
NetEase Cloud Music은 NetEase 항저우 연구소의 결과물입니다. 전문 음악가, DJ, 친구 추천 및 소셜 기능을 기반으로 합니다. 온라인 음악 서비스 재생 목록, 소셜 네트워킹, 유명인 추천 및 음악 지문은 재생 목록, DJ 프로그램, 소셜 네트워킹 및 지리적 위치를 핵심 요소로 삼아 발견 및 공유에 중점을 둡니다. NetEase Cloud Music 공식 웹사이트의 재생 목록 부분을 크롤링하고, NetEase Cloud Music 재생 목록에서 데이터를 얻고, 특정 노래 스타일의 모든 재생 목록을 얻고, 이름, 태그, 소개, 컬렉션 볼륨, 재생 볼륨 및 노래 목록을 가져옵니다. 싱글에 포함된 곡 수와 댓글 수입니다.
크롤링된 데이터 전처리, 전처리된 데이터 분석, 재생목록 볼륨, 노래목록 모음 볼륨, 노래목록 댓글 분석 볼륨, 재생목록 노래 수집 상태, 재생목록 태그 , 재생목록 기여자 등을 분석하고 시각화하여 분석 결과를 보다 직관적으로 반영합니다.
음악을 듣는 것은 오늘날 많은 젊은이들이 자신의 감정을 표현하는 방법 중 하나입니다. NetEase Cloud Music은 인기 있는 음악 플랫폼입니다. 현대 사회의 젊은이들이 직면한 문제와 정서적 압박의 다양한 측면을 이해하기 위해 사용자의 선호도를 파악하고 어떤 종류의 노래 목록이 대중에게 가장 인기 있는지 분석하고 반영할 수도 있습니다. 음악에 대한 대중의 선호와 의견은 창작자의 창작에도 매우 중요한 역할을 합니다. 일반 사용자의 관점에서 보면 재생 목록을 만드는 것은 자신의 음악 라이브러리 컬렉션을 분류하고 관리하는 것을 용이하게 하는 반면, 고품질의 재생 목록을 생성하면 자신의 음악 취향을 부각시킬 수 있습니다. 그리고 댓글은 큰 성취감과 만족감을 줍니다. 음악을 듣는 "재생 목록"은 소비자에게 매우 중요하며 사용자의 청취 경험을 크게 향상시킬 수 있습니다. 음악가, 라디오 진행자 및 기타 유형의 재생 목록 제작자에게 "재생 목록"은 자신의 음악과 작품을 더 잘 전파할 수 있을 뿐만 아니라 팬과 더 잘 소통하고 인기를 높일 수 있습니다.
이 프로젝트는 NetEase Cloud 공식 웹사이트의 중국어 재생 목록 부분에서 데이터를 크롤링합니다. 크롤링 주소는 중국어 재생 목록 - 재생 목록 - NetEase Cloud Music
각 페이지에 들어가 페이지의 각 노래 목록을 가져오고 단일 노래 목록, 노래 목록 이름, 컬렉션 볼륨, 댓글 수, 태그, 소개, 총 노래 수, 재생 볼륨, 포함된 노래 제목 및 기타 데이터를 입력합니다. 모두 웹 페이지의 동일한 div에 저장되며 각 콘텐츠는 선택기를 통해 선택됩니다.
