

Python을 사용하여 사용자 정의 웹 프레임워크를 개발하는 방법

사용자 정의 웹 프레임워크 개발
웹 서버로부터 동적 리소스 요청을 수신하고 동적 리소스 요청을 처리하기 위한 서비스를 웹 서버에 제공합니다. 요청한 리소스 경로의 접미사 이름을 기준으로 결정:
요청한 리소스 경로의 접미사 이름이 .html인 경우 동적 리소스 요청이므로 웹 프레임워크 프로그램에서 처리하도록 합니다.
그렇지 않으면 정적 리소스 요청이므로 웹 서버 프로그램에서 처리하도록 하세요.
1. 웹 서버의 기본 프로그램을 개발합니다
1. 클라이언트 HTTP 요청을 수락합니다(하위 계층은 TCP입니다)
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
from socket import *
import threading
# 开发自己的Web服务器主类
class MyHttpWebServer(object):
def __init__(self, port):
# 创建 HTTP服务的 TCP套接字
server_socket = socket(AF_INET, SOCK_STREAM)
# 设置端口号互用,程序退出之后不需要等待,直接释放端口
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, True)
# 绑定 ip和 port
server_socket.bind(('', port))
# listen使套接字变为了被动连接
server_socket.listen(128)
self.server_socket = server_socket
# 处理请求函数
@staticmethod # 静态方法
def handle_browser_request(new_socket):
# 接受客户端发来的数据
recv_data = new_socket.recv(4096)
# 如果没有数据,那么请求无效,关闭套接字,直接退出
if len(recv_data) == 0:
new_socket.close()
return
# 启动服务器,并接受客户端请求
def start(self):
# 循环并多线程来接收客户端请求
while True:
# accept等待客户端连接
new_socket, ip_port = self.server_socket.accept()
print("客户端ip和端口", ip_port)
# 一个客户端的请求交给一个线程来处理
sub_thread = threading.Thread(target=MyHttpWebServer.handle_browser_request, args=(new_socket, ))
# 设置当前线程为守护线程
sub_thread.setDaemon(True)
sub_thread.start() # 启动子线程
# Web 服务器程序的入口
def main():
web_server = MyHttpWebServer(8080)
web_server.start()
if __name__ == '__main__':
main()2. 요청이 정적 리소스인지 동적 리소스인지 확인합니다
# 对接收的字节数据进行转换为字符数据
request_data = recv_data.decode('utf-8')
print("浏览器请求的数据:", request_data)
request_array = request_data.split(' ', maxsplit=2)
# 得到请求路径
request_path = request_array[1]
print("请求的路径是:", request_path)
if request_path == "/":
# 如果请求路径为根目录,自动设置为:/index.html
request_path = "/index.html"
# 判断是否为:.html 结尾
if request_path.endswith(".html"):
"动态资源请求"
pass
else:
"静态资源请求"
pass정적 리소스를 처리하려면?
"静态资源请求"
# 根据请求路径读取/static 目录中的文件数据,相应给客户端
response_body = None # 响应主体
response_header = None # 响应头的第一行
response_first_line = None # 响应头内容
response_type = 'test/html' # 默认响应类型
try:
# 读取 static目录中相对应的文件数据,rb模式是一种兼容模式,可以打开图片,也可以打开js
with open('static'+request_path, 'rb') as f:
response_body = f.read()
if request_path.endswith('.jpg'):
response_type = 'image/webp'
response_first_line = 'HTTP/1.1 200 OK'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: ' + response_type + '; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 浏览器读取的文件可能不存在
except Exception as e:
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容
# 响应头
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Content-Length:'+str(len(response_body))+'\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 最后都会执行的代码
finally:
# 组成响应数据发送给(客户端)浏览器
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
new_socket.send(response)
# 关闭套接字
new_socket.close()
정적 리소스 요청 확인:
4. 동적 리소스가 있는 경우 수행할 작업
if request_path.endswith(".html"):
"动态资源请求"
# 动态资源的处理交给Web框架来处理,需要把请求参数交给Web框架,可能会有多个参数,采用字典结构
params = {
'request_path': request_path
}
# Web框架处理动态资源请求后,返回一个响应
response = MyFramework.handle_request(params)
