

Redis의 기본 원리는 무엇입니까

Redis 핵심 개체
Redis에는 모든 키와 값을 나타내는 데 사용되는 redisObject라는 "핵심 개체"가 있습니다. redisObject 구조는 문자열, 해시, 목록, 집합, 등 다섯 가지 유형의 데이터를 나타내는 데 사용됩니다. 그리고 ZSet 유형.
redisObject의 소스 코드는 C 언어로 작성된 redis.h에 있습니다. 관심이 있으시면 직접 확인해 보시기 바랍니다. redisObject에 대해서는 여기에 그림을 그려 넣었는데, redisObject의 구조는 다음과 같습니다. 다음과 같습니다:
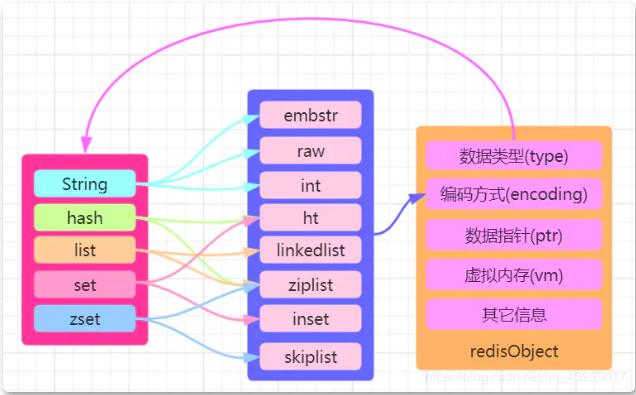
In redisObject In "유형은 그것이 속한 데이터 유형을 나타내고 인코딩은 데이터가 저장되는 방법을 나타냅니다." , 이는 구현된 데이터 유형의 기본 데이터 구조입니다. 따라서 이 글에서는 인코딩의 해당 부분을 구체적으로 소개합니다.
그럼 인코딩에서 저장 유형은 무엇을 의미하나요? 특정 데이터 유형의 의미는 아래 그림과 같습니다.
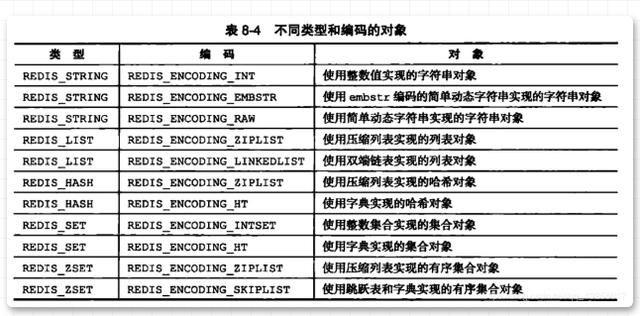
이 그림을 읽은 후에도 여전히 혼란스러울 수 있습니다. 당황하지 마십시오. 5가지 데이터 구조에 대해 자세히 소개하겠습니다. 이 그림을 통해 각 데이터 구조에 해당하는 스토리지 유형을 찾을 수 있을 뿐이며 아마도 여러분의 마음 속에 있을 것입니다.
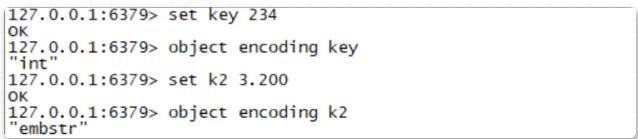
간단한 예를 들자면 Redis에서 문자열 키 234를 설정한 다음 이 문자열의 저장 유형을 확인하면 정수가 아닌 유형이 embstr 저장 유형을 사용하는 것을 볼 수 있습니다.
String type
String은 Redis의 가장 기본적인 데이터 유형입니다. 위의 소개에서도 Redis가 C 언어로 개발되었다고 언급했습니다. 그러나 Redis의 문자열 유형과 C 언어의 문자열 유형 간에는 명백한 차이가 있습니다.
문자열 유형의 데이터 구조를 저장하는 방법에는 int, raw 및 embstr의 세 가지 방법이 있습니다. 그렇다면 이 세 가지 저장 방법의 차이점은 무엇입니까?
int
Redis는 set num 123과 같이 저장된 "정수 값"이 int 저장 방법을 사용하여 저장될 경우 redisObject의 "ptr 속성"에 저장되도록 규정합니다. 이 값을 저장하세요. .