from bs4 import BeautifulSoup
import requests
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
for i in range(0, 1330, 35):
print(i)
time.sleep(2)
url = 'https://music.163.com/discover/playlist/?cat=华语&order=hot&limit=35&offset=' + str(i)#修改这里即可
response = requests.get(url=url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 获取包含歌单详情页网址的标签
ids = soup.select('.dec a')
# 获取包含歌单索引页信息的标签
lis = soup.select('#m-pl-container li')
print(len(lis))
for j in range(len(lis)):
# 获取歌单详情页地址
url = ids[j]['href']
# 获取歌单标题
title = ids[j]['title']
# 获取歌单播放量
play = lis[j].select('.nb')[0].get_text()
# 获取歌单贡献者名字
user = lis[j].select('p')[1].select('a')[0].get_text()
# 输出歌单索引页信息
print(url, title, play, user)
# 将信息写入CSV文件中
with open('playlist.csv', 'a+', encoding='utf-8-sig') as f:
f.write(url + ',' + title + ',' + play + ',' + user + '\n')
from bs4 import BeautifulSoup
import pandas as pd
import requests
import time
df = pd.read_csv('playlist.csv', header=None, error_bad_lines=False, names=['url', 'title', 'play', 'user'])
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
for i in df['url']:
time.sleep(2)
url = 'https://music.163.com' + i
response = requests.get(url=url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 获取歌单标题
title = soup.select('h3')[0].get_text().replace(',', ',')
# 获取标签
tags = []
tags_message = soup.select('.u-tag i')
for p in tags_message:
tags.append(p.get_text())
# 对标签进行格式化
if len(tags) > 1:
tag = '-'.join(tags)
else:
tag = tags[0]
# 获取歌单介绍
if soup.select('#album-desc-more'):
text = soup.select('#album-desc-more')[0].get_text().replace('\n', '').replace(',', ',')
else:
text = '无'
# 获取歌单收藏量
collection = soup.select('#content-operation i')[1].get_text().replace('(', '').replace(')', '')
