

상하이 과학 기술 대학 등이 DreamFace 출시: 텍스트만으로 '초현실적인 3D 디지털 인간'을 생성할 수 있음

대형 언어 모델(LLM), 확산(Diffusion) 등 기술의 발전으로 ChatGPT, Midjourney 등의 제품 탄생으로 새로운 AI 열풍이 불었고, 생성 AI도 큰 화제가 되었습니다. 우려.
텍스트나 이미지와 달리 3D세대는 아직 기술 탐구 단계입니다.
2022년 말 구글, 엔비디아, 마이크로소프트가 잇달아 자체 3D 생성 작품을 출시했지만, 대부분이 고급 NeRF(Neural Radiation Field) 암시적 표현을 기반으로 하고 있으며 Unity 등 산업용 3D 소프트웨어와 호환되지 않습니다. , Unreal Engine 및 Maya가 호환되지 않습니다.
기존 솔루션을 통해 Mesh로 표현된 기하학적 맵과 컬러맵으로 변환하더라도 정확도가 부족하고 시각적 품질이 저하되어 영화 및 TV 제작과 게임 제작에 직접 적용할 수 없습니다.

프로젝트 웹사이트: https://sites.google.com/view/dreamface
논문 주소: https://arxiv.org/abs/2304.03117
웹 데모: https://hyperhuman.top
HuggingFace Space: https://huggingface.co/spaces/DEEMOSTECH/ChatAvatar
이러한 문제를 해결하기 위해 Yingmo Technology와 상하이 과학 기술 대학의 R&D 팀은 텍스트 기반의 프로그레시브 3D 생성 프레임워크를 제안했습니다.
이 프레임워크는 CG 제작 표준을 준수하는 외부 데이터 세트(지오메트리 및 PBR 재질 포함)를 도입하고, 텍스트를 기반으로 이 표준을 준수하는 3D 자산을 직접 생성할 수 있는 Production-Ready 3D를 지원하는 최초의 프레임워크입니다. 자산 생성.
텍스트 생성 기반 3D 초현실적 디지털 휴먼을 달성하기 위해 팀은 이 프레임워크를 프로덕션급 3D 디지털 휴먼 데이터 세트와 결합했습니다. 본 작품은 컴퓨터 그래픽 분야 최고 국제 저널인 Transactions on Graphics에 게재 승인을 받았으며, 최고의 국제 컴퓨터 그래픽 컨퍼런스인 SIGGRAPH 2023에서 발표될 예정입니다.
DreamFace에는 주로 기하학 생성, 물리 기반 재료 확산 및 애니메이션 기능 생성의 세 가지 모듈이 포함되어 있습니다.
이전 3D 생성 작업과 비교하여 이 작업의 주요 기여는 다음과 같습니다.
· 최신 시각적 언어 모델과 애니메이션 가능한 물리적 자료를 결합한 새로운 생성 방식인 DreamFace를 제안합니다. 형상, 모양 및 애니메이션 기능을 분리하는 점진적인 학습입니다.
· 잠재 공간과 이미지 공간에서 2단계 최적화를 수행하는 동시에 새로운 물질 확산 모델과 사전 훈련된 모델을 결합하는 이중 채널 모양 생성 설계를 소개합니다.
· BlendShapes 또는 생성된 Personalized BlendShapes를 사용하는 얼굴 자산은 애니메이션화되며 자연스러운 캐릭터 디자인을 위해 DreamFace를 사용하는 방법을 추가로 보여줍니다.
기하학 생성
기하학 생성 모듈은 텍스트 프롬프트를 기반으로 일관된 기하학적 모델을 생성할 수 있습니다. 그러나 얼굴 생성의 경우 이를 감독하고 수렴하기가 어려울 수 있습니다.
