
최근 저장대학교 ReLER 연구소에서는 SAM과 비디오 분할을 긴밀하게 결합하여 SAM-Track(Segment-and-Track Anything)을 출시했습니다.
SAM-Track은 SAM에 비디오 대상을 추적하는 기능을 제공하고 다양한 상호 작용 방식(포인트, 브러시, 텍스트)을 지원합니다.
이를 바탕으로 SAM-Track은 여러 기존 비디오 분할 작업을 통합하고 원클릭 분할을 달성하며 모든 비디오의 모든 대상을 추적하고 기존 비디오 분할을 범용 비디오 분할로 추정합니다.
SAM-Track은 탁월한 성능을 갖추고 있으며 단 하나의 카드로 복잡한 시나리오에서도 수백 개의 대상을 고품질로 안정적으로 추적할 수 있습니다.

프로젝트 주소: https://github.com/z-x-yang/Segment-and-Track-Anything
논문 주소: https://arxiv.org/abs /2305.06558
SAM-Track은 프롬프트로 언어 입력을 지원합니다. 예를 들어, 카테고리 텍스트가 "Panda"인 경우 원클릭 인스턴스 수준 세분화를 사용하여 "Panda" 카테고리에 속하는 모든 대상을 추적할 수 있습니다.

"맨 왼쪽에 팬더"라는 텍스트를 입력하는 등 더 자세한 설명을 제공할 수도 있으며, SAM-Track은 분할 추적을 위한 특정 대상을 찾을 수 있습니다.

기존 비디오 추적 알고리즘과 비교하여 SAM-Track의 또 다른 강력한 기능은 많은 수의 대상을 동시에 추적 및 분할하고 새로운 물체를 자동으로 감지할 수 있다는 것입니다.

SAM-Track은 다양한 대화형 방법의 조합도 지원하며 사용자는 실제 필요에 따라 이를 연결할 수 있습니다. 예를 들어, 인체와 밀접하게 연결된 스케이트보드를 브러시를 사용하여 프레임을 만들어 중복된 개체의 분할을 방지한 다음 클릭을 사용하여 인체를 선택합니다.
완전 자동 비디오 타겟 분할 및 추적은 당연히 문제가 됩니다. 스트리트 뷰, 항공 사진, AR, 애니메이션, 의료 이미지 등을 포함한 다양한 응용 시나리오는 모두 한 번의 클릭으로 분할 및 추적할 수 있으며 새로운 항목을 자동으로 감지합니다. 사물.

자동 분할 결과가 만족스럽지 않은 경우 사용자는 클릭을 사용하여 과도하게 분할된 트램을 수정하는 등 이를 기반으로 편집 및 수정을 할 수 있습니다.

동시에 최신 버전의 SAM-Track은 추적 결과의 온라인 검색을 지원합니다. 중간에 있는 프레임의 분할 결과를 선택하여 대상을 수정 및 추가하고 다시 추적할 수 있습니다.