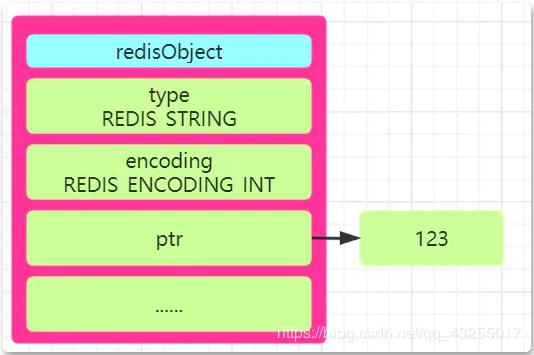
SDS
저장된 "문자열이 문자열 값이고 길이가 32바이트보다 크다"면 SDS(단순 동적 문자열)를 사용하여 저장되며 다음과 같은 경우 인코딩이 원시로 설정됩니다. "문자열 길이가 32바이트보다 작거나 같습니다." 문자열을 저장하기 위해 인코딩을 embstr로 변경합니다.
SDS는 "단순 동적 문자열"이라고 합니다. Redis 소스 코드의 SDS에는 int len, int free 및 char buf[]라는 세 가지 속성이 정의되어 있습니다.
len은 문자열의 길이를 저장하고, free는 buf 배열에서 사용되지 않은 바이트 수를 나타내며, buf 배열은 문자열의 각 문자 요소를 저장합니다.
그래서 Redsi에 Hello 문자열을 저장하면 Redis 소스코드의 설명에 따라 아래와 같이 redisObject 구조 다이어그램을 SDS 형식으로 그릴 수 있습니다.
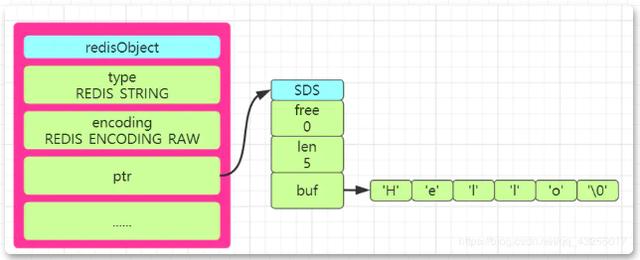
SDS와 C 언어 문자열 비교
Redis는 SDS를 문자열 저장소 유형으로 사용하는 데 확실히 고유한 장점이 있습니다. C 언어의 문자열과 비교할 때 SDS는 C 언어의 문자열에 대한 자체 설계 및 최적화 기능을 갖추고 있습니다.
(1) C 언어의 문자열은 자신의 길이를 기록하지 않으므로 "문자열의 길이를 얻을 때마다 순회하게 되며 시간 복잡도는 O(n)입니다.", Redis에서는 문자열을 얻는 동안 그냥 읽으세요 len의 값은 시간 복잡도가 O(1)이 됩니다.
(2) "c 언어"에서 두 문자열을 연결할 때 충분한 길이의 메모리 공간이 할당되지 않으면 "버퍼 오버플로가 발생합니다" 및 "SDS"는 먼저 len 속성을 사용하는지 여부를 결정합니다. 공간이 요구 사항을 충족합니다. 공간이 충분하지 않으면 해당 공간이 확장되므로 "버퍼 오버플로가 발생하지 않습니다".
(3) SDS는 "공간 사전 할당" 및 "Lazy Space Release"의 두 가지 전략도 제공합니다. 문자열에 공간을 할당할 때 실제 공간보다 더 많은 공간을 할당하면 "문자열 증가의 지속적인 실행으로 인한 메모리 재할당 횟수를 줄일 수 있습니다" .
문자열이 단축되면 SDS는 사용되지 않은 공간을 즉시 회수하지 않고 free 속성을 통해 사용되지 않은 공간을 기록하고 나중에 사용할 때 해제합니다.
특정 공간 사전 할당 원칙은 다음과 같습니다. "수정된 문자열의 길이 len이 1MB 미만인 경우 len과 동일한 길이의 공간이 사전 할당됩니다. 즉, len=free입니다. len이 더 크면 1MB보다 무료로 할당된 공간은 1MB입니다.".
(4) SDS는 문자열을 저장하는 것 외에도 바이너리 파일(예: 사진, 오디오, 비디오 등의 바이너리 데이터)을 저장할 수 있지만 C 언어의 문자열은 빈 문자열로 끝납니다. 이미지에는 종결자가 포함되어 있으므로 바이너리 안전이 아닙니다.
이해를 더 쉽게 하기 위해 아래와 같이 C 언어 문자열과 SDS를 비교하는 표를 만들었습니다.
C 언어 문자열 SDS 길이를 구하는 시간 복잡도는 O(n)입니다. length 시간 복잡도는 O(1)입니다. 바이너리 안전이 아니며 문자열만 저장할 수 있으며 문자열을 n배로 늘리면 필연적으로 N배의 메모리 할당이 발생합니다. 문자열의 메모리 할당 수를 늘리십시오.
