

Docker와 Canal을 기반으로 MySQL 실시간 증분 데이터 전송 기능을 구현하는 방법

운하 소개
운하의 역사적 기원
초창기에는 Alibaba가 항저우와 미국의 컴퓨터실에 데이터베이스 인스턴스를 배포했지만 컴퓨터실 전체의 데이터를 동기화해야 하는 비즈니스 요구로 인해 캐널은 점진적인 변화를 얻기 위해 주로 트리거(trigger) 방식을 기반으로 구상하고 탄생하기 어려웠습니다. 2010년부터 Alibaba는 동기화를 위해 점진적으로 변경된 데이터를 얻기 위해 데이터베이스 로그 분석을 점진적으로 시도하기 시작했으며, 그 결과 점진적인 구독 및 소비 사업이 탄생했습니다.
Canal에서 지원하는 현재 데이터 소스 mysql 버전은 5.1.x, 5.5.x, 5.6.x, 5.7.x, 8.0.x입니다.
운하 적용 시나리오
현재 증분 로그 구독 및 소비를 기반으로 하는 비즈니스는 주로 다음과 같습니다.
데이터베이스 증분 로그 구문 분석을 기반으로 증분 데이터 구독 및 소비 제공
데이터베이스 미러 데이터베이스 실시간 백업
인덱스 생성 및 실시간 유지 관리(분할 이종 인덱스, 역 인덱스 등)
비즈니스 캐시 새로 고침
비즈니스 로직을 사용한 증분 데이터 처리
캐널 작동 방식
운하의 원리를 소개하기 전에 먼저 mysql 마스터-슬레이브 복제의 원리를 이해해 봅시다.
mysql 마스터-슬레이브 복제 원칙
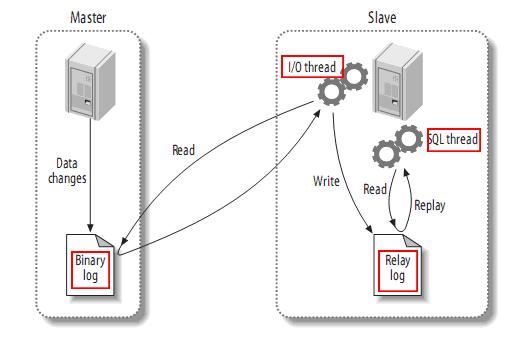
mysql 마스터는 바이너리 로그에 데이터 변경 작업을 기록합니다. 기록된 내용을 바이너리 로그 이벤트라고 하며, 이는 show binlog events 명령 View
를 통해 수행할 수 있습니다. mysql 슬레이브는 마스터 바이너리 로그의 바이너리 로그 이벤트를 릴레이 로그에 복사합니다.
mysql 슬레이브는 릴레이 로그의 이벤트를 다시 읽고 실행하여 데이터 변경 사항을 자체 데이터베이스 테이블에 매핑합니다
mysql의 작동 원리를 이해하면 canal도 유사한 논리를 사용하여 증분 데이터 구독 기능을 구현해야 한다고 대략 추측할 수 있습니다. 그런 다음 canal이 실제로 어떻게 작동하는지 살펴보겠습니다.
canal 작동 원리
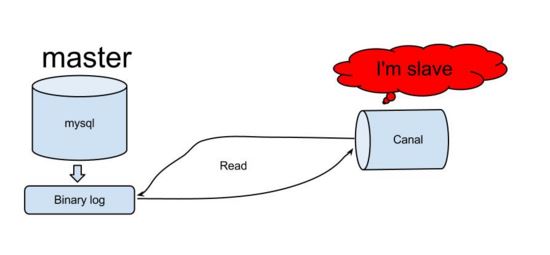
canal은 mysql 슬레이브의 상호 작용 프로토콜을 시뮬레이션하고, 자신을 mysql 슬레이브로 위장하고, 덤프 프로토콜을 mysql 마스터로 보냅니다.
mysql 마스터가 덤프 요청을 수신하고 바이너리 푸시를 시작합니다. log to Slave(canal이라고도 함)
canal은 바이너리 로그 객체를 구문 분석합니다(데이터는 바이트 스트림입니다)
이 원칙과 방법을 기반으로 데이터베이스 증분 로그 수집 및 분석을 완료하고 증분 로그를 제공할 수 있습니다. 데이터 구독 및 소비는 mysql 실시간 증분 데이터 전송 기능을 실현합니다.
canal은 그러한 프레임워크이고 순수 Java 언어로 작성되었으므로 이를 사용하는 방법을 배우고 실제 작업에 적용하는 방법을 배우기 시작합니다.
canal의 도커 환경 준비
현재 컨테이너화 기술의 인기로 인해 이 기사에서는 도커를 사용하여 개발 환경을 빠르게 구축하는 전통적인 방식에 대해 도커 컨테이너 환경 구축 방법을 배운 후, 우리는 또한 그것에 의지할 수 있습니다. 박으로 칠한 국자가 성공적으로 만들어졌습니다. 이번 글에서는 canal에 대해 주로 설명하기 때문에 docker에 대해서는 많이 다루지 않고 docker의 기본 개념과 명령어 사용법에 대해서만 소개하겠습니다. 더 많은 컨테이너 기술 전문가와 소통하고 싶다면 WeChat liyingjiese에 저를 추가하고 "그룹 추가"라고 언급하시면 됩니다. 매주 전 세계 주요 기업의 우수사례와 최신 업계 동향을 담은 그룹입니다.
docker란 무엇입니까
vmware를 사용하여 환경을 구축하는 경우에는 대부분의 사람들이 가상 머신인 vmware를 사용했다고 생각합니다. 일반 시스템 이미지만 제공하고 성공적으로 설치하면 되며, 나머지 소프트웨어 환경과 응용 프로그램은 다음과 같습니다. 구성은 로컬 머신에서와 마찬가지로 여전히 가상 머신에서 이루어지며 vmware는 호스트 리소스를 많이 차지하므로 호스트가 쉽게 정지될 수 있으며 시스템 이미지 자체도 너무 많은 공간을 차지합니다.