이 프로젝트는 사용자의 온라인 경험을 촉진하기 위해 Colab을 통해 한 번의 클릭으로 배포할 수 있는 WebUI를 제공합니다.
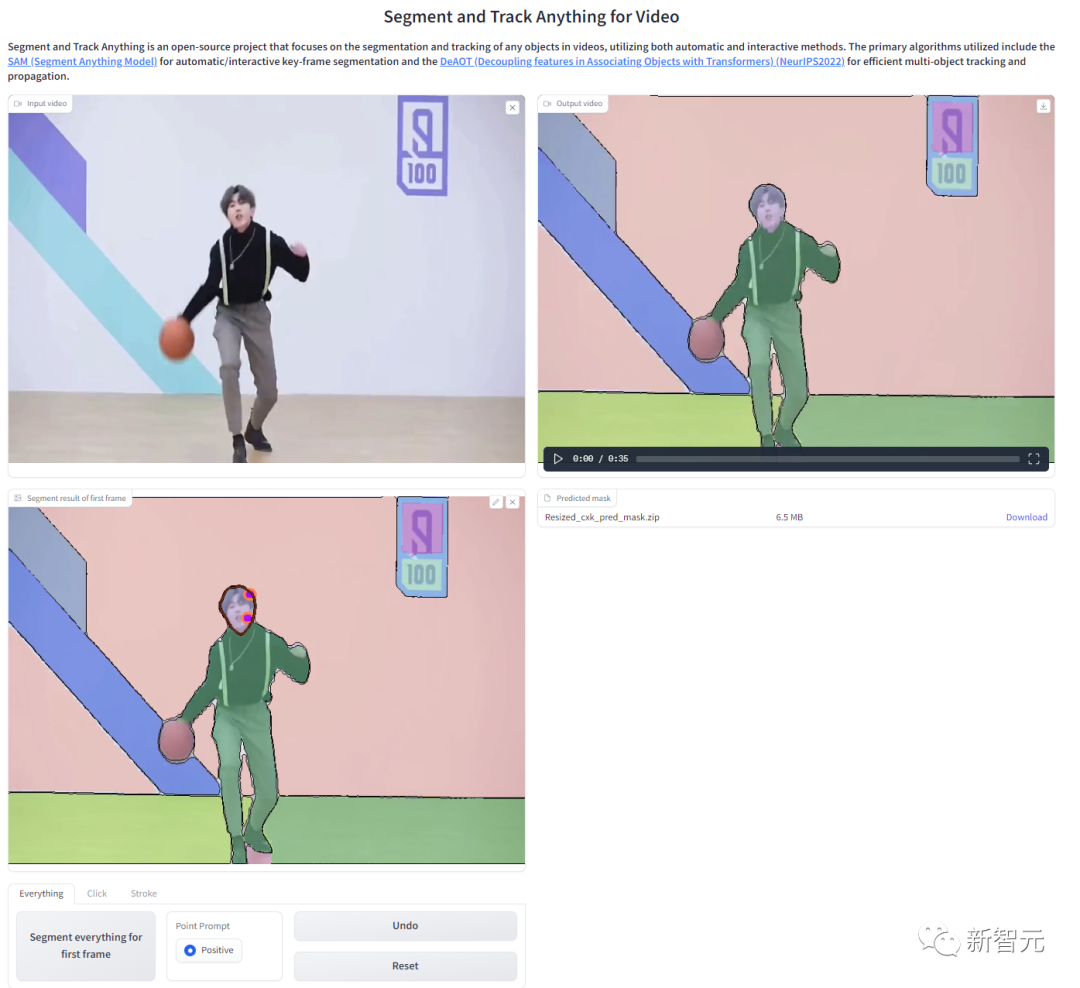
SAM-Track 모델은 ECCV'22 VOT 워크숍의 4개 트랙 챔피언십 방식인 DeAOT를 기반으로 합니다.
DeAOT는 첫 번째 프레임의 개체 주석이 주어지면 비디오의 나머지 프레임에서 개체를 추적하고 분할할 수 있는 효율적인 다중 목표 VOS 모델입니다.
DeAOT는 인식 메커니즘을 사용하여 비디오의 여러 대상을 동일한 고차원 공간에 삽입하여 여러 개체를 동시에 추적합니다.
DeAOT의 다중 객체 추적 속도 성능은 단일 객체 추적을 위한 다른 VOS 방법과 비슷합니다.
또한 DeAOT는 계층화된 Transformer 기반의 전파 메커니즘을 통해 장기 및 단기 정보를 더 효과적으로 집계하여 뛰어난 추적 성능을 보여줍니다.
DeAOT에서는 초기화를 위해 참조 프레임 주석이 필요하므로 SAM-Track에서는 편의성 향상을 위해 최근 이미지 분할 분야에서 인기가 높은 SAM(Segment Anything Model) 모델을 사용하여 주석 정보를 얻습니다.
SAM의 탁월한 제로 샘플 마이그레이션 기능과 다양한 상호 작용 방법을 사용하여 SAM-Track은 DeAOT에 대한 고품질 참조 프레임 주석 정보를 효율적으로 얻을 수 있습니다.
SAM 모델은 이미지 분할 분야에서 잘 작동하지만 의미 체계 라벨을 출력할 수 없으며 텍스트 힌트는 참조 객체 분할 및 깊은 의미 체계 이해에 의존하는 기타 작업을 제대로 지원할 수 없습니다.
따라서 SAM-Track 모델은 Grounding-DINO를 추가로 통합하여 고정밀 언어 안내 비디오 분할을 달성합니다. 접지 DINO는 우수한 언어 이해 기능을 갖춘 개방형 객체 감지 모델입니다.
Grounding-DINO는 입력된 카테고리 또는 대상 물체의 상세 설명을 기반으로 대상을 감지하고 위치 상자를 반환할 수 있습니다.
아래 그림과 같이 SAM-Track 모델은 대화형 추적 모드, 자동 추적 모드 및 융합 모드의 세 가지 객체 추적 모드를 지원합니다.
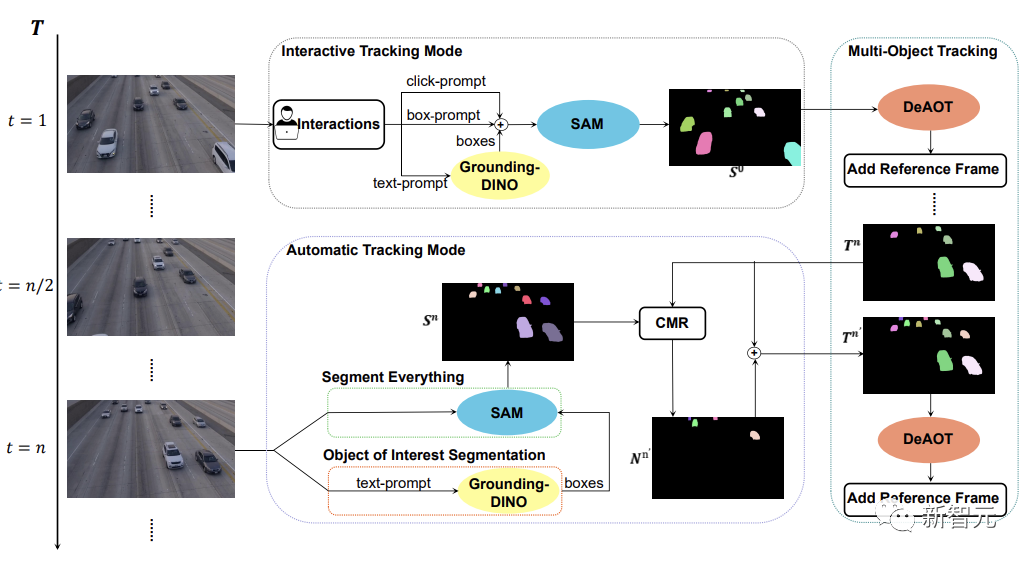