new_socket.send(response)
new_socket.close()5. 웹 서버 메인 프레임워크 전체 코드 표시:
new_socket.close()
2. 웹 프레임워크의 메인 프로그램을 개발합니다
1. 요청 경로에 따라 해당 데이터에 동적으로 응답합니다
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
import sys
import time
from socket import *
import threading
import MyFramework
# 开发自己的Web服务器主类
class MyHttpWebServer(object):
def __init__(self, port):
# 创建 HTTP服务的 TCP套接字
server_socket = socket(AF_INET, SOCK_STREAM)
# 设置端口号互用,程序退出之后不需要等待,直接释放端口
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, True)
# 绑定 ip和 port
server_socket.bind(('', port))
# listen使套接字变为了被动连接
server_socket.listen(128)
self.server_socket = server_socket
# 处理请求函数
@staticmethod # 静态方法
def handle_browser_request(new_socket):
# 接受客户端发来的数据
recv_data = new_socket.recv(4096)
# 如果没有数据,那么请求无效,关闭套接字,直接退出
if len(recv_data) == 0:
new_socket.close()
return
# 对接收的字节数据进行转换为字符数据
request_data = recv_data.decode('utf-8')
print("浏览器请求的数据:", request_data)
request_array = request_data.split(' ', maxsplit=2)
# 得到请求路径
request_path = request_array[1]
print("请求的路径是:", request_path)
if request_path == "/":
# 如果请求路径为根目录,自动设置为:/index.html
request_path = "/index.html"
# 判断是否为:.html 结尾
if request_path.endswith(".html"):
"动态资源请求"
# 动态资源的处理交给Web框架来处理,需要把请求参数交给Web框架,可能会有多个参数,采用字典结构
params = {
'request_path': request_path
}
# Web框架处理动态资源请求后,返回一个响应
response = MyFramework.handle_request(params)
new_socket.send(response)
new_socket.close()
else:
"静态资源请求"
# 根据请求路径读取/static 目录中的文件数据,相应给客户端
response_body = None # 响应主体
response_header = None # 响应头的第一行
response_first_line = None # 响应头内容
response_type = 'test/html' # 默认响应类型
try:
# 读取 static目录中相对应的文件数据,rb模式是一种兼容模式,可以打开图片,也可以打开js
with open('static'+request_path, 'rb') as f:
response_body = f.read()
if request_path.endswith('.jpg'):
response_type = 'image/webp'
response_first_line = 'HTTP/1.1 200 OK'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: ' + response_type + '; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 浏览器读取的文件可能不存在
except Exception as e:
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容
# 响应头
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Content-Length:'+str(len(response_body))+'\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 最后都会执行的代码
finally:
# 组成响应数据发送给(客户端)浏览器
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
new_socket.send(response)
# 关闭套接字
new_socket.close()
# 启动服务器,并接受客户端请求
def start(self):
# 循环并多线程来接收客户端请求
while True:
# accept等待客户端连接
new_socket, ip_port = self.server_socket.accept()
print("客户端ip和端口", ip_port)
# 一个客户端的请求交给一个线程来处理
sub_thread = threading.Thread(target=MyHttpWebServer.handle_browser_request, args=(new_socket, ))
# 设置当前线程为守护线程
sub_thread.setDaemon(True)
sub_thread.start() # 启动子线程
# Web 服务器程序的入口
def main():
web_server = MyHttpWebServer(8080)
web_server.start()
if __name__ == '__main__':
main()2. 요청 경로에 해당 응답 데이터가 없으면 404 페이지가 반환되어야 합니다
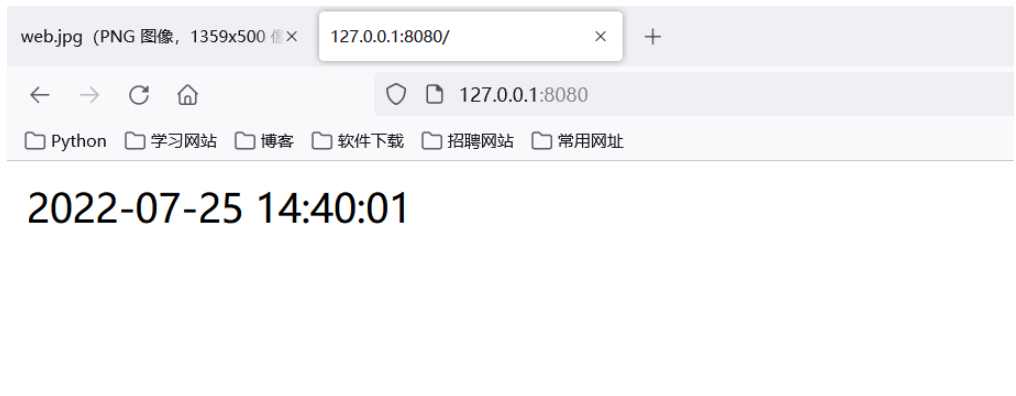 3. 템플릿을 사용하여 응답 콘텐츠 표시
3. 템플릿을 사용하여 응답 콘텐츠 표시
1. 템플릿 index.html을 직접 디자인하고, 일부 위치에서 동적 데이터를 사용하여 교체합니다.
