

MySQL의 제약은 무엇입니까?

1. 개요
개념: 제약 조건은 테이블에 저장된 데이터를 제한하기 위해 테이블의 필드에 적용되는 규칙입니다.
목적: 데이터베이스 데이터의 정확성, 유효성 및 무결성을 보장합니다.
카테고리:

참고: 제약조건은 테이블의 필드에 적용되며 테이블을 생성/수정할 때 제약조건을 추가할 수 있습니다.
2. 제약 조건 시연
데이터베이스의 공통 제약 조건과 제약 조건과 관련된 키워드를 소개했습니다. 그러면 테이블을 생성하고 수정할 때 이러한 제약 조건을 어떻게 지정합니까? .
케이스 요구사항: 요구사항에 따라 테이블 구조 생성을 완료하세요. 요구 사항은 다음과 같습니다.
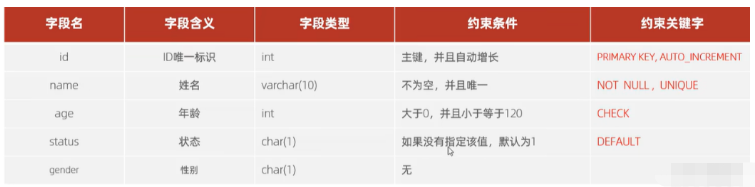
해당 테이블 생성 문은 다음과 같습니다.
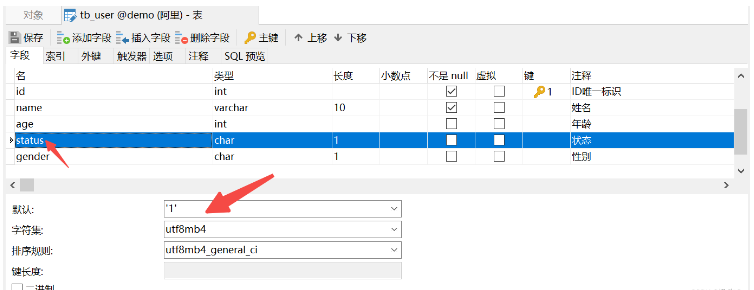
CREATE TABLE tb_user ( id INT AUTO_INCREMENT PRIMARY KEY COMMENT 'ID唯一标识', NAME VARCHAR ( 10 ) NOT NULL UNIQUE COMMENT '姓名', age INT CHECK ( age > 0 && age <= 120 ) COMMENT '年龄', STATUS CHAR ( 1 ) DEFAULT '1' COMMENT '状态', gender CHAR ( 1 ) COMMENT '性别' );
필드에 제약 조건을 추가할 때 필드 뒤에 제약 조건의 키워드만 추가하면 되므로 주의할 필요가 있습니다. 구문에.
위 SQL을 실행하여 테이블 구조를 생성한 다음 데이터 세트를 통해 테스트하여 제약 조건이 적용될 수 있는지 확인할 수 있습니다.
(1) 먼저 3개의 데이터가 추가되었습니다
insert into tb_user(name,age,status,gender) values ('Tom1',19,'1','男'),('Tom2',25,'0','男'); insert into tb_user(name,age,status,gender) values ('Tom3',19,'1','男');
3개의 데이터를 추가하는데 21초가 걸렸습니다. 무슨 일인가요?
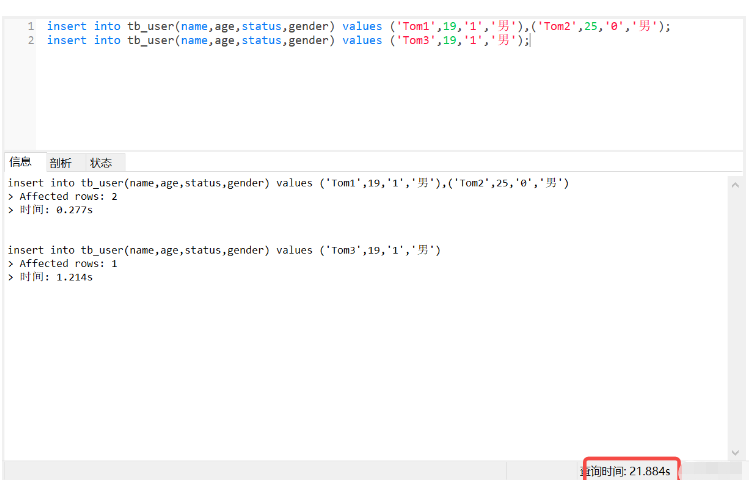
처음에는 이러한 제약 조건을 추가하면 새로운 데이터가 느려지는 줄 알았는데, 그렇지 않았습니다. 이곳은 알리바바의 리눅스 서버이고, 리눅스에서 클라이언트를 통해 mysql을 연결하여 새로운 추가를 실행하게 되었는데, 0.01초로 navicat이 원격 호스트에 연결하는 데 걸리는 시간을 나타냅니다.
