

인공지능 발전을 방해하는 8가지 문제


오늘날의 인공지능(AI)은 제한적입니다. 아직 갈 길이 멀다.
일부 AI 연구자들은 시행착오를 통해 컴퓨터가 학습하는 머신러닝 알고리즘이 '신비한 힘'이 되었다는 사실을 발견했습니다.
다양한 유형의 인공 지능
최근 인공 지능(AI)의 발전으로 우리 삶의 여러 측면이 향상되고 있습니다.
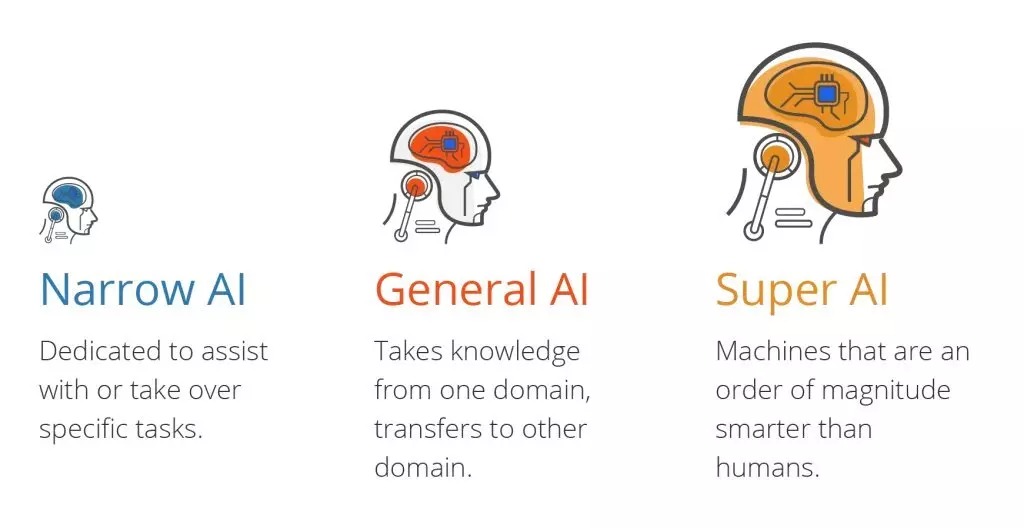
인공지능에는 세 가지 유형이 있습니다.
- 능력의 범위가 좁은 좁은 인공지능(ANI).
- 인간의 능력과 동등한 인공일반지능(AGI).
- 인간보다 지능이 뛰어난 인공슈퍼지능(ASI).
오늘날 인공지능에는 무슨 문제가 있나요?
오늘날의 인공 지능은 주로 데이터 분석, 기계 학습, 인공 신경망 또는 딥 러닝이라고 불리는 통계 학습 모델과 알고리즘에 의해 구동됩니다. 이는 IT 인프라(ML 플랫폼, 알고리즘, 데이터, 계산)와 개발 스택(라이브러리부터 언어, IDE, 워크플로 및 시각화까지)의 조합으로 구현됩니다.
요약하면 다음이 포함됩니다.
- 일부 응용 수학, 확률 이론 및 통계
- 일부 통계 학습 알고리즘, 로지스틱 회귀, 선형 회귀, 의사 결정 트리 및 랜덤 포레스트
- 일부 기계 학습 알고리즘, 감독, 비지도 및 강화
- 정보를 예측하고 분류하기 위해 여러 계층을 통해 입력 데이터를 필터링하는 일부 인공 신경망, 딥 러닝 알고리즘 및 모델
- 일부 최적화된(압축 및 양자화) 훈련된 신경망 모델
- Qualcomm Neural Handling SDK와 같은 일부 통계 패턴 및 추론 ,
- Python 및 R과 같은 일부 프로그래밍 언어.