# -*- coding: utf-8 -*-
# @File : MyFramework.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/25 14:05
import time
# 自定义Web框架
# 处理动态资源请求的函数
def handle_request(parm):
request_path = parm['request_path']
if request_path == '/index.html': # 当前请求路径有与之对应的动态响应,当前框架只开发了 index.html的功能
response = index()
return response
else:
# 没有动态资源的数据,返回404页面
return page_not_found()
# 当前 index函数,专门处理index.html的请求
def index():
# 需求,在页面中动态显示当前系统时间
data = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
response_body = data
response_first_line = 'HTTP/1.1 200 OK\r\n'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
response = (response_first_line + response_header + '\r\n' + response_body).encode('utf-8')
return response
def page_not_found():
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容
# 响应头
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
return response2. 교체 방법, 교체할 데이터
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>首页 - 电影列表</title>
<link href="/css/bootstrap.min.css" rel="stylesheet">
<script src="/js/jquery-1.12.4.min.js"></script>
<script src="/js/bootstrap.min.js"></script>
</head>
<body>
<div class="navbar navbar-inverse navbar-static-top ">
<div class="container">
<div class="navbar-header">
<button class="navbar-toggle" data-toggle="collapse" data-target="#mymenu">
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a href="#" class="navbar-brand">电影列表</a>
</div>
<div class="collapse navbar-collapse" id="mymenu">
<ul class="nav navbar-nav">
<li class="active"><a href="">电影信息</a></li>
<li><a href="">个人中心</a></li>
</ul>
</div>
</div>
</div>
<div class="container">
<div class="container-fluid">
<table class="table table-hover">
<tr>
<th>序号</th>
<th>名称</th>
<th>导演</th>
<th>上映时间</th>
<th>票房</th>
<th>电影时长</th>
<th>类型</th>
<th>备注</th>
<th>删除电影</th>
</tr>
{%datas%}
</table>
</div>
</div>
</body>
</html> 4. 프레임워크의 라우팅 목록 기능 개발
4. 프레임워크의 라우팅 목록 기능 개발
1. 향후 새로운 액션 리소스 기능을 개발하려면 다음만 수행하면 됩니다.
a 특수 처리 추가. 기능
2. 라우팅: 요청한 URL 경로와 처리 기능이 직접 매핑됩니다.
3. 라우팅 테이블
요청 경로| /index.html | |
|---|---|
| /user_info.html | |
response_body = response_body.replace('{%datas%}', data)로그인 후 복사 | 주의: 사용자 동적 자원 요청은 해당 처리 기능을 찾기 위해 라우팅 테이블을 탐색하여 완료됩니다.
1. 매개변수가 있는 데코레이터 사용
# 定义路由表
route_list = {
('/index.html', index),
('/user_info.html', user_info)
}
for path, func in route_list:
if request_path == path:
return func()
else:
# 没有动态资源的数据,返回404页面
return page_not_found()2. 처리 기능을 기반으로 경로를 추가하는 기능 추가
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
# 定义路由表
route_list = []
# route_list = {
# ('/index.html', index),
# ('/user_info.html', user_info)
# }
# 定义一个带参数的装饰器
def route(request_path): # 参数就是URL请求
def add_route(func):
# 添加路由表
route_list.append((request_path, func))
@wraps(func)
def invoke(*args, **kwargs):
# 调用指定的处理函数,并返回结果
return func()
return invoke
return add_route
# 处理动态资源请求的函数
def handle_request(parm):
request_path = parm['request_path']
# if request_path == '/index.html': # 当前请求路径有与之对应的动态响应,当前框架只开发了 index.html的功能
# response = index()
# return response
# elif request_path == '/user_info.html': # 个人中心的功能
# return user_info()
# else:
# # 没有动态资源的数据,返回404页面
# return page_not_found()
for path, func in route_list:
if request_path == path:
return func()
else:
# 没有动态资源的数据,返回404页面
return page_not_found()요약: 매개변수가 있는 데코레이터를 사용하면 라우터가 자동으로 경로를 추가할 수 있습니다. 라우팅 테이블.
