

Python 가상 머신을 사용하는 방법

python 바이트코드 디자인
파이썬 바이트코드는 주로 두 부분으로 구성됩니다. 하나는 연산 코드이고 다른 하나는 이 연산 코드의 매개변수입니다. cpython에서는 일부 바이트코드에만 매개변수가 있습니다. oparg의 값은 0입니다. cpython에서 opcode
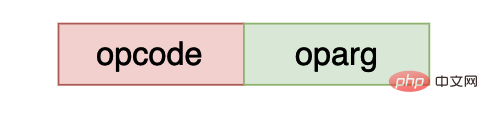
opcode와 oparg는 각각 1바이트를 차지하며, cpython 가상 머신은 바이트코드를 저장하기 위해 little endian 모드를 사용합니다.
바이트코드의 디자인을 먼저 이해하기 위해 다음 코드 조각을 사용합니다.
import dis
def add(a, b):
return a + b
if __name__ == '__main__':
print(add.__code__.co_code)
print("bytecode: ", list(bytearray(add.__code__.co_code)))
dis.dis(add)python3.9에서 위 코드의 출력은 다음과 같습니다.
b'|\x00|\x01\x17\x00S\x00'
bytecode: [124, 0, 124, 1, 23, 0, 83, 0]
5 0 LOAD_FAST 0 (a)
2 LOAD_FAST 1 (b)
4 BINARY_ADD
6 RETURN_VALUE가장 먼저 이해해야 할 것은 add.__code__.co_code입니다. Bytecode를 추가하는 함수는 바이트 시퀀스입니다. list(bytearray(add.__code__.co_code)) 이 시퀀스를 바이트별로 분리하여 10진수 형식으로 변환합니다. 이전에 설명한 각 명령어에 따르면 바이트코드는 2바이트를 차지하므로 위 바이트코드에는 4개의 명령어가 있습니다. 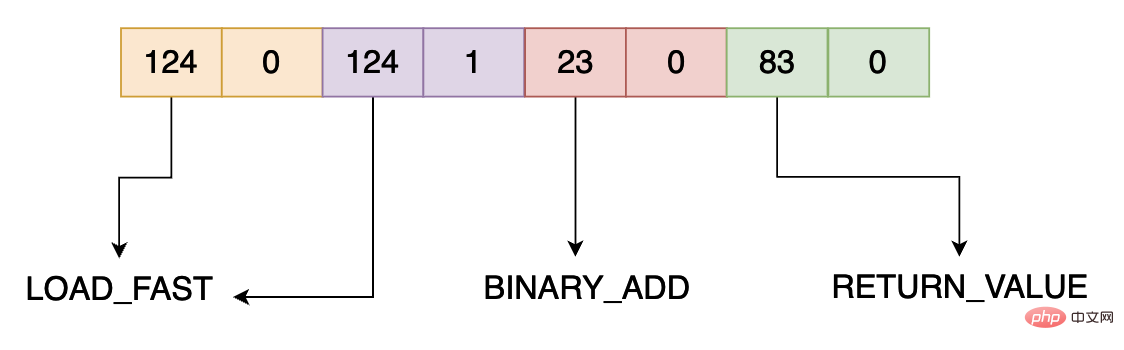
작업 코드와 해당 작업 명령어는 기사 마지막 부분에 자세한 대응표가 있습니다. 위 코드에서는 주로 124, 23, 83의 세 가지 바이트코드 명령어가 사용됩니다. 해당 연산 명령어는 각각 LOAD_FAST, BINARY_ADD 및 RETURN_VALUE입니다. 그 의미는 다음과 같습니다:
LOAD_FAST: varnames[var_num]을 스택 맨 위에 푸시합니다. BINARY_ADD: 스택에서 두 개체를 팝하고 추가 결과를 스택 맨 위에 푸시합니다. RETURN_VALUE: 스택 상단의 요소를 팝하고 이를 함수의 반환 값으로 사용합니다.
가장 먼저 알아야 할 것은 BINARY_ADD 및 RETURN_VALUE입니다. 이 두 연산 명령어에는 매개변수가 없으므로 이 두 opcode 뒤의 매개변수는 모두 0입니다.
