

중국팀이 이력서를 뒤집었다! SEEM은 모든 폭발을 완벽하게 분할하고 원클릭으로 '순간의 우주'를 분할합니다.

메타의 “Divide Everything”의 등장으로 많은 사람들은 CV가 더 이상 존재하지 않는다고 외쳤습니다.
이 모델을 기반으로 많은 네티즌들이 Grounded SAM과 같은 추가 작업을 수행했습니다.
Stable Diffusion, Whisper, ChatGPT를 함께 사용하면 음성을 통해 개를 원숭이로 변신시킬 수 있습니다.

이제 음성뿐만 아니라 다중 모드 프롬프트를 통해 모든 곳의 모든 것을 한 번에 분할할 수 있습니다.
구체적으로 어떻게 하나요?
마우스를 클릭하시면 분할된 내용을 바로 선택하실 수 있습니다.

입 벌려보세요.

스와이프만 하면 전체 이모티콘 패키지가 나타납니다.

영상을 분할할 수도 있습니다.

SEEM에 대한 최신 연구는 University of Wisconsin-Madison, Microsoft Research 및 기타 기관의 학자들이 공동으로 완료했습니다.
SEEM을 사용하면 다양한 종류의 단서, 시각적 단서(점, 마커, 상자, 낙서 및 이미지 조각), 언어 단서(텍스트 및 오디오)를 사용하여 이미지를 쉽게 분할할 수 있습니다.

논문 주소: https://arxiv.org/pdf/2304.06718.pdf
이 논문의 제목이 흥미로운 점은 이 논문이 미국 공상 과학 소설과 관련이 있다는 것입니다. 2022년 개봉 예정인 영화 'Everywhere Everywhere All at Once'는 제목이 매우 비슷하다.

NVIDIA 과학자 Jim Fan은 최고의 논문 제목에 대한 오스카상이 "모든 곳에서 모든 것을 동시에 한 번에 분할"이라고 말했습니다.
통합된 다기능 작업 사양 인터페이스를 갖는 것이 확장을 위한 기초입니다. 대규모 모델 크기가 핵심입니다. 다중 모드 프롬프트는 미래의 방식입니다.

논문을 읽은 네티즌들은 이제 이력서가 대형 모델을 수용하기 시작했다고 말했습니다. 대학원생의 미래는 어디입니까?