따라서 DreamFace는 CLIP(Contrastive Language-Image Pre-Training) 기반의 선택 프레임워크를 제안합니다. 이 프레임워크는 먼저 얼굴 기하학적 매개변수 공간 내에서 무작위로 샘플링된 후보 중에서 가장 좋은 대략적인 기하학적 모델을 선택한 다음 기하학적 세부 사항을 조각하여 머리 모델이 텍스트 단서와 더 일치합니다.
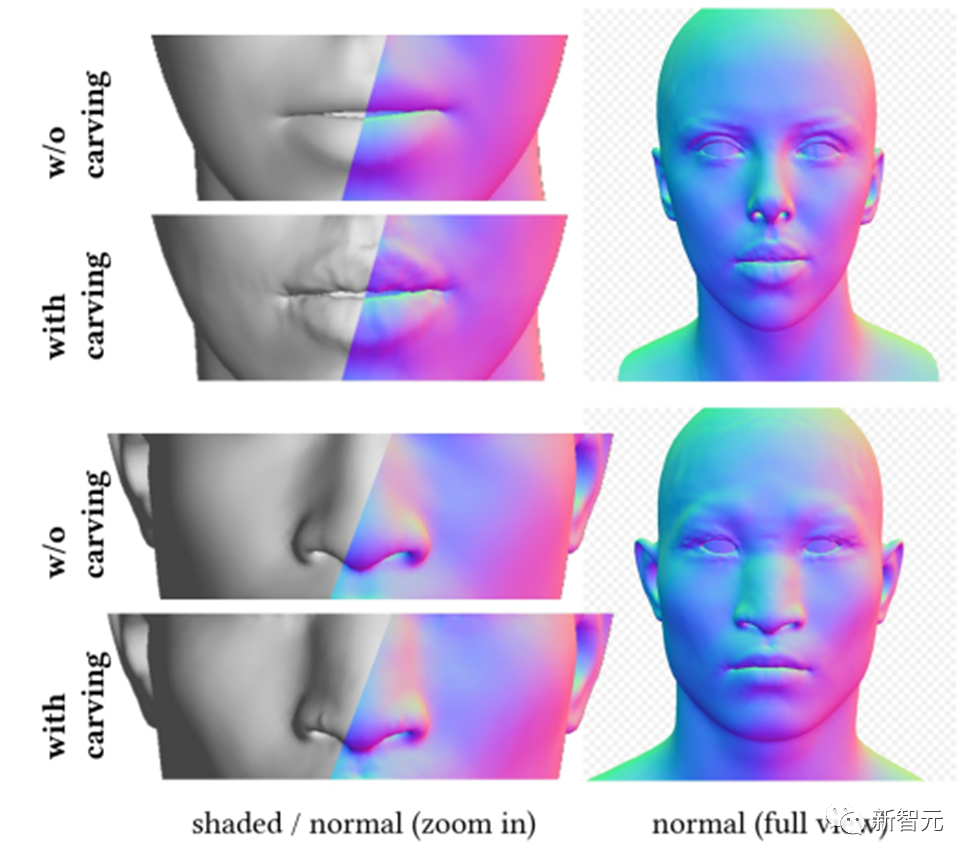
DreamFace는 입력 프롬프트를 기반으로 CLIP 모델을 사용하여 일치 점수가 가장 높은 대략적인 기하학 후보를 선택합니다. 다음으로 DreamFace는 암시적 확산 모델(LDM)을 사용하여 임의의 시야각 및 조명 조건에서 렌더링된 이미지에 대해 SDS(Scored Distillation Sampling) 처리를 수행합니다.
이를 통해 DreamFace는 정점 변위 및 상세한 노멀 맵을 통해 대략적인 기하학 모델에 얼굴 세부 정보를 추가하여 매우 상세한 기하학을 얻을 수 있습니다.
머리 모델과 마찬가지로 DreamFace도 이 프레임워크를 기반으로 헤어스타일과 색상을 선택합니다.
물리 기반 재료 확산 생성
물리 기반 재료 확산 모듈은 예측된 기하학 및 텍스트 단서와 일치하는 얼굴 질감을 예측하도록 설계되었습니다.