# 歌单播放量
play = soup.select('.s-fc6')[0].get_text()
# 歌单内歌曲数
songs = soup.select('#playlist-track-count')[0].get_text()
# 歌单评论数
comments = soup.select('#cnt_comment_count')[0].get_text()
# 输出歌单详情页信息
print(title, tag, text, collection, play, songs, comments)
# 将详情页信息写入CSV文件中
with open('music_message.csv', 'a+', encoding='utf-8') as f:
# f.write(title + '/' + tag + '/' + text + '/' + collection + '/' + play + '/' + songs + '/' + comments + '\n')
f.write(title + ',' + tag + ',' + text + ',' + collection + ',' + play + ',' + songs + ',' + comments + '\n')관련 콘텐츠를 해당 .csv 파일에 저장합니다. music_message.csv 파일에는 이름, 태그, 소개, 컬렉션 수가 저장됩니다. , 재생 횟수, 재생 목록에 포함된 노래 수, 댓글 수입니다. 재생 목록 세부 정보 페이지의 주소, 제목, 재생 볼륨 및 기여자 이름은 모두 재생 목록.csv 파일에 저장됩니다. 결과는 그림 2-1과 2-2에 나와 있습니다.
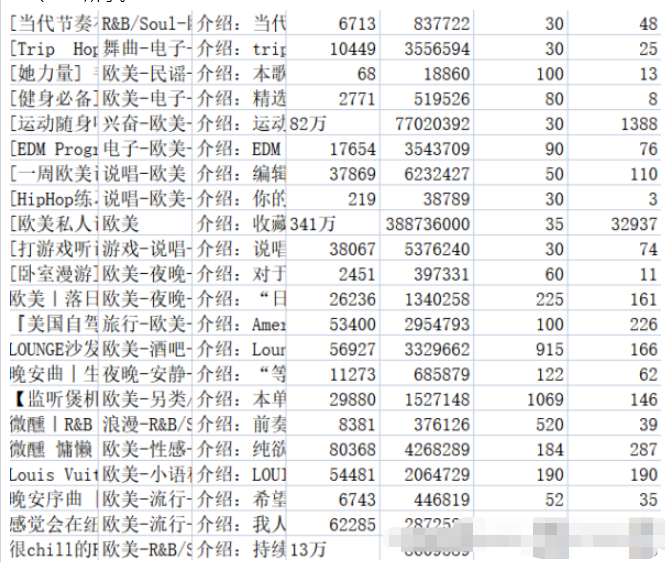
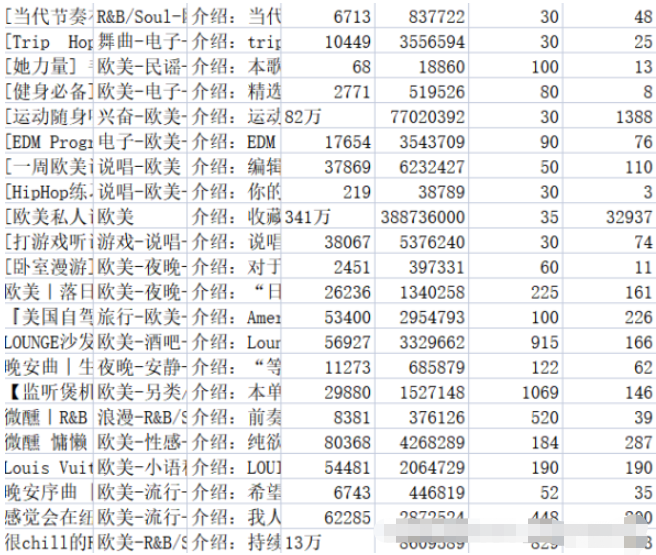
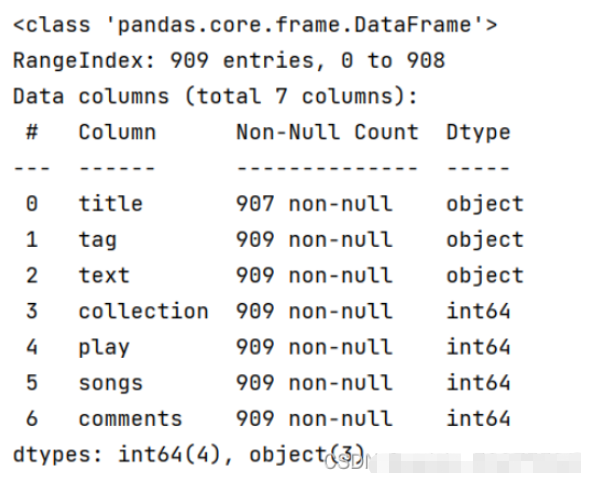
데이터 정리와 관련하여 실제로 데이터 캡처 프로세스의 일부는 이전 부분에서 수행되었습니다. 여기에는 백그라운드에서 반환된 빈 노래 목록 정보, 중복 데이터 중복 제거, 등. . 또한 댓글량 데이터를 통일된 형식으로 통합하는 등 일부 정리가 필요합니다.
댓글 수 데이터에 "10,000" 데이터를 추가하고, 후속 데이터 분석을 용이하게 하기 위해 "10,000"을 "0000"으로 바꾸고, 댓글 수에 통계 오류가 있는 데이터를 다음과 같이 채웁니다. "0". 후속 통계에 참여합니다.
df['collection'] = df['collection'].astype('string').str.strip() df['collection'] = [int(str(i).replace('万','0000')) for i in df['collection']] df['text'] = [str(i)[3:] for i in df['text']] df['comments'] = [0 if '评论' in str(i).strip() else int(i) for i in df['comments']]
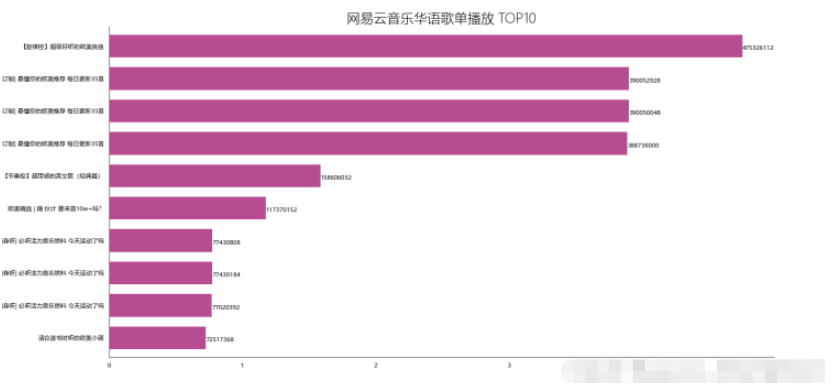
df_play = df[['title','play']].sort_values('play',ascending=False) df_play[:10] df_play = df_play[:10] _x = df_play['title'].tolist() _y = df_play['play'].tolist() df_play = get_matplot(x=_x,y=_y,chart='barh',title='网易云音乐华语歌单播放 TOP10',ha='left',size=8,color=color[0]) df_play

