

Python에서 의사결정 트리 분류 알고리즘을 구현하는 방법

사전 정보
1. 결정 트리
재작성된 문장: 지도 학습에서 일반적으로 사용되는 분류 알고리즘은 결정 트리입니다. 이는 일련의 샘플을 기반으로 하며 각 샘플에는 일련의 속성과 해당 분류 결과가 포함됩니다. 이러한 샘플을 학습에 사용하면 알고리즘은 새로운 데이터를 올바르게 분류할 수 있는 의사결정 트리를 생성할 수 있습니다
2. 샘플 데이터
기존 사용자가 14명이고 이들의 개인 속성과 특정 제품 구매 여부에 대한 데이터가 다음과 같다고 가정합니다.
| 번호 | 나이 | 소득 범위 | 직업 특성 | 신용 등급 | 구매 결정 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 01 | 높음 | 불안정 | 나쁨 아니요 | 불안정나쁨 | |||||||||
| 04 | >40 | Medium | 불안정 | 나쁨 | |||||||||
| 05 | >40 | 낮음 | 안정 | 나쁨 | |||||||||
| 06 | >40 | 낮음 | 안정 | 좋음 | |||||||||
| 07 | 30-40 | 낮음 | 안정 | 좋아요 | |||||||||
| 08 | 보통 | 불안정 | 나쁨 | ||||||||||
| 09 | 낮음 | 안정 | 나쁨 | ||||||||||
| 10 | >40 | 보통 | 안정 | 나쁨 | |||||||||
| 11 | 보통 | 안정 | 좋음 | ||||||||||
| 12 | 30-40 | 중간 | 불안정 | 좋음 | |||||||||
| 13 | 30-40 | 높음 | 안정 | 나쁨 | |||||||||
| 14 | >40 | 보통 | 불안정 | 좋아요 | |||||||||
| Age | 소득 범위 | 업무 성격 | 신용 등급 |
|---|---|---|---|
| <30 | low | stable | good |
| <30 | high | unstable | good |
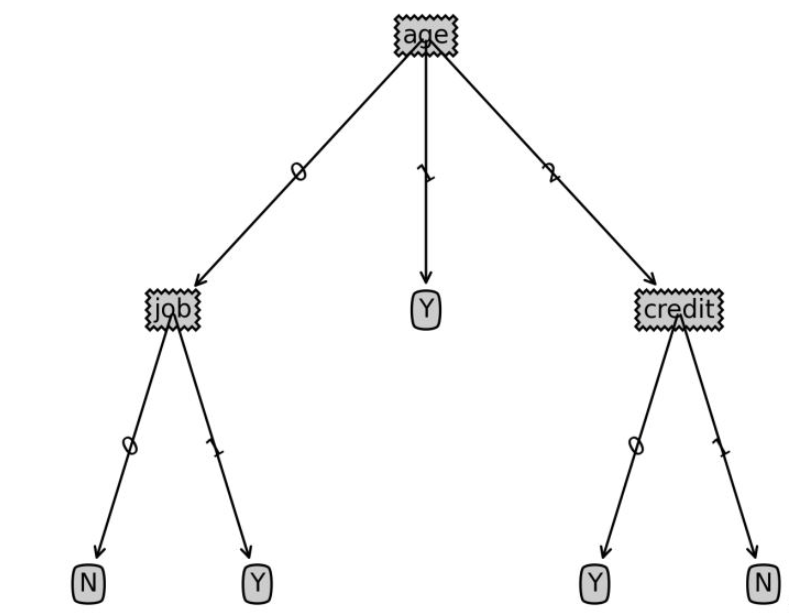
def classify(inputtree,featlabels,testvec): firststr = list(inputtree.keys())[0] seconddict = inputtree[firststr] featindex = featlabels.index(firststr) for key in seconddict.keys(): if testvec[featindex]==key: if type(seconddict[key]).__name__=='dict': classlabel=classify(seconddict[key],featlabels,testvec) else: classlabel=seconddict[key] return classlabel로그인 후 복사labels=['age','income','job','credit'] tsvec=[0,0,1,1] print('result:',classify(Tree,labels,tsvec)) tsvec1=[0,2,0,1] print('result1:',classify(Tree,labels,tsvec1))로그인 후 복사
결과: : N
포스트정보: 의사결정나무 code
다음 코드는 의사결정트리 그래픽, 비의사결정트리 알고리즘 포커스를 그리는 데 사용됩니다. 관심 있는 경우 학습에 참고할 수 있습니다
import matplotlib.pyplot as plt
decisionNode = dict(box, fc="0.8")
leafNode = dict(box, fc="0.8")
arrow_args = dict(arrow)
#获取叶节点的数目
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#测试节点的数据是否为字典,以此判断是否为叶节点
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
#获取树的层数
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#测试节点的数据是否为字典,以此判断是否为叶节点
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
#绘制节点
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args )