하지만 LOAD_FAST에는 매개변수가 있습니다. LOAD_FAST가 co-varnames[var_num]을 스택에 푸시하고 var_num이 LOAD_FAST 명령어의 매개변수라는 것을 위에서 이미 알고 있습니다. 위 코드에는 a와 b를 스택에 푸시하는 두 개의 LOAD_FAST 명령어가 있습니다. varname의 첨자는 각각 0과 1이므로 피연산자는 0과 1입니다.
바이트코드 확장 매개변수
위에서 이야기한 Python 바이트코드 피연산자와 opcode는 각각 1바이트를 차지하는데, varname이나 상수 테이블 데이터의 개수가 1바이트의 표현 범위보다 크다면 어떻게 처리해야 할까요?
이 문제를 해결하기 위해 cpython은 바이트코드에 대한 확장 매개변수를 설계합니다. 예를 들어 상수 테이블에 아래 첨자 66113이 있는 객체를 로드하려는 경우 해당 바이트코드는 다음과 같습니다.
[144, 1, 144, 2, 100, 65]
144는 EXTENDED_ARG를 나타냅니다. 기본적으로 Python 가상 머신에서 실행해야 하는 바이트코드는 아닙니다. 이 필드는 주로 확장 매개변수를 계산하는 데 사용하도록 설계되었습니다.
100에 해당하는 연산 명령어는 LOAD_CONST이고, opcode는 65이다. 그런데 위 명령어는 상수 테이블에서 첨자 65를 갖는 객체를 로드하지 않고, 첨자 66113을 갖는 객체를 로딩하게 된다. 그 이유는 EXTENDED_ARG 중
이제 위 분석 프로세스를 시뮬레이션해 보겠습니다.
먼저 바이트코드 명령어를 읽으면 opcode는 144와 같습니다. 이는 확장 매개변수임을 나타냅니다. 그런 다음 이때 매개변수 arg는 (1 x (1 < <8)) = 256. 두 번째 바이트코드 명령어를 읽으세요. 연산 코드는 144입니다. 이는 이전 arg가 이미 존재하고 0이 아니기 때문에 확장 매개변수임을 나타냅니다. 그러면 arg의 계산 방법이 이번에 변경되었습니다. arg = arg << 8 + 2 << 8, 즉, 원래 arg에 256을 곱하고 새 피연산자에 256을 곱합니다. 이때 arg = 66048입니다. 세 번째 바이트코드 명령어를 읽으세요. opcode는 100입니다. 이는 LOAD_CONST 명령어입니다. 이때 opcode는 arg += 65와 같습니다. opcode는 EXTENDED_ARG가 아니므로 피연산자에 다음을 곱할 필요가 없습니다. 256. .
위의 계산 과정을 프로그램 코드로 표현하면 아래 코드에서 코드는 실제 바이트 시퀀스 HAVE_ARGUMENT = 90입니다.
def _unpack_opargs(code):
extended_arg = 0
for i in range(0, len(code), 2):
op = code[i]
if op >= HAVE_ARGUMENT:
arg = code[i+1] | extended_arg
extended_arg = (arg << 8) if op == EXTENDED_ARG else 0
else:
arg = None
yield (i, op, arg)코드를 사용하여 이전 분석을 확인할 수 있습니다.
import dis
def num_to_byte(n):
return n.to_bytes(1, "little")
def nums_to_bytes(data):
ans = b"".join([num_to_byte(n) for n in data])
return ans
if __name__ == '__main__':
# extended_arg extended_num opcode oparg for python_version > 3.5
bytecode = nums_to_bytes([144, 1, 144, 2, 100, 65])
print(bytecode)
dis.dis(bytecode)위 코드의 출력은 다음과 같습니다.
b'\x90\x01\x90\x02dA'
0 EXTENDED_ARG 1
2 EXTENDED_ARG 258
4 LOAD_CONST 66113 (66113)위 프로그램의 출력에 따르면 분석 결과가 올바른 것을 확인할 수 있습니다.
소스 코드 바이트코드 매핑 테이블
이 섹션에서는 주로 코드 객체 객체의 co_lnotab 필드를 분석하고, 특정 필드를 분석하여 이 필드의 디자인을 학습합니다.
import dis
def add(a, b):
a += 1
b += 2
return a + b
if __name__ == '__main__':
dis.dis(add.__code__)
print(f"{list(bytearray(add.__code__.co_lnotab)) = }")
print(f"{add.__code__.co_firstlineno = }")먼저 dis 출력의 첫 번째 열은 바이트코드에 해당하는 소스 코드의 줄 번호이고, 두 번째 열은 바이트 시퀀스에서 바이트코드의 변위입니다.