도커는 누구나 쉽게 이해할 수 있도록 vmware와 비교해 소개하겠습니다. 도커는 앱(애플리케이션)을 기본 인프라(인프라)와 분리하는 앱 시작, 패키징, 실행을 위한 플랫폼을 제공합니다. . Docker에서 가장 중요한 두 가지 개념은 이미지(vmware의 시스템 이미지와 유사)와 컨테이너(vmware에 설치된 시스템과 유사)입니다.
이미지란 무엇입니까(미러)
파일 및 메타데이터 모음(루트 파일 시스템)
-
계층으로 구성되어 있으며, 각 계층은 파일을 추가, 변경, 삭제하여 새로운 이미지가 될 수 있습니다
다른 이미지가 동일한 레이어를 공유할 수 있습니다
이미지 자체는 읽기 전용입니다.

컨테이너란 무엇인가요?
이미지별로 생성(복사)
이미지 레이어 위에 컨테이너 레이어(읽기 및 쓰기 가능)를 설정합니다.
비유 객체 지향: 클래스와 인스턴스
이미지는 앱의 저장과 배포를 담당하며 컨테이너는 앱 실행을 담당합니다
Docker 네트워크 소개
Docker에는 세 가지 네트워크 유형이 있습니다.
bridge: 브리지 네트워크. 기본적으로 시작된 도커 컨테이너는 도커 설치 중에 생성된 브리지 네트워크를 사용하며, 도커 컨테이너가 다시 시작될 때마다 해당 IP 주소가 순서대로 획득됩니다.
none: 지정된 네트워크가 없습니다. --network=none을 사용하면 Docker 컨테이너가 LAN IP를 할당하지 않습니다.
호스트: 호스트 네트워크입니다. --network=host를 사용하면 Docker 컨테이너는 호스트와 네트워크를 공유하고 두 호스트는 서로 통신할 수 있습니다. 컨테이너의 포트 8080에서 수신 대기하는 웹 서비스를 실행할 때 컨테이너는 자동으로 호스트의 포트 8080에 매핑됩니다.
사용자 정의 네트워크 만들기: (고정 IP 설정)
docker network create --subnet=172.18.0.0/16 mynetwork
기존 네트워크 유형 docker 네트워크 ls 보기:

운하 환경 구축
첨부된 것은 docker 다운로드 및 설치 주소입니다 ==> ; 도커 다운로드.
운하 이미지 docker pull canal/canal-server 다운로드: docker pull canal/canal-server:
下载mysql镜像docker pull mysql,下载过的则如下图:

查看已经下载好的镜像docker images:

接下来通过镜像生成mysql容器与canal-server容器:
##生成mysql容器 docker run -d --name mysql --net mynetwork --ip 172.18.0.6 -p 3306:3306 -e mysql_root_password=root mysql ##生成canal-server容器 docker run -d --name canal-server --net mynetwork --ip 172.18.0.4 -p 11111:11111 canal/canal-server ## 命令介绍 --net mynetwork #使用自定义网络 --ip #指定分配ip
查看docker中运行的容器docker ps:

mysql的配置修改
以上只是初步准备好了基础的环境,但是怎么让canal伪装成salve并正确获取mysql中的binary log呢?
对于自建mysql,需要先开启binlog写入功能,配置binlog-format为row模式,通过修改mysql配置文件来开启bin_log,使用find / -name my.cnf查找my.cnf,修改文件内容如下:
[mysqld] log-bin=mysql-bin # 开启binlog binlog-format=row # 选择row模式 server_id=1 # 配置mysql replaction需要定义,不要和canal的slaveid重复
进入mysql容器docker exec -it mysql bash。
创建链接mysql的账号canal并授予作为mysql slave的权限,如果已有账户可直接grant:
mysql -uroot -proot # 创建账号 create user canal identified by 'canal'; # 授予权限 grant select, replication slave, replication client on *.* to 'canal'@'%'; -- grant all privileges on *.* to 'canal'@'%' ; # 刷新并应用 flush privileges;
数据库重启后,简单测试 my.cnf 配置是否生效:
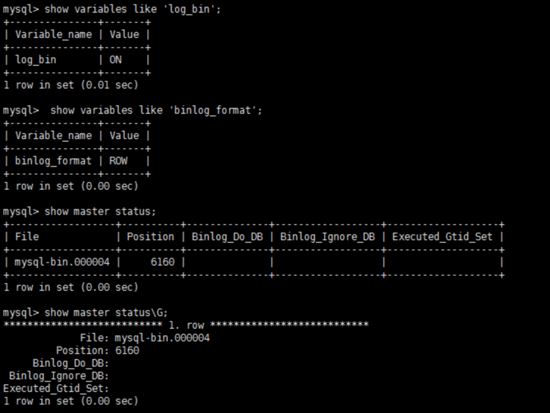
show variables like 'log_bin'; show variables like 'log_bin'; show master status;
canal-server的配置修改
进入canal-server容器docker exec -it canal-server bash。
编辑canal-server的配置vi canal-server/conf/example/instance.properties:

更多配置请参考==>canal配置说明 。
重启canal-server容器docker restart canal-server

mysql 이미지 docker pull mysql을 다운로드하면 아래와 같습니다.