오스카 최우수 논문
연구원들이 SEEM을 제안한 LLM용 프롬프트 기반 범용 인터페이스 개발에서 영감을 얻었습니다.
그림에서 볼 수 있듯이 SEEM 모델은 의미론적 분할, 인스턴스 분할, 파노라마 분할 등 힌트 없이 공개 집합에서 모든 분할 작업을 수행할 수 있습니다.
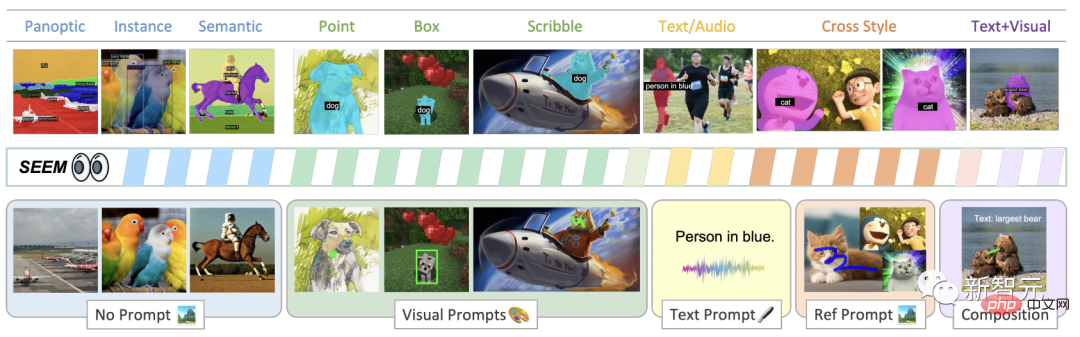
또한 시각적, 텍스트 및 인용 영역 힌트의 모든 조합을 지원하여 다양한 대화형 인용 분할이 가능합니다.
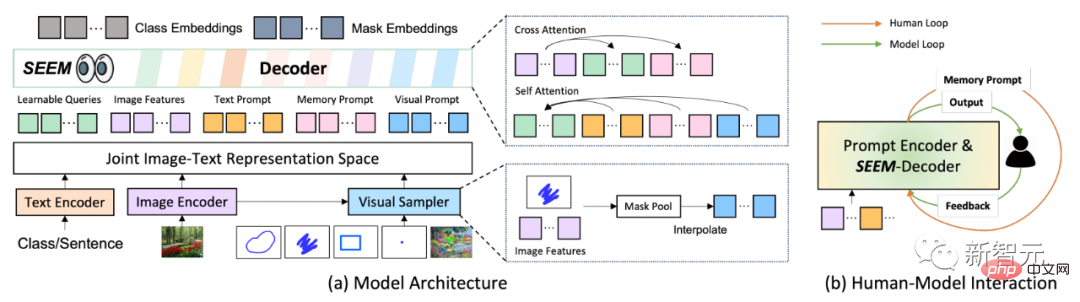
모델 아키텍처 측면에서 SEEM은 공통 인코더-디코더 아키텍처를 채택합니다. 이를 독특하게 만드는 것은 쿼리와 프롬프트 간의 복잡한 상호 작용입니다.
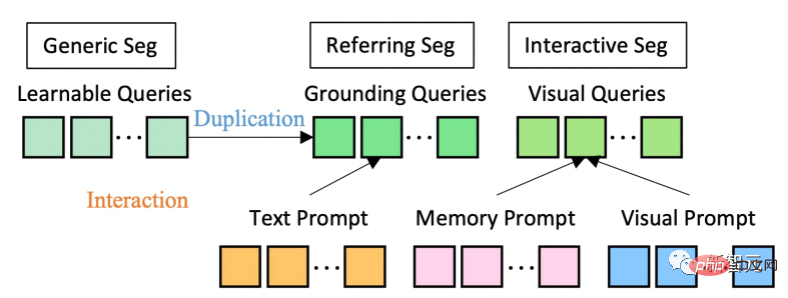
기능과 단서는 해당 인코더 또는 샘플러를 통해 공동의 시각적 의미 공간으로 인코딩됩니다.
학습 가능한 쿼리는 무작위로 초기화되고 SEEM 디코더는 마스크 및 의미론적 예측을 위한 클래스 및 마스크 임베딩을 포함하여 학습 가능한 쿼리, 이미지 특징 및 텍스트 힌트를 입력 및 출력으로 받아들입니다.
SEEM 모델에는 여러 단계의 상호 작용이 있다는 점을 언급할 가치가 있습니다. 각 라운드는 수동 주기와 모델 주기로 구성됩니다.
수동 루프에서는 이전 반복의 마스크 출력이 수동으로 수신되고 다음 디코딩 라운드에 대한 긍정적인 피드백이 시각적 신호를 통해 제공됩니다. 모델 루프에서 모델은 향후 예측을 위한 메모리 단서를 수신하고 업데이트합니다.
SEEM을 통해 Optimus Prime 트럭 사진이 주어지면 모든 대상 이미지에서 Optimus Prime을 분할할 수 있습니다.

원클릭 분할을 위해 사용자가 입력한 텍스트에서 마스크를 생성합니다.

또한 SEEM은 참조 이미지를 클릭하거나 낙서하는 것만으로 대상 이미지에서 유사한 의미를 가진 개체를 분할할 수 있습니다.

또한 SEEM은 솔루션 공간 관계를 매우 잘 이해하고 있습니다. 왼쪽 상단 행의 얼룩말이 낙서된 후 가장 왼쪽 얼룩말도 분할됩니다.

SEEM은 이미지를 비디오 마스크로 참조할 수도 있어 비디오 데이터 교육 없이도 비디오를 완벽하게 분할할 수 있습니다.