위 코드의 출력 결과는 다음과 같습니다.
源代码的行号 字节码的位移
6 0 LOAD_FAST 0 (a)
2 LOAD_CONST 1 (1)
4 INPLACE_ADD
6 STORE_FAST 0 (a)
7 8 LOAD_FAST 1 (b)
10 LOAD_CONST 2 (2)
12 INPLACE_ADD
14 STORE_FAST 1 (b)
8 16 LOAD_FAST 0 (a)
18 LOAD_FAST 1 (b)
20 BINARY_ADD
22 RETURN_VALUE
list(bytearray(add.__code__.co_lnotab)) = [0, 1, 8, 1, 8, 1]
add.__code__.co_firstlineno = 5위 코드의 출력 결과에서 바이트코드가 세 개의 세그먼트로 나뉘며 각 세그먼트는 코드 한 줄의 바이트코드를 나타냄을 알 수 있습니다. 이제 co_lnotab 필드를 분석해 보겠습니다. 이 필드는 실제로 2바이트로 나누어져 있습니다. 예를 들어, 위의 [0, 1, 8, 1, 8, 1]은 [0, 1], [8, 1], [8, 1]의 3개 세그먼트로 분할될 수 있다. 의미는 다음과 같습니다.
第一个数字表示距离上一行代码的字节码数目。 第二个数字表示距离上一行有效代码的行数。
现在我们来模拟上面代码的字节码的位移和源代码行数之间的关系:
[0, 1],说明这行代码离上一行代码的字节位移是 0 ,因此我们可以看到使用 dis 输出的字节码 LOAD_FAST ,前面的数字是 0,距离上一行代码的行数等于 1 ,代码的第一行的行号等于 5,因此 LOAD_FAST 对应的行号等于 5 + 1 = 6 。 [8, 1],说明这行代码距离上一行代码的字节位移为 8 个字节,因此第二块的 LOAD_FAST 前面是 8 ,距离上一行代码的行数等于 1,因此这个字节码对应的源代码的行号等于 6 + 1 = 7。 [8, 1],同理可以知道这块字节码对应源代码的行号是 8 。
现在有一个问题是当两行代码之间相距的行数超过 一个字节的表示范围怎么办?在 python3.5 以后如果行数差距大于 127,那么就使用 (0, 行数) 对下一个组合进行表示,(0, \(x_1\)), (0,$ x_2$) ... ,直到 \(x_1 + ... + x_n\) = 行数。
在后面的程序当中我们会使用 compile 这个 python 内嵌函数。当你使用Python编写代码时,可以使用compile()函数将Python代码编译成字节代码对象。这个字节码对象可以被传递给Python的解释器或虚拟机,以执行代码。
compile()函数接受三个参数:
source: 要编译的Python代码,可以是字符串,字节码或AST对象。 filename: 代码来源的文件名(如果有),通常为字符串。 mode: 编译代码的模式。可以是 'exec'、'eval' 或 'single' 中的一个。'exec' 模式用于编译多行代码,'eval' 用于编译单个表达式,'single' 用于编译单行代码。
import dis code = """ x=1 y=2 """ \ + "\n" * 500 + \ """ z=x+y """ code = compile(code, '<string>', 'exec') print(list(bytearray(code.co_lnotab))) print(code.co_firstlineno) dis.dis(code)
上面的代码输出结果如下所示:
[0, 1, 4, 1, 4, 127, 0, 127, 0, 127, 0, 121]
1
2 0 LOAD_CONST 0 (1)
2 STORE_NAME 0 (x)
3 4 LOAD_CONST 1 (2)
6 STORE_NAME 1 (y)
505 8 LOAD_NAME 0 (x)
10 LOAD_NAME 1 (y)
12 BINARY_ADD
14 STORE_NAME 2 (z)
16 LOAD_CONST 2 (None)
18 RETURN_VALUE根据我们前面的分析因为第三行和第二行之间的差距大于 127 ,因此后面的多个组合都是用于表示行数的。
505 = 3(前面已经有三行了) + (127 + 127 + 127 + 121)(这个是第二行和第三行之间的差距,这个值为 502,中间有 500 个换行但是因为字符串相加的原因还增加了两个换行,因此一共是 502 个换行)。
具体的算法用代码表示如下所示,下面的参数就是我们传递给 dis 模块的 code,也就是一个 code object 对象。
def findlinestarts(code):
"""Find the offsets in a byte code which are start of lines in the source.
