
使用 django-celery-beat 动态添加定时任务 celery 4.x 版本在 django 框架中是使用 django-celery-beat 进行动态添加定时任务的。前面虽然已经安装了这个库,但是还要再说明一下。
1. 安装 django-celery-beat
pip3 install django-celery-beat
2.在项目的 settings 文件配置 django-celery-beat
INSTALLED_APPS = [
'blog',
'django_celery_beat',
...
]
# Django设置时区
LANGUAGE_CODE = 'zh-hans' # 使用中国语言
TIME_ZONE = 'Asia/Shanghai' # 设置Django使用中国上海时间
# 如果USE_TZ设置为True时,Django会使用系统默认设置的时区,此时的TIME_ZONE不管有没有设置都不起作用
# 如果USE_TZ 设置为False,TIME_ZONE = 'Asia/Shanghai', 则使用上海的UTC时间。
USE_TZ = False3. 创建 django-celery-beat 相关表
执行Django数据库迁移: python manage.py migrate

4. 配置Celery使用 django-celery-beat
配置 celery.py
import os
from celery import Celery
from blog import celeryconfig
# 为celery 设置环境变量
os.environ.setdefault("DJANGO_SETTINGS_MODULE","typeidea.settings")
# 创建celery app
app = Celery('blog')
# 从单独的配置模块中加载配置
app.config_from_object(celeryconfig)
# 设置app自动加载任务
app.autodiscover_tasks([
'blog',
])配置 celeryconfig.py
# 设置结果存储
from typeidea import settings
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "typeidea.settings")
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/0'
# 设置代理人broker
BROKER_URL = 'redis://127.0.0.1:6379/1'
# celery 的启动工作数量设置
CELERY_WORKER_CONCURRENCY = 20
# 任务预取功能,就是每个工作的进程/线程在获取任务的时候,会尽量多拿 n 个,以保证获取的通讯成本可以压缩。
CELERYD_PREFETCH_MULTIPLIER = 20
# 非常重要,有些情况下可以防止死锁
CELERYD_FORCE_EXECV = True
# celery 的 worker 执行多少个任务后进行重启操作
CELERY_WORKER_MAX_TASKS_PER_CHILD = 100
# 禁用所有速度限制,如果网络资源有限,不建议开足马力。
CELERY_DISABLE_RATE_LIMITS = True
CELERY_ENABLE_UTC = False
CELERY_TIMEZONE = settings.TIME_ZONE
DJANGO_CELERY_BEAT_TZ_AWARE = False
CELERY_BEAT_SCHEDULER = 'django_celery_beat.schedulers:DatabaseScheduler'编写任务 tasks.py
import time
from celery import Celery
from blog.celery import app
# 使用redis做为broker
# app = Celery('blog.tasks2',broker='redis://127.0.0.1:6379/0',backend='redis://127.0.0.1:6379/1')
# 创建任务函数
@app.task
def my_task(a, b, c):
print('任务正在执行...')
print('任务1函数休眠10s')
time.sleep(10)
return a + b + c
@app.task
def my_task2():
print("任务2函数正在执行....")
print('任务2函数休眠10s')
time.sleep(10)5. 启动定时任务work
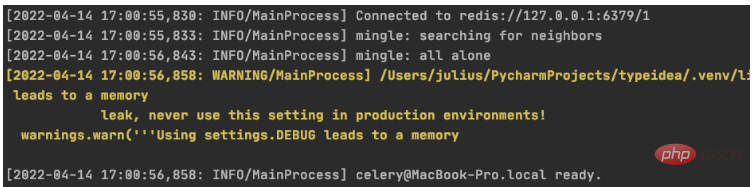
启动定时任务首先需要有一个work执行异步任务,然后再启动一个定时器触发任务。
启动任务 work
$ celery -A blog worker -l info
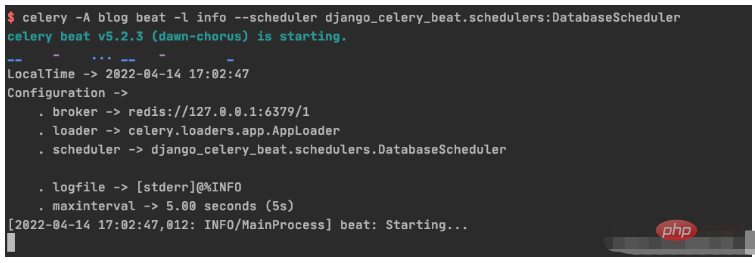
启动定时器触发 beat
celery -A blog beat -l info --scheduler django_celery_beat.schedulers:DatabaseScheduler
六、具体操作演练
6.1 创建基于间隔时间的周期性任务
1. 初始化周期间隔对象interval 对象
>>> from django_celery_beat.models import PeriodicTask, IntervalSchedule >>> schedule, created = IntervalSchedule.objects.get_or_create( ... every=10, ... period=IntervalSchedule.SECONDS, ... ) >>> IntervalSchedule.objects.all() <QuerySet [<IntervalSchedule: every 10 seconds>]>
2.创建一个无参数的周期性间隔任务
>>>PeriodicTask.objects.create(interval=schedule,name='my_task2',task='blog.tasks.my_task2',) <PeriodicTask: my_task2: every 10 seconds>
beat 调度服务日志显示如下:

worker 服务日志显示如下:

3.创建一个带参数的周期性间隔任务
>>> PeriodicTask.objects.create(interval=schedule,name='my_task',task='blog.tasks.my_task',args=json.dumps([10,20,30])) <PeriodicTask: my_task: every 10 seconds>
beat 调度服务日志结果:

worker 服务日志结果:

4.如何高并发执行任务
需要并行执行任务的时候,就需要设置多个worker来执行任务。
6.2 创建一个不带参数的周期性间隔任务
1.初始化 crontab 的调度对象
>>> import pytz >>> schedule, _ = CrontabSchedule.objects.get_or_create( ... minute='*', ... hour='*', ... day_of_week='*', ... day_of_month='*', ... timezone=pytz.timezone('Asia/Shanghai') ... )
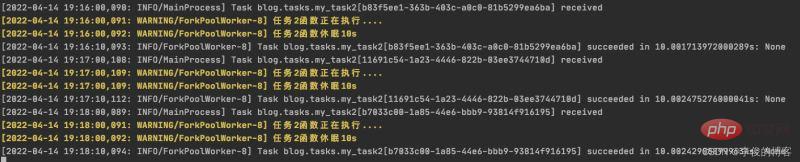
2. 创建不带参数的定时任务
PeriodicTask.objects.create(crontab=schedule,name='my_task2_crontab',task='blog.tasks.my_task2',)
beat 调度服务执行结果

worker 执行服务结果
6.3 周期性任务的查询、删除操作
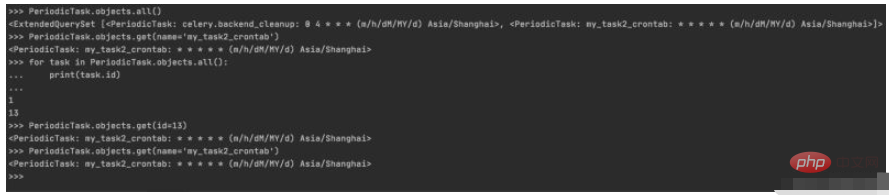
1. 周期性任务的查询
>>> PeriodicTask.objects.all() <ExtendedQuerySet [<PeriodicTask: celery.backend_cleanup: 0 4 * * * (m/h/dM/MY/d) Asia/Shanghai>, <PeriodicTask: my_task2_crontab: * * * * * (m/h/dM/MY/d) Asia/Shanghai>]> >>> PeriodicTask.objects.get(name='my_task2_crontab') <PeriodicTask: my_task2_crontab: * * * * * (m/h/dM/MY/d) Asia/Shanghai> >>> for task in PeriodicTask.objects.all(): ... print(task.id) ... 1 13 >>> PeriodicTask.objects.get(id=13) <PeriodicTask: my_task2_crontab: * * * * * (m/h/dM/MY/d) Asia/Shanghai> >>> PeriodicTask.objects.get(name='my_task2_crontab') <PeriodicTask: my_task2_crontab: * * * * * (m/h/dM/MY/d) Asia/Shanghai>
控制台实际操作记录
2.周期性任务的暂停/启动
2.1 设置my_taks2_crontab 暂停任务
>>> my_task2_crontab = PeriodicTask.objects.get(id=13) >>> my_task2_crontab.enabled True >>> my_task2_crontab.enabled=False >>> my_task2_crontab.save()
查看worker输出:

可以看到worker从19:31以后已经没有输出了,说明已经成功吧my_task2_crontab 任务暂停
2.2 设置my_task2_crontab 开启任务
把任务的 enabled 为 True 即可:
>>> my_task2_crontab.enabled False >>> my_task2_crontab.enabled=True >>> my_task2_crontab.save()
查看worker输出:
可以看到worker从19:36开始有输出,说明已把my_task2_crontab 任务重新启动
3. 周期性任务的删除
获取到指定的任务后调用delete(),再次查询指定任务会发现已经不存在了
PeriodicTask.objects.get(name='my_task2_crontab').delete()
>>> PeriodicTask.objects.get(name='my_task2_crontab')
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "/Users/julius/PycharmProjects/typeidea/.venv/lib/python3.9/site-packages/django/db/models/manager.py", line 85, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "/Users/julius/PycharmProjects/typeidea/.venv/lib/python3.9/site-packages/django/db/models/query.py", line 435, in get
raise self.model.DoesNotExist(
django_celery_beat.models.PeriodicTask.DoesNotExist: PeriodicTask matching query does not exist.위 내용은 Python Celery를 사용하여 예약된 작업을 동적으로 추가하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7469
7469
 15
1376
52
77
11
48
19
19
29
15
1376
52
77
11
48
19
19
29