- PyTorch, ONNX, Apache MXNet, TensorFlow, Caffe2, CNTK, SciKit-Learn 및 Keras와 같은 일부 ML 플랫폼, 프레임워크 및 런타임,
- 일부 통합 개발 환경(IDE ), PyCharm, Microsoft VS Code, Jupyter, MATLAB 등,
- 일부 물리적 서버, 가상 머신, 컨테이너, 특수 하드웨어(예: GPU), 클라우드 기반 컴퓨팅 리소스(가상 머신, 컨테이너 및 서버리스 컴퓨팅 포함) ).
현재 사용되는 대부분의 AI 애플리케이션은 약한 AI라고 불리는 좁은 AI로 분류될 수 있습니다.
모두 세 가지 주요 상호 작용 엔진으로 정의되는 일반적인 인공 지능과 기계 학습이 부족합니다.
- 세계 모델[표현, 학습 및 추론] 기계 또는 현실 시뮬레이터(세계 하이퍼그래프 네트워크).
- World Knowledge Engine(글로벌 지식 그래프)
- World Data Engine(글로벌 데이터 그래프 네트워크)
일반 AI와 ML 및 DL 애플리케이션/기계/시스템의 차이점은 세계를 여러 그럴듯한 세계 상태 표현으로 이해한다는 것입니다. , 현실 기계와 글로벌 지식 엔진 및 세계 데이터 엔진.
일반/실제 AI 스택의 가장 중요한 구성 요소이며, 실제 데이터 엔진과 상호 작용하고 지능형 기능/능력을 제공합니다.
- 세계에 대한 정보 처리
- 상태를 추정/계산/학습합니다. 세계 모델
- 데이터 요소, 점, 세트 일반화
- 데이터 구조 및 유형 지정
- 학습 전달
- 콘텐츠 맥락화
- 인과 패턴, 규칙 및 규칙성과 같은 인과 데이터 패턴 형성/발견
- 추론 모두 시스템과 네트워크에서 가능한 상호 작용, 원인, 효과, 루프, 인과 관계
- 다양한 범위와 규모, 다양한 수준의 일반화 및 사양에서 세계 상태를 예측/검토합니다
- 세계와 효과적이고 효율적으로 상호 작용하고 적응합니다. 지능형 예측 및 처방에 따라 탐색하고 환경을 조작합니다.
사실 이는 주로 빅 데이터 컴퓨팅, 알고리즘 혁신, 통계 학습 이론 및 연결주의 철학에 의존하는 통계 귀납적 추론 엔진입니다.
대부분의 사람들에게는 데이터 수집, 관리, 탐색, 기능 엔지니어링, 모델 훈련, 평가 및 최종 배포를 거쳐 간단한 기계 학습(ML) 모델을 구축하는 것뿐입니다.
EDA: 탐색적 데이터 분석
AI Ops — AI의 엔드투엔드 라이프사이클 관리
오늘날의 AI 기능은 각각의 다양한 실제 시나리오에 맞게 알고리즘을 구성하고 조정해야 하는 "머신 러닝"에서 나옵니다. 이로 인해 매우 수동적이며 개발을 감독하는 데 많은 시간이 필요합니다. 이 수동 프로세스는 오류가 발생하기 쉽고 비효율적이며 관리하기 어렵습니다. 다양한 유형의 알고리즘을 구성하고 조정할 수 있는 전문성이 부족하다는 점은 말할 것도 없습니다.
구성, 조정 및 모델 선택이 점점 자동화되고 있으며 Google, Microsoft, Amazon, IBM 등과 같은 모든 주요 기술 회사는 기계 학습 모델 구축 프로세스를 자동화하기 위해 유사한 AutoML 플랫폼을 출시했습니다.
AutoML에는 기계 학습 알고리즘을 기반으로 예측 모델을 구축하는 데 필요한 작업을 자동화하는 작업이 포함됩니다. 이러한 작업에는 수동으로 수행하기에는 지루할 수 있는 데이터 정리 및 전처리, 기능 엔지니어링, 기능 선택, 모델 선택, 하이퍼파라미터 튜닝이 포함됩니다.