Generate pairs (offset, lineno) as described in Python/compile.c.
"""
byte_increments = code.co_lnotab[0::2]
line_increments = code.co_lnotab[1::2]
bytecode_len = len(code.co_code)
lastlineno = None
lineno = code.co_firstlineno
addr = 0
for byte_incr, line_incr in zip(byte_increments, line_increments):
if byte_incr:
if lineno != lastlineno:
yield (addr, lineno)
lastlineno = lineno
addr += byte_incr
if addr >= bytecode_len:
# The rest of the lnotab byte offsets are past the end of
# the bytecode, so the lines were optimized away.
return
if line_incr >= 0x80:
# line_increments is an array of 8-bit signed integers
line_incr -= 0x100
lineno += line_incr
if lineno != lastlineno:
yield (addr, lineno)| 操作 | 操作码 |
|---|---|
| POP_TOP | 1 |
| ROT_TWO | 2 |
| ROT_THREE | 3 |
| DUP_TOP | 4 |
| DUP_TOP_TWO | 5 |
| ROT_FOUR | 6 |
| NOP | 9 |
| UNARY_POSITIVE | 10 |
| UNARY_NEGATIVE | 11 |
| UNARY_NOT | 12 |
| UNARY_INVERT | 15 |
| BINARY_MATRIX_MULTIPLY | 16 |
| INPLACE_MATRIX_MULTIPLY | 17 |
| BINARY_POWER | 19 |
| BINARY_MULTIPLY | 20 |
| BINARY_MODULO | 22 |
| BINARY_ADD | 23 |
| BINARY_SUBTRACT | 24 |
| BINARY_SUBSCR | 25 |
| BINARY_FLOOR_DIVIDE | 26 |
| BINARY_TRUE_DIVIDE | 27 |
| INPLACE_FLOOR_DIVIDE | 28 |
| INPLACE_TRUE_DIVIDE | 29 |
| RERAISE | 48 |
| WITH_EXCEPT_START | 49 |
| GET_AITER | 50 |
| GET_ANEXT | 51 |
| BEFORE_ASYNC_WITH | 52 |
| END_ASYNC_FOR | 54 |
| INPLACE_ADD | 55 |
| INPLACE_SUBTRACT | 56 |
| INPLACE_MULTIPLY | 57 |
| INPLACE_MODULO | 59 |
| STORE_SUBSCR | 60 |
| DELETE_SUBSCR | 61 |
| BINARY_LSHIFT | 62 |
| BINARY_RSHIFT | 63 |
| BINARY_AND | 64 |
| BINARY_XOR | 65 |
| BINARY_OR | 66 |
| INPLACE_POWER | 67 |
| GET_ITER | 68 |
| GET_YIELD_FROM_ITER | 69 |
| PRINT_EXPR | 70 |
| LOAD_BUILD_CLASS | 71 |
| YIELD_FROM | 72 |
| GET_AWAITABLE | 73 |
| LOAD_ASSERTION_ERROR | 74 |
| INPLACE_LSHIFT | 75 |
| INPLACE_RSHIFT | 76 |
| INPLACE_AND | 77 |
| INPLACE_XOR | 78 |
| INPLACE_OR | 79 |
| LIST_TO_TUPLE | 82 |
| RETURN_VALUE | 83 |
| IMPORT_STAR | 84 |
| SETUP_ANNOTATIONS | 85 |
| YIELD_VALUE | 86 |
| POP_BLOCK | 87 |
| POP_EXCEPT | 89 |
| STORE_NAME | 90 |