이러한 새로운 제약 조건이 추가되더라도 새 데이터가 느려지는 현상이 발생하며 이는 기본적으로 단일 데이터에는 보이지 않습니다.
(2) 테스트 이름 NOT NULL
insert into tb_user(name,age,status,gender) values (null,19,'1','男');

(3) 테스트 이름 UNIQUE(전용)
위에 추가한 데이터에는 이미 Tom3가 있는데, 다시 추가하면 바로 오류가 발생합니다. .
insert into tb_user(name,age,status,gender) values ('Tom3',19,'1','男');

오류가 보고되긴 하지만 이때 다른 데이터를 추가하면 현상을 발견하게 됩니다.
insert into tb_user(name,age,status,gender) values ('Tom4',80,'1','男');
분명히 self-increasing ID인데 4가 없습니다. 그 이유는 UNIQUE는 self-increasing ID를 신청한 후 데이터베이스에 넣을 준비가 되어 있기 때문입니다. 그러면 이때 먼저 여부를 확인합니다. 데이터베이스에 동일한 이름의 값이 있는 경우 신규 추가는 실패하지만 자동 증가 ID가 적용되었습니다.
반대로 방금 널 이름을 테스트했을 때 그는 이미 초기에 비어 있다고 판단하고 아직 ID 신청 단계에 이르지 않았기 때문에 ID를 신청하지 않았습니다.
비어 있는지 확인 -》 자동 증가 ID 적용 -》 이미 존재하는 값이 있는지 확인
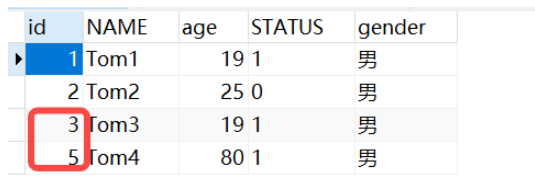
요약: 새로 추가된 이름이 비어 있지 않지만, 동일한 데이터를 갖는 경우 이전 항목의 경우 이번에는 새 추가가 실패하지만 기본 키 ID에는 적용됩니다.
(4) 테스트 CHECK
우리가 설정한 것은 age가 0보다 크고 120보다 작거나 같아야 한다는 것입니다. 그렇지 않으면 저장이 실패합니다!
age int check (age > 0 && age <= 120) COMMENT '年龄' ,
insert into tb_user(name,age,status,gender) values ('Tom5',-1,'1','男'); insert into tb_user(name,age,status,gender) values ('Tom5',121,'1','男');
(5) DEFAULT ‘1’ 기본값 테스트
STATUS CHAR ( 1 ) DEFAULT '1' COMMENT '状态',
insert into tb_user(name,age,gender) values ('Tom5',120,'男');
(6) 위에서 SQL 문을 작성하여 제약 조건 사양을 완성합니다.
기본 키 자동 증가
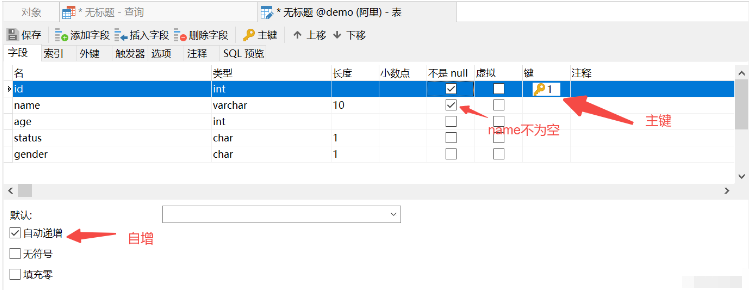
이름 고유 제약 조건

상태 기본값은 1
3. 외래 키 제약 조건
1.