문자열 유형 응용 프로그램
이렇게 말하면 많은 사람들이 이미 Redis의 문자열 유형에 능숙하다고 말할 수 있다고 생각합니다. 위에서 언급한 것처럼 문자열을 사용하여 이미지를 저장할 수 있습니다. 이제 사례 구현으로 사진 저장을 살펴보겠습니다.
(1) 먼저 업로드된 이미지를 인코딩해야 합니다. 이미지를 Base64 인코딩으로 처리하는 도구 클래스는 다음과 같습니다.
/** * 将图片内容处理成Base64编码格式 * @param file * @return */ public static String encodeImg(MultipartFile file) { byte[] imgBytes = null; try { imgBytes = file.getBytes(); } catch (IOException e) { e.printStackTrace(); } BASE64Encoder encoder = new BASE64Encoder(); return imgBytes==null?null:encoder.encode(imgBytes );코드 복사
(2) 두 번째 단계는 처리된 이미지 문자열 형식을 Redis에 저장하는 것입니다. 구현된 코드는 다음과 같습니다.
/** * Redis存储图片 * @param file * @return */ public void uploadImageServiceImpl(MultipartFile image) { String imgId = UUID.randomUUID().toString(); String imgStr= ImageUtils.encodeImg(image); redisUtils.set(imgId , imgStr); // 后续操作可以把imgId存进数据库对应的字段,如果需要从redis中取出,只要获取到这个字段后从redis中取出即可。 }이는 이미지의 이진 저장을 실현합니다. 물론 문자열 유형 데이터 구조의 적용에는 기존 계산도 포함됩니다. "통계 웨이보 수, 팬 수 통계' 등
Hash 유형
Hash 객체를 구현하는 방법에는 ziplist와 hashtable의 두 가지 방법이 있습니다. Hashtable의 저장 방법은 String 유형이며 값도 키 값 형식으로 저장됩니다.
사전 유형의 하위 계층은 해시테이블로 구현됩니다. 사전의 기본 구현 원리를 이해한다는 것은 해시테이블의 구현 원리를 이해한다는 의미이기도 합니다.
Dictionary
둘 다 추가할 때 키를 통해 배열 첨자를 계산합니다. 차이점은 HashMap에서는 해시 함수를 사용하는 반면, 해시 테이블에서는 해시 값을 계산해야 한다는 것입니다. sizemask를 사용하면 속성과 해시가 다시 배열 첨자를 얻습니다.
해시 테이블의 가장 큰 문제는 해시 충돌이라는 것을 알고 있습니다. 해시 충돌을 해결하기 위해 해시 테이블의 서로 다른 키가 계산을 통해 동일한 인덱스를 얻는 경우 단방향 연결 목록("체인 주소 방법") 아래 그림과 같이 구성됩니다.
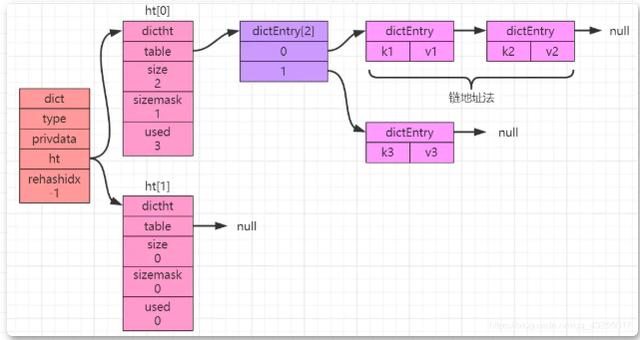
rehash
사전의 기본 구현에서 값 개체는 각 dictEntry의 개체로 저장됩니다. 해시 테이블이 계속 증가하거나 감소하면 해시 테이블을 확장하거나 축소해야 합니다.
HashMap과 마찬가지로 여기서도 rehash 작업, 즉 rehash 배열이 수행됩니다. 위 그림에서 볼 수 있듯이 ht[0]과 ht[1]은 두 개의 객체입니다. 아래에서는 해당 속성의 역할에 중점을 둡니다.
해시 테이블 구조 정의에는 4가지 속성이 있습니다: dictEntry **table, unsigned long size, unsigned long sizemask 및 unsigned long Used. 각각 "해시 테이블 배열, 해시 테이블 크기, 계산에 사용됨을 의미합니다. 인덱스 값 항상 크기-1 및 해시 테이블의 노드 수와 같습니다.".
ht[0]은 처음에 데이터를 저장하는 데 사용됩니다. 확장 또는 축소가 필요한 경우 ht[0]의 크기에 따라 ht[1]의 크기가 결정되며 ht[0]의 모든 키-값 쌍은 다음과 같습니다. ht[1]로 다시 해시되었습니다.
