

SpringBoot 프로젝트에서 MySQL 읽기 및 쓰기 분리를 구현하는 방법

1. MySQL 마스터-슬레이브 복제
하지만 자세히 살펴보면 우리 프로젝트가 모두 단일 데이터베이스를 사용할 때 다음과 같은 문제가 있을 수 있습니다.
모두 읽고 쓰기 압력은 모두 하나의 데이터베이스가 부담합니다. 높은 압력
데이터베이스 서버 디스크가 손상되면 데이터가 손실됩니다, 이는 단일 실패 지점입니다
위의 두 가지 문제를 해결하려면 위에서는 MySQL, 마스터(Master) 서버, 슬레이브(Slave) 서버 두 대를 준비할 수 있습니다. 마스터 데이터베이스의 데이터 변경(쓰기, 업데이트, 삭제 작업)이 필요합니다. 슬레이브 데이터베이스(마스터에서 복사됨)에 동기화됩니다. 사용자가 우리 프로젝트에 접근할 때 쓰기 작업(삽입, 업데이트, 삭제)이면 메인 라이브러리가 직접 작동되고, 읽기 작업(선택)이면 슬레이브 라이브러리가 작동됩니다. 이 구조는 읽기와 쓰기의 분리입니다.

비동기 복제 프로세스입니다. 바이너리 로그 기능. 이는 하나 이상의 MySQL 데이터베이스(슬레이브, 즉 슬레이브 데이터베이스)가 다른 MySQL 데이터베이스(마스터, 즉 메인 데이터베이스)의 로그를 복사한 후 로그를 구문 분석하여 자신에게 적용한다는 의미이며, 마침내 를 달성했습니다. 라이브러리 의 데이터가 메인 라이브러리의 데이터와 일치합니다. MySQL 마스터-슬레이브 복제는 MySQL 데이터베이스에 내장된 기능이며 타사 도구를 사용할 필요가 없습니다.
바이너리 로그: 바이너리 로그(BINLOG)는 모든 DDL(데이터 정의 언어) 문과 DML(데이터 조작 언어) 문을 기록하지만 데이터 쿼리 문은 포함하지 않습니다. 이 로그는 재해 발생 시 데이터 복구에 매우 중요한 역할을 합니다. MySQL의 마스터-슬레이브 복제는 이 binlog를 통해 구현됩니다. 기본적으로 MySQL은 이 로그를 활성화하지 않습니다. MySQL 복제 프로세스는 세 단계로 나뉩니다.- MySQL 마스터는 데이터 변경 사항을 바이너리 로그(
바이너리 로그)에 기록합니다.
- 슬레이브는 마스터의 바이너리 로그를 릴레이 로그(
relay log)에 복사합니다. )
- 릴레이 로그에 슬레이브 REDO 이벤트를 적용하고 데이터 변경 사항을 자체 데이터에 반영합니다

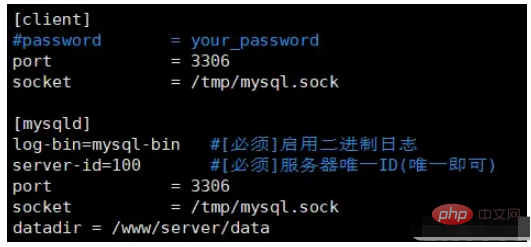
1.Mysql 데이터베이스 vim /etc/my 구성 파일을 수정하세요. .cnf
在打开的文件中加入下面两行,其中的server-id不一定是100,确保唯一即可 log-bin=mysql-bin #[必须]启用二进制日志 server-id=100 #[必须]服务器唯一ID
2. MySQL 서비스를 다시 시작하세요
MySQL을 다시 시작하는 가장 간단한 방법은net stop mysql;net start mysql; systemctl restart mysqld service mysqld restart
3입니다. 그리고 승인하세요
다음 명령은 MySQL에 로그인한 후에만 실행할 수 있습니다. 왜냐하면 이것은 SQL 명령이고 Linux는 그것이 무엇인지 모르기 때문입니다.GRANT REPLICATION SLAVE ON *.* to '用户名'@'开放的地址' identified by '密码'; eg: GRANT REPLICATION SLAVE ON *.* to 'masterDb'@'%' identified by 'Master@123456'; 记得刷一下权限 FLUSH PRIVILEGES;
4. 마스터 동기화 상태를 확인하세요
이때, 다음 명령은 여전히 SQL 명령이기 때문에 MySQL을 종료할 필요는 없습니다. 다음 SQL을 실행하면 두 가지 중요한 매개변수를 얻을 수 있습니다. 나중에 필요해요.show master status;
이 SQL 문장을 실행한 후 == 다시는 메인 데이터베이스를 운영하지 마세요! 더 이상 본관을 운영하지 마세요! 더 이상 본관을 운영하지 마세요! ==중요한 점을 세 번 말씀드립니다. 메인 라이브러리를 운영하다 보면  빨간색 상자 안의 두 가지 속성 값이 변경될 수 있기 때문입니다
빨간색 상자 안의 두 가지 속성 값이 변경될 수 있기 때문입니다
1.2.2、从库配置
服务器:192.168.150.101(别试了黑不了的,这也是虚拟机的ip)
1、 修改Mysql数据库的配置文件 vim /etc/my.cnf