외래 키:사용 데이터의 일관성과 무결성을 보장하기 위해 두 테이블의 데이터 간의 연결을 설정합니다.
예제를 살펴보겠습니다.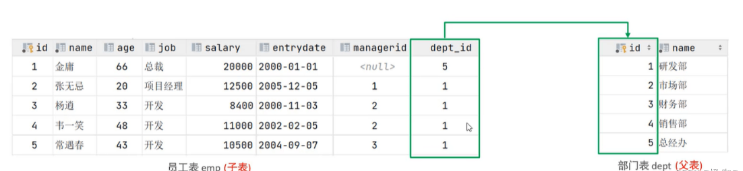 왼쪽의 emp 테이블은 직원 ID, 이름, 나이, 직위, 급여, 입사 등 직원의 기본 정보를 저장하는 직원 테이블입니다. 날짜, 감독자 ID, 부서 ID가 저장됩니다. 직원 정보에 저장되는 것은 부서 ID dept_id이고, 이 부서의 ID는 연관된 부서 테이블 dept의 기본 키 id입니다. 그러면 emp 테이블의 dept_id가 외래 키입니다. 이며 다른 테이블의 기본 키와 연결되어 있습니다.
왼쪽의 emp 테이블은 직원 ID, 이름, 나이, 직위, 급여, 입사 등 직원의 기본 정보를 저장하는 직원 테이블입니다. 날짜, 감독자 ID, 부서 ID가 저장됩니다. 직원 정보에 저장되는 것은 부서 ID dept_id이고, 이 부서의 ID는 연관된 부서 테이블 dept의 기본 키 id입니다. 그러면 emp 테이블의 dept_id가 외래 키입니다. 이며 다른 테이블의 기본 키와 연결되어 있습니다.
2、 不使用外键有什么影响
通过上面的示例,我们分别来演示 添加外键 和不添加外键的区别,首先来看不添加 外键 对数据有什么影响:
准备数据:
CREATE TABLE dept ( id INT auto_increment COMMENT 'ID' PRIMARY KEY, NAME VARCHAR ( 50 ) NOT NULL COMMENT '部门名称' ) COMMENT '部门表'; INSERT INTO dept (id, name) VALUES (1, '研发部'), (2, '市场部'),(3, '财务部'), (4, '销售部'), (5, '总经办'); CREATE TABLE emp ( id INT auto_increment COMMENT 'ID' PRIMARY KEY, NAME VARCHAR ( 50 ) NOT NULL COMMENT '姓名', age INT COMMENT '年龄', job VARCHAR ( 20 ) COMMENT '职位', salary INT COMMENT '薪资', entrydate date COMMENT '入职时间', managerid INT COMMENT '直属领导ID', dept_id INT COMMENT '部门ID' ) COMMENT '员工表'; INSERT INTO emp (id, name, age, job,salary, entrydate, managerid, dept_id) VALUES (1, '金庸', 66, '总裁',20000, '2000-01-01', null,5), (2, '张无忌', 20, '项目经理',12500, '2005-12-05', 1,1), (3, '杨逍', 33, '开发', 8400,'2000-11-03', 2,1), (4, '韦一笑', 48, '开 发',11000, '2002-02-05', 2,1), (5, '常遇春', 43, '开发',10500, '2004-09-07', 3,1), (6, '小昭', 19, '程 序员鼓励师',6600, '2004-10-12', 2,1);
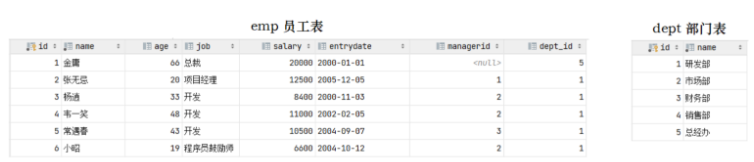
接下来,我们可以做一个测试,删除id为1的部门信息。
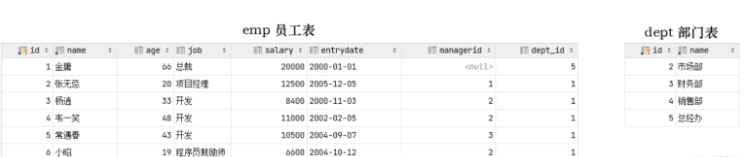
