

COUNT(expression): 쿼리된 레코드의 총 수를 반환합니다. 표현식 매개 변수는 필드 또는 * 기호입니다.
MySQL 버전: 5.7.29
사용자 테이블을 생성하고 백만 개의 데이터를 삽입합니다. 이 중 성별 필드의 50만 행에는 null 값이 있습니다
CREATE TABLE `users` ( `Id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id', `name` varchar(32) DEFAULT NULL COMMENT '名称', `gender` varchar(20) DEFAULT NULL COMMENT '性别', `create_date` datetime DEFAULT NULL COMMENT '创建时间', PRIMARY KEY (`Id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='用户表';
in 이전 MySQL 5.7.18, InnoDB는 클러스터형 인덱스를 스캔하여 명령문을 처리했습니다. SELECT COUNT(*) MySQL 5.7.18부터 InnoDB는 인덱스 또는 최적화 프로그램 힌트가 최적화 프로그램에 다른 인덱스를 사용하도록 지시하지 않는 한 사용 가능한 가장 작은 보조 인덱스를 순회하여 SELECT COUNT(*) 문을 처리합니다. 보조 인덱스가 없으면 클러스터형 인덱스를 검색합니다.
일반적인 의미는 보조 인덱스가 있으면 보조 인덱스를 사용하고 보조 인덱스가 여러 개인 경우 비용을 줄이기 위해 가장 작은 보조 인덱스를 먼저 선택한다는 것입니다.
다음 테스트는 이러한 뷰를 확인하는 데 사용됩니다.
먼저 기본 키 인덱스 Id가 하나만 있을 때 실행 계획을 쿼리합니다.

타입은 인덱스를 사용한다는 뜻의 index이고 키는 기본 키를 의미하는 PRIMARY임을 알 수 있습니다. 키 인덱스가 사용됩니다(key_len=8).
둘째, 이름 필드에 인덱스를 추가하고 다시 실행 계획을 사용하여

인덱스도 사용하는 것을 볼 수 있는데, 인덱스는 이름 필드의 인덱스인 key_len=99를 사용하고 있습니다.
그런 다음 name 필드 인덱스를 유지하면서 create_date 필드에 인덱스를 추가합니다. 실행 계획을 다시 확인합니다.

이번에는 create_date 필드의 인덱스인 key_len=6이 사용되는 것을 볼 수 있습니다.
위에서 어떤 인덱스를 사용하더라도 최종적으로 쿼리되는 총 행 수는 NULL 값 포함 여부에 관계없이 백만 개입니다.
count(1)은 count(*)와 동일한 쿼리 결과를 가지며, NULL 값 포함 여부에 관계없이 최종적으로 백만 개의 데이터를 반환합니다.
count(col)은 특정 열의 값을 계산하며 이는 세 가지 상황으로 구분됩니다.
및 count(*)를 계산합니다.
count(name)로 쿼리하면 실행 계획은 다음과 같습니다.

인덱스 필드는 통계에 사용되며 인덱스도 적중됩니다.
열의 이름 필드를 NULL로 설정한 후 개수 쿼리를 수행하면 결과는 999999
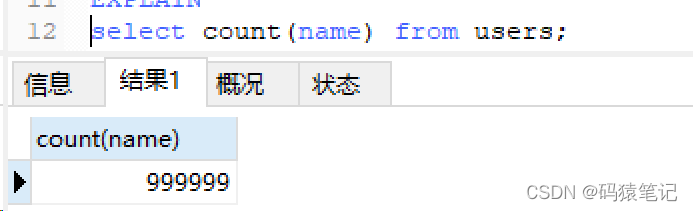
그런 다음 이 열의 NULL 값을 빈 문자열로 설정하고 개수 쿼리를 수행하면 결과가 반환됩니다. 1000000
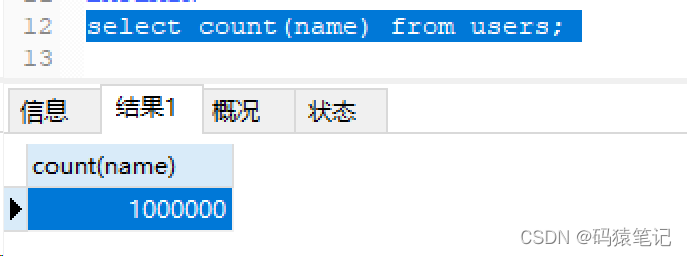
따라서 요약하면 단순히 인덱스 필드를 사용하여 행 수를 계산하면 인덱스에 적중될 수 있으며 NULL 값이 아닌 행 수만 계산됩니다.
인덱스가 없는 필드 개수를 계산하면 인덱스는 사용되지 않고 NULL 값이 아닌 행의 개수만 계산됩니다.

이전에는 count(1)이 count(*)보다 더 효율적이라는 것을 어디서 보거나 들은 적이 없습니다. 잘못된 인식입니다. 공식 홈페이지에 이런 문장이 있는데 InnoDB는 SELECT COUNT( *)와 SELECT COUNT(1) 연산을 동일하게 처리합니다.
번역하면 InnoDB는 SELECT COUNT( *)와 SELECT COUNT(1) 연산을 처리합니다. COUNT(1) 연산과 동일한 방식으로 수행하면 성능 차이가 없습니다.
MyISAM 테이블의 경우 COUNT(*)는 테이블에서 검색할 때 매우 빠르게 반환하도록 최적화되어 있으며 다른 열은 검색되지 않으며 절도 없습니다. 스토리지 엔진이 정확한 행 수와 매우 높은 수를 저장하기 때문에 이 최적화는 MyISAM 테이블에만 적용됩니다. 접근이 빠릅니다. COUNT(1)은 첫 번째 열이 NOT NULL로 정의된 경우에만 동일한 최적화를 수행합니다. ----MySQL 공식 웹사이트에서
이러한 최적화는 어디에도, 그룹화도 없다는 전제를 기반으로 합니다.
알리바바 개발 사양에도 언급되어 있습니다

개발 중에 count(*)를 사용할 수 있다면 그냥 count(*)를 사용하세요.
위 내용은 MySQL에서 count(*), count(1), count(col)의 차이점은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



