

Python에서 ClickHouse를 사용하는 방법

클릭하우스는 최근 많은 관심을 받고 있는 오픈소스 컬럼형 데이터베이스(DBMS)로 주로 데이터 온라인 분석(OLAP) 분야에서 활용되며 2016년 오픈소스로 공개됐다. 현재 국내 커뮤니티는 호황을 누리고 있으며 주요 제조업체가 이를 대규모로 추적하여 사용하고 있습니다.
Toutiao는 사용자 행동 분석을 위해 내부적으로 ClickHouse를 사용합니다. 내부적으로는 총 수천 개의 ClickHouse 노드가 있으며, 단일 클러스터에는 최대 1,200개의 노드가 있으며, 총 데이터 양은 수십 PB이며 일일 증가량은 증가합니다. 데이터 용량은 약 300TB입니다.
Tencent는 게임 데이터 분석을 위해 내부적으로 ClickHouse를 사용하고 있으며 이에 대한 완벽한 모니터링 및 운영 시스템을 구축했습니다.
씨트립은 2018년 7월 시범운영을 시작으로 내부 업무의 80%를 ClickHouse 데이터베이스로 이전했습니다. 데이터는 매일 10억 이상 증가하고 쿼리 요청은 거의 100만 건에 달합니다.
Kuaishou도 내부적으로 ClickHouse를 사용하고 있으며 총 저장 용량은 약 10PB이며 매일 200TB가 추가되며 쿼리의 90%가 3S 미만입니다.
해외에서 Yandex는 사용자 클릭 행동을 분석하는 데 사용되는 수백 개의 노드를 보유하고 있으며 CloudFlare 및 Spotify와 같은 선도적인 회사에서도 이를 사용하고 있습니다.
ClickHouse는 원래 세계에서 두 번째로 큰 웹 분석 플랫폼인 YandexMetrica를 개발하기 위해 개발되었습니다. 수년간 시스템의 핵심 구성요소로 지속적으로 사용되어 왔습니다.
1. ClickHouse의 사용 관행에 대해
먼저 몇 가지 기본 개념을 검토해 보겠습니다.
OLTP: 추가, 삭제, 수정 및 쿼리를 주로 수행하는 전통적인 관계형 데이터베이스입니다. , 은행 시스템, 전자상거래 시스템 등 거래 일관성을 강조합니다.OLTP:是传统的关系型数据库,主要操作增删改查,强调事务一致性,比如银行系统、电商系统。OLAP
OLAP: 주로 데이터를 읽고 복잡한 데이터 분석을 수행하며 기술적 의사결정 지원에 중점을 두고 직관적이고 간단한 결과를 제공하는 웨어하우스형 데이터베이스입니다.
1.1 ClickHouse는 데이터 웨어하우스 시나리오에 적용됩니다- ClickHouse는 OLAP 시나리오에 더 적합한 열형 데이터베이스입니다.
- 대부분이 읽기 요청입니다
- 데이터는 단일 행이 아닌 상당히 큰 배치(행 1000개 이상)로 업데이트되거나 전혀 업데이트되지 않습니다.
- 데이터베이스에 추가된 데이터는 수정할 수 없습니다.
- 읽기의 경우 데이터베이스에서 꽤 많은 행을 가져오지만 열의 일부만 가져옵니다.
- 넓은 테이블, 즉 각 테이블에 많은 수의 열이 포함됨
- 쿼리가 상대적으로 적음(일반적으로 서버당 초당 수백 개 이하)
- 간단한 쿼리의 경우 약 50밀리초의 지연을 허용합니다.
- 열의 데이터는 비교적 작습니다: 숫자 및 짧은 문자열(예: URL당 60바이트)
- 단일 쿼리를 처리할 때 높은 처리량에 필요(서버당 최대 1초) 수십억 행)
- 트랜잭션이 필요하지 않습니다
- 낮은 데이터 일관성 요구 사항
- 쿼리당 하나의 큰 테이블. 그 사람 빼고는 다 작아요.
- Clickhouse 클라이언트 도구는 dbeaver이며, 공식 웹사이트는 https://dbeaver 입니다. .io/.