| DELETE_NAME | 91 |
| UNPACK_SEQUENCE | 92 |
| FOR_ITER | 93 |
| UNPACK_EX | 94 |
| STORE_ATTR | 95 |
| DELETE_ATTR | 96 |
| STORE_GLOBAL | 97 |
| DELETE_GLOBAL | 98 |
| LOAD_CONST | 100 |
| LOAD_NAME | 101 |
| BUILD_TUPLE | 102 |
| BUILD_LIST | 103 |
| BUILD_SET | 104 |
| BUILD_MAP | 105 |
| LOAD_ATTR | 106 |
| COMPARE_OP | 107 |
| IMPORT_NAME | 108 |
| IMPORT_FROM | 109 |
| JUMP_FORWARD | 110 |
| JUMP_IF_FALSE_OR_POP | 111 |
| JUMP_IF_TRUE_OR_POP | 112 |
| JUMP_ABSOLUTE | 113 |
| POP_JUMP_IF_FALSE | 114 |
| POP_JUMP_IF_TRUE | 115 |
| LOAD_GLOBAL | 116 |
| IS_OP | 117 |
| CONTAINS_OP | 118 |
| JUMP_IF_NOT_EXC_MATCH | 121 |
| SETUP_FINALLY | 122 |
| LOAD_FAST | 124 |
| STORE_FAST | 125 |
| DELETE_FAST | 126 |
| RAISE_VARARGS | 130 |
| CALL_FUNCTION | 131 |
| MAKE_FUNCTION | 132 |
| BUILD_SLICE | 133 |
| LOAD_CLOSURE | 135 |
| LOAD_DEREF | 136 |
| STORE_DEREF | 137 |
| DELETE_DEREF | 138 |
| CALL_FUNCTION_KW | 141 |
| CALL_FUNCTION_EX | 142 |
| SETUP_WITH | 143 |
| LIST_APPEND | 145 |
| SET_ADD | 146 |
| MAP_ADD | 147 |
| LOAD_CLASSDEREF | 148 |
| EXTENDED_ARG | 144 |
| SETUP_ASYNC_WITH | 154 |
| FORMAT_VALUE | 155 |
| BUILD_CONST_KEY_MAP | 156 |
| BUILD_STRING | 157 |
| LOAD_METHOD | 160 |
| CALL_METHOD | 161 |
| LIST_EXTEND | 162 |
| SET_UPDATE | 163 |
| DICT_MERGE | 164 |
| DICT_UPDATE | 165 |
위 내용은 Python 가상 머신을 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7425
7425
 15
1359
52
76
11
27
19
15
1359
52
76
11
27
19

 휴대폰에서 XML을 PDF로 변환 할 때 변환 속도가 빠르나요?
Apr 02, 2025 pm 10:09 PM
휴대폰에서 XML을 PDF로 변환 할 때 변환 속도가 빠르나요?
Apr 02, 2025 pm 10:09 PM
모바일 XML에서 PDF의 속도는 다음 요인에 따라 다릅니다. XML 구조의 복잡성. 모바일 하드웨어 구성 변환 방법 (라이브러리, 알고리즘) 코드 품질 최적화 방법 (효율적인 라이브러리 선택, 알고리즘 최적화, 캐시 데이터 및 다중 스레딩 사용). 전반적으로 절대적인 답변은 없으며 특정 상황에 따라 최적화해야합니다.
 휴대 전화에서 XML 파일을 PDF로 변환하는 방법은 무엇입니까?
Apr 02, 2025 pm 10:12 PM
휴대 전화에서 XML 파일을 PDF로 변환하는 방법은 무엇입니까?
Apr 02, 2025 pm 10:12 PM
단일 애플리케이션으로 휴대 전화에서 직접 XML에서 PDF 변환을 완료하는 것은 불가능합니다. 두 단계를 통해 달성 할 수있는 클라우드 서비스를 사용해야합니다. 1. 클라우드에서 XML을 PDF로 변환하십시오. 2. 휴대 전화에서 변환 된 PDF 파일에 액세스하거나 다운로드하십시오.
 C 언어 합계의 기능은 무엇입니까?
Apr 03, 2025 pm 02:21 PM
C 언어 합계의 기능은 무엇입니까?