먼저 DreamFace는 수집된 대규모 UV 재료 데이터 세트에 대해 사전 훈련된 LDM을 미세 조정하여 두 개의 LDM 확산 모델을 얻었습니다.

DreamFace는 두 가지 확산 프로세스를 조정하는 공동 훈련 체계를 사용합니다. 하나는 UV 텍스처 맵을 직접 제거하고 다른 하나는 렌더링된 이미지를 감독하여 얼굴 UV 맵과 렌더링된 이미지가 올바른지 확인하는 것입니다. of는 텍스트 프롬프트와 일치합니다.
생성 시간을 단축하기 위해 DreamFace는 거친 질감 잠재력 확산 단계를 채택하여 세부적인 질감 생성에 대한 선험적 잠재력을 제공합니다.
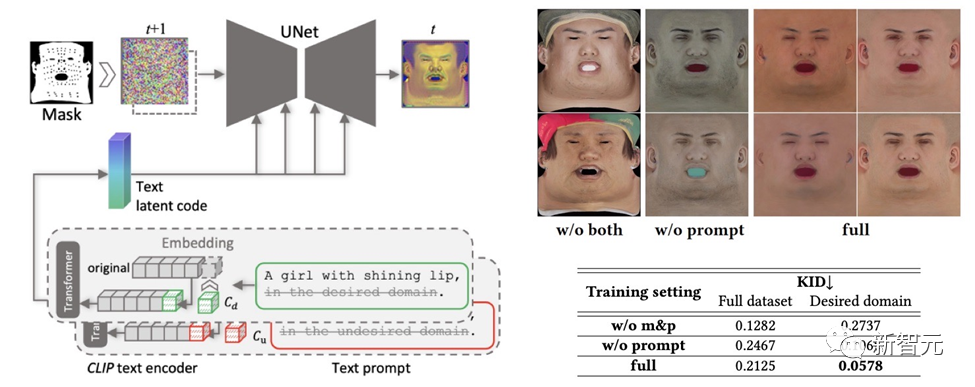
생성된 텍스처 맵에 바람직하지 않은 기능이나 조명 상황이 포함되지 않도록 하면서 다양성을 유지하기 위해 단서 학습 전략이 설계되었습니다.
팀에서는 고품질 확산 맵을 생성하기 위해 두 가지 방법을 사용합니다.
(1) 프롬프트 조정. 손으로 제작한 도메인별 텍스트 큐와 달리 DreamFace는 두 개의 도메인별 연속 텍스트 큐 Cd 및 Cu를 해당 텍스트 큐와 결합합니다. 이는 U-Net 디노이저 훈련 중에 최적화되어 불안정성과 시간 소모적인 프롬프트 수동 작성을 방지합니다.
(2) 비얼굴 부위 마스킹. LDM 노이즈 제거 프로세스는 결과 확산 맵에 원치 않는 요소가 포함되지 않도록 얼굴이 아닌 영역 마스크로 추가로 제한됩니다.