结果,我们看到删除成功,而删除成功之后,部门表不存在id为1的部门,而在emp表中还有很多的员工,关联的为id为1的部门,此时就出现了数据的不完整性。 而要想解决这个问题就得通过数据库的外键约束。
正常开发当中有时候会通过业务代码来控制数据的不完整性,例如删除部门的时候会先根据部门id去查看一下有没有对应的员工表,如果有则删除失败,没有则删除成功。
3、 添加外键的语法
可以在创建表的时候直接添加外键,也可以对现已存在的表添加外键。
(1)方式一
CREATE TABLE 表名( 字段名 数据类型, ... [CONSTRAINT] [外键名称] FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名) );
使用示例:
CREATE TABLE emp ( id INT auto_increment COMMENT 'ID' PRIMARY KEY, NAME VARCHAR ( 50 ) NOT NULL COMMENT '姓名', age INT COMMENT '年龄', job VARCHAR ( 20 ) COMMENT '职位', salary INT COMMENT '薪资', entrydate date COMMENT '入职时间', managerid INT COMMENT '直属领导ID', dept_id INT COMMENT '部门ID', CONSTRAINT fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept (id) ) COMMENT '员工表';
也可以省略掉CONSTRAINT fk_emp_dept_id 这样mysql就会自动给我们起外键名称。
方式二:对现存在的表添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名) ;
使用示例:
alter table emp add constraint fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept(id);
方式三:Navicat添加外键

删除外键:
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
使用示例:
alter table emp drop foreign key fk_emp_dept_id;
4、 删除/更新行为
我们将在父表数据删除时发生的限制行为称为删除/更新行为,此行为是在添加外键之后发生的。具体的删除/更新行为有以下几种:

默认的MySQL 8.0.27版本中,RESTRICT是用于删除和更新行的行为!但是,不同的版本可能会有不同的行为

具体语法为:
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段) REFERENCES 主表名 (主表字段名) ON UPDATE CASCADE ON DELETE CASCADE;
就是比原先添加外键后面多了这些ON UPDATE CASCADE ON DELETE CASCADE,代表的是更新时采用CASCADE ,删除时也采用CASCADE
5、 演示删除/更新行为
(1)演示RESTRICT
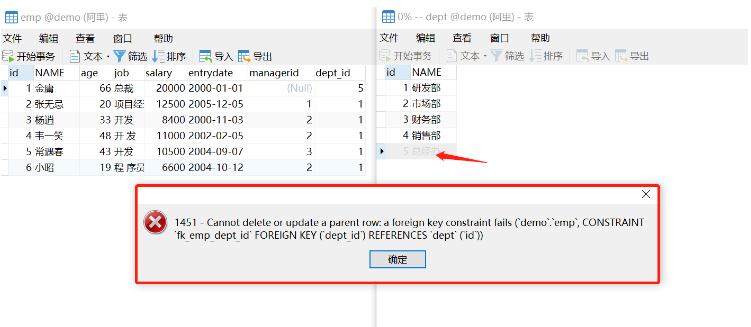
在对父表中的记录进行删除或更新操作时,需要先检查该记录是否存在关联的外键,如果存在,则不允许执行删除或更新操作。 (与 NO ACTION 一致) 默认行为
首先要添加外键,默认是RESTRICT行为!
alter table emp add constraint fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept(id);
删除父表中id为5的记录时,会因为emp表中的dept_id存在5而报错。假如要更新id也同样会报错的!
