첫 번째 요청이 오면 기본적으로 첫 번째 서버에 접속하고, 두 번째 요청은 두 번째 서버에 접속하고, 세 번째 요청은 세 번째 서버에 접속하게 됩니다. 네 번째 요청은 첫 번째 역을 방문하라는 요청입니다. 다음은 제가 작성한 코드로 구현한 간단한 알고리즘입니다.
public class simplepolling {
/**
* key是ip
*/
public static list <string> ipservice = new linkedlist <>();
static {
ipservice.add("192.168.1.1");
ipservice.add("192.168.1.2");
ipservice.add("192.168.1.3");
}
public static int pos = 0;
public static string getip(){
if(pos >= ipservice.size()){
//防止索引越界
pos = 0;
}
string ip = ipservice.get(pos);
pos ++;
return ip;
}
public static void main(string[] args) {
for (int i = 0; i < 4; i++) {
system.out.println(getip());
}
}
}
로그인 후 복사
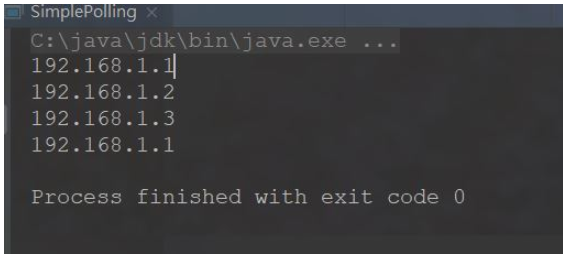
4번의 시뮬레이션 실행 결과는
이때, 더 좋은 성능을 가진 서버(192.168.1.1 등)가 있다면 이걸 원합니다. 서버에서 더 많은 요청을 처리해야 합니다. 이번에는 가중치 확률이 관련되어 있으므로 이 알고리즘을 구현할 수 없습니다. 나중에 설명하는 폴링 업그레이드 버전 알고리즘을 참조하세요.
Weighted Polling Algorithm
이때 앞에 있는 3개의 서버의 가중치를 설정해야 합니다. 예를 들어 첫 번째 서버는 5, 두 번째 서버는 1, 세 번째 서버는 다음과 같습니다. 서버는 1
으로 설정됩니다. 첫 번째 서버 서버
192.168.1.1
5
두 번째 서버
192.168.1.2
1
세 번째 서버
192.168.1.3
1
현재 상위 5개 각 요청은 첫 번째 서버에 액세스하고, 여섯 번째 요청은 두 번째 서버에 액세스하고, 일곱 번째 요청은 세 번째 서버에 액세스합니다.
다음은 제가 제시한 코드 예시입니다.
public class weightpolling {
/**
* key是ip,value是权重
*/
public static map<string, integer> ipservice = new linkedhashmap<>();
static {
ipservice.put("192.168.1.1", 5);
ipservice.put("192.168.1.2", 1);
ipservice.put("192.168.1.3", 1);
}
public static int requestid = 0;
public static int getandincrement() {
return requestid++;
}
public static string getip(){
//获取总的权重
int totalweight =0;
for (integer value : ipservice.values()) {
totalweight+= value;
}
//获取当前轮询的值
int andincrement = getandincrement();
int pos = andincrement% totalweight;
for (string ip : ipservice.keyset()) {
if(pos < ipservice.get(ip)){
return ip;
}
pos -= ipservice.get(ip);
}
return null;
}
public static void main(string[] args) {
for (int i = 0; i < 7; i++) {
system.out.println(getip());
}
}
}
로그인 후 복사
이때 실행 결과는
처음으로 보이는 서버는 5번 실행되었고, 다음 2개의 서버는 1번 실행되었으며, 곧. 아마도 이 알고리즘이 나쁘지 않다고 생각할 수도 있습니다. 실제로 이 알고리즘의 한 가지 단점은 첫 번째 서버의 가중치가 너무 크면 첫 번째 서버에 많은 요청을 실행해야 할 수도 있다는 것입니다. 이 경우 분포가 고르지 않아 특정 서버에 부담을 줄 수 있습니다. 과도한 크기는 붕괴로 이어집니다. 그래서 나중에 이 문제를 해결하기 위해 세 번째 알고리즘을 소개하겠습니다
Smooth Weighted Polling Algorithms
이 알고리즘은 더 복잡할 수도 있습니다. 나중에 관련 정보를 읽었을 때 이해가 되지 않았습니다. 여기에서 예시로 든 서버 구성과 무게는 여전히 위와 같습니다
request
현재 체중 = 본인 체중 + 선택 후 현재 체중
총 중량
현재 최대 중량
반환 IP
선택 후 현재 중량 = 현재 최대 중량 - 총 중량
1
{5,1,1}
7
5
192. 168 .1.1
{-2, 1,3 ,3}
7
3
192.168.1.2
{1,-4,3}
4
{6,-3,4}
7
6
192.16 8.1.1
{-1,-3,4}
5
{4,-2,5}
7
5
192.168 .1.3
{4,-2,-2}
6
{9,-1,-1}
7
9
192.168.1.1
{2,-1,-1}
7
{7,0,0}
7
7
192.168.1.1
{0,0,0}
위 사진에서 볼 수 있듯이, 무게는 첫 번째 서버는 5로 설정되어 있으며 다섯 번째 요청은 아니지만 모두 첫 번째 서버에서 실행되지만 스케줄링 순서는 매우 균일하며 현재 가중치는 {0, 0, 0} 7번째 스케줄링에서 인스턴스의 상태가 초기 상태와 일치하므로 향후에도 스케줄링 작업이 반복될 수 있습니다.