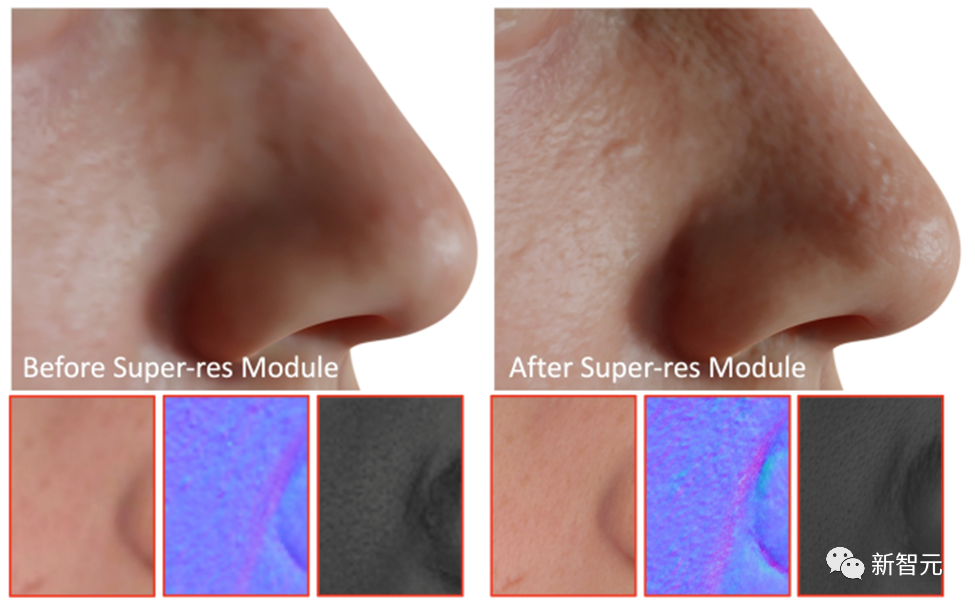
DreamFace는 마지막 단계로 초해상도 모듈을 적용하여 고품질 렌더링을 위한 4K 물리적 기반 텍스처를 생성합니다.

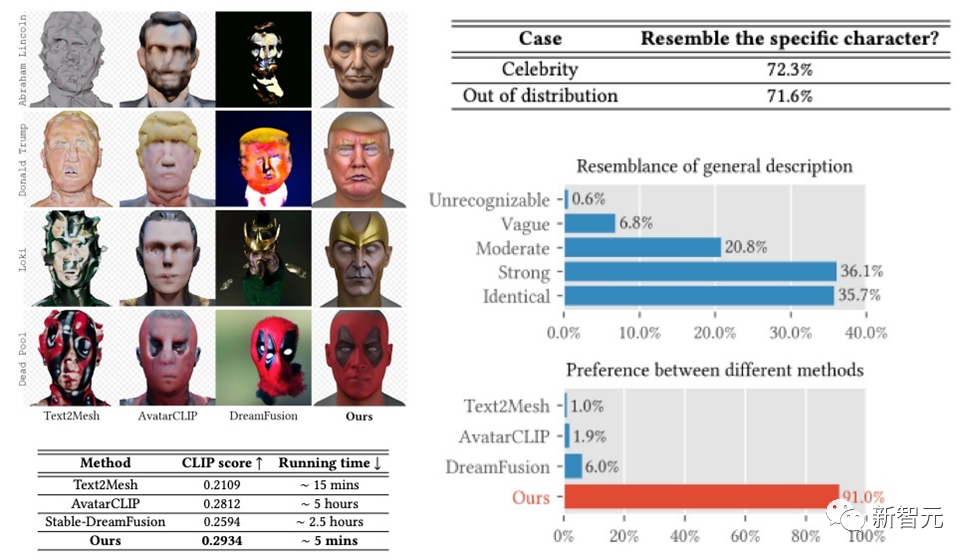
DreamFace 프레임워크는 설명을 기반으로 한 유명인 생성 및 캐릭터 생성에서 매우 좋은 결과를 얻었으며, User Study에서는 이전 작업을 훨씬 능가하는 결과를 얻었습니다. 전작과 비교해 런닝타임 측면에서도 분명한 장점이 있다.
이 외에도 DreamFace는 팁과 스케치를 사용한 텍스처 편집도 지원합니다. 미세 조정된 텍스처 LDM 및 큐를 직접 사용하여 노화 및 메이크업과 같은 전역 편집 효과를 얻을 수 있습니다. 마스크나 스케치를 더욱 조합하여 문신, 턱수염, 모반 등 다양한 효과를 연출할 수 있습니다.