SAS4485-2020.pdf
제시된 엔드투엔드 ML 파이프라인은 모든 데이터의 소스인 세계 자체가 누락된 3가지 주요 단계로 구성됩니다.
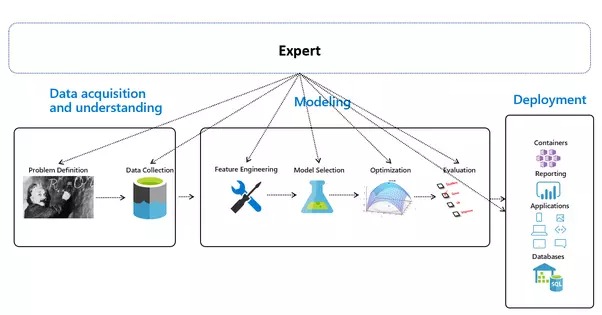
자동화된 기계 학습 - 개요
빅테크 AI의 핵심 비결은 다크 심층 신경망인 스킨딥 머신러닝(Skin-Deep Machine Learning)이다. 해당 모델은 대량의 라벨링된 데이터와 최대한 많은 레이어를 포함하는 신경망 아키텍처를 통해 훈련되어야 한다.
각 작업에는 특별한 네트워크 아키텍처가 필요합니다.
- 회귀 및 분류를 위한 인공 신경망(ANN)
- 컴퓨터 비전을 위한 CNN(Convolutional Neural Networks)
- 시계열 분석을 위해 순환 신경망(RNN)
- 자체- 특징 추출을 위한 맵 구성
- 추천 시스템을 위한 Deep Boltzmann Machines
- 추천 시스템을 위한 자동 인코더
ANN은 정보 처리 패러다임으로 소개되었으며, 생물학적 신경계/뇌가 정보를 처리하는 방식에서 영감을 얻은 것 같습니다. 그리고 이러한 인공 신경망은 다양한 활성화 함수를 학습/계산할 수 있는 '보편함수 근사기'로 표현됩니다.
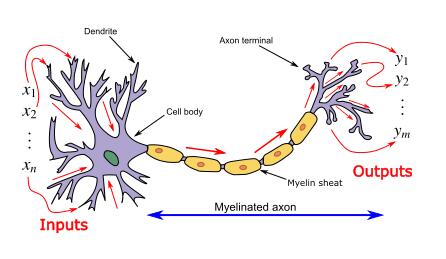