대화형 추적 모드의 경우 SAM-Track 모델은 먼저 SAM을 적용하고 사용자에게 만족스러운 대화형 분할 결과가 나올 때까지 프레임을 클릭하거나 그려 참조 프레임에서 대상을 선택합니다. 획득.
언어 기반 비디오 객체 분할을 구현하려는 경우 SAM-Track은 Grounding-DINO를 호출하여 먼저 입력 텍스트를 기반으로 대상 객체의 위치 프레임을 획득하고 이를 기반으로 객체의 분할을 획득합니다. SAM 결과를 통해 관심 대상을 검색합니다.
마지막으로 DeAOT는 대화형 분할 결과를 참조 프레임으로 사용하여 선택한 대상을 추적합니다. 추적 프로세스 동안 DeAOT는 과거 프레임의 시각적 임베딩 및 고차원 ID 임베딩을 현재 프레임에 레이어 방식으로 전파하여 프레임별 추적 및 여러 대상 객체의 분할을 달성합니다. 따라서 SAM-Track은 다중 모드 상호 작용을 지원하여 분할된 비디오에서 관심 개체를 추적할 수 있습니다.
그러나 대화형 추적 모드는 비디오에 새로 등장하는 개체를 처리할 수 없습니다. 자율주행, 스마트시티 등 특정 분야에 SAM-Track 적용을 제한합니다.
SAM-Track의 적용 범위와 성능을 더욱 확장하기 위해 SAM-Track은 자동 추적 모드를 구현하여 영상에 나타나는 새로운 물체를 추적합니다.
자동 추적 모드에서는 Segment Everything과 관심 개체 분할을 사용하여 n 프레임마다 나타나는 새 개체에 대한 주석을 얻습니다. 새로 나타나는 객체의 ID 할당 문제에 대해 SAM-Track은 비교 마스크 모듈(CMR)을 사용하여 새 객체의 ID를 결정합니다.
퓨전 모드는 대화형 추적 모드와 자동 추적 모드를 결합합니다. 대화형 추적 모드를 사용하면 사용자가 비디오의 첫 번째 프레임에 대한 주석을 쉽게 얻을 수 있는 반면, 자동 추적 모드는 비디오의 후속 프레임에 나타나는 선택되지 않은 새로운 개체를 처리합니다. 추적 방법의 조합은 SAM-Track의 적용 범위를 확장하고 SAM-Track의 실용성을 높입니다.
위 내용은 영상 분할의 마지막! Zhejiang University는 최근 SAM-Track을 출시했습니다: 한 번의 클릭으로 범용 지능형 비디오 분할의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