확장 작업: ht[1]의 확장된 크기는 ht[0].used의 현재 값의 두 배인 2의 첫 번째 정수 거듭제곱입니다. 축소 작업: ht[0].used의 첫 번째 정수 거듭제곱이 더 큽니다. 2의 정수 거듭제곱보다 크거나 같습니다.
ht[0]의 모든 키-값 쌍이 ht[1]로 다시 해시되면 모든 배열 첨자 값이 다시 계산됩니다. 데이터 마이그레이션이 완료되면 ht[0]이 해제되고 ht [ 1]을 ht[0]으로 변경하고, 다음 확장 및 축소에 대비하여 ht[1]을 새로 생성합니다.
점진적 재해시
재해시 과정에서 데이터 양이 너무 많으면 Redis는 모든 데이터를 한 번에 성공적으로 재해시하지 못하므로 Redis의 외부 서비스가 중단됩니다. 이 상황을 처리하기 위해 Redis는 내부적으로 를 채택합니다. "점진적인 재해시" ".
Redis는 모든 재해시 작업이 완료될 때까지 모든 재해시 작업을 여러 단계로 나눕니다. 구체적인 구현은 객체의 rehashindex 속성과 관련됩니다. "rehashindex가 -1로 표현되면 재해시 작업이 없음을 의미합니다.".
재해시 작업이 시작되면 값이 0으로 변경됩니다. 점진적인 재해시 과정에서"업데이트, 삭제, 쿼리는 ht[0]과 ht[1] 모두에서 수행됩니다." 예를 들어, 값을 업데이트하려면 먼저 ht[0]을 업데이트한 다음 ht[1]을 업데이트하세요.
새 작업은 ht[1] 테이블에 직접 추가되며 ht[0]은 데이터를 추가하지 않습니다. 이렇게 하면 "ht[0]이 마지막 순간에 변경될 때까지 감소만 하고 증가하지는 않습니다. . 빈 테이블로', 재해시 작업이 완료됩니다.
위는 사전의 기본 해시테이블의 구현 원리입니다. 해시테이블의 구현 원리에 대해 이야기한 후, 해시 데이터 구조의 두 가지 저장 방법인"ziplist(압축 목록)"
을 살펴보겠습니다.ziplist
压缩列表(ziplist)是一组连续内存块组成的顺序的数据结构,压缩列表能够节省空间,压缩列表中使用多个节点来存储数据。
压缩列表是列表键和哈希键底层实现的原理之一,「压缩列表并不是以某种压缩算法进行压缩存储数据,而是它表示一组连续的内存空间的使用,节省空间」,压缩列表的内存结构图如下:

压缩列表中每一个节点表示的含义如下所示:
zlbytes:4个字节的大小,记录压缩列表占用内存的字节数。
zltail:4个字节大小,记录表尾节点距离起始地址的偏移量,用于快速定位到尾节点的地址。
zllen:2个字节的大小,记录压缩列表中的节点数。
entry:表示列表中的每一个节点。
zlend:表示压缩列表的特殊结束符号'0xFF'。
再压缩列表中每一个entry节点又有三部分组成,包括previous_entry_ength、encoding、content。
previous_entry_ength表示前一个节点entry的长度,可用于计算前一个节点的其实地址,因为他们的地址是连续的。
encoding:这里保存的是content的内容类型和长度。
content:content保存的是每一个节点的内容。

说到这里相信大家已经都hash这种数据结构已经非常了解,若是第一次接触Redis五种基本数据结构的底层实现的话,建议多看几遍,下面来说一说hash的应用场景。
应用场景
哈希表相对于String类型存储信息更加直观,擦欧总更加方便,经常会用来做用户数据的管理,存储用户的信息。
hash也可以用作高并发场景下使用Redis生成唯一的id。下面我们就以这两种场景用作案例编码实现。
存储用户数据
第一个场景比如我们要储存用户信息,一般使用用户的ID作为key值,保持唯一性,用户的其他信息(地址、年龄、生日、电话号码等)作为value值存储。
若是传统的实现就是将用户的信息封装成为一个对象,通过序列化存储数据,当需要获取用户信息的时候,就会通过反序列化得到用户信息。
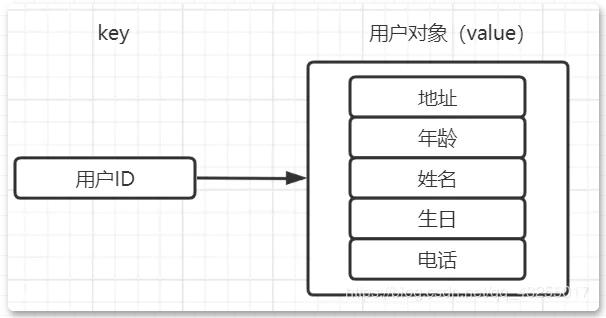
但是这样必然会造成序列化和反序列化的性能的开销,并且若是只修改其中的一个属性值,就需要把整个对象序列化出来,操作的动作太大,造成不必要的性能开销。
若是使用Redis的hash来存储用户数据,就会将原来的value值又看成了一个k v形式的存储容器,这样就不会带来序列化的性能开销的问题。
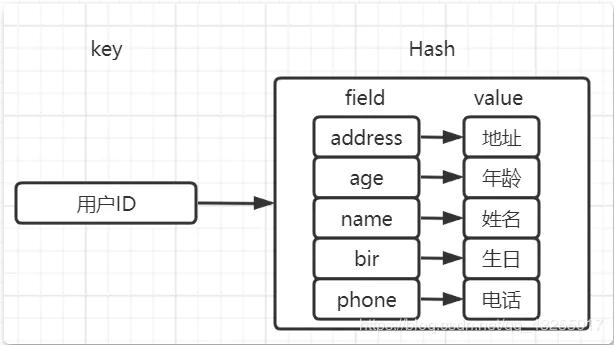
分布式生成唯一ID
第二个场景就是生成分布式的唯一ID,这个场景下就是把redis封装成了一个工具类进行实现,实现的代码如下:
// offset表示的是id的递增梯度值 public Long getId(String key,String hashKey,Long offset) throws BusinessException{ try { if (null == offset) { offset=1L; } // 生成唯一id return redisUtil.increment(key, hashKey, offset); } catch (Exception e) { //若是出现异常就是用uuid来生成唯一的id值 int randNo=UUID.randomUUID().toString().hashCode(); if (randNo <h3 id="List类型">List类型</h3><p>在 Redis 3.2 之前的版本,Redis 的列表是通过结合使用 ziplist 和 linkedlist 实现的。在3.2之后的版本就是引入了quicklist。</p><p>ziplist压缩列表上面已经讲过了,我们来看看linkedlist和quicklist的结构是怎么样的。</p><p>Linkedlist有双向链接,和普通的链表一样,都由指向前后节点的指针构成。时间复杂度为O(1)的操作包括插入、修改和更新,而时间复杂度为O(n)的操作是查询。</p><p>linkedlist和quicklist的底层实现是采用链表进行实现,在c语言中并没有内置的链表这种数据结构,Redis实现了自己的链表结构。</p><p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/887/227/168511087742882.jpg" class="lazy" alt="Redis의 기본 원리는 무엇입니까"></p><p>Redis中链表的特性:</p><ol class=" list-paddingleft-2">
<li><p>每一个节点都有指向前一个节点和后一个节点的指针。</p></li>
<li><p>头节点和尾节点的prev和next指针指向为null,所以链表是无环的。</p></li>
<li><p>链表有自己长度的信息,获取长度的时间复杂度为O(1)。</p></li>
</ol><p>Redis中List的实现比较简单,下面我们就来看看它的应用场景。</p><h3 id="应用场景">应用场景</h3><p>Redis中的列表可以实现<strong>「阻塞队列」</strong>,结合lpush和brpop命令就可以实现。生产者使用lupsh从列表的左侧插入元素,消费者使用brpop命令从队列的右侧获取元素进行消费。</p><p>(1)首先配置redis的配置,为了方便我就直接放在application.yml配置文件中,实际中可以把redis的配置文件放在一个redis.properties文件单独放置,具体配置如下:</p><pre class="brush:php;toolbar:false">spring redis: host: 127.0.0.1 port: 6379 password: user timeout: 0 database: 2 pool: max-active: 100 max-idle: 10 min-idle: 0 max-wait: 100000(2)第二步创建redis的配置类,叫做RedisConfig,并标注上@Configuration注解,表明他是一个配置类。
@Configuration public class RedisConfiguration { @Value("{spring.redis.port}") private int port; @Value("{spring.redis.pool.max-active}") private int maxActive; @Value("{spring.redis.pool.min-idle}") private int minIdle; @Value("{spring.redis.database}") private int database; @Value("${spring.redis.timeout}") private int timeout; @Bean public JedisPoolConfig getRedisConfiguration(){ JedisPoolConfig jedisPoolConfig= new JedisPoolConfig(); jedisPoolConfig.setMaxTotal(maxActive); jedisPoolConfig.setMaxIdle(maxIdle); jedisPoolConfig.setMinIdle(minIdle); jedisPoolConfig.setMaxWaitMillis(maxWait); return jedisPoolConfig; } @Bean public JedisConnectionFactory getConnectionFactory() { JedisConnectionFactory factory = new JedisConnectionFactory(); factory.setHostName(host); factory.setPort(port); factory.setPassword(password); factory.setDatabase(database); JedisPoolConfig jedisPoolConfig= getRedisConfiguration(); factory.setPoolConfig(jedisPoolConfig); return factory; } @Bean public RedisTemplate, ?> getRedisTemplate() { JedisConnectionFactory factory = getConnectionFactory(); RedisTemplate, ?> redisTemplate = new StringRedisTemplate(factory); return redisTemplate; } }(3)第三步就是创建Redis的工具类RedisUtil,自从学了面向对象后,就喜欢把一些通用的东西拆成工具类,好像一个一个零件,需要的时候,就把它组装起来。