SEEM은 데이터 세트 및 설정에서 파노라마 세분화, 참조 세분화 및 대화형 세분화라는 세 가지 데이터 세트에 대해 교육을 받았습니다.
대화형 세분화
대화형 세분화에서 연구원들은 SEEM을 최첨단 대화형 세분화 모델과 비교했습니다.
SEEM은 일반 모델로서는 RITM, SimpleClick 등에 필적하는 성능을 달성했습니다. 또한 SAM과 매우 유사한 성능을 달성합니다. 또한 SAM은 훈련을 위해 50개 이상의 분할된 데이터를 사용합니다.
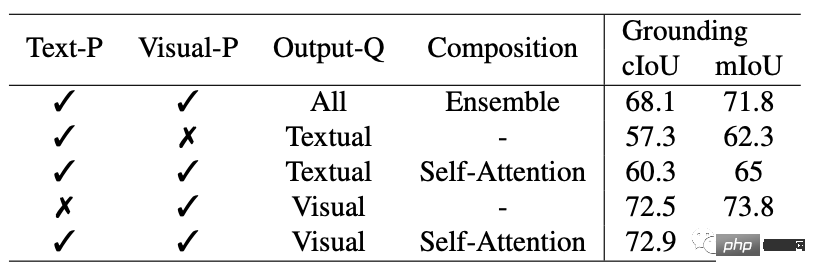
특히 기존 대화형 모델과 달리 SEEM은 고전적인 분할 작업뿐만 아니라 텍스트, 점, 기념일 로고, 경계 상자 및 이미지를 포함한 광범위한 다중 모드 입력을 최초로 지원하여 강력한 조합 기능을 제공합니다.
Universal Segmentation
모든 세분화 작업에 대해 사전 훈련된 매개변수 세트를 사용하여 연구자는 범용 세분화 데이터 세트에 대한 성능을 직접 평가할 수 있습니다.
SEEM은 더 나은 파노라마 보기, 인스턴스 및 의미론적 분할 성능을 달성합니다.
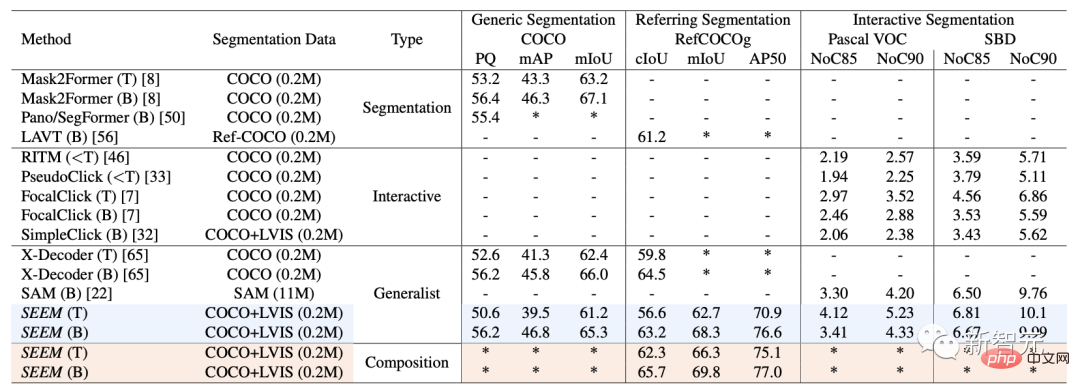
연구원은 SEEM에 대해 네 가지 예상 목표를 가지고 있습니다.
1 다용성: 포인트, 상자, 낙서, 마스크, 텍스트를 포함한 다양한 유형의 프롬프트를 처리하는 다기능 프롬프트 엔진을 도입합니다.
2. 복합성: 추론을 위한 시각적 단서와 텍스트 단서에 대한 즉각적인 쿼리를 결합하여 학습 가능한 메모리 단서를 통해; 마스크 기반 교차 주의를 통해 대화 내역 정보를 보존합니다.
4. 의미 인식: 텍스트 쿼리 및 마스크 태그를 인코딩하기 위해 텍스트 인코더를 사용하여 개방형 어휘 분할을 활성화합니다.
과 SAM
Meta가 제안한 SAM 모델의 차이점은 통합 프레임워크 프롬프트 인코더에서 점, 경계 상자 및 문장을 지정하여 한 번의 클릭으로 개체를 분할할 수 있다는 것입니다.
 SAM은 다양한 용도로 사용할 수 있습니다. 즉, 다양한 사용 사례를 포괄하는 데 충분한 제로 샘플 전송 기능이 있으며 추가 교육이 필요하지 않고 바로 사용할 수 있습니다. 수중 사진인지 세포현미경인지에 관계없이 새로운 이미지 영역에서.
SAM은 다양한 용도로 사용할 수 있습니다. 즉, 다양한 사용 사례를 포괄하는 데 충분한 제로 샘플 전송 기능이 있으며 추가 교육이 필요하지 않고 바로 사용할 수 있습니다. 수중 사진인지 세포현미경인지에 관계없이 새로운 이미지 영역에서.
 연구원들은 SEEM과 SAM을 세 가지 분할 작업(에지 감지, 오픈 세트 및 대화형 분할)에 대한 대화형 및 의미론적 기능 측면에서 비교했습니다.
연구원들은 SEEM과 SAM을 세 가지 분할 작업(에지 감지, 오픈 세트 및 대화형 분할)에 대한 대화형 및 의미론적 기능 측면에서 비교했습니다.
오픈 세트 분할에는 높은 수준의 의미 체계도 필요하며 상호 작용이 필요하지 않습니다.
SAM에 비해 SEEM은 더 넓은 범위의 상호 작용과 의미 수준을 포괄합니다.
SAM은 점 및 경계 상자와 같은 제한된 상호 작용 유형만 지원하며 의미 체계 레이블 자체를 출력하지 않기 때문에 높은 의미 체계 작업을 무시합니다.
SEEM의 경우 연구원들은 두 가지 주요 특징을 강조했습니다.
첫째, SEEM에는 모든 시각적 및 언어 단서를 공동 표현 공간으로 인코딩하는 통합 큐 인코더가 있습니다. 따라서 SEEM은 보다 일반적인 사용을 지원할 수 있으며 잠재적으로 사용자 지정 프롬프트로 확장될 수 있습니다.
둘째, SEEM은 텍스트 마스킹과 의미 인식 예측 출력에 탁월한 성능을 발휘합니다.
저자 소개
논문의 제1저자 Xueyan Zou
현재 University of Wisconsin-Madison 컴퓨터공학과 박사과정 학생이자 지도교수입니다. 이용재 교수님이십니다.
이전에 Zou는 같은 멘토의 지도 아래 캘리포니아 대학교 데이비스에서 3년을 보냈으며 Fanyi Xiao 박사와 긴밀히 협력했습니다.
그녀는 홍콩 침례 대학교에서 PC Yuen 교수와 Chu Xiaowen 교수의 지도를 받아 학사 학위를 받았습니다.