 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
이 기사는 MySQL 데이터베이스의 작동을 소개합니다. 먼저 MySQLworkBench 또는 명령 줄 클라이언트와 같은 MySQL 클라이언트를 설치해야합니다. 1. MySQL-Uroot-P 명령을 사용하여 서버에 연결하고 루트 계정 암호로 로그인하십시오. 2. CreateABase를 사용하여 데이터베이스를 작성하고 데이터베이스를 선택하십시오. 3. CreateTable을 사용하여 테이블을 만들고 필드 및 데이터 유형을 정의하십시오. 4. InsertInto를 사용하여 데이터를 삽입하고 데이터를 쿼리하고 업데이트를 통해 데이터를 업데이트하고 DELETE를 통해 데이터를 삭제하십시오. 이러한 단계를 마스터하고 일반적인 문제를 처리하는 법을 배우고 데이터베이스 성능을 최적화하면 MySQL을 효율적으로 사용할 수 있습니다.
 MySQL 다운로드 파일이 손상되어 설치할 수 없습니다. 수리 솔루션
Apr 08, 2025 am 11:21 AM
MySQL 다운로드 파일이 손상되어 설치할 수 없습니다. 수리 솔루션
Apr 08, 2025 am 11:21 AM
MySQL 다운로드 파일은 손상되었습니다. 어떻게해야합니까? 아아, mySQL을 다운로드하면 파일 손상을 만날 수 있습니다. 요즘 정말 쉽지 않습니다! 이 기사는 모든 사람이 우회를 피할 수 있도록이 문제를 해결하는 방법에 대해 이야기합니다. 읽은 후 손상된 MySQL 설치 패키지를 복구 할 수있을뿐만 아니라 향후에 갇히지 않도록 다운로드 및 설치 프로세스에 대해 더 깊이 이해할 수 있습니다. 파일 다운로드가 손상된 이유에 대해 먼저 이야기합시다. 이에 대한 많은 이유가 있습니다. 네트워크 문제는 범인입니다. 네트워크의 다운로드 프로세스 및 불안정성의 중단으로 인해 파일 손상이 발생할 수 있습니다. 다운로드 소스 자체에도 문제가 있습니다. 서버 파일 자체가 고장 났으며 물론 다운로드하면 고장됩니다. 또한 일부 안티 바이러스 소프트웨어의 과도한 "열정적 인"스캔으로 인해 파일 손상이 발생할 수 있습니다. 진단 문제 : 파일이 실제로 손상되었는지 확인하십시오
 다운로드 후 MySQL을 설치할 수 없습니다
Apr 08, 2025 am 11:24 AM
다운로드 후 MySQL을 설치할 수 없습니다
Apr 08, 2025 am 11:24 AM
MySQL 설치 실패의 주된 이유는 다음과 같습니다. 1. 권한 문제, 관리자로 실행하거나 Sudo 명령을 사용해야합니다. 2. 종속성이 누락되었으며 관련 개발 패키지를 설치해야합니다. 3. 포트 충돌, 포트 3306을 차지하는 프로그램을 닫거나 구성 파일을 수정해야합니다. 4. 설치 패키지가 손상되어 무결성을 다운로드하여 확인해야합니다. 5. 환경 변수가 잘못 구성되었으며 운영 체제에 따라 환경 변수를 올바르게 구성해야합니다. 이러한 문제를 해결하고 각 단계를 신중하게 확인하여 MySQL을 성공적으로 설치하십시오.
 MySQL 설치 후 시작할 수없는 서비스에 대한 솔루션
Apr 08, 2025 am 11:18 AM
MySQL 설치 후 시작할 수없는 서비스에 대한 솔루션
Apr 08, 2025 am 11:18 AM
MySQL이 시작을 거부 했습니까? 당황하지 말고 확인합시다! 많은 친구들이 MySQL을 설치 한 후 서비스를 시작할 수 없다는 것을 알았으며 너무 불안했습니다! 걱정하지 마십시오.이 기사는 침착하게 다루고 그 뒤에있는 마스터 마인드를 찾을 수 있습니다! 그것을 읽은 후에는이 문제를 해결할뿐만 아니라 MySQL 서비스에 대한 이해와 문제 해결 문제에 대한 아이디어를 향상시키고보다 강력한 데이터베이스 관리자가 될 수 있습니다! MySQL 서비스는 시작되지 않았으며 간단한 구성 오류에서 복잡한 시스템 문제에 이르기까지 여러 가지 이유가 있습니다. 가장 일반적인 측면부터 시작하겠습니다. 기본 지식 : 서비스 시작 프로세스 MySQL 서비스 시작에 대한 간단한 설명. 간단히 말해서 운영 체제는 MySQL 관련 파일을로드 한 다음 MySQL 데몬을 시작합니다. 여기에는 구성이 포함됩니다
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 성능 최적화는 설치 구성, 인덱싱 및 쿼리 최적화, 모니터링 및 튜닝의 세 가지 측면에서 시작해야합니다. 1. 설치 후 innodb_buffer_pool_size 매개 변수와 같은 서버 구성에 따라 my.cnf 파일을 조정해야합니다. 2. 과도한 인덱스를 피하기 위해 적절한 색인을 작성하고 Execution 명령을 사용하여 실행 계획을 분석하는 것과 같은 쿼리 문을 최적화합니다. 3. MySQL의 자체 모니터링 도구 (showprocesslist, showstatus)를 사용하여 데이터베이스 건강을 모니터링하고 정기적으로 백업 및 데이터베이스를 구성하십시오. 이러한 단계를 지속적으로 최적화함으로써 MySQL 데이터베이스의 성능을 향상시킬 수 있습니다.
 MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 기본 데이터 저장 및 관리를위한 네트워크 연결없이 실행할 수 있습니다. 그러나 다른 시스템과의 상호 작용, 원격 액세스 또는 복제 및 클러스터링과 같은 고급 기능을 사용하려면 네트워크 연결이 필요합니다. 또한 보안 측정 (예 : 방화벽), 성능 최적화 (올바른 네트워크 연결 선택) 및 데이터 백업은 인터넷에 연결하는 데 중요합니다.