这里要注意server-id和主库以及其他从库都不能相同,否则后面将会配置不成功。
2、重启Mysql服务
这里有三个方法都能重启MySQL,最简单的无疑就是一关一开:
net stop mysql;net start mysql; systemctl restart mysqld service mysqld restart
3、设置主库地址及同步位置
登录进去MySQL之后才能够执行下面的命令,因为这是SQL命令
设置主库地址和同步位置 change master to master_host='192.168.150.100',master_user='masterDb',master_password='Master@123456',master_log_file='mysql-bin.000010',master_log_pos=68479; 记得记得开启从库配置 start slave;
参数说明:
master_host: 主库的 IP地址
master_user: 访问主库进行主从复制的 用户名 ( 上面在主库创建的 )
master_password: 访问主库进行主从复制的用户名对应的 密码
master_log_file: 从哪个 日志文件 开始同步 ( 即1.2.1中第4步获取的 File )
master_log_pos: 从指定日志文件的哪个 位置 开始同步 ( 即1.2.1中第4步获取的 Position )
4、查看从数据库的状态
这个时候还 不用退出MySQL ,因为下面的命令还是SQL命令,执行下面的SQL,可以看到从库的状态信息。通过状态信息中的 Slave_IO_running 和 Slave_SQL_running 可以看出主从同步是否就绪,如果这两个参数全为 Yes ,表示主从同步已经配置完成。
show slave status\G;

1.3、坑位介绍
1.3.1、UUID报错
这可能是由于linux 是复制出来的,MySQL中还有一个 server_uuid 是一样的,我们也需要修改。 vim /var/lib/mysql/auto.cnf

1.3.2、server_id报错
这应该就是各位大牛设置server_id的时候不小心设置相同的id了,修改过来就行,步骤在上面的配置中。
1.3.3、同步异常解决
这是狗子在操作过程中搞出来的一个错误……
出错的原因是在主库中删除了用户信息,但是在从库中同步的时候失败导致同步停止,下面记录自己的操作(是在进入MySQL的操作且是从库)。
MASTER_LOG_POS
STOP SLAVE; SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1; START SLAVE; SHOW SLAVE STATUS\G;
在数据库中操作时,一定要注意当前所在的数据库是哪个,作为一个良好的实践:在SQL语句前加 USE dbname 。
操作不规范,亲人两行泪……
2、项目中实现
2.1、ShardingJDBC
Sharding-JDBC定位为 轻量级Java框架 ,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以 jar包 形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动, 完全兼容JDBC和各种ORM框架 。
使用Sharding-JDBC可以在程序中轻松的实现数据库 读写分离 。
Sharding-JDBC具有以下几个特点:
适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
下面我们将用ShardingJDBC在项目中实现MySQL的读写分离。
2.2、依赖导入
在pom.xml文件中导入ShardingJDBC的依赖坐标
<!--sharding-jdbc-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>2.3、配置文件
在application.yml中增加数据源的配置
spring:
shardingsphere:
datasource:
names:
master,slave
# 主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.150.100:3306/db_test?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: 123456
# 从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.150.101:3306/db_test?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: 123456
masterslave:
# 读写分离配置,设置负载均衡的模式为轮询
load-balance-algorithm-type: round_robin
# 最终的数据源名称
name: dataSource
# 主库数据源名称
master-data-source-name: master
# 从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave
props:
sql:
show: true #开启SQL显示,默认false
# 覆盖注册bean,后面创建数据源会覆盖前面创建的数据源
main:
allow-bean-definition-overriding: true2.4、测试跑路
这时我们就可以对我们项目中的配置进行一个测试,下面分别调用一个更新接口和一个查询接口,通过查看日志中记录的数据源来判断是否能够按照我们预料中的跑。
更新操作(写操作)