- dbeaver는 개발자와 데이터베이스 관리자를 위한 무료 오픈 소스(GPL) 범용 데이터베이스 도구입니다. [바이두 백과사전]
- 이 프로젝트의 핵심 목표는 사용 편의성을 향상시키는 것이므로 데이터베이스 관리 도구를 특별히 설계하고 개발했습니다. 오픈 소스 프레임워크를 기반으로 하는 무료 크로스 플랫폼으로 다양한 확장(플러그인) 작성이 가능합니다.
- JDBC 드라이버가 있는 모든 데이터베이스를 지원합니다.
 아래 그림과 같이 작업 인터페이스 메뉴의 "데이터베이스"를 통해 새 연결을 생성 및 구성하고 ClickHouse 드라이버를 선택하고 다운로드합니다(기본값은 드라이버 없음).
아래 그림과 같이 작업 인터페이스 메뉴의 "데이터베이스"를 통해 새 연결을 생성 및 구성하고 ClickHouse 드라이버를 선택하고 다운로드합니다(기본값은 드라이버 없음).
jdbc:clickhouse://192.168.17.61:8123
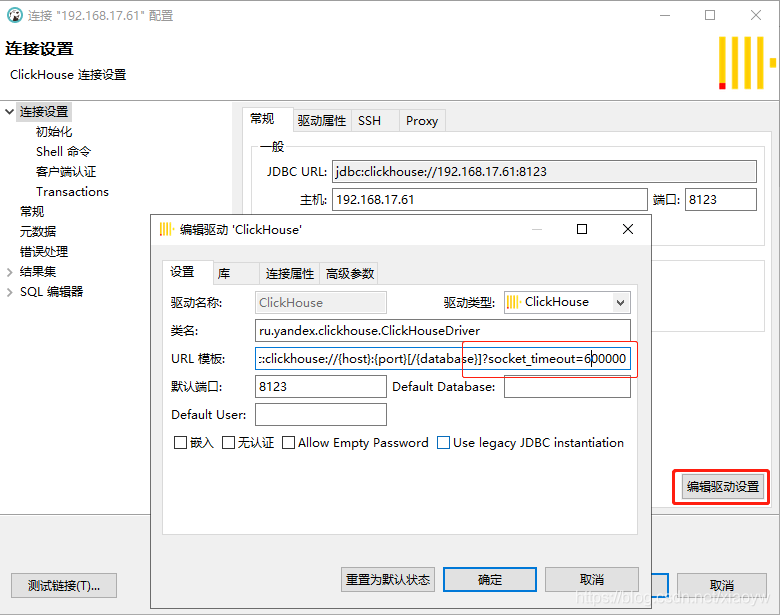 DBeaver를 사용하여 Clickhouse에 쿼리를 연결할 때 가끔 연결 또는 쿼리 시간이 초과되는 경우가 있습니다. 이때 연결 매개변수에 소켓_timeout 매개변수를 추가하고 설정하면 문제를 해결할 수 있습니다.
DBeaver를 사용하여 Clickhouse에 쿼리를 연결할 때 가끔 연결 또는 쿼리 시간이 초과되는 경우가 있습니다. 이때 연결 매개변수에 소켓_timeout 매개변수를 추가하고 설정하면 문제를 해결할 수 있습니다.