(2)演示CASCADE
当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有,则
也删除/更新外键在子表中的记录。
删除外键的语法:
ALTER TABLE 表名 DROP FOREIGN KEY 外键约束名;
删除外键的示例:
alter table emp drop foreign key fk_emp_dept_id;
指定外键的删除更新行为为cascade
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update cascade on delete cascade ;
修改父表id为1的记录,将id修改为6

我们发现,原来在子表中dept_id值为1的记录,现在也变为6了,这就是cascade级联的效果。
在一般的业务系统中,不会修改一张表的主键值。
删除父表id为6的记录

我们发现,父表的数据删除成功了,但是子表中关联的记录也被级联删除了。
(3)演示SET NULL
当在父表中删除对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(这就要求该外键允许取null)。
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update set null on delete set null ;
在执行测试之前,我们需要先移除已创建的外键 fk_emp_dept_id。然后再通过数据脚本,将emp、dept表的数据恢复了。
接下来,我们删除id为1的数据,看看会发生什么样的现象。
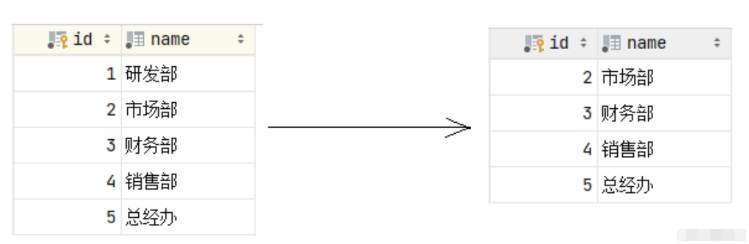
我们发现父表的记录是可以正常的删除的,父表的数据删除之后,再打开子表 emp,我们发现子表emp的dept_id字段,原来dept_id为1的数据,现在都被置为NULL了。
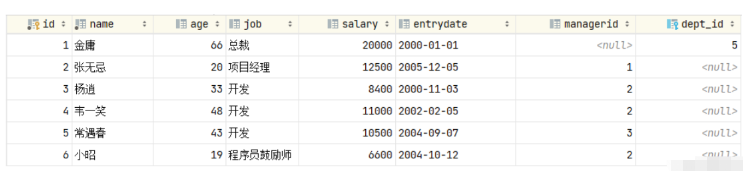
이것은 SET NULL의 삭제/업데이트 동작의 효과입니다.
4. 기본 키 ID로 자동 증가 또는 uuid를 사용하는 것이 더 낫습니까?
MySQL에서는 공식적으로 uuid 또는 불연속적이고 반복되지 않는 눈송이 ID(긴 모양 및 고유)를 사용하지 말 것을 권장합니다. , 그러나 지속적인 자동 증가를 권장합니다. 기본 키 ID를 늘리는 데 대한 공식 권장 사항은 auto_increment인데 uuid를 사용하는 것이 권장되지 않는 이유는 무엇입니까?
1. uuid, 자동 증가 ID 및 난수 삽입 효율성 테스트
먼저 3개의 테이블을 생성합니다. user_auto_key는 id 저장소의 uuid를 나타내고, random_key는 테이블 ID를 나타냅니다. 눈송이 ID입니다. 그러면 jdbc에 연결하여 데이터를 일괄 삽입하는 테스트 결과는 다음과 같습니다.
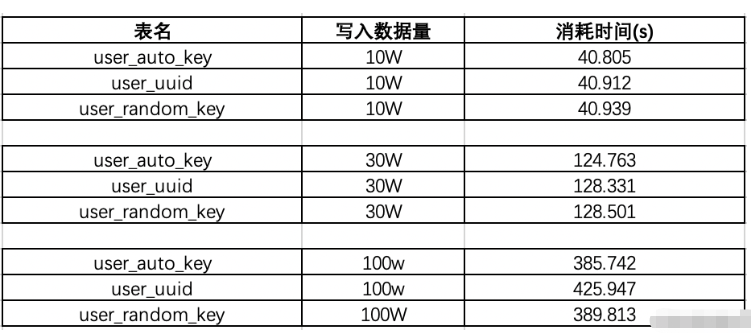
기존 데이터 용량이 130W인 경우: 10w 데이터를 다시 삽입하여 결과가 어떻게 나올지 테스트해 보겠습니다.

할 수 있습니다. 데이터의 양이 100W 정도일 때 uuid의 삽입 효율이 가장 낮고, 후속 시퀀스에서 130W의 데이터가 추가되면 uudi의 시간이 다시 급락합니다. 시간 사용의 전체 효율성 순위는 다음과 같습니다. auto_key>random_key>uuid, uuid는 효율성이 가장 낮습니다
2. 자체 증가 ID 사용의 단점
1. 다른 사람들이 데이터베이스를 크롤링하면 자체 증가 ID를 기반으로 얻을 수 있습니다. 비즈니스 성장 정보를 통해 운영 상황을 쉽게 분석할 수 있습니다.