Jianwei Yang

Yang은 Jianfeng Gao 박사가 감독하는 Redmond의 Microsoft Research 딥 러닝 그룹 선임 연구원입니다.
Yang의 연구는 주로 컴퓨터 비전, 비전과 언어, 기계 학습에 중점을 두고 있습니다. 그는 구조화된 시각적 이해의 다양한 수준과 언어 및 환경 구현을 통해 인간과의 지능적인 상호 작용을 위해 이를 어떻게 더 활용할 수 있는지에 중점을 둡니다.
2020년 3월 Microsoft에 합류하기 전 Yang은 Georgia Tech의 대화형 컴퓨팅 대학에서 컴퓨터 과학 박사 학위를 받았습니다. 그의 지도교수는 Devi Parikh 교수였으며 Dhruv Batra 교수와도 긴밀하게 협력했습니다.
Gao Jianfeng

Gao Jianfeng은 뛰어난 과학자이자 Microsoft Research의 부사장, IEEE 회원, ACM 회원입니다.
현재 Gao Jianfeng은 딥러닝 그룹을 이끌고 있습니다. 이 그룹의 임무는 최첨단 딥 러닝과 자연어 및 이미지 이해 분야의 응용 분야를 발전시키고 대화 모델 및 방법을 발전시키는 것입니다.
연구에는 주로 자연어 이해 및 생성을 위한 신경 언어 모델, 신경 기호 컴퓨팅, 시각 언어의 기초 및 이해, 대화형 인공 지능 등이 포함됩니다.
2014년부터 2018년까지 Gao Jianfeng은 Microsoft 인공 지능 및 연구 부서와 Redmond Microsoft Research의 DLTC(딥 러닝 기술 센터)에서 상업용 인공 지능의 파트너 연구 관리자로 근무했습니다.
2006년부터 2014년까지 Gao Jianfeng은 자연어 처리 그룹의 수석 연구원을 역임했습니다.
이용재