@Component public class RedisUtil { @Autowired private RedisTemplate<string> redisTemplate; /** 存消息到消息队列中 @param key 键 @param value 值 @return */ public boolean lPushMessage(String key, Object value) { try { redisTemplate.opsForList().leftPush(key, value); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** 从消息队列中弹出消息 - <rpop> @param key 键 @return */ public Object rPopMessage(String key) { try { return redisTemplate.opsForList().rightPop(key); } catch (Exception e) { e.printStackTrace(); return null; } } /** 查看消息 @param key 键 @param start 开始 @param end 结束 0 到 -1代表所有值 复制代码@return */ public List<object> getMessage(String key, long start, long end) { try { return redisTemplate.opsForList().range(key, start, end); } catch (Exception e) { e.printStackTrace(); return null; } }</object></rpop></string>这样就完成了Redis消息队列工具类的创建,在后面的代码中就可以直接使用。
Set集合
Redis中列表和集合都可以用来存储字符串,但是「Set是不可重复的集合,而List列表可以存储相同的字符串」,Set集合是无序的这个和后面讲的ZSet有序集合相对。
Set的底层实现是「ht和intset」,ht(哈希表)前面已经详细了解过,下面我们来看看inset类型的存储结构。
inset也叫做整数集合,用于保存整数值的数据结构类型,它可以保存int16_t、int32_t 或者int64_t 的整数值。
在整数集合中,有三个属性值encoding、length、contents[],分别表示编码方式、整数集合的长度、以及元素内容,length就是记录contents里面的大小。
在整数集合新增元素的时候,若是超出了原集合的长度大小,就会对集合进行升级,具体的升级过程如下:
首先扩展底层数组的大小,并且数组的类型为新元素的类型。
然后将原来的数组中的元素转为新元素的类型,并放到扩展后数组对应的位置。
整数集合升级后就不会再降级,编码会一直保持升级后的状态。
应用场景
Set集合的应用场景可以用来「去重、抽奖、共同好友、二度好友」等业务类型。接下来模拟一个添加好友的案例实现:
@RequestMapping(value = "/addFriend", method = RequestMethod.POST) public Long addFriend(User user, String friend) { String currentKey = null; // 判断是否是当前用户的好友 if (AppContext.getCurrentUser().getId().equals(user.getId)) { currentKey = user.getId.toString(); } //若是返回0则表示不是该用户好友 return currentKey==null?0l:setOperations.add(currentKey, friend); }
假如两个用户A和B都是用上上面的这个接口添加了很多的自己的好友,那么有一个需求就是要实现获取A和B的共同好友,那么可以进行如下操作:
public Set intersectFriend(User userA, User userB) { return setOperations.intersect(userA.getId.toString(), userB.getId.toString()); }举一反三,还可以实现A用户自己的好友,或者B用户自己的好友等,都可以进行实现。
ZSet集合
ZSet是有序集合,从上面的图中可以看到ZSet的底层实现是ziplist和skiplist实现的,ziplist上面已经详细讲过,这里来讲解skiplist的结构实现。
skiplist也叫做「跳跃表」,跳跃表是一种有序的数据结构,它通过每一个节点维持多个指向其它节点的指针,从而达到快速访问的目的。
skiplist由如下几个特点:
有很多层组成,由上到下节点数逐渐密集,最上层的节点最稀疏,跨度也最大。
每一层都是一个有序链表,只扫包含两个节点,头节点和尾节点。
每一层的每一个每一个节点都含有指向同一层下一个节点和下一层同一个位置节点的指针。