jdbc:clickhouse://{host}:{port}[/{database}]?socket_timeout=600000- 1.3. 빅 데이터 응용 실습
- 환경에 대한 간략한 설명:
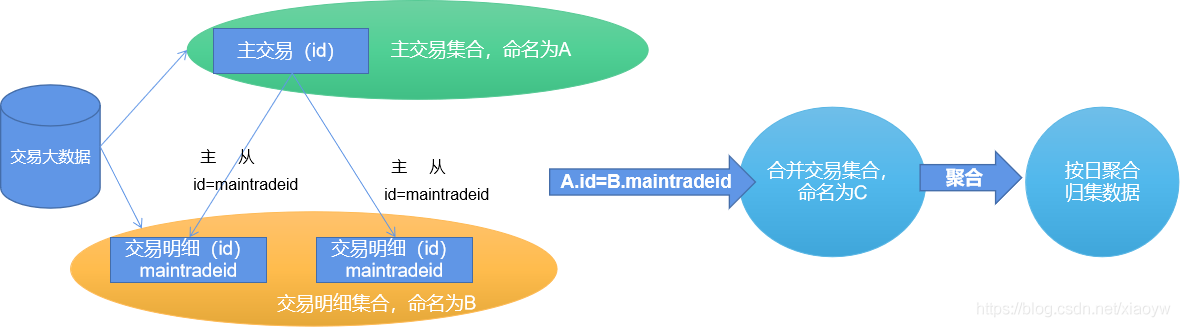 고객의 거래 행태를 분석하기 위해 제한된 자원 하에서 아래 그림과 같이 거래 내역을 날짜별, 거래 시점별로 추출하여 거래 기록으로 정리합니다.
고객의 거래 행태를 분석하기 위해 제한된 자원 하에서 아래 그림과 같이 거래 내역을 날짜별, 거래 시점별로 추출하여 거래 기록으로 정리합니다.
其中,在ClickHouse上,交易数据结构由60个列(字段)组成,截取部分如下所示:
针对频繁出现“would use 10.20 GiB , maximum: 9.31 GiB”等内存不足的情况,基于ClickHouse的SQL,编写了提取聚合数据集SQL语句,如下所示。
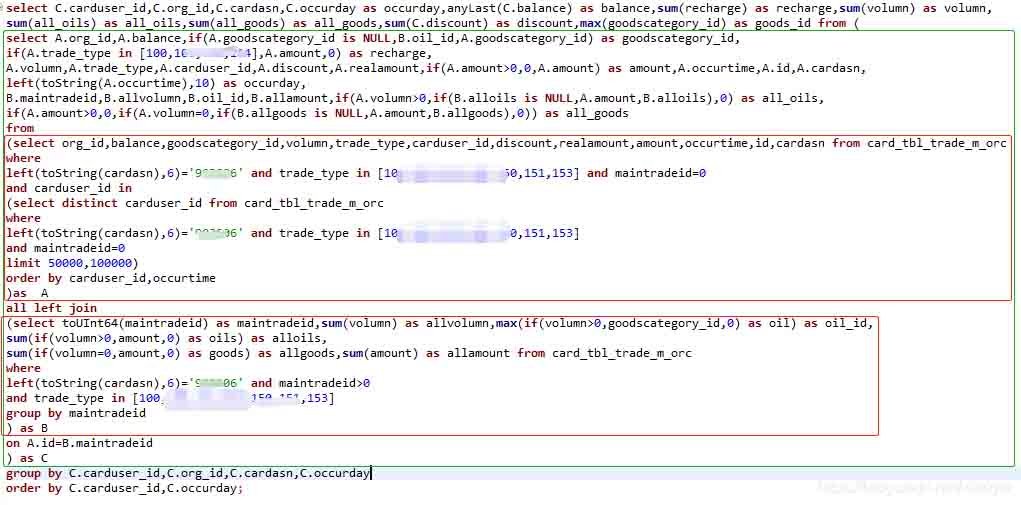
大约60s返回结果,如下所示:

2. Python使用ClickHouse实践
2.1. ClickHouse第三方Python驱动clickhouse_driver
ClickHouse没有提供官方Python接口驱动,常用第三方驱动接口为clickhouse_driver,可以使用pip方式安装,如下所示:
pip install clickhouse_driver
Collecting clickhouse_driver
Downloading https://files.pythonhosted.org/packages/88/59/c570218bfca84bd0ece896c0f9ac0bf1e11543f3c01d8409f5e4f801f992/clickhouse_driver-0.2.1-cp36-cp36m-win_amd64.whl (173kB)
100% |████████████████████████████████| 174kB 27kB/s
Collecting tzlocal<3.0 (from clickhouse_driver)
Downloading https://files.pythonhosted.org/packages/5d/94/d47b0fd5988e6b7059de05720a646a2930920fff247a826f61674d436ba4/tzlocal-2.1-py2.py3-none-any.whl
Requirement already satisfied: pytz in d:\python\python36\lib\site-packages (from clickhouse_driver) (2020.4)
Installing collected packages: tzlocal, clickhouse-driver
Successfully installed clickhouse-driver-0.2.1 tzlocal-2.1使用的client api不能用了,报错如下:
File "clickhouse_driver\varint.pyx", line 62, in clickhouse_driver.varint.read_varint
File "clickhouse_driver\bufferedreader.pyx", line 55, in clickhouse_driver.bufferedreader.BufferedReader.read_one
File "clickhouse_driver\bufferedreader.pyx", line 240, in clickhouse_driver.bufferedreader.BufferedSocketReader.read_into_buffer
EOFError: Unexpected EOF while reading bytes
Python驱动使用ClickHouse端口9000。
ClickHouse服务器和客户端之间的通信有两种协议:http(端口8123)和本机(端口9000)。DBeaver驱动配置使用jdbc驱动方式,端口为8123。
ClickHouse接口返回数据类型为元组,也可以返回Pandas的DataFrame,本文代码使用的为返回DataFrame。
collection = self.client.query_dataframe(self.query_sql)
2.2. 实践程序代码
由于我本机最初资源为8G内存(现扩到16G),以及实际可操作性,分批次取数据保存到多个文件中,每个文件大约为1G。
# -*- coding: utf-8 -*-
'''
Created on 2021年3月1日
@author: xiaoyw
'''
import pandas as pd
import json
import numpy as np
import datetime