다운로드한 이미지 보기 미러 도커 이미지:
다음으로 미러를 통해 mysql 컨테이너와 canal-server 컨테이너를 생성합니다.
docker exec -it canal-server bash tail -100f canal-server/logs/example/example.log
docker docker ps에서 실행 중인 컨테이너 보기: 
mysql 설정 수정
위는 기본 환경에 대한 사전 준비일 뿐인데 어떻게 운하를 연고로 위장하고 mysql에서 바이너리 로그를 올바르게 얻을 수 있을까요? 자체 구축된 mysql의 경우 먼저 binlog 쓰기 기능을 활성화하고,binlog-format을 행 모드로 구성하고, mysql 구성 파일을 수정하여 bin_log를 활성화하고, find / -를 사용해야 합니다. name my.cnf my.cnf를 찾아 다음과 같이 파일 내용을 수정합니다. # 下载对镜像 docker pull elasticsearch:7.1.1 docker pull mobz/elasticsearch-head:5-alpine # 创建容器并运行 docker run -d --name elasticsearch --net mynetwork --ip 172.18.0.2 -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.1.1 docker run -d --name elasticsearch-head --net mynetwork --ip 172.18.0.5 -p 9100:9100 mobz/elasticsearch-head:5-alpine
docker exec -it mysql bash를 입력합니다. mysql에 연결된 계정 운하를 만들고 mysql 슬레이브가 될 수 있는 권한을 부여합니다. 이미 계정이 있는 경우 다음을 직접 부여할 수 있습니다. 🎜package com.example.canal.study.pojo;
import lombok.data;
import java.io.serializable;
// @data 用户生产getter、setter方法
@data
public class student implements serializable {
private string id;
private string name;
private int age;
private string sex;
private string city;
}🎜package com.example.canal.study.common;
import com.alibaba.otter.canal.client.canalconnector;
import com.alibaba.otter.canal.client.canalconnectors;
import org.apache.http.httphost;
import org.elasticsearch.client.restclient;
import org.elasticsearch.client.resthighlevelclient;
import org.springframework.beans.factory.annotation.value;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
import java.net.inetsocketaddress;
/**
* @author haha
*/
@configuration
public class canalconfig {
// @value 获取 application.properties配置中端内容
@value("${canal.server.ip}")
private string canalip;
@value("${canal.server.port}")
private integer canalport;
@value("${canal.destination}")
private string destination;
@value("${elasticsearch.server.ip}")
private string elasticsearchip;
@value("${elasticsearch.server.port}")
private integer elasticsearchport;
@value("${zookeeper.server.ip}")
private string zkserverip;
// 获取简单canal-server连接
@bean
public canalconnector canalsimpleconnector() {
canalconnector canalconnector = canalconnectors.newsingleconnector(new inetsocketaddress(canalip, canalport), destination, "", "");
return canalconnector;
}
// 通过连接zookeeper获取canal-server连接
@bean
public canalconnector canalhaconnector() {
canalconnector canalconnector = canalconnectors.newclusterconnector(zkserverip, destination, "", "");
return canalconnector;
}
// elasticsearch 7.x客户端
@bean
public resthighlevelclient resthighlevelclient() {
resthighlevelclient client = new resthighlevelclient(
restclient.builder(new httphost(elasticsearchip, elasticsearchport))
);
return client;
}
}docker exec -it canal-server bash로 수정합니다. 🎜🎜 운하 서버 구성 편집 vi canal-server/conf/example/instance.properties: 🎜🎜🎜🎜자세한 구성은 ==>canal 구성 지침을 참조하세요. 🎜🎜canal-server 컨테이너 다시 시작 docker restart canal-server 시작 로그를 보려면 컨테이너를 입력하세요. 🎜public static class twotuple<a, b> {
public final a eventtype;
public final b columnmap;
public twotuple(a a, b b) {
eventtype = a;
columnmap = b;
}
}
public static list<twotuple<eventtype, map>> printentry(list<entry> entrys) {
list<twotuple<eventtype, map>> rows = new arraylist<>();
for (entry entry : entrys) {
// binlog event的事件事件
long executetime = entry.getheader().getexecutetime();
// 当前应用获取到该binlog锁延迟的时间
long delaytime = system.currenttimemillis() - executetime;
date date = new date(entry.getheader().getexecutetime());
simpledateformat simpledateformat = new simpledateformat("yyyy-mm-dd hh:mm:ss");
// 当前的entry(binary log event)的条目类型属于事务
if (entry.getentrytype() == entrytype.transactionbegin || entry.getentrytype() == entrytype.transactionend) {
if (entry.getentrytype() == entrytype.transactionbegin) {
transactionbegin begin = null;
try {
begin = transactionbegin.parsefrom(entry.getstorevalue());
} catch (invalidprotocolbufferexception e) {
throw new runtimeexception("parse event has an error , data:" + entry.tostring(), e);
}
// 打印事务头信息,执行的线程id,事务耗时
logger.info(transaction_format,
new object[]{entry.getheader().getlogfilename(),
string.valueof(entry.getheader().getlogfileoffset()),
string.valueof(entry.getheader().getexecutetime()),
simpledateformat.format(date),
entry.getheader().getgtid(),
string.valueof(delaytime)});
logger.info(" begin ----> thread id: {}", begin.getthreadid());
printxainfo(begin.getpropslist());
} else if (entry.getentrytype() == entrytype.transactionend) {
transactionend end = null;
try {
end = transactionend.parsefrom(entry.getstorevalue());
} catch (invalidprotocolbufferexception e) {
throw new runtimeexception("parse event has an error , data:" + entry.tostring(), e);
}
// 打印事务提交信息,事务id
logger.info("----------------\n");
logger.info(" end ----> transaction id: {}", end.gettransactionid());