애니메이션 기능 생성
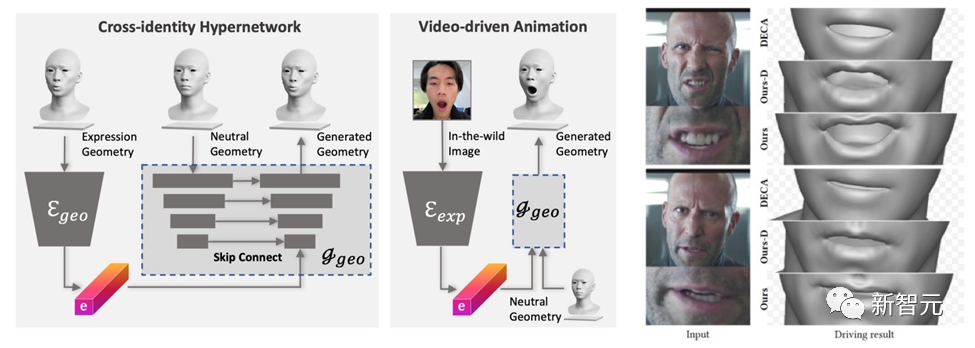
DreamFace에서 생성된 모델에는 애니메이션 기능이 있습니다. BlendShapes 기반 방법과 달리 DreamFace의 신경 얼굴 애니메이션 방법은 고유한 변형을 예측하여 결과 중립 모델에 애니메이션을 적용하여 개인화된 애니메이션을 생성합니다.
먼저, 기하 생성기는 표현의 잠재 공간을 학습하도록 훈련되며, 여기서 디코더는 중립 기하를 조건으로 확장됩니다. 그런 다음 식 인코더는 RGB 이미지에서 식 특징을 추출하도록 추가로 훈련됩니다. 따라서 DreamFace는 단안 RGB 이미지를 사용하여 중립 기하학적 모양을 조건으로 개인화된 애니메이션을 생성할 수 있습니다.
표현 제어를 위해 일반적인 BlendShapes를 사용하는 DECA에 비해 DreamFace의 프레임워크는 미세한 표현 디테일을 제공하고 미세한 디테일로 퍼포먼스를 캡처할 수 있습니다.
결론
이 글에서는 최신 시각 언어 모델, 암시적 확산 모델, 물리 기반 물질 확산 기술을 결합한 텍스트 기반 프로그레시브 3D 생성 프레임워크인 DreamFace를 소개합니다.
DreamFace의 주요 혁신에는 기하학 생성, 물리적 기반 재료 확산 생성 및 애니메이션 기능 생성이 포함됩니다. 전통적인 3D 생성 방법과 비교하여 DreamFace는 더 높은 정확도, 더 빠른 실행 속도 및 더 나은 CG 파이프라인 호환성을 제공합니다.
DreamFace의 프로그레시브 생성 프레임워크는 복잡한 3D 생성 작업을 해결하기 위한 효과적인 솔루션을 제공하며 더욱 유사한 연구 및 기술 개발을 촉진할 것으로 예상됩니다.
또한 물리 기반 소재 확산 세대와 애니메이션 역량 세대를 통해 영화 및 TV 제작, 게임 개발 및 기타 관련 산업에 3D 생성 기술 적용을 촉진할 것입니다.