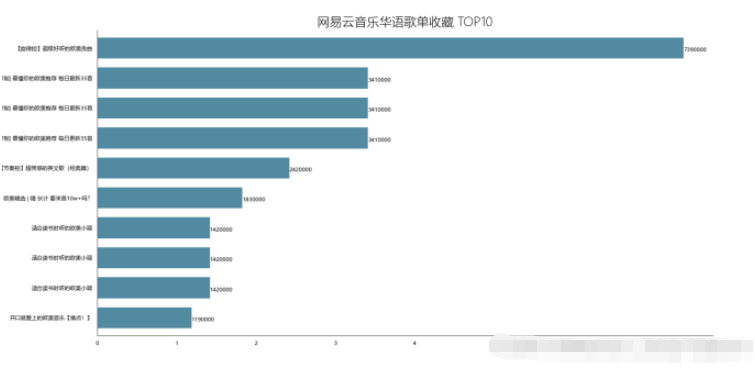
df_col = df[['title','collection']].sort_values('collection',ascending=False) df_col[:10] df_col = df_col[:10] _x = df_col['title'].tolist() _y = df_col['collection'].tolist() df_col = get_matplot(x=_x,y=_y,chart='barh',title='网易云音乐华语歌单收藏 TOP10',ha='left',size=8,color=color[1]) df_col
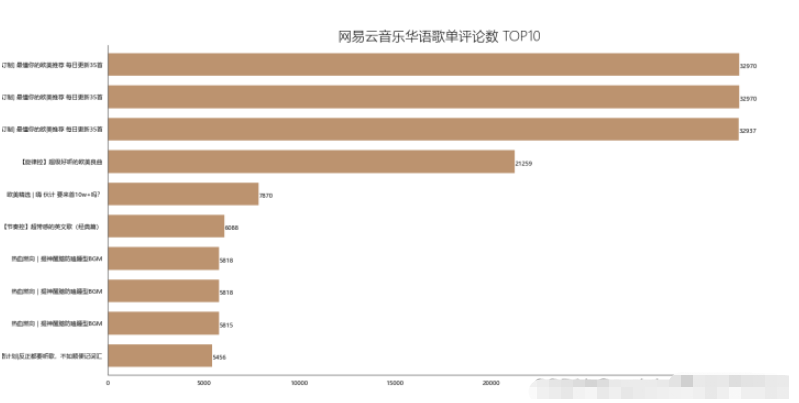
df_com = df[['title','comments']].sort_values('comments',ascending=False) df_com[:10] df_com = df_com[:10] _x = df_com['title'].tolist() _y = df_com['comments'].tolist() df_com = get_matplot(x=_x,y=_y,chart='barh',title='网易云音乐华语歌单评论数 TOP10',ha='left',size=8,color=color[2]) df_com

df_songs = np.log(df['songs']) df_songs df_songs = get_matplot(x=0,y=df_songs,chart='hist',title='华语歌单歌曲收录分布情况',ha='left',size=10,color=color[3]) df_songs
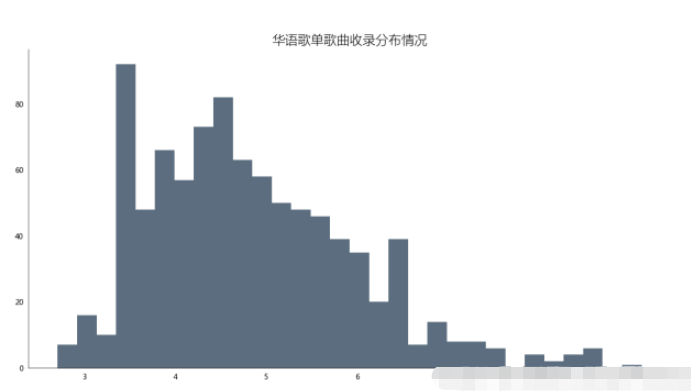
通过对柱形图分析发现,歌单对歌曲的收录情况多数集中在20-60首歌曲,至多超过80首,也存在空歌单现象,但绝大多数歌单收录歌曲均超过10首左右。这次可视化分析将有助于后续创作者更好地收录歌曲到自己的创作歌单中。也能够更受大众欢迎。
def get_tag(df):
df = df['tag'].str.split('-')
datalist = list(set(x for data in df for x in data))
return datalist
df_tag = get_tag(df)
# df_tag
def get_lx(x,i):
if i in str(x):
return 1
else:
return 0
for i in list(df_tag):#这里的df['all_category'].unique()也可以自己用列表构建,我这里是利用了前面获得的
df[i] = df['tag'].apply(get_lx,i=f'{i}')
# df.head()
Series = df.iloc[:,7:].sum().sort_values(0,ascending=False)
df_tag = [tag for tag in zip(Series.index.tolist(),Series.values.tolist())]
df_tag[:10]
df_iex = [index for index in Series.index.tolist()][:20]
df_tag = [tag for tag in Series.values.tolist()][:20]
df_tagiex = get_matplot(x=df_iex,y=df_tag,chart='plot',title='网易云音乐华语歌单标签图',size=10,ha='center',color=color[3])
df_tagiex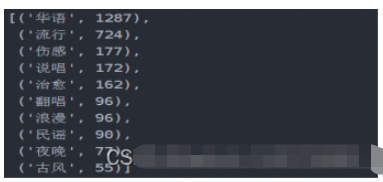