Apr 03, 2025 pm 02:21 PM
C 언어에는 내장 합계 기능이 없으므로 직접 작성해야합니다. 합계는 배열 및 축적 요소를 가로 질러 달성 할 수 있습니다. 루프 버전 : 루프 및 배열 길이를 사용하여 계산됩니다. 포인터 버전 : 포인터를 사용하여 배열 요소를 가리키며 효율적인 합계는 자체 증가 포인터를 통해 달성됩니다. 동적으로 배열 버전을 할당 : 배열을 동적으로 할당하고 메모리를 직접 관리하여 메모리 누출을 방지하기 위해 할당 된 메모리가 해제되도록합니다.
 휴대 전화에서 XML을 PDF로 변환하는 방법은 무엇입니까?
Apr 02, 2025 pm 10:18 PM
휴대 전화에서 XML을 PDF로 변환하는 방법은 무엇입니까?
Apr 02, 2025 pm 10:18 PM
휴대 전화에서 XML을 PDF로 직접 변환하는 것은 쉽지 않지만 클라우드 서비스를 통해 달성 할 수 있습니다. 가벼운 모바일 앱을 사용하여 XML 파일을 업로드하고 생성 된 PDF를 수신하고 클라우드 API로 변환하는 것이 좋습니다. Cloud API는 Serverless Computing Services를 사용하고 올바른 플랫폼을 선택하는 것이 중요합니다. XML 구문 분석 및 PDF 생성을 처리 할 때 복잡성, 오류 처리, 보안 및 최적화 전략을 고려해야합니다. 전체 프로세스에는 프론트 엔드 앱과 백엔드 API가 함께 작동해야하며 다양한 기술에 대한 이해가 필요합니다.
 XML을 그림으로 변환하는 방법
Apr 03, 2025 am 07:39 AM
XML을 그림으로 변환하는 방법
Apr 03, 2025 am 07:39 AM
XSLT 변환기 또는 이미지 라이브러리를 사용하여 XML을 이미지로 변환 할 수 있습니다. XSLT 변환기 : XSLT 프로세서 및 스타일 시트를 사용하여 XML을 이미지로 변환합니다. 이미지 라이브러리 : Pil 또는 Imagemagick와 같은 라이브러리를 사용하여 XML 데이터에서 이미지를 그리기 및 텍스트 그리기와 같은 이미지를 만듭니다.
 누가 더 많은 파이썬이나 자바 스크립트를 지불합니까?
Apr 04, 2025 am 12:09 AM
누가 더 많은 파이썬이나 자바 스크립트를 지불합니까?
Apr 04, 2025 am 12:09 AM
기술 및 산업 요구에 따라 Python 및 JavaScript 개발자에 대한 절대 급여는 없습니다. 1. 파이썬은 데이터 과학 및 기계 학습에서 더 많은 비용을 지불 할 수 있습니다. 2. JavaScript는 프론트 엔드 및 풀 스택 개발에 큰 수요가 있으며 급여도 상당합니다. 3. 영향 요인에는 경험, 지리적 위치, 회사 규모 및 특정 기술이 포함됩니다.
 XML을 MP3로 변환하는 방법
Apr 03, 2025 am 09:00 AM
XML을 MP3로 변환하는 방법
Apr 03, 2025 am 09:00 AM
XML을 MP3로 변환하는 단계에는 다음이 포함됩니다. XML에서 오디오 데이터 추출 : XML 파일을 구문 분석하고, 오디오 데이터가 포함 된 Base64 인코딩 문자열을 찾아 이진 형식으로 디코딩하십시오. 오디오 데이터를 MP3로 인코딩합니다. MP3 인코더를 설치하고 인코딩 매개 변수를 설정하고 이진 오디오 데이터를 MP3 형식으로 인코딩 한 다음 파일에 저장하십시오.
 XML 형식을 변경하는 방법
Apr 03, 2025 am 08:42 AM
XML 형식을 변경하는 방법
Apr 03, 2025 am 08:42 AM
XML 형식을 수정하는 방법에는 여러 가지가 있습니다. Notepad와 같은 텍스트 편집기로 수동으로 편집; XMLBeautifier와 같은 온라인 또는 데스크탑 XML 서식 도구와 자동 포맷; XSLT와 같은 XML 변환 도구를 사용하여 변환 규칙을 정의합니다. 또는 Python과 같은 프로그래밍 언어를 사용하여 구문 분석하고 작동합니다. 원본 파일을 수정하고 백업 할 때주의하십시오.