이용재는 워싱턴 매디슨 대학교 컴퓨터공학과 부교수입니다.
그는 2021년 가을 UW-Madison에 입사하기 전 Cruise에서 인공지능 분야의 방문 강사로 1년을 보냈고, 그 전에는 University of California, Davis에서 조교수 및 부교수로 6년을 보냈습니다.
그는 또한 카네기멜론대학교 로봇연구소에서 박사후 연구원으로 1년을 보냈습니다.
그는 2012년 5월 오스틴에 있는 텍사스 대학교에서 Kristen Grauman과 함께 박사 학위를 받았으며, 2006년 5월에 일리노이 대학교 어바나-샴페인에서 학사 학위를 받았습니다.
그는 또한 Larry Zitnick 및 Michael Cohen과 함께 Microsoft Research에서 여름 인턴으로 일했습니다.
현재 이씨의 연구는 컴퓨터 비전과 머신러닝에 중점을 두고 있습니다. Lee는 특히 사람의 감독을 최소화하면서 시각적 데이터를 이해할 수 있는 강력한 시각적 인식 시스템을 만드는 데 관심이 있습니다.
현재 SEEM에서 데모를 열었습니다:
https://huggingface.co/spaces/xdecoder/SEEM
어서 사용해 보세요.
위 내용은 중국팀이 이력서를 뒤집었다! SEEM은 모든 폭발을 완벽하게 분할하고 원클릭으로 '순간의 우주'를 분할합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7677
7677
 15
1393
52
1207
24
91
11
73
19
15
1393
52
1207
24
91
11
73
19