printxainfo(end.getpropslist());
logger.info(transaction_format,
new object[]{entry.getheader().getlogfilename(),
string.valueof(entry.getheader().getlogfileoffset()),
string.valueof(entry.getheader().getexecutetime()), simpledateformat.format(date),
entry.getheader().getgtid(), string.valueof(delaytime)});
}
continue;
}
// 当前entry(binary log event)的条目类型属于原始数据
if (entry.getentrytype() == entrytype.rowdata) {
rowchange rowchage = null;
try {
// 获取储存的内容
rowchage = rowchange.parsefrom(entry.getstorevalue());
} catch (exception e) {
throw new runtimeexception("parse event has an error , data:" + entry.tostring(), e);
}
// 获取当前内容的事件类型
eventtype eventtype = rowchage.geteventtype();
logger.info(row_format,
new object[]{entry.getheader().getlogfilename(),
string.valueof(entry.getheader().getlogfileoffset()), entry.getheader().getschemaname(),
entry.getheader().gettablename(), eventtype,
string.valueof(entry.getheader().getexecutetime()), simpledateformat.format(date),
entry.getheader().getgtid(), string.valueof(delaytime)});
// 事件类型是query或数据定义语言ddl直接打印sql语句,跳出继续下一次循环
if (eventtype == eventtype.query || rowchage.getisddl()) {
logger.info(" sql ----> " + rowchage.getsql() + sep);
continue;
}
printxainfo(rowchage.getpropslist());
// 循环当前内容条目的具体数据
for (rowdata rowdata : rowchage.getrowdataslist()) {
list<canalentry.column> columns;
// 事件类型是delete返回删除前的列内容,否则返回改变后列的内容
if (eventtype == canalentry.eventtype.delete) {
columns = rowdata.getbeforecolumnslist();
} else {
columns = rowdata.getaftercolumnslist();
}
hashmap<string, object> map = new hashmap<>(16);
// 循环把列的name与value放入map中
for (column column: columns){
map.put(column.getname(), column.getvalue());
}
rows.add(new twotuple<>(eventtype, map));
}
}
}
return rows;
}package com.example.canal.study.common;
import com.alibaba.fastjson.json;
import com.example.canal.study.pojo.student;
import lombok.extern.slf4j.slf4j;
import org.elasticsearch.client.resthighlevelclient;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.stereotype.component;
import org.elasticsearch.action.docwriterequest;
import org.elasticsearch.action.delete.deleterequest;
import org.elasticsearch.action.delete.deleteresponse;
import org.elasticsearch.action.get.getrequest;
import org.elasticsearch.action.get.getresponse;
import org.elasticsearch.action.index.indexrequest;
import org.elasticsearch.action.index.indexresponse;
import org.elasticsearch.action.update.updaterequest;
import org.elasticsearch.action.update.updateresponse;
import org.elasticsearch.client.requestoptions;
import org.elasticsearch.common.xcontent.xcontenttype;
import java.io.ioexception;
import java.util.map;
/**
* @author haha
*/
@slf4j
@component
public class elasticutils {
@autowired
private resthighlevelclient resthighlevelclient;
/**
* 新增
* @param student
* @param index 索引
*/
public void savees(student student, string index) {
indexrequest indexrequest = new indexrequest(index)
.id(student.getid())
.source(json.tojsonstring(student), xcontenttype.json)
.optype(docwriterequest.optype.create);
try {
indexresponse response = resthighlevelclient.index(indexrequest, requestoptions.default);
log.info("保存数据至elasticsearch成功:{}", response.getid());
} catch (ioexception e) {
log.error("保存数据至elasticsearch失败: {}", e);
}
}
/**
* 查看
* @param index 索引
* @param id _id
* @throws ioexception
*/
public void getes(string index, string id) throws ioexception {
getrequest getrequest = new getrequest(index, id);
getresponse response = resthighlevelclient.get(getrequest, requestoptions.default);
map<string, object> fields = response.getsource();
for (map.entry<string, object> entry : fields.entryset()) {
system.out.println(entry.getkey() + ":" + entry.getvalue());
}
}
/**
* 更新
* @param student
* @param index 索引
* @throws ioexception
*/
public void updatees(student student, string index) throws ioexception {
updaterequest updaterequest = new updaterequest(index, student.getid());
updaterequest.upsert(json.tojsonstring(student), xcontenttype.json);
updateresponse response = resthighlevelclient.update(updaterequest, requestoptions.default);
log.info("更新数据至elasticsearch成功:{}", response.getid());
}
/**
* 根据id删除数据
* @param index 索引
* @param id _id
* @throws ioexception
*/
public void deletees(string index, string id) throws ioexception {
deleterequest deleterequest = new deleterequest(index, id);
deleteresponse response = resthighlevelclient.delete(deleterequest, requestoptions.default);
log.info("删除数据至elasticsearch成功:{}", response.getid());
}
}package com.example.canal.study.action;
import com.alibaba.otter.canal.client.canalconnector;
import com.alibaba.otter.canal.protocol.canalentry;
import com.alibaba.otter.canal.protocol.message;
import com.example.canal.study.common.canaldataparser;
import com.example.canal.study.common.elasticutils;