如果一个节点在某一层出现,那么该以下的所有链表同一个位置都会出现该节点。
具体实现的结构图如下所示:
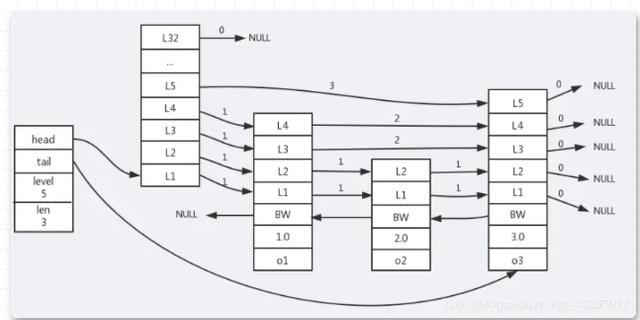
跳跃表的结构中包含指向头节点和尾节点的指针head和tail,能够快速进行定位。当在跳跃表中从尾向前遍历时,层数用 level 表示,跳跃表长度用 len 表示,同时也会使用后退指针 BW。
BW下面还有两个值分别表示分值(score)和成员对象(各个节点保存的成员对象)。
跳跃表的实现中,除了最底层的一层保存的是原始链表的完整数据,上层的节点数会越来越少,并且跨度会越来越大。
跳跃表的上面层就相当于索引层,都是为了找到最后的数据而服务的,数据量越大,条表所体现的查询的效率就越高,和平衡树的查询效率相差无几。
应用场景
因为ZSet是有序的集合,因此ZSet在实现排序类型的业务是比较常见的,比如在首页推荐10个最热门的帖子,也就是阅读量由高到低,排行榜的实现等业务。
下面就选用获取排行榜前前10名的选手作为案例实现,实现的代码如下所示:
@Autowired private RedisTemplate redisTemplate; /** * 获取前10排名 * @return */ public static List<levelvo> getZset(String key, long baseNum, LevelService levelService){ ZSetOperations<serializable> operations = redisTemplate.opsForZSet(); // 根据score分数值获取前10名的数据 Set<zsetoperations.typedtuple>> set = operations.reverseRangeWithScores(key,0,9); List<levelvo> list= new ArrayList<levelvo>(); int i=1; for (ZSetOperations.TypedTuple<object> o:set){ int uid = (int) o.getValue(); LevelCache levelCache = levelService.getLevelCache(uid); LevelVO levelVO = levelCache.getLevelVO(); long score = (o.getScore().longValue() - baseNum + levelVO .getCtime())/CommonUtil.multiplier; levelVO .setScore(score); levelVO .setRank(i); list.add( levelVO ); i++; } return list; }</object></levelvo></levelvo></zsetoperations.typedtuple></serializable></levelvo>以上的代码实现大致逻辑就是根据score分数值获取前10名的数据,然后封装成lawyerVO对象的列表进行返回。
위 내용은 Redis의 기본 원리는 무엇입니까의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7665
7665
 15
1393
52
1205
24
91
11
73
19
15
1393
52
1205
24
91
11
73
19

 Redis 클러스터 모드를 구축하는 방법
Apr 10, 2025 pm 10:15 PM
Redis 클러스터 모드를 구축하는 방법
Apr 10, 2025 pm 10:15 PM
Redis Cluster Mode는 Sharding을 통해 Redis 인스턴스를 여러 서버에 배포하여 확장 성 및 가용성을 향상시킵니다. 시공 단계는 다음과 같습니다. 포트가 다른 홀수 redis 인스턴스를 만듭니다. 3 개의 센티넬 인스턴스를 만들고, Redis 인스턴스 및 장애 조치를 모니터링합니다. Sentinel 구성 파일 구성, Redis 인스턴스 정보 및 장애 조치 설정 모니터링 추가; Redis 인스턴스 구성 파일 구성, 클러스터 모드 활성화 및 클러스터 정보 파일 경로를 지정합니다. 각 redis 인스턴스의 정보를 포함하는 Nodes.conf 파일을 작성합니다. 클러스터를 시작하고 Create 명령을 실행하여 클러스터를 작성하고 복제본 수를 지정하십시오. 클러스터에 로그인하여 클러스터 정보 명령을 실행하여 클러스터 상태를 확인하십시오. 만들다
 Redis 데이터를 지우는 방법
Apr 10, 2025 pm 10:06 PM
Redis 데이터를 지우는 방법
Apr 10, 2025 pm 10:06 PM
Redis 데이터를 지우는 방법 : Flushall 명령을 사용하여 모든 키 값을 지우십시오. FlushDB 명령을 사용하여 현재 선택한 데이터베이스의 키 값을 지우십시오. 선택을 사용하여 데이터베이스를 전환 한 다음 FlushDB를 사용하여 여러 데이터베이스를 지우십시오. del 명령을 사용하여 특정 키를 삭제하십시오. Redis-Cli 도구를 사용하여 데이터를 지우십시오.