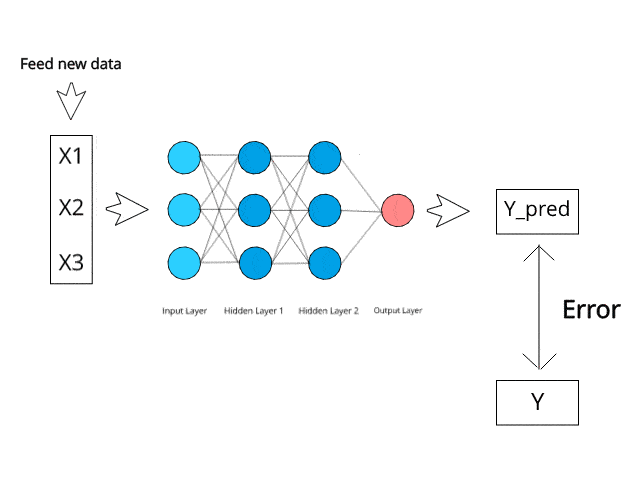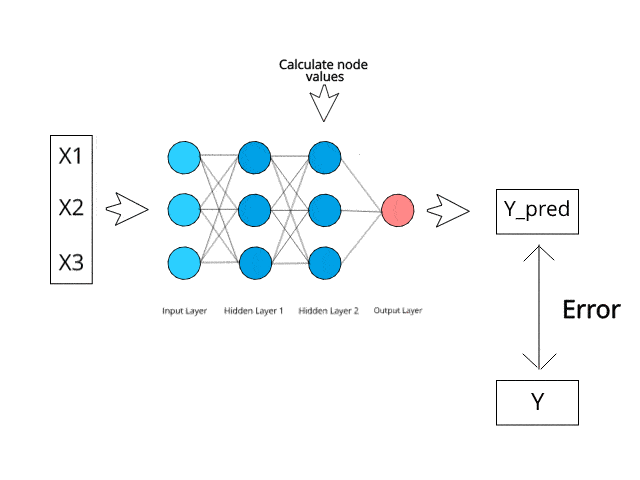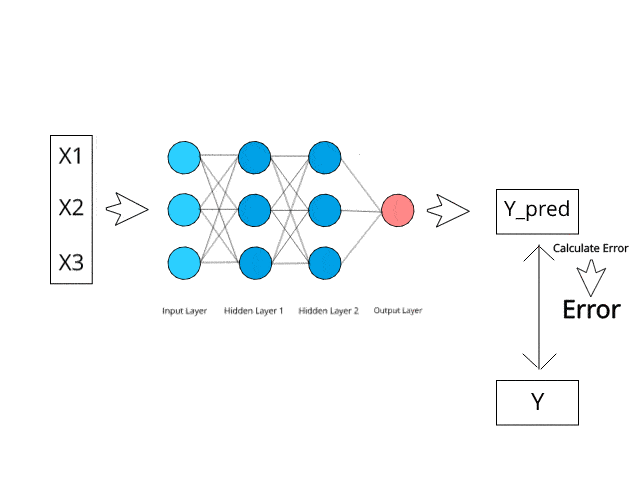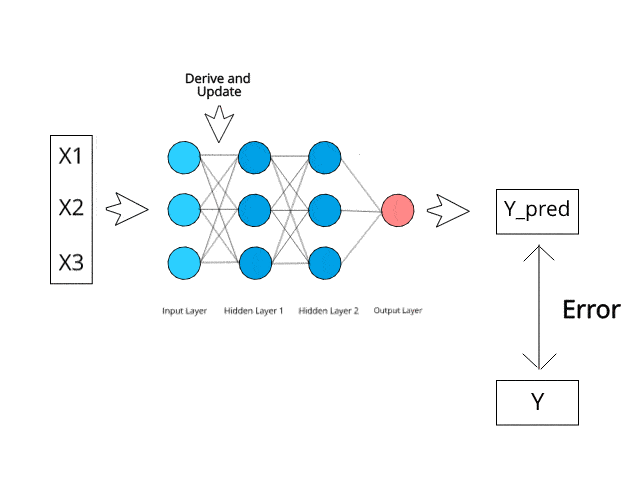
신경망은 테스트 단계에서 특정 역전파 및 오류 수정 메커니즘을 통해 계산/학습합니다.
오류를 최소화함으로써 이러한 다층 시스템이 언젠가는 스스로 아이디어를 학습하고 개념화할 수 있을 것이라고 상상해 보십시오.
인공 신경망(ANN) 소개
대체로 R 또는 Python 코드 몇 줄이면 기계 지능을 구현하기에 충분하며, 준 신경망 훈련을 위한 다양한 온라인 리소스와 튜토리얼이 많이 있습니다. 딥페이크 네트워크, 이미지 조작 - 비디오 - Generative Adversarial Networks, BigGAN, CycleGAN, StyleGAN, GauGAN, Artbreeder, DeOldify 등과 같이 세상에 대한 이해가 전혀 없는 오디오 텍스트입니다.
그들은 얼굴, 풍경, 일반 이미지 등이 무엇인지 전혀 이해하지 못한 채 만들고 수정합니다.
짝이 없는 이미지 대 이미지 번역을 위해 주기 일관성이 있는 적대 네트워크를 사용하면 2019년은 딥 러닝과 머신 러닝을 14가지 용도로 사용할 수 있는 새로운 AI 시대가 될 것입니다.
자신만의 방식으로 작동하는 수많은 디지털 도구와 프레임워크가 있습니다.