 비디오 파일은 브라우저 캐시의 어디에 저장됩니까?
Feb 19, 2024 pm 05:09 PM
비디오 파일은 브라우저 캐시의 어디에 저장됩니까?
Feb 19, 2024 pm 05:09 PM
브라우저는 어떤 폴더에 동영상을 캐시하나요? 우리는 매일 인터넷 브라우저를 사용하다 보면 유튜브에서 뮤직비디오를 보거나 넷플릭스에서 영화를 보는 등 다양한 온라인 동영상을 자주 보게 됩니다. 이러한 비디오는 나중에 다시 재생할 때 빠르게 로드할 수 있도록 로드 프로세스 중에 브라우저에 의해 캐시됩니다. 그렇다면 문제는 캐시된 동영상이 실제로 어느 폴더에 저장되어 있느냐는 것입니다. 브라우저마다 캐시된 비디오 폴더를 다른 위치에 저장합니다. 아래에서는 몇 가지 일반적인 브라우저와 해당 브라우저를 소개합니다.
 Douyin에 다른 사람의 동영상을 게시하는 것이 침해인가요? 침해 없이 동영상을 편집하려면 어떻게 해야 하나요?
Mar 21, 2024 pm 05:57 PM
Douyin에 다른 사람의 동영상을 게시하는 것이 침해인가요? 침해 없이 동영상을 편집하려면 어떻게 해야 하나요?
Mar 21, 2024 pm 05:57 PM
단편 동영상 플랫폼의 등장으로 Douyin은 모든 사람의 일상생활에 없어서는 안 될 부분이 되었습니다. TikTok에서는 전 세계의 흥미로운 동영상을 볼 수 있습니다. 어떤 사람들은 다른 사람의 동영상을 게시하는 것을 좋아하는데, 이는 다음과 같은 질문을 제기합니다. Douyin이 다른 사람의 동영상을 게시하면 저작권을 침해합니까? 이 글에서는 이 문제에 대해 논의하고 침해 없이 동영상을 편집하는 방법과 침해 문제를 방지하는 방법을 알려드립니다. 1. Douyin이 타인의 영상을 게시하는 것에 대한 침해인가요? 우리나라 저작권법 조항에 따르면, 저작권 소유자의 허락 없이 저작권 소유자의 저작물을 무단으로 사용하는 것은 침해입니다. 따라서 원저작자나 저작권 소유자의 허락 없이 Douyin에 다른 사람의 동영상을 게시하는 것은 침해입니다. 2. 침해 없이 동영상을 편집하는 방법은 무엇입니까? 1. 공개 도메인 또는 라이센스 콘텐츠의 사용: 공개
 윙크 동영상 워터마크 제거하는 방법
Feb 23, 2024 pm 07:22 PM
윙크 동영상 워터마크 제거하는 방법
Feb 23, 2024 pm 07:22 PM
윙크 동영상 워터마크 제거 방법 winkAPP에 동영상 워터마크 제거 도구가 있는데 대부분의 친구들이 윙크 동영상 워터마크 제거 방법을 모릅니다. 편집자가 가져온 텍스트 튜토리얼입니다. 관심 있는 사용자가 와서 살펴보세요! 윙크에서 비디오 워터마크를 제거하는 방법 1. 먼저 윙크 앱을 열고 홈페이지 영역에서 [워터마크 제거] 기능을 선택합니다. 2. 그런 다음 앨범에서 워터마크를 제거하려는 비디오를 선택합니다. 3. 그런 다음 비디오를 선택하고 클릭합니다. 영상 편집 후 오른쪽 상단 [√] 4. 마지막으로 아래 그림과 같이 [원클릭 인쇄]를 클릭한 후 [처리]를 클릭하세요.
 Douyin에 동영상을 게시하여 수익을 창출하는 방법은 무엇입니까? 초보자가 Douyin으로 어떻게 돈을 벌 수 있나요?
Mar 21, 2024 pm 08:17 PM
Douyin에 동영상을 게시하여 수익을 창출하는 방법은 무엇입니까? 초보자가 Douyin으로 어떻게 돈을 벌 수 있나요?
Mar 21, 2024 pm 08:17 PM
국민 단편 영상 플랫폼인 Douyin은 우리가 여가 시간에 재미있고 참신한 다양한 단편 영상을 즐길 수 있게 해줄 뿐만 아니라, 우리 자신을 보여주고 우리의 가치를 실현할 수 있는 무대를 제공합니다. 그렇다면 Douyin에 동영상을 게시하여 돈을 버는 방법은 무엇입니까? 이 글은 이 질문에 대해 자세히 답변하고 TikTok에서 더 많은 수익을 창출하는 데 도움이 될 것입니다. 1. Douyin에 동영상을 게시하여 수익을 창출하는 방법은 무엇입니까? 동영상을 게시하고 Douyin에서 일정 조회수를 얻은 후 광고 공유 계획에 참여할 수 있는 기회를 얻게 됩니다. 이 수입 방식은 Douyin 사용자들에게 가장 친숙한 방법 중 하나이며, 많은 창작자들의 주요 수입원이기도 합니다. Douyin은 계정 가중치, 영상 콘텐츠, 시청자 피드백 등 다양한 요소를 바탕으로 광고 공유 기회 제공 여부를 결정합니다. TikTok 플랫폼을 통해 시청자는 선물을 보내 좋아하는 크리에이터를 지원할 수 있습니다.