이전 그림의 의미를 명확하게 이해하지 못하실 수도 있습니다. 여기서 간단히 설명하겠습니다.
1. 우선, 전체 무게는 현재 설정된 무게의 합으로 변경되지 않습니다.
2 2장에서. 요청이 들어오면 현재 가중치 선택 값을 기본적으로 {0,0,0}으로 초기화하므로 현재 가중치 값은 {5+0,1+0,1+0}입니다. 5,1,1은 앞서 설정한 각 서버별로 설정된 가중치입니다.
3. 여기서 첫 번째 요청의 최대 가중치는 5라고 결론을 내릴 수 있습니다. 그런 다음 첫 번째 서버 ip로 돌아갑니다
4. 그러면 선택 후 현재 가중치를 설정합니다. 현재 최대 가중치에서 전체 가중치(5-7)를 뺀 값입니다. 이때 선택되지 않은 가중치는 변경되지 않습니다. 현재 가중치의 선택된 가중치를 구합니다.
5. 두 번째 요청이 오면 위의 2, 3, 4단계를 계속합니다. 여기서는 이해가 되지 않습니다. 아래에 자체 Java 코드를 제공하겠습니다. 구현된 알고리즘:
public class polling {
/**
* key是ip,value是权重
*/
public static map <string,integer> ipservice = new linkedhashmap <>();
static {
ipservice.put("192.168.1.1",5);
ipservice.put("192.168.1.2",1);
ipservice.put("192.168.1.3",1);
}
private static map<string,weight> weightmap = new linkedhashmap <>();
public static string getip(){
//计算总的权重
int totalweight = 0;
for (integer value : ipservice.values()) {
totalweight+=value;
}
//首先判断weightmap是否为空
if(weightmap.isempty()){
ipservice.foreach((ip,weight)->{
weight weights = new weight(ip, weight,0);
weightmap.put(ip,weights);
});
}
//给map中得对象设置当前权重
weightmap.foreach((ip,weight)->{
weight.setcurrentweight(weight.getweight() + weight.getcurrentweight());
});
//判断最大权重是否大于当前权重,如果为空或者小于当前权重,则把当前权重赋值给最大权重
weight maxweight = null;
for (weight weight : weightmap.values()) {
if(maxweight ==null || weight.getcurrentweight() > maxweight.getcurrentweight()){
maxweight = weight;
}
}
//最后把当前最大权重减去总的权重
maxweight.setcurrentweight(maxweight.getcurrentweight() - totalweight);
//返回
return maxweight.getip();
}
public static void main(string[] args) {
//模拟轮询7次取ip
for (int i = 0; i < 7; i++) {
system.out.println(getip());
}
}
}
class weight{
/**
* ip
*/
private string ip;
/**
* 设置得权重
*/
private int weight;
/**
* 当前权重
*/
private int currentweight;
public weight(string ip, int weight,int currentweight) {
this.ip = ip;
this.weight = weight;
this.currentweight = currentweight;
}
public string getip() {
return ip;
}
public void setip(string ip) {
this.ip = ip;
}
public int getweight() {
return weight;
}
public void setweight(int weight) {
this.weight = weight;
}
public int getcurrentweight() {
return currentweight;
}
public void setcurrentweight(int currentweight) {
this.currentweight = currentweight;
}
}
로그인 후 복사
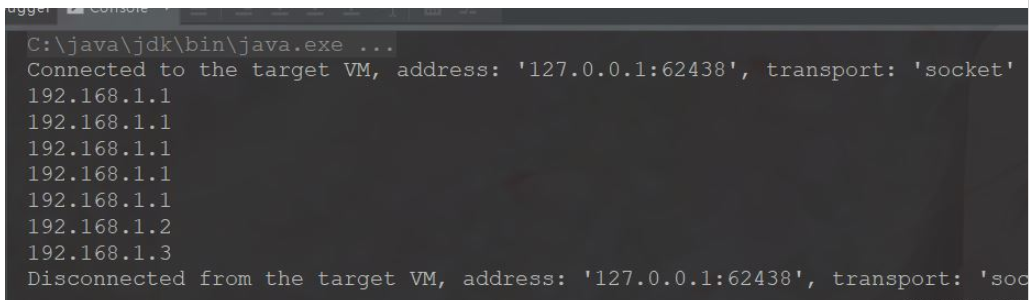
여기 코드의 실행 결과는 다음과 같습니다.