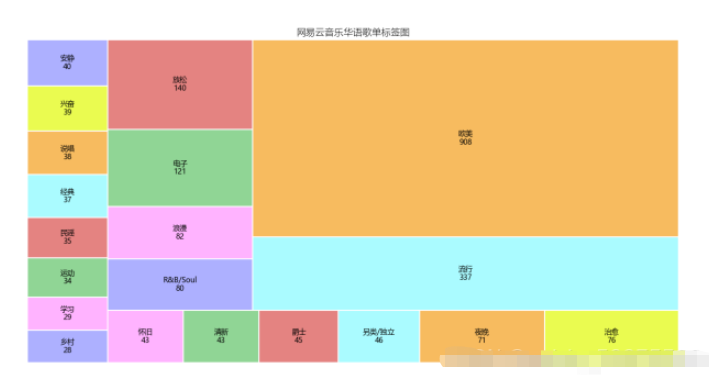
可以通过此标签图看出歌单的风格,可以分析出目前的主流歌曲的情感,以及大众的需求,也网易云音乐用户的音乐偏好,据此可以看出,网易云音乐用户,在音乐偏好上比较多元化:国内流行、欧美流行、电子、 等各种风格均有涉及。
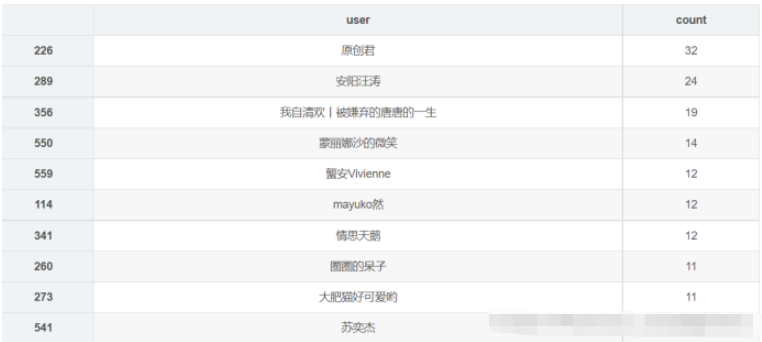
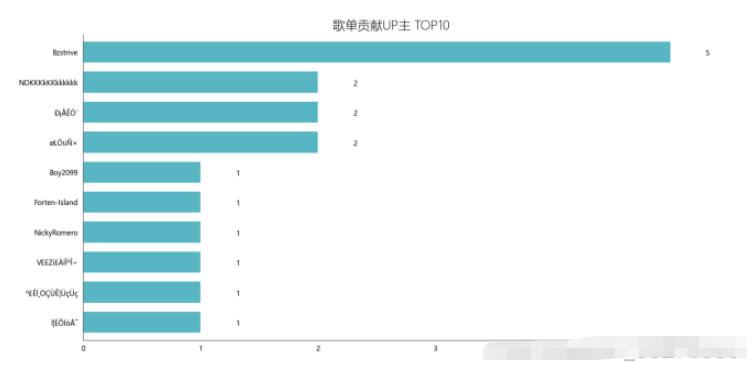
df_user = pd.read_csv('playlist.csv',encoding="unicode_escape",header=0,names=['url','title','play','user'],sep=',') df_user.shape df_user = df_user.iloc[:,1:] df_user['count'] = 0 df_user = df_user.groupby('user',as_index=False)['count'].count() df_user = df_user.sort_values('count',ascending=False)[:10] df_user df_user = df_user[:10] names = df_user['user'].tolist() nums = df_user['count'].tolist() df_u = get_matplot(x=names,y=nums,chart='barh',title='歌单贡献UP主 TOP10',ha='left',size=10,color=color[4]) df_u
import wordcloud
import pandas as pd
import numpy as np
from PIL import Image
data = pd.read_excel('music_message.xlsx')
#根据播放量排序,只取前五十个
data = data.sort_values('play',ascending=False).head(50)
#font_path指明用什么样的字体风格,这里用的是电脑上都有的微软雅黑
w1 = wordcloud.WordCloud(width=1000,height=700,
background_color='black',
font_path='msyh.ttc')
txt = "\n".join(i for i in data['title'])
w1.generate(txt)
w1.to_file('F:\\词云.png')
为了简化代码,构建了通用函数
get_matplot(x,y,chart,title,ha,size,color)
x表示充当x轴数据;
y表示充当y轴数据;
chart表示图标类型,这里分为三种barh、hist、squarify.plot;
ha表示文本相对朝向;
size表示字体大小;
color表示图表颜色;
def get_matplot(x,y,chart,title,ha,size,color):
# 设置图片显示属性,字体及大小
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['font.size'] = size
plt.rcParams['axes.unicode_minus'] = False
# 设置图片显示属性
fig = plt.figure(figsize=(16, 8), dpi=80)
ax = plt.subplot(1, 1, 1)
ax.patch.set_color('white')
# 设置坐标轴属性
lines = plt.gca()
# 设置显示数据
if x ==0:
pass
else:
x.reverse()
y.reverse()
data = pd.Series(y, index=x)
# 设置坐标轴颜色
lines.spines['right'].set_color('none')