from clickhouse_driver import Client
#from clickhouse_driver import connect
# 基于Clickhouse数据库基础数据对象类
class DB_Obj(object):
'''
192.168.17.61:9000
ebd_all_b04.card_tbl_trade_m_orc
'''
def __init__(self, db_name):
self.db_name = db_name
host='192.168.17.61' #服务器地址
port ='9000' #'8123' #端口
user='***' #用户名
password='***' #密码
database=db_name #数据库
send_receive_timeout = 25 #超时时间
self.client = Client(host=host, port=port, database=database) #, send_receive_timeout=send_receive_timeout)
#self.conn = connect(host=host, port=port, database=database) #, send_receive_timeout=send_receive_timeout)
def setPriceTable(self,df):
self.pricetable = df
def get_trade(self,df_trade,filename):
print('Trade join price!')
df_trade = pd.merge(left=df_trade,right=self.pricetable[['occurday','DIM_DATE','END_DATE','V_0','V_92','V_95','ZDE_0','ZDE_92',
'ZDE_95']],how="left",on=['occurday'])
df_trade.to_csv(filename,mode='a',encoding='utf-8',index=False)
def get_datas(self,query_sql):
n = 0 # 累计处理卡客户数据
k = 0 # 取每次DataFrame数据量
batch = 100000 #100000 # 分批次处理
i = 0 # 文件标题顺序累加
flag=True # 数据处理解释标志
filename = 'card_trade_all_{}.csv'
while flag:
self.query_sql = query_sql.format(n, n+batch)
print('query started')
collection = self.client.query_dataframe(self.query_sql)
print('return query result')
df_trade = collection #pd.DataFrame(collection)
i=i+1
k = len(df_trade)
if k > 0:
self.get_trade(df_trade, filename.format(i))
n = n + batch
if k == 0:
flag=False
print('Completed ' + str(k) + 'trade details!')
print('Usercard count ' + str(n) )
return n
# 价格变动数据集
class Price_Table(object):
def __init__(self, cityname, startdate):
self.cityname = cityname
self.startdate = startdate
self.filename = 'price20210531.csv'
def get_price(self):
df_price = pd.read_csv(self.filename)
......
self.price_table=self.price_table.append(data_dict, ignore_index=True)
print('generate price table!')
class CardTradeDB(object):
def __init__(self,db_obj):
self.db_obj = db_obj
def insertDatasByCSV(self,filename):
# 存在数据混合类型
df = pd.read_csv(filename,low_memory=False)
# 获取交易记录
def getTradeDatasByID(self,ID_list=None):
# 字符串过长,需要使用'''
query_sql = '''select C.carduser_id,C.org_id,C.cardasn,C.occurday as
......