2. 높은 동시 로드의 경우 innodb는 기본 키에 따라 삽입할 때 명백한 잠금 경합을 일으키며 기본 키의 상한은 경합 핫스팟이 됩니다. 모든 삽입이 여기에서 발생하기 때문에 동시 삽입은 간격 잠금 경쟁으로 이어집니다.
3. Auto_Increment 잠금 메커니즘은 자동 증가 잠금 가져오기를 유발하고 자동 증가가 발생하면 특정 성능 손실이 발생합니다
4. -increment ID에는 데이터 마이그레이션이 포함됩니다. 꽤 번거롭습니다!
5. 그리고 일단 하위 데이터베이스와 하위 테이블의 경우 ID를 자동 증가시키는 것이 꽤 번거롭습니다!
3. uuid 사용의 단점
uuid에는 순차적 자동 증가 ID에 비해 규칙이 없기 때문에 새 행의 값이 반드시 이전 기본 키의 값보다 클 필요는 없으므로 대신 innodb에서 이를 수행할 수 없습니다. 항상 인덱스 끝에 새 행을 삽입하려면 새 공간을 할당하기 위해 새 행에 적합한 새 위치를 찾아야 합니다. 이 과정에는 여러 번의 추가 작업이 필요하며, 데이터의 무질서로 인해 데이터가 흩어지게 되어 다음과 같은 문제가 발생할 수 있습니다.
1. 작성된 대상 페이지가 디스크에 플러시되어 캐시에서 제거되었을 가능성이 있습니다. 또는 캐시에 로드되지 않은 경우 innodb는 삽입하기 전에 디스크에서 메모리로 대상 페이지를 찾아서 읽어야 하며 이로 인해 많은 무작위 IO
2가 발생합니다. 쓰기가 순서에 맞지 않기 때문에 innodb는 해야 합니다. 자주 페이지 분할 작업을 수행하여 새 행에 공간을 할당합니다. 페이지 분할로 인해 한 번 삽입하려면 최소 3페이지를 수정해야 합니다.
3. 페이지 분할이 잦아 페이지가 희박해지고 불규칙해집니다. .Filling은 결국 데이터 조각화로 이어질 것입니다.
uuid는 실제로 이 문제를 일으킬 수 있지만 Snowflake 알고리즘은 당연히 새로 삽입된 ID가 가장 클 것이라고 생각합니다. 눈송이 알고리즘을 사용하는 것은 매우 좋은 선택입니다!
5. 실제 개발에서는 외래 키를 최대한 적게 사용하세요
기본 키와 인덱스는 데이터 검색 속도를 최적화할 수 있을 뿐만 아니라 개발자가 다른 작업을 저장할 수도 있습니다.
충돌 초점: 데이터베이스 설계에 외래 키가 필요한지 여부. 여기에는 두 가지 질문이 있습니다.
첫 번째는 데이터베이스 데이터의 무결성과 일관성을 보장하는 방법입니다.
두 번째는 첫 번째 질문이 성능에 미치는 영향입니다.
참고로 찬반론 두 가지 관점으로 나누어져 있습니다!
1. 긍정적인 관점
1. 데이터베이스 자체가 데이터 일관성과 무결성을 보장하며, 프로그램이 100% 데이터 무결성을 보장하기 어렵고, 데이터베이스 서버에서도 외래 키를 사용하기 때문에 더 안정적입니다. 충돌이나 기타 문제가 발생하면 데이터 일관성과 무결성이 최대한 보장될 수 있습니다.
2. 기본 키와 외래 키를 사용하여 데이터베이스를 설계하면 ER 다이어그램의 가독성이 높아질 수 있으며 이는 데이터베이스 설계에서 매우 중요합니다.
3. 외래 키로 어느 정도 설명되는 비즈니스 로직은 디자인을 사려 깊고 구체적이며 포괄적으로 만듭니다.
데이터베이스와 애플리케이션 사이에는 일대다 관계가 있습니다. 애플리케이션 A는 데이터의 일부의 무결성을 유지합니다. 시스템이 커지면 애플리케이션 A와 B가 서로 다른 개발을 통해 추가될 수 있습니다. 팀. 데이터 무결성을 보장하기 위해 어떻게 조율하고, 1년 후에 새로운 C 애플리케이션이 추가되면 어떻게 처리하나요?