import com.example.canal.study.pojo.student;
import lombok.extern.slf4j.slf4j;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.beans.factory.annotation.qualifier;
import org.springframework.stereotype.component;
import java.io.ioexception;
import java.util.list;
import java.util.map;
/**
* @author haha
*/
@slf4j
@component
public class binlogelasticsearch {
@autowired
private canalconnector canalsimpleconnector;
@autowired
private elasticutils elasticutils;
//@qualifier("canalhaconnector")使用名为canalhaconnector的bean
@autowired
@qualifier("canalhaconnector")
private canalconnector canalhaconnector;
public void binlogtoelasticsearch() throws ioexception {
opencanalconnector(canalhaconnector);
// 轮询拉取数据
integer batchsize = 5 * 1024;
while (true) {
message message = canalhaconnector.getwithoutack(batchsize);
// message message = canalsimpleconnector.getwithoutack(batchsize);
long id = message.getid();
int size = message.getentries().size();
log.info("当前监控到binlog消息数量{}", size);
if (id == -1 || size == 0) {
try {
// 等待2秒
thread.sleep(2000);
} catch (interruptedexception e) {
e.printstacktrace();
}
} else {
//1. 解析message对象
list<canalentry.entry> entries = message.getentries();
list<canaldataparser.twotuple<canalentry.eventtype, map>> rows = canaldataparser.printentry(entries);
for (canaldataparser.twotuple<canalentry.eventtype, map> tuple : rows) {
if(tuple.eventtype == canalentry.eventtype.insert) {
student student = createstudent(tuple);
// 2。将解析出的对象同步到elasticsearch中
elasticutils.savees(student, "student_index");
// 3.消息确认已处理
// canalsimpleconnector.ack(id);
canalhaconnector.ack(id);
}
if(tuple.eventtype == canalentry.eventtype.update){
student student = createstudent(tuple);
elasticutils.updatees(student, "student_index");
// 3.消息确认已处理
// canalsimpleconnector.ack(id);
canalhaconnector.ack(id);
}
if(tuple.eventtype == canalentry.eventtype.delete){
elasticutils.deletees("student_index", tuple.columnmap.get("id").tostring());
canalhaconnector.ack(id);
}
}
}
}
}
/**
* 封装数据至student
* @param tuple
* @return
*/
private student createstudent(canaldataparser.twotuple<canalentry.eventtype, map> tuple){
student student = new student();
student.setid(tuple.columnmap.get("id").tostring());
student.setage(integer.parseint(tuple.columnmap.get("age").tostring()));
student.setname(tuple.columnmap.get("name").tostring());
student.setsex(tuple.columnmap.get("sex").tostring());
student.setcity(tuple.columnmap.get("city").tostring());
return student;
}
/**
* 打开canal连接
*
* @param canalconnector
*/
private void opencanalconnector(canalconnector canalconnector) {
//连接canalserver
canalconnector.connect();
// 订阅destination
canalconnector.subscribe();
}
/**
* 关闭canal连接
*
* @param canalconnector
*/
private void closecanalconnector(canalconnector canalconnector) {
//关闭连接canalserver
canalconnector.disconnect();
// 注销订阅destination
canalconnector.unsubscribe();
}
}package com.example.canal.study;
import com.example.canal.study.action.binlogelasticsearch;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.boot.applicationarguments;
import org.springframework.boot.applicationrunner;
import org.springframework.boot.springapplication;
import org.springframework.boot.autoconfigure.springbootapplication;
/**
* @author haha
*/
@springbootapplication
public class canaldemoapplication implements applicationrunner {
@autowired
private binlogelasticsearch binlogelasticsearch;
public static void main(string[] args) {
springapplication.run(canaldemoapplication.class, args);
}
// 程序启动则执行run方法
@override
public void run(applicationarguments args) throws exception {
binlogelasticsearch.binlogtoelasticsearch();
}
}server.port=8081 spring.application.name = canal-demo canal.server.ip = 192.168.124.5 canal.server.port = 11111 canal.destination = example zookeeper.server.ip = 192.168.124.5:2181 zookeeper.sasl.client = false elasticsearch.server.ip = 192.168.124.5 elasticsearch.server.port = 9200
docker pull zookeeper docker run -d --name zookeeper --net mynetwork --ip 172.18.0.3 -p 2181:2181 zookeeper docker run -d --name canal-server2 --net mynetwork --ip 172.18.0.8 -p 11113:11113 canal/canal-server
package com.example.canal.study.action;
import com.alibaba.otter.canal.client.canalconnector;
import com.alibaba.otter.canal.protocol.canalentry;
import com.alibaba.otter.canal.protocol.message;
import com.example.canal.study.common.canaldataparser;
import com.example.canal.study.common.elasticutils;
import com.example.canal.study.pojo.student;
import lombok.extern.slf4j.slf4j;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.beans.factory.annotation.qualifier;
import org.springframework.stereotype.component;
import java.io.ioexception;
import java.util.list;
import java.util.map;
/**
* @author haha
*/
@slf4j
@component