- 개방형 언어 - Python이 가장 인기가 있으며 R 및 Scala도 그 중 하나입니다.
- 개방형 프레임워크 - Scikit-learn, XGBoost, TensorFlow 등
- 방법 및 기술 – 회귀부터 최첨단 GAN 및 RL까지의 클래식 ML 기술
- 생산성 향상 기능 – 시각적 모델링, 기능 엔지니어링, 알고리즘 선택 및 하이퍼파라미터 최적화에 도움이 되는 AutoAI
- 개발 도구 – — DataRobot, H2O, Watson Studio, Azure ML Studio, Sagemaker, Anaconda 등.
scikit-learn, R, SparkML, Jupyter, R, Python, XGboost, Hadoop, Spark, TensorFlow, Keras, PyTorch, Docker, Plumbr 등 데이터 과학자가 작업하는 분야는 정말 안타깝습니다. .
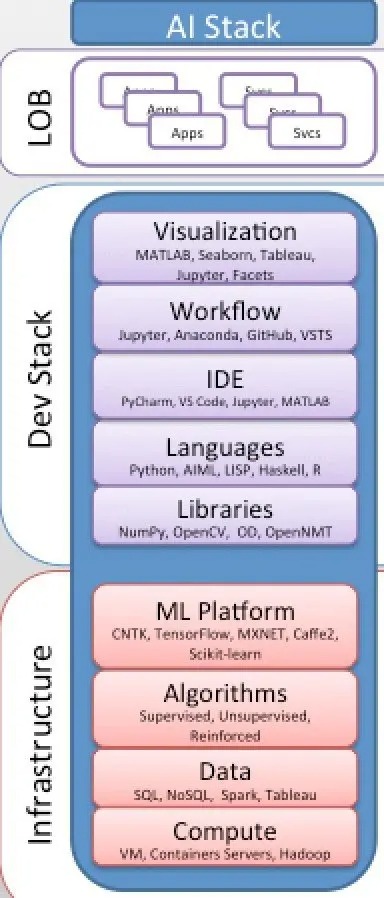
최신 AI 스택 및 AI-as-a-Service 소비 모델
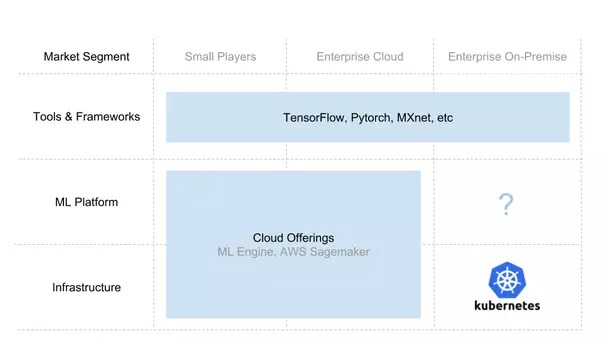
AI 스택 구축
인공지능인 척 하는 것은 실제로는 가짜 인공지능입니다. 최상의 상태에서는 자동 학습 기술인 ML/DL/NN 패턴 인식기이며 본질적으로 수학적 및 통계적이며 직관적으로 행동하거나 환경을 모델링할 수 없으며 지능, 학습 및 이해가 전혀 없습니다.
인공지능의 발전을 가로막는 문제
많은 장점에도 불구하고 인공지능은 완벽하지 않습니다. 인공지능의 발전을 방해하는 8가지 문제와 근본적인 실수는 무엇입니까?
1. 데이터 부족
AI는 훈련을 위해 대규모 데이터 세트가 필요하며 이러한 데이터 세트는 포괄적이고 편견이 없어야 하며 품질이 좋아야 합니다. 때로는 새로운 데이터가 생성될 때까지 기다려야 합니다.
2. 시간 소모적
인공 지능은 상당한 정확성과 관련성을 가지고 목적을 달성할 수 있을 만큼 알고리즘을 학습하고 개발하는 데 충분한 시간이 필요합니다. 또한 기능을 수행하려면 상당한 자원이 필요합니다. 이는 컴퓨터 능력에 대한 추가 요구 사항을 의미할 수 있습니다.