limit {},{})
group by C.carduser_id,C.org_id,C.cardasn,C.occurday
order by C.carduser_id,C.occurday'''
n = self.db_obj.get_datas(query_sql)
return n
if __name__ == '__main__':
PTable = Price_Table('湖北','2015-12-01')
PTable.get_price()
db_obj = DB_Obj('ebd_all_b04')
db_obj.setPriceTable(PTable.price_table)
CTD = CardTradeDB(db_obj)
df = CTD.getTradeDatasByID()返回本地文件为:
3. 小结一下
ClickHouse运用于OLAP场景时,拥有出色的查询速度,但需要具备大内存支持。Python第三方clickhouse-driver 驱动基本满足数据处理需求,如果能返回Pandas DataFrame最好。
ClickHouse和Pandas聚合都是非常快的,ClickHouse聚合函数也较为丰富(例如文中anyLast(x)返回最后遇到的值),如果能通过SQL聚合的,还是在ClickHouse中完成比较理想,把更小的结果集反馈给Python进行机器学习。
操作ClickHouse删除指定数据
def info_del2(i):
client = click_client(host='地址', port=端口, user='用户名', password='密码',
database='数据库')
sql_detail='alter table SS_GOODS_ORDER_ALL delete where order_id='+str(i)+';'
try:
client.execute(sql_detail)
except Exception as e:
print(e,'删除商品数据失败')在进行数据删除的时候,python操作clickhou和mysql的方式不太一样,这里不能使用以往常用的%s然后添加数据的方式,必须完整的编辑一条语句,如同上面方法所写的一样,传进去的参数统一使用str类型
위 내용은 Python에서 ClickHouse를 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7470
7470
 15
1377
52
77
11
48
19
19
29
15
1377
52
77
11
48
19
19
29

 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
이 기사는 MySQL 데이터베이스의 작동을 소개합니다. 먼저 MySQLworkBench 또는 명령 줄 클라이언트와 같은 MySQL 클라이언트를 설치해야합니다. 1. MySQL-Uroot-P 명령을 사용하여 서버에 연결하고 루트 계정 암호로 로그인하십시오. 2. CreateABase를 사용하여 데이터베이스를 작성하고 데이터베이스를 선택하십시오. 3. CreateTable을 사용하여 테이블을 만들고 필드 및 데이터 유형을 정의하십시오. 4. InsertInto를 사용하여 데이터를 삽입하고 데이터를 쿼리하고 업데이트를 통해 데이터를 업데이트하고 DELETE를 통해 데이터를 삭제하십시오. 이러한 단계를 마스터하고 일반적인 문제를 처리하는 법을 배우고 데이터베이스 성능을 최적화하면 MySQL을 효율적으로 사용할 수 있습니다.