위 내용은 상하이 과학 기술 대학 등이 DreamFace 출시: 텍스트만으로 '초현실적인 3D 디지털 인간'을 생성할 수 있음의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7328
7328
 9
1626
14
1350
46
1262
25
1209
29
9
1626
14
1350
46
1262
25
1209
29

 상하이 과학 기술 대학 등이 DreamFace 출시: 텍스트만으로 '초현실적인 3D 디지털 인간'을 생성할 수 있음
May 17, 2023 am 08:02 AM
상하이 과학 기술 대학 등이 DreamFace 출시: 텍스트만으로 '초현실적인 3D 디지털 인간'을 생성할 수 있음
May 17, 2023 am 08:02 AM
LLM(Large Language Model), 확산(Diffusion) 등 기술의 발전으로 ChatGPT, Midjourney 등의 제품 탄생으로 새로운 AI 열풍이 불고 있으며, 생성 AI 역시 큰 관심의 대상이 되었습니다. 텍스트나 이미지와 달리 3D 생성은 아직 기술 탐색 단계에 있습니다. 2022년 말 구글, 엔비디아, 마이크로소프트가 잇달아 자체 3D 생성 작업을 시작했지만, 대부분이 NeRF(Advanced Neural Radiation Field) 암시적 표현을 기반으로 하고 있어 산업용 3D 소프트웨어 등의 렌더링 파이프라인과 호환되지 않습니다. 유니티, 언리얼엔진, 마야. 기존의 솔루션을 통해 Mesh로 표현되는 기하학적, 컬러맵으로 변환하더라도 정확도가 떨어지는 문제가 발생합니다.
 젠장, 나는 디지털 동료들에게 둘러싸여 있다! Xiaobing AI 디지털 직원은 제로 샘플 맞춤화 및 즉시 고용을 통해 다시 업그레이드됩니다.
Jul 19, 2024 pm 05:52 PM
젠장, 나는 디지털 동료들에게 둘러싸여 있다! Xiaobing AI 디지털 직원은 제로 샘플 맞춤화 및 즉시 고용을 통해 다시 업그레이드됩니다.
Jul 19, 2024 pm 05:52 PM
"안녕하세요, 저는 이제 막 입사했습니다. 사업에 관해 궁금한 점이 있으면 조언 부탁드립니다!" 뭐, 이 동료들은 모두 대형 모델을 중심으로 한 '디지털 피플'인가요? 이미지 30초, 오디오 10초, 10분만 투자하면 실제 사람과 다를 바 없는 '디지털 동료'를 빠르게 맞춤 설정할 수 있습니다. 실시간으로 사용자와 직접 상호 작용할 수 있으며 통신 운영자 수준에서 고품질, 저지연 오디오 및 비디오 전송이 가능합니다. 이렇습니다: 이것은 Xiaoice가 출시한 최신 "제로 샷 Xiaoice 신경 렌더링, Zero-XNR" 기술로, 1000억 개가 넘는 대규모 모델 기반의 신기술을 기반으로 합니다.
 대형 모델은 디지털 피플에게 인기가 높습니다. 문장 하나를 5분 안에 맞춤 설정할 수 있으며, 춤추는 동안, 호스팅하고, 물건을 배달하는 동안 붙잡을 수 있습니다.
May 08, 2024 pm 08:10 PM
대형 모델은 디지털 피플에게 인기가 높습니다. 문장 하나를 5분 안에 맞춤 설정할 수 있으며, 춤추는 동안, 호스팅하고, 물건을 배달하는 동안 붙잡을 수 있습니다.
May 08, 2024 pm 08:10 PM
단 5분 만에 바로 업무에 나갈 수 있는 3D 디지털 휴먼을 만들 수 있습니다. 이는 대형 모델이 디지털 휴먼 분야에 가져온 최신 충격이다. 이렇게 생성된 디지털 피플이 직접 생방송 방에 입장해 앵커 역할을 할 수 있다는 요구를 한 문장으로 표현합니다. 걸그룹 댄스에 춤을 추는 것도 문제가 아니다. 전체 생산 과정에서 생각나는 대로 말하면 됩니다. 대형 모델은 요구 사항을 자동으로 분해하여 즉시 디자인을 얻고 아이디어를 수정할 수 있습니다. △2배속을 사용하면 더 이상 보스/파티A의 아이디어가 너무 기발할까봐 걱정할 필요가 없습니다. 이러한 Vincent 디지털 휴먼 기술은 Baidu Intelligent Cloud의 최신 릴리스에서 비롯됩니다. 말하든 말든 이제는 디지털 사람들이 단번에 사용할 수 있는 문턱을 낮춰야 할 때다. 이런 아티팩트 소식을 듣고 저희는 평소대로 바로 내부 테스트 자격을 확보했습니다. 자세한 내용을 살짝 살펴보겠습니다~ 5분 안에 3D 디지털맨이 직접 업무에 임합니다.