lines.spines['top'].set_color('none')
lines.spines['left'].set_color((64/255, 64/255, 64/255))
lines.spines['bottom'].set_color((64/255, 64/255, 64/255))
# 设置坐标轴刻度
lines.xaxis.set_ticks_position('none')
lines.yaxis.set_ticks_position('none')
if chart == 'barh':
# 绘制柱状图,设置柱状图颜色
data.plot.barh(ax=ax, width=0.7, alpha=0.7, color=color)
# 添加标题,设置字体大小
ax.set_title(f'{title}', fontsize=18, fontweight='light')
# 添加歌曲出现次数文本
for x, y in enumerate(data.values):
plt.text(y+0.3, x-0.12, '%s' % y, ha=f'{ha}')
elif chart == 'hist':
# 绘制直方图,设置柱状图颜色
ax.hist(y, bins=30, alpha=0.7, color=(21/255, 47/255, 71/255))
# 添加标题,设置字体大小
ax.set_title(f'{title}', fontsize=18, fontweight='light')
elif chart == 'plot':
colors = ['#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50',
'#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50',
'#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50',
'#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50',
'#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50',
'#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50',
'#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff']
plot = squarify.plot(sizes=y, label=x, color=colors, alpha=1, value=y, edgecolor='white', linewidth=1.5)
# 设置标签大小为1
plt.rc('font', size=6)
# 设置标题大小
plot.set_title(f'{title}', fontsize=13, fontweight='light')
# 除坐标轴
plt.axis('off')
# 除上边框和右边框刻度
plt.tick_params(top=False, right=False)
# 显示图片
plt.show()
#构建color序列
color = [(153/255, 0/255, 102/255),(8/255, 88/255, 121/255),(160/255, 102/255, 50/255),(136/255, 43/255, 48/255),(16/255, 152/255, 168/255),(153/255, 0/255, 102/255)]위 내용은 Python을 사용하여 NetEase Cloud 재생 목록 데이터를 분석하고 시각화하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