6. 영화 목록 페이지 개발 사례
1. 쿼리 데이터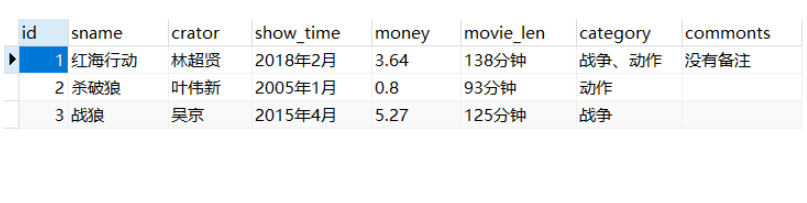 my_web.py
my_web.py
@route('/user_info.html')
MyFramework.py
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
import socket
import sys
import threading
import time
import MyFramework
# 开发自己的Web服务器主类
class MyHttpWebServer(object):
def __init__(self, port):
# 创建HTTP服务器的套接字
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置端口号复用,程序退出之后不需要等待几分钟,直接释放端口
server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
server_socket.bind(('', port))
server_socket.listen(128)
self.server_socket = server_socket
# 处理浏览器请求的函数
@staticmethod
def handle_browser_request(new_socket):
# 接受客户端发送过来的数据
recv_data = new_socket.recv(4096)
# 如果没有收到数据,那么请求无效,关闭套接字,直接退出
if len(recv_data) == 0:
new_socket.close()
return
# 对接受的字节数据,转换成字符
request_data = recv_data.decode('utf-8')
print("浏览器请求的数据:", request_data)
request_array = request_data.split(' ', maxsplit=2)
# 得到请求路径
request_path = request_array[1]
print('请求路径是:', request_path)
if request_path == '/': # 如果请求路径为跟目录,自动设置为/index.html
request_path = '/index.html'
# 根据请求路径来判断是否是动态资源还是静态资源
if request_path.endswith('.html'):
'''动态资源的请求'''
# 动态资源的处理交给Web框架来处理,需要把请求参数传给Web框架,可能会有多个参数,所有采用字典机构
params = {
'request_path': request_path,
}
# Web框架处理动态资源请求之后,返回一个响应
response = MyFramework.handle_request(params)
new_socket.send(response)
new_socket.close()
else:
'''静态资源的请求'''
response_body = None # 响应主体
response_header = None # 响应头
response_first_line = None # 响应头的第一行
# 其实就是:根据请求路径读取/static目录中静态的文件数据,响应给客户端
try:
# 读取static目录中对应的文件数据,rb模式:是一种兼容模式,可以打开图片,也可以打开js
with open('static' + request_path, 'rb') as f:
response_body = f.read()
if request_path.endswith('.jpg'):
response_type = 'image/webp'
response_first_line = 'HTTP/1.1 200 OK'
response_header = 'Server: Laoxiao_Server\r\n'
except Exception as e: # 浏览器想读取的文件可能不存在
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容(字节)
# 响应头 (字符数据)
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Server: Laoxiao_Server\r\n'
finally:
# 组成响应数据,发送给客户端(浏览器)
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
new_socket.send(response)
new_socket.close() # 关闭套接字
# 启动服务器,并且接受客户端的请求
def start(self):
# 循环并且多线程来接受客户端的请求
while True:
new_socket, ip_port = self.server_socket.accept()
print("客户端的ip和端口", ip_port)
# 一个客户端请求交给一个线程来处理
sub_thread = threading.Thread(target=MyHttpWebServer.handle_browser_request, args=(new_socket,))
sub_thread.setDaemon(True) # 设置当前线程为守护线程
sub_thread.start() # 子线程要启动
# web服务器程序的入口
def main():
web_server = MyHttpWebServer(8080)
web_server.start()
if __name__ == '__main__':
main()2.