 Unity Greater China의 플랫폼 기술 이사 Yang Dong: 메타버스에서 디지털 휴먼 여정의 시작
Apr 08, 2023 pm 06:11 PM
Unity Greater China의 플랫폼 기술 이사 Yang Dong: 메타버스에서 디지털 휴먼 여정의 시작
Apr 08, 2023 pm 06:11 PM
메타버스 콘텐츠 구축의 초석인 디지털 피플은 구현되고 지속 가능하게 개발될 수 있는 메타버스 세분화를 위한 가장 초기의 성숙한 시나리오로, 현재 가상 아이돌, 전자상거래 배송, TV 호스팅, 가상 앵커 등의 상용 애플리케이션이 인정받고 있습니다. 공개. 메타버스의 세계에서 가장 핵심적인 콘텐츠 중 하나는 바로 디지털 휴먼이다. 왜냐하면 디지털 휴먼은 메타버스 속 현실 세계의 인간의 '화신'일 뿐만 아니라, 우리가 Metaverse에서는 다양한 상호작용을 수행합니다. 사실적인 디지털 휴먼 캐릭터를 생성하고 렌더링하는 것이 컴퓨터 그래픽에서 가장 어려운 문제 중 하나라는 것은 잘 알려져 있습니다. 최근 51CTO가 주최한 MetaCon Metaverse Technology Conference "Games and AI Interaction" 지점에서 Unity 중화권 플랫폼 기술 이사 Yang Dong이 일련의 데모 시연을 했습니다.
 디지털 휴먼이 아시안 게임의 주요 횃불을 밝히고, 이 ICCV 논문에서 Ant의 생성 AI 블랙 기술을 공개합니다.
Sep 29, 2023 pm 11:57 PM
디지털 휴먼이 아시안 게임의 주요 횃불을 밝히고, 이 ICCV 논문에서 Ant의 생성 AI 블랙 기술을 공개합니다.
Sep 29, 2023 pm 11:57 PM
디지털 휴먼을 열면 생성 AI로 가득 차게 됩니다. 9월 23일 저녁, 항저우 아시안게임 개막식에서 주성화에 점화된 수억 명의 온라인 디지털 성화봉송 주자들이 첸탕강에 모인 '작은 불꽃'이 디지털 휴먼의 모습을 형상화했다. . 이어 디지털휴먼 성화봉송 주자와 현장의 여섯 번째 성화봉송 주자가 함께 성화대에 올라 메인 성화를 함께 점화한 것이 개막식의 핵심 아이디어로 디지털-실제 상호 연결된 성화 점화 형식이 화제가 됐다. , 사람들의 관심을 불러일으킵니다. 재작성된 내용: 개막식의 핵심 아이디어인 디지털 리얼리티 인터넷의 성화 조명 방식은 열띤 토론을 불러일으키고 사람들의 관심을 끌었습니다. 디지털 휴먼 점화는 수억 명의 사람들이 참여한 전례 없는 이니셔티브입니다. 다수의 첨단 및 복잡한 기술. 가장 중요한 질문 중 하나는 어떻게
 대형 모델을 통한 인간-컴퓨터 대화형 대화
Apr 11, 2023 pm 07:27 PM
대형 모델을 통한 인간-컴퓨터 대화형 대화
Apr 11, 2023 pm 07:27 PM
서론: 대화 기술은 디지털 인간 상호 작용의 핵심 기능 중 하나입니다. 이번 공유는 주로 Baidu PLATO와 관련된 연구 개발 및 응용에서 시작하여 대화 시스템에 대한 대형 모델의 영향과 디지털 인간을 위한 몇 가지 기회에 대해 이야기합니다. 이번 공유의 제목은 '대형 모델로 구동되는 인간-컴퓨터 상호작용 대화'입니다. 오늘의 소개는 다음과 같은 점에서 시작됩니다: 대화 시스템 개요 Baidu PLATO 및 관련 기술 대화 대형 모델 구현, 과제 및 전망 1. 대화 시스템 개요 1. 대화 시스템 개요 일상 생활에서 우리는 종종 작업 중심의 작업과 접하게 됩니다. 모바일 어시스턴트에게 알람 설정을 요청하거나 스마트 스피커에 노래 재생을 요청하는 등의 시스템. 특정 분야에서 이러한 수직적 대화를 위한 기술은 상대적으로 성숙되어 있으며, 대화 이해, 대화 관리, 대화 관리 등 시스템 설계는 일반적으로 모듈식입니다.