2. 반대 뷰
1. 데이터 무결성을 보장하기 위해 트리거나 애플리케이션을 사용할 수 있습니다
2. 기본 키/외래 키를 과도하게 사용하면 개발이 어려워지고 테이블이 너무 많아지는 등의 문제가 발생합니다. 외래 키를 사용하지 않을 경우 데이터 관리가 간단하고 조작이 편리하며 성능이 높습니다(데이터 삽입, 업데이트, 삭제 시 가져오기, 내보내기 등의 작업이 더 빨라짐)
대량 데이터베이스의 외래 키는 생각하지 마세요. 프로그램이 매일 수백만 개의 레코드를 삽입해야 한다면 외래 키 제약 조건이 있을 때마다 해당 레코드가 적합한지 검사해야 합니다. 필드가 두 개 이상이면 스캔 횟수가 기하급수적으로 늘어납니다. 내 프로그램 중 하나가 3시간 만에 완료되었습니다. 외래 키를 추가하면 28시간이 걸립니다!
3. 결론
1. 대규모 시스템(낮은 성능 요구 사항, 높은 보안 요구 사항)에서는 외래 키를 사용하고(고성능 요구 사항은 자체 보안 제어) 소규모 시스템에서는 외래 키가 필요하지 않습니다. 무엇이든 외래 키를 사용하는 것이 좋습니다.
2. 외래 키를 적절하게 사용하고 과도하게 사용하지 마세요.
데이터의 일관성과 무결성을 보장하기 위해 외래 키를 사용하지 않고도 프로그램을 통해 제어할 수 있습니다. 이때, 데이터 보호를 구현하기 위해 레이어를 작성해야 하며, 이 레이어를 통해 데이터베이스의 다양한 애플리케이션에 접근할 수 있습니다.
참고:
MySQL에서는 외래 키 사용을 허용하지만 무결성 검사를 위해 InnoDB 테이블 유형을 제외한 모든 테이블 유형에서 이 기능이 무시됩니다. 이는 이상하게 보일 수 있지만 실제로는 매우 정상입니다. 데이터베이스의 모든 외래 키를 삽입, 업데이트 및 삭제할 때마다 무결성 검사를 수행하는 것은 성능에 영향을 줄 수 있는 시간과 리소스를 소모하는 프로세스입니다. 특히 복잡한 또는 권선 연결 수. 따라서 사용자는 테이블을 기반으로 특정 요구에 맞는 것을 선택할 수 있습니다.
따라서 더 나은 성능이 필요하고 무결성 검사가 필요하지 않은 경우 MySQL에서 참조 무결성을 기반으로 테이블을 구축하고 이를 기반으로 좋은 성능을 유지하려면 MyISAM 테이블 유형을 사용하도록 선택할 수 있습니다. 좋은 선택 테이블 구조는 innoDB 유형입니다
위 내용은 MySQL의 제약은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7460
7460
 15
1376
52
77
11
44
19
17
17
15
1376
52
77
11
44
19
17
17

 MySQL 사용자와 데이터베이스의 관계
Apr 08, 2025 pm 07:15 PM
MySQL 사용자와 데이터베이스의 관계
Apr 08, 2025 pm 07:15 PM
MySQL 데이터베이스에서 사용자와 데이터베이스 간의 관계는 권한과 테이블로 정의됩니다. 사용자는 데이터베이스에 액세스 할 수있는 사용자 이름과 비밀번호가 있습니다. 권한은 보조금 명령을 통해 부여되며 테이블은 Create Table 명령에 의해 생성됩니다. 사용자와 데이터베이스 간의 관계를 설정하려면 데이터베이스를 작성하고 사용자를 생성 한 다음 권한을 부여해야합니다.