 Redis 대기열을 읽는 방법
Apr 10, 2025 pm 10:12 PM
Redis 대기열을 읽는 방법
Apr 10, 2025 pm 10:12 PM
Redis의 대기열을 읽으려면 대기열 이름을 얻고 LPOP 명령을 사용하여 요소를 읽고 빈 큐를 처리해야합니다. 특정 단계는 다음과 같습니다. 대기열 이름 가져 오기 : "큐 :"와 같은 "대기열 : my-queue"의 접두사로 이름을 지정하십시오. LPOP 명령을 사용하십시오. 빈 대기열 처리 : 대기열이 비어 있으면 LPOP이 NIL을 반환하고 요소를 읽기 전에 대기열이 존재하는지 확인할 수 있습니다.
 Redis 명령을 사용하는 방법
Apr 10, 2025 pm 08:45 PM
Redis 명령을 사용하는 방법
Apr 10, 2025 pm 08:45 PM
Redis 지시 사항을 사용하려면 다음 단계가 필요합니다. Redis 클라이언트를 엽니 다. 명령 (동사 키 값)을 입력하십시오. 필요한 매개 변수를 제공합니다 (명령어마다 다름). 명령을 실행하려면 Enter를 누르십시오. Redis는 작업 결과를 나타내는 응답을 반환합니다 (일반적으로 OK 또는 -err).
 Redis Lock을 사용하는 방법
Apr 10, 2025 pm 08:39 PM
Redis Lock을 사용하는 방법
Apr 10, 2025 pm 08:39 PM
Redis를 사용하여 잠금 작업을 사용하려면 SetNX 명령을 통해 잠금을 얻은 다음 만료 명령을 사용하여 만료 시간을 설정해야합니다. 특정 단계는 다음과 같습니다. (1) SETNX 명령을 사용하여 키 값 쌍을 설정하십시오. (2) 만료 명령을 사용하여 잠금의 만료 시간을 설정하십시오. (3) DEL 명령을 사용하여 잠금이 더 이상 필요하지 않은 경우 잠금을 삭제하십시오.
 Redis의 소스 코드를 읽는 방법
Apr 10, 2025 pm 08:27 PM
Redis의 소스 코드를 읽는 방법
Apr 10, 2025 pm 08:27 PM
Redis 소스 코드를 이해하는 가장 좋은 방법은 단계별로 이동하는 것입니다. Redis의 기본 사항에 익숙해집니다. 특정 모듈을 선택하거나 시작점으로 기능합니다. 모듈 또는 함수의 진입 점으로 시작하여 코드를 한 줄씩 봅니다. 함수 호출 체인을 통해 코드를 봅니다. Redis가 사용하는 기본 데이터 구조에 익숙해 지십시오. Redis가 사용하는 알고리즘을 식별하십시오.
 Redis 명령 줄을 사용하는 방법
Apr 10, 2025 pm 10:18 PM
Redis 명령 줄을 사용하는 방법
Apr 10, 2025 pm 10:18 PM
Redis Command Line 도구 (Redis-Cli)를 사용하여 다음 단계를 통해 Redis를 관리하고 작동하십시오. 서버에 연결하고 주소와 포트를 지정하십시오. 명령 이름과 매개 변수를 사용하여 서버에 명령을 보냅니다. 도움말 명령을 사용하여 특정 명령에 대한 도움말 정보를 봅니다. 종금 명령을 사용하여 명령 줄 도구를 종료하십시오.
 Redis로 데이터 손실을 해결하는 방법
Apr 10, 2025 pm 08:24 PM
Redis로 데이터 손실을 해결하는 방법
Apr 10, 2025 pm 08:24 PM
REDIS 데이터 손실 원인에는 메모리 실패, 정전, 인간 오류 및 하드웨어 고장이 포함됩니다. 솔루션은 다음과 같습니다. 1. RDB 또는 AOF 지속성을 사용하여 디스크에 데이터를 저장합니다. 2. 고 가용성을 위해 여러 서버에 복사하십시오. 3. Redis Sentinel 또는 Redis 클러스터를 사용한 Ha; 4. 데이터를 백업 할 스냅 샷을 만듭니다. 5. 지속성, 복제, 스냅 샷, 모니터링 및 보안 조치와 같은 모범 사례를 구현합니다.