查询操作(读操作)

완료! ! ! 프로그램은 예상대로 정상적으로 성공적으로 실행되었으며 ShardingJDBC를 사용하여 프로젝트에서 데이터베이스 읽기 및 쓰기 분리를 성공적으로 실현했습니다.
위 내용은 SpringBoot 프로젝트에서 MySQL 읽기 및 쓰기 분리를 구현하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7467
7467
 15
1376
52
77
11
46
19
18
20
15
1376
52
77
11
46
19
18
20

 MySQL 사용자와 데이터베이스의 관계
Apr 08, 2025 pm 07:15 PM
MySQL 사용자와 데이터베이스의 관계
Apr 08, 2025 pm 07:15 PM
MySQL 데이터베이스에서 사용자와 데이터베이스 간의 관계는 권한과 테이블로 정의됩니다. 사용자는 데이터베이스에 액세스 할 수있는 사용자 이름과 비밀번호가 있습니다. 권한은 보조금 명령을 통해 부여되며 테이블은 Create Table 명령에 의해 생성됩니다. 사용자와 데이터베이스 간의 관계를 설정하려면 데이터베이스를 작성하고 사용자를 생성 한 다음 권한을 부여해야합니다.
 MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL은 설치가 간단하고 강력하며 데이터를 쉽게 관리하기 쉽기 때문에 초보자에게 적합합니다. 1. 다양한 운영 체제에 적합한 간단한 설치 및 구성. 2. 데이터베이스 및 테이블 작성, 삽입, 쿼리, 업데이트 및 삭제와 같은 기본 작업을 지원합니다. 3. 조인 작업 및 하위 쿼리와 같은 고급 기능을 제공합니다. 4. 인덱싱, 쿼리 최적화 및 테이블 파티셔닝을 통해 성능을 향상시킬 수 있습니다. 5. 데이터 보안 및 일관성을 보장하기위한 지원 백업, 복구 및 보안 조치.
 Redshift Zero ETL과의 RDS MySQL 통합
Apr 08, 2025 pm 07:06 PM
Redshift Zero ETL과의 RDS MySQL 통합
Apr 08, 2025 pm 07:06 PM
데이터 통합 단순화 : AmazonRdsMysQL 및 Redshift의 Zero ETL 통합 효율적인 데이터 통합은 데이터 중심 구성의 핵심입니다. 전통적인 ETL (추출, 변환,로드) 프로세스는 특히 데이터베이스 (예 : AmazonRDSMySQL)를 데이터웨어 하우스 (예 : Redshift)와 통합 할 때 복잡하고 시간이 많이 걸립니다. 그러나 AWS는 이러한 상황을 완전히 변경 한 Zero ETL 통합 솔루션을 제공하여 RDSMYSQL에서 Redshift로 데이터 마이그레이션을위한 단순화 된 거의 실시간 솔루션을 제공합니다. 이 기사는 RDSMYSQL ZERL ETL 통합으로 Redshift와 함께 작동하여 데이터 엔지니어 및 개발자에게 제공하는 장점과 장점을 설명합니다.
 MySQL 사용자 이름 및 비밀번호를 작성하는 방법
Apr 08, 2025 pm 07:09 PM
MySQL 사용자 이름 및 비밀번호를 작성하는 방법
Apr 08, 2025 pm 07:09 PM
MySQL 사용자 이름 및 비밀번호를 작성하려면 : 1. 사용자 이름과 비밀번호를 결정합니다. 2. 데이터베이스에 연결; 3. 사용자 이름과 비밀번호를 사용하여 쿼리 및 명령을 실행하십시오.
 MySQL의 쿼리 최적화는 데이터베이스 성능을 향상시키는 데 필수적입니다. 특히 대규모 데이터 세트를 처리 할 때