3. 결과의 잘못된 해석
또 다른 주요 과제는 알고리즘에서 생성된 결과를 정확하게 해석하는 능력입니다. 또한 알고리즘을 목적에 따라 신중하게 선택해야 합니다.
4. 오류가 발생하기 쉬움
인공지능은 자율적이지만 오류가 발생하기 쉽습니다. 알고리즘이 비포괄적으로 만들 수 있을 만큼 작은 데이터 세트에 대해 훈련되었다고 가정합니다. 편향된 훈련 세트에서 편향된 예측을 하게 됩니다. 기계 학습의 경우 이러한 실수로 인해 오랫동안 감지되지 않을 수 있는 일련의 오류가 발생할 수 있습니다. 문제가 발견되면 문제의 원인을 파악하는 데 상당한 시간이 걸릴 수 있으며 문제를 해결하는 데는 더 오랜 시간이 걸릴 수 있습니다.
5. 윤리적 문제
자신의 판단보다 데이터와 알고리즘을 신뢰한다는 생각에는 장점과 단점이 있습니다. 분명히 우리는 이러한 알고리즘의 이점을 누리고 있습니다. 그렇지 않으면 애초에 이를 사용하지 않을 것입니다. 이러한 알고리즘을 사용하면 사용 가능한 데이터를 사용하여 정보에 입각한 판단을 내려 프로세스를 자동화할 수 있습니다. 그러나 때로는 이는 누군가의 직업을 알고리즘으로 대체하는 것을 의미하며 이는 윤리적인 결과를 낳습니다. 게다가 무슨 일이 생기면 누구를 비난해야 할까요?
6. 기술 자원 부족
인공지능은 아직 비교적 새로운 기술입니다. 시작 코드부터 프로세스의 유지 관리 및 모니터링까지 프로세스를 유지하려면 기계 학습 전문가가 필요합니다. 인공지능과 머신러닝 산업은 아직 시장에 비교적 새로운 분야입니다. 인간 형태의 적절한 자원을 찾는 것도 어렵습니다. 따라서 기계 학습 과학 자료를 개발하고 관리할 수 있는 유능한 대표자가 부족합니다. 데이터 연구원은 처음부터 끝까지 수학적, 기술적, 과학적 지식뿐만 아니라 공간적 통찰력이 필요한 경우가 많습니다.
7. 인프라 부족
인공지능에는 많은 데이터 처리 능력이 필요합니다. 상속 프레임워크는 압박감에 따른 책임과 제약을 처리할 수 없습니다. 인프라가 AI 문제를 처리할 수 있는지 확인해야 하며, 그렇지 않은 경우 좋은 하드웨어와 적응형 스토리지로 완전히 업그레이드해야 합니다.
8. 느린 결과와 편견
인공지능은 시간이 많이 걸립니다. 데이터 및 요청 과부하로 인해 결과 전달이 예상보다 오래 걸리고 있습니다. 결과를 일반화하기 위해 데이터베이스의 특정 기능에 초점을 맞추는 것은 기계 학습 모델에서 흔히 발생하며 이는 편향으로 이어질 수 있습니다.
결론
인공지능은 우리 삶의 여러 측면을 장악했습니다. 완벽하지는 않지만 인공 지능은 성장하는 분야이며 수요가 높습니다. 사람의 개입 없이 이미 존재하고 가공된 데이터를 활용하여 실시간 결과를 제공합니다. 이는 종종 데이터 기반 모델을 개발하여 대량의 데이터를 분석하고 평가하는 데 도움이 됩니다. 인공지능은 많은 문제점을 안고 있지만 진화하는 분야이다. 의료 진단과 백신 개발부터 첨단 거래 알고리즘까지, 인공지능은 과학 발전의 핵심이 되었습니다.