 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 Redshift Zero ETL과의 RDS MySQL 통합
Apr 08, 2025 pm 07:06 PM
Redshift Zero ETL과의 RDS MySQL 통합
Apr 08, 2025 pm 07:06 PM
데이터 통합 단순화 : AmazonRdsMysQL 및 Redshift의 Zero ETL 통합 효율적인 데이터 통합은 데이터 중심 구성의 핵심입니다. 전통적인 ETL (추출, 변환,로드) 프로세스는 특히 데이터베이스 (예 : AmazonRDSMySQL)를 데이터웨어 하우스 (예 : Redshift)와 통합 할 때 복잡하고 시간이 많이 걸립니다. 그러나 AWS는 이러한 상황을 완전히 변경 한 Zero ETL 통합 솔루션을 제공하여 RDSMYSQL에서 Redshift로 데이터 마이그레이션을위한 단순화 된 거의 실시간 솔루션을 제공합니다. 이 기사는 RDSMYSQL ZERL ETL 통합으로 Redshift와 함께 작동하여 데이터 엔지니어 및 개발자에게 제공하는 장점과 장점을 설명합니다.
 MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL은 설치가 간단하고 강력하며 데이터를 쉽게 관리하기 쉽기 때문에 초보자에게 적합합니다. 1. 다양한 운영 체제에 적합한 간단한 설치 및 구성. 2. 데이터베이스 및 테이블 작성, 삽입, 쿼리, 업데이트 및 삭제와 같은 기본 작업을 지원합니다. 3. 조인 작업 및 하위 쿼리와 같은 고급 기능을 제공합니다. 4. 인덱싱, 쿼리 최적화 및 테이블 파티셔닝을 통해 성능을 향상시킬 수 있습니다. 5. 데이터 보안 및 일관성을 보장하기위한 지원 백업, 복구 및 보안 조치.
 MySQL 사용자 이름 및 비밀번호를 작성하는 방법
Apr 08, 2025 pm 07:09 PM
MySQL 사용자 이름 및 비밀번호를 작성하는 방법
Apr 08, 2025 pm 07:09 PM
MySQL 사용자 이름 및 비밀번호를 작성하려면 : 1. 사용자 이름과 비밀번호를 결정합니다. 2. 데이터베이스에 연결; 3. 사용자 이름과 비밀번호를 사용하여 쿼리 및 명령을 실행하십시오.
 MySQL의 쿼리 최적화는 데이터베이스 성능을 향상시키는 데 필수적입니다. 특히 대규모 데이터 세트를 처리 할 때
Apr 08, 2025 pm 07:12 PM
MySQL의 쿼리 최적화는 데이터베이스 성능을 향상시키는 데 필수적입니다. 특히 대규모 데이터 세트를 처리 할 때
Apr 08, 2025 pm 07:12 PM
1. 올바른 색인을 사용하여 스캔 한 데이터의 양을 줄임으로써 데이터 검색 속도를 높이십시오. 테이블 열을 여러 번 찾으면 해당 열에 대한 인덱스를 만듭니다. 귀하 또는 귀하의 앱이 기준에 따라 여러 열에서 데이터가 필요한 경우 복합 인덱스 2를 만듭니다. 2. 선택을 피하십시오 * 필요한 열만 선택하면 모든 원치 않는 열을 선택하면 더 많은 서버 메모리를 선택하면 서버가 높은 부하 또는 주파수 시간으로 서버가 속도가 느려지며, 예를 들어 Creation_at 및 Updated_at 및 Timestamps와 같은 열이 포함되어 있지 않기 때문에 쿼리가 필요하지 않기 때문에 테이블은 선택을 피할 수 없습니다.
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 산성 특성 이해 : 신뢰할 수있는 데이터베이스의 기둥
Apr 08, 2025 pm 06:33 PM
산성 특성 이해 : 신뢰할 수있는 데이터베이스의 기둥
Apr 08, 2025 pm 06:33 PM
데이터베이스 산 속성에 대한 자세한 설명 산 속성은 데이터베이스 트랜잭션의 신뢰성과 일관성을 보장하기위한 일련의 규칙입니다. 데이터베이스 시스템이 트랜잭션을 처리하는 방법을 정의하고 시스템 충돌, 전원 중단 또는 여러 사용자의 동시 액세스가 발생할 경우에도 데이터 무결성 및 정확성을 보장합니다. 산 속성 개요 원자력 : 트랜잭션은 불가분의 단위로 간주됩니다. 모든 부분이 실패하고 전체 트랜잭션이 롤백되며 데이터베이스는 변경 사항을 유지하지 않습니다. 예를 들어, 은행 송금이 한 계정에서 공제되지만 다른 계정으로 인상되지 않은 경우 전체 작업이 취소됩니다. BeginTransaction; updateAccountssetBalance = Balance-100WH