여기의 실행 결과는 설명된 결과와 일치함을 알 수 있습니다. 탁자.
위 내용은 Nginx가 폴링 알고리즘을 구현하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
본 웹사이트의 성명
본 글의 내용은 네티즌들의 자발적인 기여로 작성되었으며, 저작권은 원저작자에게 있습니다. 본 사이트는 이에 상응하는 법적 책임을 지지 않습니다. 표절이나 침해가 의심되는 콘텐츠를 발견한 경우 admin@php.cn으로 문의하세요.
클라우드 서버에서 nginx 도메인 이름을 구성하는 방법 : 클라우드 서버의 공개 IP 주소를 가리키는 레코드를 만듭니다. Nginx 구성 파일에 가상 호스트 블록을 추가하여 청취 포트, 도메인 이름 및 웹 사이트 루트 디렉토리를 지정합니다. Nginx를 다시 시작하여 변경 사항을 적용하십시오. 도메인 이름 테스트 구성에 액세스하십시오. 기타 참고 : HTTPS를 활성화하려면 SSL 인증서를 설치하고 방화벽에서 포트 80 트래픽을 허용하고 DNS 해상도가 적용되기를 기다립니다.
Windows에서 Nginx를 구성하는 방법은 무엇입니까? nginx를 설치하고 가상 호스트 구성을 만듭니다. 기본 구성 파일을 수정하고 가상 호스트 구성을 포함하십시오. 시작 또는 새로 고침 Nginx. 구성을 테스트하고 웹 사이트를보십시오. SSL을 선택적으로 활성화하고 SSL 인증서를 구성하십시오. 포트 80 및 443 트래픽을 허용하도록 방화벽을 선택적으로 설정하십시오.
nginx가 시작되었는지 확인하는 방법 : 1. 명령 줄을 사용하십시오 : SystemCTL 상태 nginx (linux/unix), netstat -ano | Findstr 80 (Windows); 2. 포트 80이 열려 있는지 확인하십시오. 3. 시스템 로그에서 nginx 시작 메시지를 확인하십시오. 4. Nagios, Zabbix 및 Icinga와 같은 타사 도구를 사용하십시오.
Docker Container Startup 단계 : 컨테이너 이미지를 당기기 : "Docker Pull [Mirror Name]"을 실행하십시오. 컨테이너 생성 : "docker"[옵션] [미러 이름] [명령 및 매개 변수]를 사용하십시오. 컨테이너를 시작하십시오 : "Docker start [컨테이너 이름 또는 ID]"를 실행하십시오. 컨테이너 상태 확인 : 컨테이너가 "Docker PS"로 실행 중인지 확인하십시오.
Nginx 서버를 시작하려면 다른 운영 체제에 따라 다른 단계가 필요합니다. Linux/Unix System : Nginx 패키지 설치 (예 : APT-Get 또는 Yum 사용). SystemCTL을 사용하여 nginx 서비스를 시작하십시오 (예 : Sudo SystemCtl start nginx). Windows 시스템 : Windows 바이너리 파일을 다운로드하여 설치합니다. nginx.exe 실행 파일을 사용하여 nginx를 시작하십시오 (예 : nginx.exe -c conf \ nginx.conf). 어떤 운영 체제를 사용하든 서버 IP에 액세스 할 수 있습니다.