위 내용은 인공지능 발전을 방해하는 8가지 문제의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7546
7546
 15
1381
52
83
11
57
19
21
89
15
1381
52
83
11
57
19
21
89

 데비안 메일 서버 방화벽 구성 팁
Apr 13, 2025 am 11:42 AM
데비안 메일 서버 방화벽 구성 팁
Apr 13, 2025 am 11:42 AM
데비안 메일 서버의 방화벽 구성은 서버 보안을 보장하는 데 중요한 단계입니다. 다음은 iptables 및 방화구 사용을 포함하여 일반적으로 사용되는 여러 방화벽 구성 방법입니다. iptables를 사용하여 iptables를 설치하도록 방화벽을 구성하십시오 (아직 설치되지 않은 경우) : sudoapt-getupdatesudoapt-getinstalliptablesview 현재 iptables 규칙 : sudoiptables-l configuration
 데비안 메일 서버 SSL 인증서 설치 방법
Apr 13, 2025 am 11:39 AM
데비안 메일 서버 SSL 인증서 설치 방법
Apr 13, 2025 am 11:39 AM
Debian Mail 서버에 SSL 인증서를 설치하는 단계는 다음과 같습니다. 1. OpenSSL 툴킷을 먼저 설치하십시오. 먼저 OpenSSL 툴킷이 이미 시스템에 설치되어 있는지 확인하십시오. 설치되지 않은 경우 다음 명령을 사용하여 설치할 수 있습니다. 개인 키 및 인증서 요청 생성 다음에 다음, OpenSSL을 사용하여 2048 비트 RSA 개인 키 및 인증서 요청 (CSR)을 생성합니다.
 Centos Shutdown 명령 줄
Apr 14, 2025 pm 09:12 PM
Centos Shutdown 명령 줄
Apr 14, 2025 pm 09:12 PM
CentOS 종료 명령은 종료이며 구문은 종료 [옵션] 시간 [정보]입니다. 옵션은 다음과 같습니다. -H 시스템 중지 즉시 옵션; -P 종료 후 전원을 끕니다. -R 다시 시작; -대기 시간. 시간은 즉시 (현재), 분 (분) 또는 특정 시간 (HH : MM)으로 지정할 수 있습니다. 추가 정보는 시스템 메시지에 표시 될 수 있습니다.
 Sony는 PS5 Pro에서 특수 GPU를 사용하여 AMD로 AI를 개발할 가능성을 확인합니다.
Apr 13, 2025 pm 11:45 PM
Sony는 PS5 Pro에서 특수 GPU를 사용하여 AMD로 AI를 개발할 가능성을 확인합니다.
Apr 13, 2025 pm 11:45 PM
Sonyinteractiveent intustionment (SIE, Sony Interactive Entertainment)의 최고 건축가 인 Mark Cerny는 성능 업그레이드 된 AMDRDNA2.X 아키텍처 GPU 및 AMD와 함께 기계 학습/인공 지능 프로그램 코드 "Amethylst"를 포함하여 차세대 호스트 PlayStation5Pro (PS5PRO)에 대한 더 많은 하드웨어 세부 정보를 발표했습니다. PS5PRO 성능 향상의 초점은 여전히 강력한 GPU, Advanced Ray Tracing 및 AI 구동 PSSR Super-Resolution 기능을 포함하여 세 가지 기둥에 있습니다. GPU는 Sony가 RDNA2.x라는 맞춤형 AMDRDNA2 아키텍처를 채택하며 RDNA3 아키텍처가 있습니다.
 Centos에서 Gitlab의 백업 방법은 무엇입니까?
Apr 14, 2025 pm 05:33 PM
Centos에서 Gitlab의 백업 방법은 무엇입니까?