public class binlogelasticsearch {
@autowired
private canalconnector canalsimpleconnector;
@autowired
private elasticutils elasticutils;
//@qualifier("canalhaconnector")使用名为canalhaconnector的bean
@autowired
@qualifier("canalhaconnector")
private canalconnector canalhaconnector;
public void binlogtoelasticsearch() throws ioexception {
opencanalconnector(canalhaconnector);
// 轮询拉取数据
integer batchsize = 5 * 1024;
while (true) {
message message = canalhaconnector.getwithoutack(batchsize);
// message message = canalsimpleconnector.getwithoutack(batchsize);
long id = message.getid();
int size = message.getentries().size();
log.info("当前监控到binlog消息数量{}", size);
if (id == -1 || size == 0) {
try {
// 等待2秒
thread.sleep(2000);
} catch (interruptedexception e) {
e.printstacktrace();
}
} else {
//1. 解析message对象
list<canalentry.entry> entries = message.getentries();
list<canaldataparser.twotuple<canalentry.eventtype, map>> rows = canaldataparser.printentry(entries);
for (canaldataparser.twotuple<canalentry.eventtype, map> tuple : rows) {
if(tuple.eventtype == canalentry.eventtype.insert) {
student student = createstudent(tuple);
// 2。将解析出的对象同步到elasticsearch中
elasticutils.savees(student, "student_index");
// 3.消息确认已处理
// canalsimpleconnector.ack(id);
canalhaconnector.ack(id);
}
if(tuple.eventtype == canalentry.eventtype.update){
student student = createstudent(tuple);
elasticutils.updatees(student, "student_index");
// 3.消息确认已处理
// canalsimpleconnector.ack(id);
canalhaconnector.ack(id);
}
if(tuple.eventtype == canalentry.eventtype.delete){
elasticutils.deletees("student_index", tuple.columnmap.get("id").tostring());
canalhaconnector.ack(id);
}
}
}
}
}
/**
* 封装数据至student
* @param tuple
* @return
*/
private student createstudent(canaldataparser.twotuple<canalentry.eventtype, map> tuple){
student student = new student();
student.setid(tuple.columnmap.get("id").tostring());
student.setage(integer.parseint(tuple.columnmap.get("age").tostring()));
student.setname(tuple.columnmap.get("name").tostring());
student.setsex(tuple.columnmap.get("sex").tostring());
student.setcity(tuple.columnmap.get("city").tostring());
return student;
}
/**
* 打开canal连接
*
* @param canalconnector
*/
private void opencanalconnector(canalconnector canalconnector) {
//连接canalserver
canalconnector.connect();
// 订阅destination
canalconnector.subscribe();
}
/**
* 关闭canal连接
*
* @param canalconnector
*/
private void closecanalconnector(canalconnector canalconnector) {
//关闭连接canalserver
canalconnector.disconnect();
// 注销订阅destination
canalconnector.unsubscribe();
}
}canaldemoapplication.java(spring boot启动类)
package com.example.canal.study;
import com.example.canal.study.action.binlogelasticsearch;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.boot.applicationarguments;
import org.springframework.boot.applicationrunner;
import org.springframework.boot.springapplication;
import org.springframework.boot.autoconfigure.springbootapplication;
/**
* @author haha
*/
@springbootapplication
public class canaldemoapplication implements applicationrunner {
@autowired
private binlogelasticsearch binlogelasticsearch;
public static void main(string[] args) {
springapplication.run(canaldemoapplication.class, args);
}
// 程序启动则执行run方法
@override
public void run(applicationarguments args) throws exception {
binlogelasticsearch.binlogtoelasticsearch();
}
}application.properties
server.port=8081 spring.application.name = canal-demo canal.server.ip = 192.168.124.5 canal.server.port = 11111 canal.destination = example zookeeper.server.ip = 192.168.124.5:2181 zookeeper.sasl.client = false elasticsearch.server.ip = 192.168.124.5 elasticsearch.server.port = 9200
canal集群高可用的搭建
通过上面的学习,我们知道了单机直连方式的canala应用。在当今互联网时代,单实例模式逐渐被集群高可用模式取代,那么canala的多实例集群方式如何搭建呢!
基于zookeeper获取canal实例
准备zookeeper的docker镜像与容器:
docker pull zookeeper docker run -d --name zookeeper --net mynetwork --ip 172.18.0.3 -p 2181:2181 zookeeper docker run -d --name canal-server2 --net mynetwork --ip 172.18.0.8 -p 11113:11113 canal/canal-server
1、机器准备:
运行canal的容器ip: 172.18.0.4 , 172.18.0.8
zookeeper容器ip:172.18.0.3:2181
mysql容器ip:172.18.0.6:3306
2、按照部署和配置,在单台机器上各自完成配置,演示时instance name为example。
3、修改canal.properties,加上zookeeper配置并修改canal端口:
canal.port=11113 canal.zkservers=172.18.0.3:2181 canal.instance.global.spring.xml = classpath:spring/default-instance.xml
4、创建example目录,并修改instance.properties:
canal.instance.mysql.slaveid = 1235 #之前的canal slaveid是1234,保证slaveid不重复即可 canal.instance.master.address = 172.18.0.6:3306
注意: 两台机器上的instance目录的名字需要保证完全一致,ha模式是依赖于instance name进行管理,同时必须都选择default-instance.xml配置。
启动两个不同容器的canal,启动后,可以通过tail -100f logs/example/example.log查看启动日志,只会看到一台机器上出现了启动成功的日志。
比如我这里启动成功的是 172.18.0.4:
查看一下zookeeper中的节点信息,也可以知道当前工作的节点为172.18.0.4:11111:
[zk: localhost:2181(connected) 15] get /otter/canal/destinations/example/running