 영화 및 TV 드라마 프로모션: Dimension Upgrade, N World와 협력하여 서로 대화할 수 있는 디지털 인간 'Lotus Tower' 제작
Sep 08, 2023 pm 07:01 PM
영화 및 TV 드라마 프로모션: Dimension Upgrade, N World와 협력하여 서로 대화할 수 있는 디지털 인간 'Lotus Tower' 제작
Sep 08, 2023 pm 07:01 PM
좋아하는 영화나 TV 시리즈의 등장인물과 대화하는 것이 어떨지 상상해 본 적이 있나요? "뇌 속의 작은 극장"에서만 할 수 있었던 일이 이제 실제로 가능해졌습니다. 최근에는 환루이 센츄리(Huanrui Century)가 제작한 "로터스(Lotus)"가 제작되었습니다! 타워'가 공중파를 강타하며 여름 드라마 시청 열풍을 일으켰다. N월드의 기술 지원을 받아 대화형 AI 디지털 휴먼 캐릭터가 '로터스 타워' 시리즈 캐릭터에 맞게 맞춤화됐다. 디지털 휴먼이 영화와 TV 시리즈의 홍보와 배급에 활용된 것은 이번이 처음이다. , 시청자가 시리즈를 시청하면서 다른 것을 얻을 수 있습니다. 환루이센추리는 국내 영화 및 TV 문화 산업을 선도하는 그룹이다. 영화 및 TV 드라마 제작 측면에서 우리는 다양한 고품질 콘텐츠 제작을 핵심으로 고집하고, 산업화되고 체계적인 제작 능력을 바탕으로 약 100편에 달하는 TV 드라마 및 온라인 드라마를 제작하고 누적 클릭 수는 1,000억 개가 넘습니다. 아티스트 매니지먼트 측면에서
 AI 디지털 휴먼 기술: 비디오 산업에 힘을 실어주고 미래의 문을 열어드립니다.
Dec 20, 2023 pm 05:25 PM
AI 디지털 휴먼 기술: 비디오 산업에 힘을 실어주고 미래의 문을 열어드립니다.
Dec 20, 2023 pm 05:25 PM
2023년 중국의 주요 전자상거래 플랫폼은 다수의 생방송 방을 출시할 예정이며, 이 생방송 방에는 '디지털 휴먼' 앵커가 탑재될 예정입니다. 이들 앵커는 실제 사람의 표정과 움직임을 고도로 모방할 수 있을 뿐만 아니라 24시간 상품 라이브 스트리밍이 가능해 소비자의 쇼핑 질문에 원활하게 답변할 수 있다. 관련 통계에 따르면 현재 중국에는 비디오 공연 및 기타 활동에 종사하는 앵커 계정이 거의 1억 4천만 개에 달하며, 그 중 가상 '디지털 피플'의 비율이 40%에 달합니다. , 2030년까지 우리나라의 가상 디지털 휴먼 시장 규모는 2,700억 위안에 이를 것으로 예상됩니다. Xinyi Technology의 Han Kun 회장이 중국 최고의 인공 지능인 디지털 휴먼 이미지에 대한 기자 회견을 주재했습니다.