위 내용은 Python을 사용하여 사용자 정의 웹 프레임워크를 개발하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7498
7498
 15
1377
52
77
11
52
19
19
52
15
1377
52
77
11
52
19
19
52

 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 hadidb : 파이썬의 가볍고 수평 확장 가능한 데이터베이스
Apr 08, 2025 pm 06:12 PM
hadidb : 파이썬의 가볍고 수평 확장 가능한 데이터베이스
Apr 08, 2025 pm 06:12 PM
HADIDB : 가볍고 높은 수준의 확장 가능한 Python 데이터베이스 HadIDB (HADIDB)는 파이썬으로 작성된 경량 데이터베이스이며 확장 수준이 높습니다. PIP 설치를 사용하여 HADIDB 설치 : PIPINSTALLHADIDB 사용자 관리 사용자 만들기 사용자 : createUser () 메소드를 작성하여 새 사용자를 만듭니다. Authentication () 메소드는 사용자의 신원을 인증합니다. Fromhadidb.operationimportuseruser_obj = user ( "admin", "admin") user_obj.
 MySQL Workbench가 Mariadb에 연결할 수 있습니다
Apr 08, 2025 pm 02:33 PM
MySQL Workbench가 Mariadb에 연결할 수 있습니다
Apr 08, 2025 pm 02:33 PM
MySQL Workbench는 구성이 올바른 경우 MariadB에 연결할 수 있습니다. 먼저 커넥터 유형으로 "mariadb"를 선택하십시오. 연결 구성에서 호스트, 포트, 사용자, 비밀번호 및 데이터베이스를 올바르게 설정하십시오. 연결을 테스트 할 때는 마리아드 브 서비스가 시작되었는지, 사용자 이름과 비밀번호가 올바른지, 포트 번호가 올바른지, 방화벽이 연결을 허용하는지 및 데이터베이스가 존재하는지 여부를 확인하십시오. 고급 사용에서 연결 풀링 기술을 사용하여 성능을 최적화하십시오. 일반적인 오류에는 불충분 한 권한, 네트워크 연결 문제 등이 포함됩니다. 오류를 디버깅 할 때 오류 정보를 신중하게 분석하고 디버깅 도구를 사용하십시오. 네트워크 구성을 최적화하면 성능이 향상 될 수 있습니다
 MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
해시 값으로 저장되기 때문에 MongoDB 비밀번호를 Navicat을 통해 직접 보는 것은 불가능합니다. 분실 된 비밀번호 검색 방법 : 1. 비밀번호 재설정; 2. 구성 파일 확인 (해시 값이 포함될 수 있음); 3. 코드를 점검하십시오 (암호 하드 코드 메일).
 MySQL을 해결하는 방법은 로컬 호스트에 연결할 수 없습니다
Apr 08, 2025 pm 02:24 PM
MySQL을 해결하는 방법은 로컬 호스트에 연결할 수 없습니다
Apr 08, 2025 pm 02:24 PM
MySQL 연결은 다음과 같은 이유로 인한 것일 수 있습니다. MySQL 서비스가 시작되지 않았고 방화벽이 연결을 가로 채고 포트 번호가 올바르지 않으며 사용자 이름 또는 비밀번호가 올바르지 않으며 My.cnf의 청취 주소가 부적절하게 구성되어 있습니다. 1. MySQL 서비스가 실행 중인지 확인합니다. 2. MySQL이 포트 3306을들을 수 있도록 방화벽 설정을 조정하십시오. 3. 포트 번호가 실제 포트 번호와 일치하는지 확인하십시오. 4. 사용자 이름과 암호가 올바른지 확인하십시오. 5. my.cnf의 바인드 아드 드레스 설정이 올바른지 확인하십시오.
 MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 기본 데이터 저장 및 관리를위한 네트워크 연결없이 실행할 수 있습니다. 그러나 다른 시스템과의 상호 작용, 원격 액세스 또는 복제 및 클러스터링과 같은 고급 기능을 사용하려면 네트워크 연결이 필요합니다. 또한 보안 측정 (예 : 방화벽), 성능 최적화 (올바른 네트워크 연결 선택) 및 데이터 백업은 인터넷에 연결하는 데 중요합니다.
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 Amazon Athena와 함께 AWS Glue Crawler를 사용하는 방법
Apr 09, 2025 pm 03:09 PM
Amazon Athena와 함께 AWS Glue Crawler를 사용하는 방법
Apr 09, 2025 pm 03:09 PM
데이터 전문가는 다양한 소스에서 많은 양의 데이터를 처리해야합니다. 이것은 데이터 관리 및 분석에 어려움을 겪을 수 있습니다. 다행히도 AWS Glue와 Amazon Athena의 두 가지 AWS 서비스가 도움이 될 수 있습니다.