 iPhone의 비디오에서 슬로우 모션을 제거하는 2가지 방법
Mar 04, 2024 am 10:46 AM
iPhone의 비디오에서 슬로우 모션을 제거하는 2가지 방법
Mar 04, 2024 am 10:46 AM
iOS 장치에서 카메라 앱을 사용하면 슬로우 모션 비디오를 촬영할 수 있으며, 최신 iPhone을 사용하는 경우 초당 240프레임까지 촬영할 수 있습니다. 이 기능을 사용하면 고속 동작을 풍부하고 자세하게 캡처할 수 있습니다. 그러나 때로는 비디오의 세부 사항과 동작을 더 잘 감상할 수 있도록 슬로우 모션 비디오를 정상 속도로 재생하고 싶을 수도 있습니다. 이 기사에서는 iPhone의 기존 비디오에서 슬로우 모션을 제거하는 모든 방법을 설명합니다. iPhone의 비디오에서 슬로우 모션을 제거하는 방법 [2가지 방법] 사진 앱 또는 iMovie 앱을 사용하여 장치의 비디오에서 슬로우 모션을 제거할 수 있습니다. 방법 1: iPhone에서 사진 앱을 사용하여 열기
 Xiaohongshu 비디오 작품을 출판하는 방법은 무엇입니까? 영상을 올릴 때 주의할 점은 무엇인가요?
Mar 23, 2024 pm 08:50 PM
Xiaohongshu 비디오 작품을 출판하는 방법은 무엇입니까? 영상을 올릴 때 주의할 점은 무엇인가요?
Mar 23, 2024 pm 08:50 PM
단편 동영상 플랫폼의 등장으로 Xiaohongshu는 많은 사람들이 자신의 삶을 공유하고 자신을 표현하며 트래픽을 얻는 플랫폼이 되었습니다. 이 플랫폼에서는 비디오 작품을 출판하는 것이 매우 인기 있는 상호 작용 방식입니다. 그렇다면 Xiaohongshu 비디오 작품을 출판하는 방법은 무엇입니까? 1. 샤오홍슈 영상 작품은 어떻게 출판하나요? 먼저, 공유할 비디오 콘텐츠가 준비되어 있는지 확인하세요. 휴대폰이나 기타 카메라 장비를 사용해 촬영할 수 있지만 화질과 사운드 선명도에 주의해야 합니다. 2. 영상 편집 : 작품을 더욱 돋보이게 하기 위해 영상을 편집할 수 있습니다. Douyin, Kuaishou 등과 같은 전문 비디오 편집 소프트웨어를 사용하여 필터, 음악, 자막 및 기타 요소를 추가할 수 있습니다. 3. 표지를 선택하세요. 표지는 사용자의 클릭을 유도하는 핵심 요소입니다. 사용자의 클릭을 유도할 수 있는 명확하고 흥미로운 그림을 표지로 선택하세요.
 UC 브라우저로 다운로드한 비디오를 로컬 비디오로 변환하는 방법
Feb 29, 2024 pm 10:19 PM
UC 브라우저로 다운로드한 비디오를 로컬 비디오로 변환하는 방법
Feb 29, 2024 pm 10:19 PM
UC 브라우저로 다운로드한 비디오를 로컬 비디오로 변환하는 방법은 무엇입니까? 많은 휴대폰 사용자는 웹 검색뿐만 아니라 온라인으로 다양한 비디오 및 TV 프로그램을 시청하고 좋아하는 비디오를 휴대폰에 다운로드할 수 있는 기능을 즐겨 사용합니다. 실제로 다운로드한 비디오를 로컬 비디오로 변환할 수 있지만 많은 사람들이 이를 수행하는 방법을 모릅니다. 따라서 편집자는 UC 브라우저에 캐시된 비디오를 로컬 비디오로 변환하는 방법을 특별히 제공합니다. uc 브라우저에 캐시된 비디오를 로컬 비디오로 변환하는 방법 1. uc 브라우저를 열고 "메뉴" 옵션을 클릭합니다. 2. "다운로드/동영상"을 클릭하세요. 3. "캐시된 비디오"를 클릭하세요. 4. 비디오를 길게 누르고 옵션이 나타나면 "디렉터리 열기"를 클릭합니다. 5. 다운로드하고 싶은 항목을 확인하세요.
 이미지 품질을 압축하지 않고 웨이보에 동영상을 게시하는 방법_화질을 압축하지 않고 웨이보에 동영상을 게시하는 방법
Mar 30, 2024 pm 12:26 PM
이미지 품질을 압축하지 않고 웨이보에 동영상을 게시하는 방법_화질을 압축하지 않고 웨이보에 동영상을 게시하는 방법
Mar 30, 2024 pm 12:26 PM
1. 먼저 휴대폰에서 웨이보를 열고 오른쪽 하단의 [나]를 클릭하세요(그림 참조). 2. 그런 다음 오른쪽 상단에 있는 [기어]를 클릭하여 설정을 엽니다(그림 참조). 3. 그런 다음 [일반 설정]을 찾아 엽니다(그림 참조). 4. 그런 다음 [동영상 팔로우] 옵션을 입력하세요(그림 참조). 5. 그런 다음 [동영상 업로드 해상도] 설정을 엽니다(그림 참조). 6. 마지막으로 [원본 화질]을 선택하여 압축을 방지합니다(그림 참조).