 MySQL 다운로드 파일이 손상되어 설치할 수 없습니다. 수리 솔루션
Apr 08, 2025 am 11:21 AM
MySQL 다운로드 파일이 손상되어 설치할 수 없습니다. 수리 솔루션
Apr 08, 2025 am 11:21 AM
MySQL 다운로드 파일은 손상되었습니다. 어떻게해야합니까? 아아, mySQL을 다운로드하면 파일 손상을 만날 수 있습니다. 요즘 정말 쉽지 않습니다! 이 기사는 모든 사람이 우회를 피할 수 있도록이 문제를 해결하는 방법에 대해 이야기합니다. 읽은 후 손상된 MySQL 설치 패키지를 복구 할 수있을뿐만 아니라 향후에 갇히지 않도록 다운로드 및 설치 프로세스에 대해 더 깊이 이해할 수 있습니다. 파일 다운로드가 손상된 이유에 대해 먼저 이야기합시다. 이에 대한 많은 이유가 있습니다. 네트워크 문제는 범인입니다. 네트워크의 다운로드 프로세스 및 불안정성의 중단으로 인해 파일 손상이 발생할 수 있습니다. 다운로드 소스 자체에도 문제가 있습니다. 서버 파일 자체가 고장 났으며 물론 다운로드하면 고장됩니다. 또한 일부 안티 바이러스 소프트웨어의 과도한 "열정적 인"스캔으로 인해 파일 손상이 발생할 수 있습니다. 진단 문제 : 파일이 실제로 손상되었는지 확인하십시오
 다운로드 후 MySQL을 설치할 수 없습니다
Apr 08, 2025 am 11:24 AM
다운로드 후 MySQL을 설치할 수 없습니다
Apr 08, 2025 am 11:24 AM
MySQL 설치 실패의 주된 이유는 다음과 같습니다. 1. 권한 문제, 관리자로 실행하거나 Sudo 명령을 사용해야합니다. 2. 종속성이 누락되었으며 관련 개발 패키지를 설치해야합니다. 3. 포트 충돌, 포트 3306을 차지하는 프로그램을 닫거나 구성 파일을 수정해야합니다. 4. 설치 패키지가 손상되어 무결성을 다운로드하여 확인해야합니다. 5. 환경 변수가 잘못 구성되었으며 운영 체제에 따라 환경 변수를 올바르게 구성해야합니다. 이러한 문제를 해결하고 각 단계를 신중하게 확인하여 MySQL을 성공적으로 설치하십시오.
 MySQL 설치 후 시작할 수없는 서비스에 대한 솔루션
Apr 08, 2025 am 11:18 AM
MySQL 설치 후 시작할 수없는 서비스에 대한 솔루션
Apr 08, 2025 am 11:18 AM
MySQL이 시작을 거부 했습니까? 당황하지 말고 확인합시다! 많은 친구들이 MySQL을 설치 한 후 서비스를 시작할 수 없다는 것을 알았으며 너무 불안했습니다! 걱정하지 마십시오.이 기사는 침착하게 다루고 그 뒤에있는 마스터 마인드를 찾을 수 있습니다! 그것을 읽은 후에는이 문제를 해결할뿐만 아니라 MySQL 서비스에 대한 이해와 문제 해결 문제에 대한 아이디어를 향상시키고보다 강력한 데이터베이스 관리자가 될 수 있습니다! MySQL 서비스는 시작되지 않았으며 간단한 구성 오류에서 복잡한 시스템 문제에 이르기까지 여러 가지 이유가 있습니다. 가장 일반적인 측면부터 시작하겠습니다. 기본 지식 : 서비스 시작 프로세스 MySQL 서비스 시작에 대한 간단한 설명. 간단히 말해서 운영 체제는 MySQL 관련 파일을로드 한 다음 MySQL 데몬을 시작합니다. 여기에는 구성이 포함됩니다
 MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 성능 최적화는 설치 구성, 인덱싱 및 쿼리 최적화, 모니터링 및 튜닝의 세 가지 측면에서 시작해야합니다. 1. 설치 후 innodb_buffer_pool_size 매개 변수와 같은 서버 구성에 따라 my.cnf 파일을 조정해야합니다. 2. 과도한 인덱스를 피하기 위해 적절한 색인을 작성하고 Execution 명령을 사용하여 실행 계획을 분석하는 것과 같은 쿼리 문을 최적화합니다. 3. MySQL의 자체 모니터링 도구 (showprocesslist, showstatus)를 사용하여 데이터베이스 건강을 모니터링하고 정기적으로 백업 및 데이터베이스를 구성하십시오. 이러한 단계를 지속적으로 최적화함으로써 MySQL 데이터베이스의 성능을 향상시킬 수 있습니다.
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 기본 데이터 저장 및 관리를위한 네트워크 연결없이 실행할 수 있습니다. 그러나 다른 시스템과의 상호 작용, 원격 액세스 또는 복제 및 클러스터링과 같은 고급 기능을 사용하려면 네트워크 연결이 필요합니다. 또한 보안 측정 (예 : 방화벽), 성능 최적화 (올바른 네트워크 연결 선택) 및 데이터 백업은 인터넷에 연결하는 데 중요합니다.