{"active":true,"address":"172.18.0.4:11111","cid":1}客户端链接, 消费数据
可以通过指定zookeeper地址和canal的instance name,canal client会自动从zookeeper中的running节点获取当前服务的工作节点,然后与其建立链接:
[zk: localhost:2181(connected) 0] get /otter/canal/destinations/example/running
{"active":true,"address":"172.18.0.4:11111","cid":1}对应的客户端编码可以使用如下形式,上文中的canalconfig.java中的canalhaconnector就是一个ha连接:
canalconnector connector = canalconnectors.newclusterconnector("172.18.0.3:2181", "example", "", "");链接成功后,canal server会记录当前正在工作的canal client信息,比如客户端ip,链接的端口信息等(聪明的你,应该也可以发现,canal client也可以支持ha功能):
[zk: localhost:2181(connected) 4] get /otter/canal/destinations/example/1001/running
{"active":true,"address":"192.168.124.5:59887","clientid":1001}数据消费成功后,canal server会在zookeeper中记录下当前最后一次消费成功的binlog位点(下次你重启client时,会从这最后一个位点继续进行消费):
[zk: localhost:2181(connected) 5] get /otter/canal/destinations/example/1001/cursor
{"@type":"com.alibaba.otter.canal.protocol.position.logposition","identity":{"slaveid":-1,"sourceaddress":{"address":"mysql.mynetwork","port":3306}},"postion":{"included":false,"journalname":"binlog.000004","position":2169,"timestamp":1562672817000}}停止正在工作的172.18.0.4的canal server:
docker exec -it canal-server bash cd canal-server/bin sh stop.sh
这时172.18.0.8会立马启动example instance,提供新的数据服务:
[zk: localhost:2181(connected) 19] get /otter/canal/destinations/example/running
{"active":true,"address":"172.18.0.8:11111","cid":1}与此同时,客户端也会随着canal server的切换,通过获取zookeeper中的最新地址,与新的canal server建立链接,继续消费数据,整个过程自动完成。
异常与总结
elasticsearch-head无法访问elasticsearch
es与es-head是两个独立的进程,当es-head访问es服务时,会存在一个跨域问题。所以我们需要修改es的配置文件,增加一些配置项来解决这个问题,如下:
[root@localhost /usr/local/elasticsearch-head-master]# cd ../elasticsearch-5.5.2/config/ [root@localhost /usr/local/elasticsearch-5.5.2/config]# vim elasticsearch.yml # 文件末尾加上如下配置 http.cors.enabled: true http.cors.allow-origin: "*"
修改完配置文件后需重启es服务。
elasticsearch-head查询报406 not acceptable
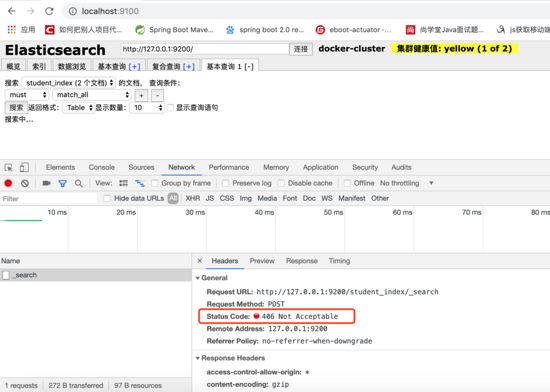
解决方法:
1、进入head安装目录;
2、cd _site/
3、编辑vendor.js 共有两处
#6886行 contenttype: "application/x-www-form-urlencoded 改成 contenttype: "application/json;charset=utf-8" #7574行 var inspectdata = s.contenttype === "application/x-www-form-urlencoded" && 改成 var inspectdata = s.contenttype === "application/json;charset=utf-8" &&
使用elasticsearch-rest-high-level-client报org.elasticsearch.action.index.indexrequest.ifseqno
#pom中除了加入依赖 <dependency> <groupid>org.elasticsearch.client</groupid> <artifactid>elasticsearch-rest-high-level-client</artifactid> <version>7.1.1</version> </dependency> #还需加入 <dependency> <groupid>org.elasticsearch</groupid> <artifactid>elasticsearch</artifactid> <version>7.1.1</version> </dependency>
相关参考: 。
为什么elasticsearch要在7.x版本不能使用type?
参考: 为什么elasticsearch要在7.x版本去掉type?
使用spring-data-elasticsearch.jar报org.elasticsearch.client.transport.nonodeavailableexception
由于本文使用的是elasticsearch7.x以上的版本,目前spring-data-elasticsearch底层采用es官方transportclient,而es官方计划放弃transportclient,工具以es官方推荐的resthighlevelclient进行调用请求。 可参考 resthighlevelclient api 。
设置docker容器开启启动
如果创建时未指定 --restart=always ,可通过update 命令 docker update --restart=always [containerid]
docker for mac network host模式不生效
host模式是为了性能,但是这却对docker的隔离性造成了破坏,导致安全性降低。 在性能场景下,可以用--netwokr host开启host模式,但需要注意的是,如果你用windows或mac本地启动容器的话,会遇到host模式失效的问题。原因是host模式只支持linux宿主机。
参见官方文档: 。
客户端连接zookeeper报authenticate using sasl(unknow error)

zookeeper.jar은 dokcer의 사육사 버전과 일치하지 않습니다
zookeeper.jar은 3.4.6
이 오류는 사육사가 시스템에서 리소스를 다음과 같이 신청해야 함을 의미합니다. 외부 애플리케이션의 경우 리소스 신청 시 인증을 통과해야 하며, sasl은 sasl 인증을 우회하는 방법을 찾고자 합니다. 기다리지 않고 효율성을 높이세요.
프로젝트 코드에 system.setproperty("zookeeper.sasl.client", "false")를 추가합니다. 스프링 부트 프로젝트인 경우 application.properties에 있을 수 있습니다. zookeeper.sasl.client=false를 추가하세요. system.setproperty("zookeeper.sasl.client", "false");,如果是spring boot项目可以在application.properties中加入zookeeper.sasl.client=false。
参考: increased cpu usage by unnecessary sasl checks 。
如果更换canal.client.jar中依赖的zookeeper.jar的版本
把canal的官方源码下载到本机git clone ,然后修改client模块下pom.xml文件中关于zookeeper的内容,然后重新mvn install:
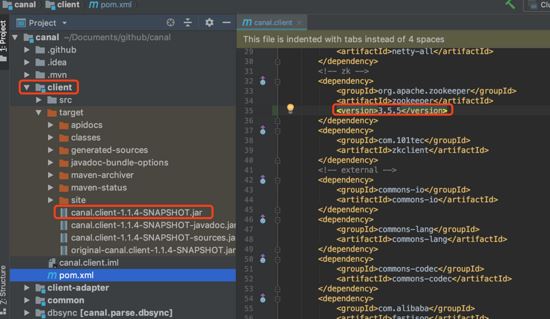
把自己项目依赖的包替换为刚刚mvn install
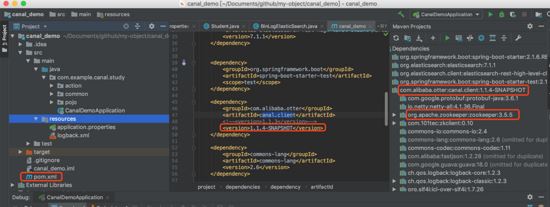 canal.client.jar이 의존하는 Zookeeper.jar의 버전을 변경하는 경우
canal.client.jar이 의존하는 Zookeeper.jar의 버전을 변경하는 경우
🎜🎜프로젝트가 의존하는 패키지를 mvn install에서 방금 생성한 패키지로 교체: 🎜🎜🎜🎜위 내용은 Docker와 Canal을 기반으로 MySQL 실시간 증분 데이터 전송 기능을 구현하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7442
7442
 15
1371
52
76
11
36
19
9
6
15
1371
52
76
11
36
19
9
6

 MySQL에 루트로 로그인 할 수 없습니다
Apr 08, 2025 pm 04:54 PM
MySQL에 루트로 로그인 할 수 없습니다
Apr 08, 2025 pm 04:54 PM
Root로 MySQL에 로그인 할 수없는 주된 이유는 권한 문제, 구성 파일 오류, 암호 일관성이 없음, 소켓 파일 문제 또는 방화벽 차단입니다. 솔루션에는 다음이 포함됩니다. 구성 파일의 BAND-ADDRESS 매개 변수가 올바르게 구성되어 있는지 확인하십시오. 루트 사용자 권한이 수정 또는 삭제되어 재설정되었는지 확인하십시오. 케이스 및 특수 문자를 포함하여 비밀번호가 정확한지 확인하십시오. 소켓 파일 권한 설정 및 경로를 확인하십시오. 방화벽이 MySQL 서버에 연결되는지 확인하십시오.