Apr 14, 2025 pm 05:33 PM
CentOS 시스템 하에서 Gitlab의 백업 및 복구 정책 데이터 보안 및 복구 가능성을 보장하기 위해 CentOS의 Gitlab은 다양한 백업 방법을 제공합니다. 이 기사는 완전한 GITLAB 백업 및 복구 전략을 설정하는 데 도움이되는 몇 가지 일반적인 백업 방법, 구성 매개 변수 및 복구 프로세스를 자세히 소개합니다. 1. 수동 백업 gitlab-rakegitlab : 백업 : 명령을 작성하여 수동 백업을 실행하십시오. 이 명령은 gitlab 저장소, 데이터베이스, 사용자, 사용자 그룹, 키 및 권한과 같은 주요 정보를 백업합니다. 기본 백업 파일은/var/opt/gitlab/backups 디렉토리에 저장됩니다. /etc /gitlab을 수정할 수 있습니다
 Centos에서 Zookeeper의 성능을 조정하는 방법은 무엇입니까?
Apr 14, 2025 pm 03:18 PM
Centos에서 Zookeeper의 성능을 조정하는 방법은 무엇입니까?
Apr 14, 2025 pm 03:18 PM
CentOS에 대한 Zookeeper Performance Tuning은 하드웨어 구성, 운영 체제 최적화, 구성 매개 변수 조정, 모니터링 및 유지 관리 등 여러 측면에서 시작할 수 있습니다. 특정 튜닝 방법은 다음과 같습니다. SSD는 하드웨어 구성에 권장됩니다. Zookeeper의 데이터는 디스크에 작성되므로 SSD를 사용하여 I/O 성능을 향상시키는 것이 좋습니다. 충분한 메모리 : 자주 디스크 읽기 및 쓰기를 피하기 위해 충분한 메모리 리소스를 동물원에 충분한 메모리 자원을 할당하십시오. 멀티 코어 CPU : 멀티 코어 CPU를 사용하여 Zookeeper가이를 병렬로 처리 할 수 있도록하십시오.
 마침내 변경되었습니다! Microsoft Windows 검색 기능은 새로운 업데이트를 안내합니다.
Apr 13, 2025 pm 11:42 PM
마침내 변경되었습니다! Microsoft Windows 검색 기능은 새로운 업데이트를 안내합니다.
Apr 13, 2025 pm 11:42 PM
EU의 일부 Windows 내부 채널에서 Microsoft의 Windows 검색 기능 개선이 테스트되었습니다. 이전에 통합 Windows 검색 기능은 사용자에 의해 비판을 받았으며 경험이 좋지 않았습니다. 이 업데이트는 검색 기능을 두 부분으로 나눕니다. 로컬 검색 및 Bing 기반 웹 검색을 위해 사용자 경험을 향상시킵니다. 검색 인터페이스의 새 버전은 기본적으로 로컬 파일 검색을 수행합니다. 온라인으로 검색 해야하는 경우 "Microsoft BingwebSearch"탭을 클릭하여 전환해야합니다. 전환 후 검색 바에는 사용자가 키워드를 입력 할 수있는 "Microsoft Bingwebsearch :"가 표시됩니다. 이 움직임은 로컬 검색 결과와 Bing 검색 결과의 혼합을 효과적으로 피합니다.
 Centos에서 Pytorch 모델을 훈련시키는 방법
Apr 14, 2025 pm 03:03 PM
Centos에서 Pytorch 모델을 훈련시키는 방법
Apr 14, 2025 pm 03:03 PM
CentOS 시스템에서 Pytorch 모델을 효율적으로 교육하려면 단계가 필요 하며이 기사는 자세한 가이드를 제공합니다. 1. 환경 준비 : 파이썬 및 종속성 설치 : CentOS 시스템은 일반적으로 파이썬을 사전 설치하지만 버전은 더 오래 될 수 있습니다. YUM 또는 DNF를 사용하여 Python 3 및 Upgrade Pip : Sudoyumupdatepython3 (또는 SudodnfupdatePython3), PIP3INSTALL-UPGRADEPIP를 설치하는 것이 좋습니다. CUDA 및 CUDNN (GPU 가속도) : NVIDIAGPU를 사용하는 경우 Cudatool을 설치해야합니다.