#绘制连接线
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
#绘制树结构
def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) #this determines the x width of this tree
depth = getTreeDepth(myTree)
firstStr = list(myTree.keys())[0] #the text label for this node should be this
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
plotTree(secondDict[key],cntrPt,str(key)) #recursion
else: #it's a leaf node print the leaf node
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
#创建决策树图形
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #no ticks
#createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;
plotTree(inTree, (0.5,1.0), '')
plt.savefig('决策树.png',dpi=300,bbox_inches='tight')
plt.show()위 내용은 Python에서 의사결정 트리 분류 알고리즘을 구현하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7546
7546
 15
1381
52
83
11
57
19
21
89
15
1381
52
83
11
57
19
21
89

 PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP 및 Python : 코드 예제 및 비교
Apr 15, 2025 am 12:07 AM
PHP와 Python은 고유 한 장점과 단점이 있으며 선택은 프로젝트 요구와 개인 선호도에 달려 있습니다. 1.PHP는 대규모 웹 애플리케이션의 빠른 개발 및 유지 보수에 적합합니다. 2. Python은 데이터 과학 및 기계 학습 분야를 지배합니다.
 Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
Centos에서 Pytorch에 대한 GPU 지원은 어떻습니까?
Apr 14, 2025 pm 06:48 PM
CentOS 시스템에서 Pytorch GPU 가속도를 활성화하려면 Cuda, Cudnn 및 GPU 버전의 Pytorch를 설치해야합니다. 다음 단계는 프로세스를 안내합니다. CUDA 및 CUDNN 설치 CUDA 버전 호환성 결정 : NVIDIA-SMI 명령을 사용하여 NVIDIA 그래픽 카드에서 지원하는 CUDA 버전을보십시오. 예를 들어, MX450 그래픽 카드는 CUDA11.1 이상을 지원할 수 있습니다. Cudatoolkit 다운로드 및 설치 : NVIDIACUDATOOLKIT의 공식 웹 사이트를 방문하여 그래픽 카드에서 지원하는 가장 높은 CUDA 버전에 따라 해당 버전을 다운로드하여 설치하십시오. CUDNN 라이브러리 설치 :
 Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker 원리에 대한 자세한 설명
Apr 14, 2025 pm 11:57 PM
Docker는 Linux 커널 기능을 사용하여 효율적이고 고립 된 응용 프로그램 실행 환경을 제공합니다. 작동 원리는 다음과 같습니다. 1. 거울은 읽기 전용 템플릿으로 사용되며, 여기에는 응용 프로그램을 실행하는 데 필요한 모든 것을 포함합니다. 2. Union 파일 시스템 (Unionfs)은 여러 파일 시스템을 스택하고 차이점 만 저장하고 공간을 절약하고 속도를 높입니다. 3. 데몬은 거울과 컨테이너를 관리하고 클라이언트는 상호 작용을 위해 사용합니다. 4. 네임 스페이스 및 CGroup은 컨테이너 격리 및 자원 제한을 구현합니다. 5. 다중 네트워크 모드는 컨테이너 상호 연결을 지원합니다. 이러한 핵심 개념을 이해 함으로써만 Docker를 더 잘 활용할 수 있습니다.
 Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript : 커뮤니티, 라이브러리 및 리소스
Apr 15, 2025 am 12:16 AM
Python과 JavaScript는 커뮤니티, 라이브러리 및 리소스 측면에서 고유 한 장점과 단점이 있습니다. 1) Python 커뮤니티는 친절하고 초보자에게 적합하지만 프론트 엔드 개발 리소스는 JavaScript만큼 풍부하지 않습니다. 2) Python은 데이터 과학 및 기계 학습 라이브러리에서 강력하며 JavaScript는 프론트 엔드 개발 라이브러리 및 프레임 워크에서 더 좋습니다. 3) 둘 다 풍부한 학습 리소스를 가지고 있지만 Python은 공식 문서로 시작하는 데 적합하지만 JavaScript는 MDNWebDocs에서 더 좋습니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 미니 오펜 센토 호환성
Apr 14, 2025 pm 05:45 PM
미니 오펜 센토 호환성
Apr 14, 2025 pm 05:45 PM
Minio Object Storage : Centos System Minio 하의 고성능 배포는 Go Language를 기반으로 개발 한 고성능 분산 객체 저장 시스템입니다. Amazons3과 호환됩니다. Java, Python, JavaScript 및 Go를 포함한 다양한 클라이언트 언어를 지원합니다. 이 기사는 CentOS 시스템에 대한 Minio의 설치 및 호환성을 간단히 소개합니다. CentOS 버전 호환성 Minio는 다음을 포함하되 이에 국한되지 않는 여러 CentOS 버전에서 확인되었습니다. CentOS7.9 : 클러스터 구성, 환경 준비, 구성 파일 설정, 디스크 파티셔닝 및 미니를 다루는 완전한 설치 안내서를 제공합니다.
 Centos에서 Pytorch의 분산 교육을 운영하는 방법
Apr 14, 2025 pm 06:36 PM
Centos에서 Pytorch의 분산 교육을 운영하는 방법
Apr 14, 2025 pm 06:36 PM
CentOS 시스템에 대한 Pytorch 분산 교육에는 다음 단계가 필요합니다. Pytorch 설치 : 전제는 Python과 PIP가 CentOS 시스템에 설치된다는 것입니다. CUDA 버전에 따라 Pytorch 공식 웹 사이트에서 적절한 설치 명령을 받으십시오. CPU 전용 교육의 경우 다음 명령을 사용할 수 있습니다. PipinStalltorchtorchvisiontorchaudio GPU 지원이 필요한 경우 CUDA 및 CUDNN의 해당 버전이 설치되어 있는지 확인하고 해당 PyTorch 버전을 설치하려면 설치하십시오. 분산 환경 구성 : 분산 교육에는 일반적으로 여러 기계 또는 단일 기계 다중 GPU가 필요합니다. 장소
 Centos에 nginx를 설치하는 방법
Apr 14, 2025 pm 08:06 PM
Centos에 nginx를 설치하는 방법
Apr 14, 2025 pm 08:06 PM
Centos Nginx를 설치하려면 다음 단계를 수행해야합니다. 개발 도구, PCRE-DEVEL 및 OPENSSL-DEVEL과 같은 종속성 설치. nginx 소스 코드 패키지를 다운로드하고 압축을 풀고 컴파일하고 설치하고 설치 경로를/usr/local/nginx로 지정하십시오. nginx 사용자 및 사용자 그룹을 만들고 권한을 설정하십시오. 구성 파일 nginx.conf를 수정하고 청취 포트 및 도메인 이름/IP 주소를 구성하십시오. Nginx 서비스를 시작하십시오. 종속성 문제, 포트 충돌 및 구성 파일 오류와 같은 일반적인 오류는주의를 기울여야합니다. 캐시를 켜고 작업자 프로세스 수 조정과 같은 특정 상황에 따라 성능 최적화를 조정해야합니다.
 Centos에서 Pytorch 버전을 선택하는 방법
Apr 14, 2025 pm 06:51 PM
Centos에서 Pytorch 버전을 선택하는 방법
Apr 14, 2025 pm 06:51 PM
CentOS 시스템에 Pytorch를 설치할 때는 적절한 버전을 신중하게 선택하고 다음 주요 요소를 고려해야합니다. 1. 시스템 환경 호환성 : 운영 체제 : CentOS7 이상을 사용하는 것이 좋습니다. Cuda 및 Cudnn : Pytorch 버전 및 Cuda 버전은 밀접하게 관련되어 있습니다. 예를 들어, pytorch1.9.0은 cuda11.1을 필요로하고 Pytorch2.0.1은 cuda11.3을 필요로합니다. CUDNN 버전도 CUDA 버전과 일치해야합니다. Pytorch 버전을 선택하기 전에 호환 CUDA 및 CUDNN 버전이 설치되었는지 확인하십시오. 파이썬 버전 : Pytorch 공식 지점