 MySQL 사용자와 데이터베이스의 관계
Apr 08, 2025 pm 07:15 PM
MySQL 사용자와 데이터베이스의 관계
Apr 08, 2025 pm 07:15 PM
MySQL 데이터베이스에서 사용자와 데이터베이스 간의 관계는 권한과 테이블로 정의됩니다. 사용자는 데이터베이스에 액세스 할 수있는 사용자 이름과 비밀번호가 있습니다. 권한은 보조금 명령을 통해 부여되며 테이블은 Create Table 명령에 의해 생성됩니다. 사용자와 데이터베이스 간의 관계를 설정하려면 데이터베이스를 작성하고 사용자를 생성 한 다음 권한을 부여해야합니다.
 Redshift Zero ETL과의 RDS MySQL 통합
Apr 08, 2025 pm 07:06 PM
Redshift Zero ETL과의 RDS MySQL 통합
Apr 08, 2025 pm 07:06 PM
데이터 통합 단순화 : AmazonRdsMysQL 및 Redshift의 Zero ETL 통합 효율적인 데이터 통합은 데이터 중심 구성의 핵심입니다. 전통적인 ETL (추출, 변환,로드) 프로세스는 특히 데이터베이스 (예 : AmazonRDSMySQL)를 데이터웨어 하우스 (예 : Redshift)와 통합 할 때 복잡하고 시간이 많이 걸립니다. 그러나 AWS는 이러한 상황을 완전히 변경 한 Zero ETL 통합 솔루션을 제공하여 RDSMYSQL에서 Redshift로 데이터 마이그레이션을위한 단순화 된 거의 실시간 솔루션을 제공합니다. 이 기사는 RDSMYSQL ZERL ETL 통합으로 Redshift와 함께 작동하여 데이터 엔지니어 및 개발자에게 제공하는 장점과 장점을 설명합니다.
 MySQL의 쿼리 최적화는 데이터베이스 성능을 향상시키는 데 필수적입니다. 특히 대규모 데이터 세트를 처리 할 때
Apr 08, 2025 pm 07:12 PM
MySQL의 쿼리 최적화는 데이터베이스 성능을 향상시키는 데 필수적입니다. 특히 대규모 데이터 세트를 처리 할 때
Apr 08, 2025 pm 07:12 PM
1. 올바른 색인을 사용하여 스캔 한 데이터의 양을 줄임으로써 데이터 검색 속도를 높이십시오. 테이블 열을 여러 번 찾으면 해당 열에 대한 인덱스를 만듭니다. 귀하 또는 귀하의 앱이 기준에 따라 여러 열에서 데이터가 필요한 경우 복합 인덱스 2를 만듭니다. 2. 선택을 피하십시오 * 필요한 열만 선택하면 모든 원치 않는 열을 선택하면 더 많은 서버 메모리를 선택하면 서버가 높은 부하 또는 주파수 시간으로 서버가 속도가 느려지며, 예를 들어 Creation_at 및 Updated_at 및 Timestamps와 같은 열이 포함되어 있지 않기 때문에 쿼리가 필요하지 않기 때문에 테이블은 선택을 피할 수 없습니다.
 MySQL 테이블 잠금 테이블 변경 여부
Apr 08, 2025 pm 05:06 PM
MySQL 테이블 잠금 테이블 변경 여부
Apr 08, 2025 pm 05:06 PM
MySQL이 테이블 구조를 수정하면 메타 데이터 잠금 장치가 일반적으로 사용되므로 테이블을 잠글 수 있습니다. 자물쇠의 영향을 줄이려면 다음과 같은 조치를 취할 수 있습니다. 1. 온라인 DDL과 함께 테이블을 사용할 수 있습니다. 2. 배치에서 복잡한 수정을 수행합니다. 3. 소형 또는 피크 기간 동안 운영됩니다. 4. PT-OSC 도구를 사용하여 더 미세한 제어를 달성하십시오.
 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 MySQL은 Android에서 실행할 수 있습니다
Apr 08, 2025 pm 05:03 PM
MySQL은 Android에서 실행할 수 있습니다
Apr 08, 2025 pm 05:03 PM
MySQL은 Android에서 직접 실행할 수는 없지만 다음 방법을 사용하여 간접적으로 구현할 수 있습니다. Android 시스템에 구축 된 Lightweight Database SQLite를 사용하여 별도의 서버가 필요하지 않으며 모바일 장치 애플리케이션에 매우 적합한 작은 리소스 사용량이 있습니다. MySQL 서버에 원격으로 연결하고 데이터 읽기 및 쓰기를 위해 네트워크를 통해 원격 서버의 MySQL 데이터베이스에 연결하지만 강력한 네트워크 종속성, 보안 문제 및 서버 비용과 같은 단점이 있습니다.
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
