

MySQL 데이터 지속성 프로세스 예시 분석

1. 프로세스에 대한 간략한 설명
MySQL 데이터의 지속성 프로세스를 이해하면 기본 MySQL에 대한 이해를 심화하는 데 도움이 될 수 있습니다. 관심이 있다면 이 과정을 깊이 있게 연구하고 연구할 수 있습니다.
MySQL 데이터 저장은 일반적으로 메모리의 저장 프로시저와 하드 디스크의 영구 저장의 두 부분으로 나눌 수 있습니다. 여기에는 메모리의 버퍼 폴과 redo 로그가 포함됩니다. code> 및 <code>트랜잭션 로그 및 테이블 구조를 디스크에 저장합니다. 이 문서에서는 각 부분의 구체적인 디자인을 자세히 설명하지 않고 개념적인 이해만 제공합니다. buffer poll和redo log以及磁盘上的事务日志和表结构,在本文中,我们不具体解释每一部分的具体设计,只是给大家一个概念型的认识:
buffer poll是InnoDB引擎缓存池的一部分,我们这里可以简单理解为数据库从磁盘读进内存的内存块的缓存;redo log是内存中的逻辑日志,记录了事务的变更操作事务日志是磁盘上的食物逻辑日志表结构是真正存储数据的结构
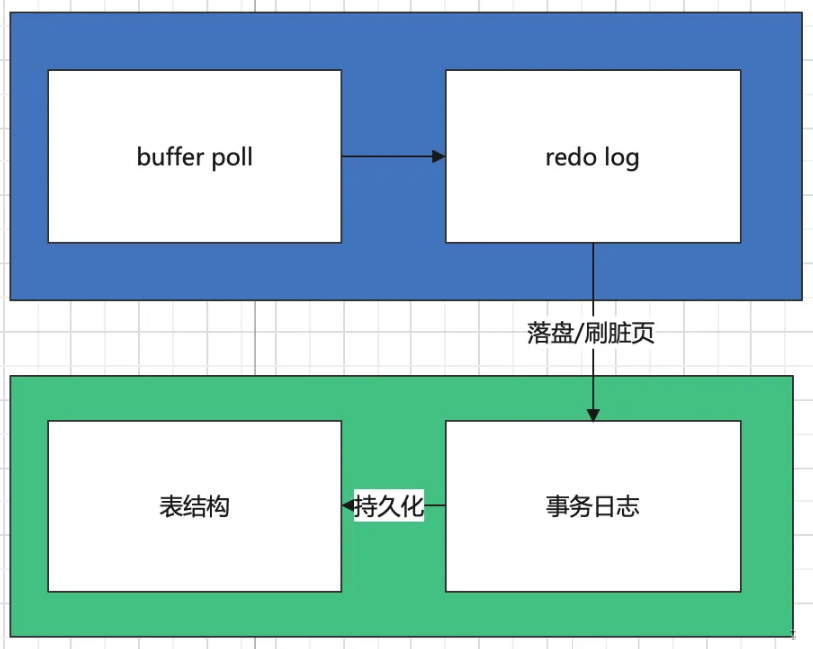
2. 内存中的操作
buffer poll中有对于读入内存的数据的缓存,在查询命令执行时,会优先在缓存中查看是否命中,未命中就会从磁盘中将需要的数据读进来,缓存的管理使用的是改良的LRU算法,这里不做深入地介绍了。
当一条修改指令运行的时候,首先进行的是对于buffer poll中缓存的修改,被修改后的数据会被标记为脏页,同时,修改的操作也会记录在redo log中,我们常说的MVCC中的版本链就是借助redo log实现的。
需要注意的是,脏页不是立刻落到磁盘的,而是有可以设置的刷盘控制机制,例如,一个事务执行结算后立刻落盘,按照一定时间定期落盘等等。
在内存中的操作都是非持久化的,如果这时发生了意料之外的问题导致系统宕机,数据是还没有持久化的,所以理论上也不会对数据库造成破坏性的影响。
3. 磁盘的持久化
3.1 事务日志的作用
InnoDB在磁盘的持久化分为两步,第一步是逻辑日志的存储,之后再将日志中的数据刷进磁盘空间。
在讨论为什么要使用逻辑日志之前,我们需要简单理解随机IO与顺序IO的区别:
寻址过程是磁盘IO中的一个重要瓶颈,因为它需要将探针移动到需要读取的位置来读取磁盘数据。
顺序IO是指寻址的空间是连续的,移动距离很短,随机IO是指我们需要寻找的地址分布在各处,需要移动很长的距离。
所以,我们能很明晰的得出结论:将随机IO替换为顺序IO
-
buffer poll은 InnoDB 엔진 캐시 풀의 일부입니다. 여기서는 데이터베이스가 수행하는 메모리 블록의 캐시로 간단히 이해할 수 있습니다. ; -
redo log는 메모리의 논리적 로그인으로, 트랜잭션 변경 작업을 기록합니다 -
트랜잭션 로그디스크에 있는 음식 논리 로그입니다 -
테이블 구조는 실제로 데이터가 저장되는 구조입니다
 2. 메모리 내 작업🎜🎜buffer poll code>에는 메모리로 읽어온 데이터에 대한 캐시가 있습니다. query 명령이 실행되면 먼저 캐시에 적중이 있는지 확인하고, 적중되지 않으면 필요한 데이터를 가져옵니다. 캐시 관리가 향상되었습니다. 여기서는 LRU 알고리즘을 자세히 소개하지 않습니다. 🎜🎜수정 명령이 실행되면 가장 먼저 해야 할 일은
2. 메모리 내 작업🎜🎜buffer poll code>에는 메모리로 읽어온 데이터에 대한 캐시가 있습니다. query 명령이 실행되면 먼저 캐시에 적중이 있는지 확인하고, 적중되지 않으면 필요한 데이터를 가져옵니다. 캐시 관리가 향상되었습니다. 여기서는 LRU 알고리즘을 자세히 소개하지 않습니다. 🎜🎜수정 명령이 실행되면 가장 먼저 해야 할 일은 버퍼 폴에서 캐시를 수정하는 것입니다. 동시에 수정된 데이터는 더티 페이지로 표시됩니다. 수정 작업은 redo 로그에도 기록됩니다. 우리가 흔히 말하는 MVCC의 버전 체인은 redo 로그의 도움으로 구현됩니다. 