Apr 08, 2025 pm 07:12 PM
MySQL의 쿼리 최적화는 데이터베이스 성능을 향상시키는 데 필수적입니다. 특히 대규모 데이터 세트를 처리 할 때
Apr 08, 2025 pm 07:12 PM
1. 올바른 색인을 사용하여 스캔 한 데이터의 양을 줄임으로써 데이터 검색 속도를 높이십시오. 테이블 열을 여러 번 찾으면 해당 열에 대한 인덱스를 만듭니다. 귀하 또는 귀하의 앱이 기준에 따라 여러 열에서 데이터가 필요한 경우 복합 인덱스 2를 만듭니다. 2. 선택을 피하십시오 * 필요한 열만 선택하면 모든 원치 않는 열을 선택하면 더 많은 서버 메모리를 선택하면 서버가 높은 부하 또는 주파수 시간으로 서버가 속도가 느려지며, 예를 들어 Creation_at 및 Updated_at 및 Timestamps와 같은 열이 포함되어 있지 않기 때문에 쿼리가 필요하지 않기 때문에 테이블은 선택을 피할 수 없습니다.
 산성 특성 이해 : 신뢰할 수있는 데이터베이스의 기둥
Apr 08, 2025 pm 06:33 PM
산성 특성 이해 : 신뢰할 수있는 데이터베이스의 기둥
Apr 08, 2025 pm 06:33 PM
데이터베이스 산 속성에 대한 자세한 설명 산 속성은 데이터베이스 트랜잭션의 신뢰성과 일관성을 보장하기위한 일련의 규칙입니다. 데이터베이스 시스템이 트랜잭션을 처리하는 방법을 정의하고 시스템 충돌, 전원 중단 또는 여러 사용자의 동시 액세스가 발생할 경우에도 데이터 무결성 및 정확성을 보장합니다. 산 속성 개요 원자력 : 트랜잭션은 불가분의 단위로 간주됩니다. 모든 부분이 실패하고 전체 트랜잭션이 롤백되며 데이터베이스는 변경 사항을 유지하지 않습니다. 예를 들어, 은행 송금이 한 계정에서 공제되지만 다른 계정으로 인상되지 않은 경우 전체 작업이 취소됩니다. BeginTransaction; updateAccountssetBalance = Balance-100WH
 Navicat에서 데이터베이스 비밀번호를 검색 할 수 있습니까?
Apr 08, 2025 pm 09:51 PM
Navicat에서 데이터베이스 비밀번호를 검색 할 수 있습니까?
Apr 08, 2025 pm 09:51 PM
Navicat 자체는 데이터베이스 비밀번호를 저장하지 않으며 암호화 된 암호 만 검색 할 수 있습니다. 솔루션 : 1. 비밀번호 관리자를 확인하십시오. 2. Navicat의 "비밀번호 기억"기능을 확인하십시오. 3. 데이터베이스 비밀번호를 재설정합니다. 4. 데이터베이스 관리자에게 문의하십시오.
 마스터 SQL 한계 절 항의 : 쿼리의 행 수 제어
Apr 08, 2025 pm 07:00 PM
마스터 SQL 한계 절 항의 : 쿼리의 행 수 제어
Apr 08, 2025 pm 07:00 PM
sqllimit 절 : 쿼리 결과의 행 수를 제어하십시오. SQL의 한계 절은 쿼리에서 반환 된 행 수를 제한하는 데 사용됩니다. 이것은 대규모 데이터 세트, 페이지 진화 디스플레이 및 테스트 데이터를 처리 할 때 매우 유용하며 쿼리 효율성을 효과적으로 향상시킬 수 있습니다. 구문의 기본 구문 : SelectColumn1, Collect2, ... Fromtable_namelimitnumber_of_rows; 번호_of_rows : 반환 된 행 수를 지정하십시오. 오프셋이있는 구문 : SelectColumn1, Column2, ... Fromtable_namelimitOffset, number_of_rows; 오프셋 : skip