🎜🎜더티 페이지는 즉시 디스크에 삭제되지 않지만 설정할 수 있는 플러시 제어 메커니즘이 있습니다. 예를 들어 트랜잭션은 결제 후 즉시 디스크에 삭제되고 정기적으로 디스크에 삭제됩니다. 특정 시간 등 🎜🎜메모리의 모든 작업은 비영구적입니다. 예상치 못한 문제가 발생하여 시스템이 충돌하더라도 데이터는 지속되지 않으므로 이론적으로 데이터베이스에 파괴적인 영향을 미치지 않습니다. 🎜🎜3. 디스크 지속성🎜🎜3.1 트랜잭션 로그의 역할🎜🎜InnoDB의 디스크 지속성은 두 단계로 나누어집니다. 첫 번째 단계는 논리적 로그를 저장한 다음 로그의 데이터를 디스크 공간에 플러시하는 것입니다. 🎜🎜논리 로그를 사용해야 하는 이유를 논의하기 전에 임의 IO와 순차 IO의 차이점을 간략하게 이해해야 합니다.🎜🎜주소 지정 프로세스는 디스크 데이터를 읽으려면 프로브를 읽어야 하는 위치로 프로브를 이동해야 하므로 디스크 IO에 심각한 병목 현상이 발생합니다. 🎜🎜순차 IO는 주소 지정 공간이 연속적이고 이동 거리가 매우 짧다는 것을 의미합니다. 랜덤 IO는 우리가 찾아야 할 주소가 모든 곳에 분산되어 있어야 함을 의미합니다. 매우 빠르게 장거리를 이동했습니다. 🎜🎜그래서 우리는 Random IO를 Sequential IO로 대체하면 디스크 IO의 효율성을 효과적으로 향상시킬 수 있다는 결론을 내릴 수 있습니다. 이것이 바로 논리 로그의 역할이기 때문입니다. 로그 파일은 디스크에 연속적으로 존재하므로 데이터 테이블 정보가 어디에나 분산되어 있는 것에 비해 IO 효율성이 훨씬 높을 수 있습니다. 🎜🎜트랜잭션 로그의 작업을 완전히 업데이트하면 트랜잭션이 성공적으로 유지되고 전용 스레드가 로그 정보를 테이블 구조에 저장하는 역할을 담당하게 됩니다. 🎜🎜3.2 테이블 구조의 2단계 저장🎜🎜 로그 정보를 테이블 구조에 저장하는 과정은 두 단계로 나누어집니다. 먼저 업데이트 후 테이블 헤더의 캐시 영역에 데이터가 업데이트됩니다. 완료되면 해당 테이블 구조 새로 고침에서 데이터가 업데이트됩니다. 🎜🎜2단계 저장의 목적은 데이터 저장의 강력한 일관성을 보장하고 디스크에 플래시하는 과정에서 데이터베이스 가동 중지 시간으로 인해 데이터가 불완전해지는 것을 방지하는 것입니다. 🎜🎜테이블 헤더의 캐시 영역과 테이블 구조의 저장 블록에는 데이터의 무결성을 확인하는 체크 코드가 있습니다. 전자는 완전하고 후자는 불완전한 경우 이전 데이터를 다시 플래시하면 됩니다. 전자가 불완전하면 로그 플러시 프로세스가 실패했음을 의미하므로 다시 플러시하면 됩니다. 🎜위 내용은 MySQL 데이터 지속성 프로세스 예시 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7569
7569
 15
1386
52
87
11
61
19
28
107
15
1386
52
87
11
61
19
28
107

 MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) 데이터베이스 및 테이블 작성 : CreateAbase 및 CreateTable 명령을 사용하십시오. 2) 기본 작업 : 삽입, 업데이트, 삭제 및 선택. 3) 고급 운영 : 가입, 하위 쿼리 및 거래 처리. 4) 디버깅 기술 : 확인, 데이터 유형 및 권한을 확인하십시오. 5) 최적화 제안 : 인덱스 사용, 선택을 피하고 거래를 사용하십시오.
 phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
다음 단계를 통해 phpmyadmin을 열 수 있습니다. 1. 웹 사이트 제어판에 로그인; 2. phpmyadmin 아이콘을 찾고 클릭하십시오. 3. MySQL 자격 증명을 입력하십시오. 4. "로그인"을 클릭하십시오.
 MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템으로, 주로 데이터를 신속하고 안정적으로 저장하고 검색하는 데 사용됩니다. 작업 원칙에는 클라이언트 요청, 쿼리 해상도, 쿼리 실행 및 반환 결과가 포함됩니다. 사용의 예로는 테이블 작성, 데이터 삽입 및 쿼리 및 조인 작업과 같은 고급 기능이 포함됩니다. 일반적인 오류에는 SQL 구문, 데이터 유형 및 권한이 포함되며 최적화 제안에는 인덱스 사용, 최적화 된 쿼리 및 테이블 분할이 포함됩니다.
 MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL은 성능, 신뢰성, 사용 편의성 및 커뮤니티 지원을 위해 선택됩니다. 1.MYSQL은 효율적인 데이터 저장 및 검색 기능을 제공하여 여러 데이터 유형 및 고급 쿼리 작업을 지원합니다. 2. 고객-서버 아키텍처 및 다중 스토리지 엔진을 채택하여 트랜잭션 및 쿼리 최적화를 지원합니다. 3. 사용하기 쉽고 다양한 운영 체제 및 프로그래밍 언어를 지원합니다. 4. 강력한 지역 사회 지원을 받고 풍부한 자원과 솔루션을 제공합니다.
 단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
Redis는 단일 스레드 아키텍처를 사용하여 고성능, 단순성 및 일관성을 제공합니다. 동시성을 향상시키기 위해 I/O 멀티플렉싱, 이벤트 루프, 비 블로킹 I/O 및 공유 메모리를 사용하지만 동시성 제한 제한, 단일 고장 지점 및 쓰기 집약적 인 워크로드에 부적합한 제한이 있습니다.
 MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL : 개발자를위한 필수 기술
Apr 10, 2025 am 09:30 AM
MySQL 및 SQL은 개발자에게 필수적인 기술입니다. 1.MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템이며 SQL은 데이터베이스를 관리하고 작동하는 데 사용되는 표준 언어입니다. 2.MYSQL은 효율적인 데이터 저장 및 검색 기능을 통해 여러 스토리지 엔진을 지원하며 SQL은 간단한 문을 통해 복잡한 데이터 작업을 완료합니다. 3. 사용의 예에는 기본 쿼리 및 조건 별 필터링 및 정렬과 같은 고급 쿼리가 포함됩니다. 4. 일반적인 오류에는 구문 오류 및 성능 문제가 포함되며 SQL 문을 확인하고 설명 명령을 사용하여 최적화 할 수 있습니다. 5. 성능 최적화 기술에는 인덱스 사용, 전체 테이블 스캔 피하기, 조인 작업 최적화 및 코드 가독성 향상이 포함됩니다.
 MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
데이터베이스 및 프로그래밍에서 MySQL의 위치는 매우 중요합니다. 다양한 응용 프로그램 시나리오에서 널리 사용되는 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) MySQL은 웹, 모바일 및 엔터프라이즈 레벨 시스템을 지원하는 효율적인 데이터 저장, 조직 및 검색 기능을 제공합니다. 2) 클라이언트 서버 아키텍처를 사용하고 여러 스토리지 엔진 및 인덱스 최적화를 지원합니다. 3) 기본 사용에는 테이블 작성 및 데이터 삽입이 포함되며 고급 사용에는 다중 테이블 조인 및 복잡한 쿼리가 포함됩니다. 4) SQL 구문 오류 및 성능 문제와 같은 자주 묻는 질문은 설명 명령 및 느린 쿼리 로그를 통해 디버깅 할 수 있습니다. 5) 성능 최적화 방법에는 인덱스의 합리적인 사용, 최적화 된 쿼리 및 캐시 사용이 포함됩니다. 모범 사례에는 거래 사용 및 준비된 체계가 포함됩니다
 Redis Exporter 서비스로 Redis 액 적을 모니터링하십시오
Apr 10, 2025 pm 01:36 PM
Redis Exporter 서비스로 Redis 액 적을 모니터링하십시오
Apr 10, 2025 pm 01:36 PM
Redis 데이터베이스의 효과적인 모니터링은 최적의 성능을 유지하고 잠재적 인 병목 현상을 식별하며 전반적인 시스템 신뢰성을 보장하는 데 중요합니다. Redis Exporter Service는 Prometheus를 사용하여 Redis 데이터베이스를 모니터링하도록 설계된 강력한 유틸리티입니다. 이 튜토리얼은 Redis Exporter Service의 전체 설정 및 구성을 안내하여 모니터링 솔루션을 원활하게 구축 할 수 있도록합니다. 이 자습서를 연구하면 완전히 작동하는 모니터링 설정을 달성 할 수 있습니다.
