

클러스터형 인덱스는 기본적으로 innodb에서 생성된 기본 키를 기반으로 하는 인덱스 구조이며 테이블의 데이터는 리프 노드의 데이터 페이지로 클러스터형 인덱스에 직접 배치됩니다.
Data 기본 키 기반 검색: 클러스터형 인덱스의 루트 노드에서 이진 검색을 시작하여 해당 데이터 페이지를 끝까지 찾고 페이지 디렉터리를 기반으로 기본 키 대상 데이터를 직접 찾습니다.
다른 필드를 인덱스하고 싶거나 여러 필드를 기반으로 공동 인덱스를 만들고 싶다면 인덱스 구조는 어떻게 되나요?
이름, 나이 등 다른 필드가 색인화되어 있다고 가정하면 동일한 원칙이 적용됩니다. 예를 들어 데이터를 삽입하는 경우:
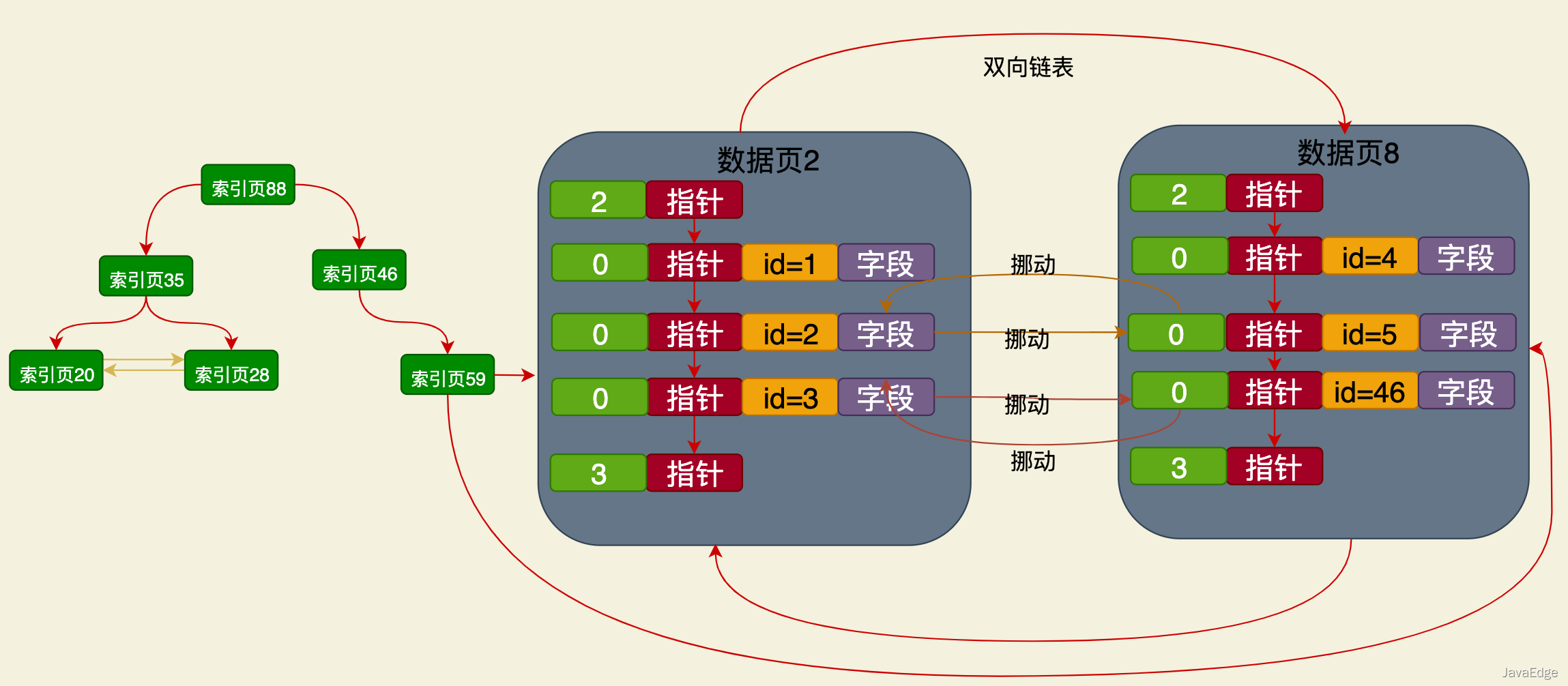
클러스터형 인덱스의 리프 노드에 있는 데이터 페이지에 전체 데이터를 삽입하고 동시에 다른 필드에 대해 설정된 클러스터형 인덱스
인덱스를 유지합니다. re-configure a B+ tree
예를 들어 name 필드를 기반으로 인덱스를 생성하면 데이터가 삽입될 때 새로운 B+ 트리가 생성되지만 B+ 트리의 리프 노드도 데이터 페이지입니다. 기본 키 필드와 이름 필드만 데이터 페이지에 배치됩니다.
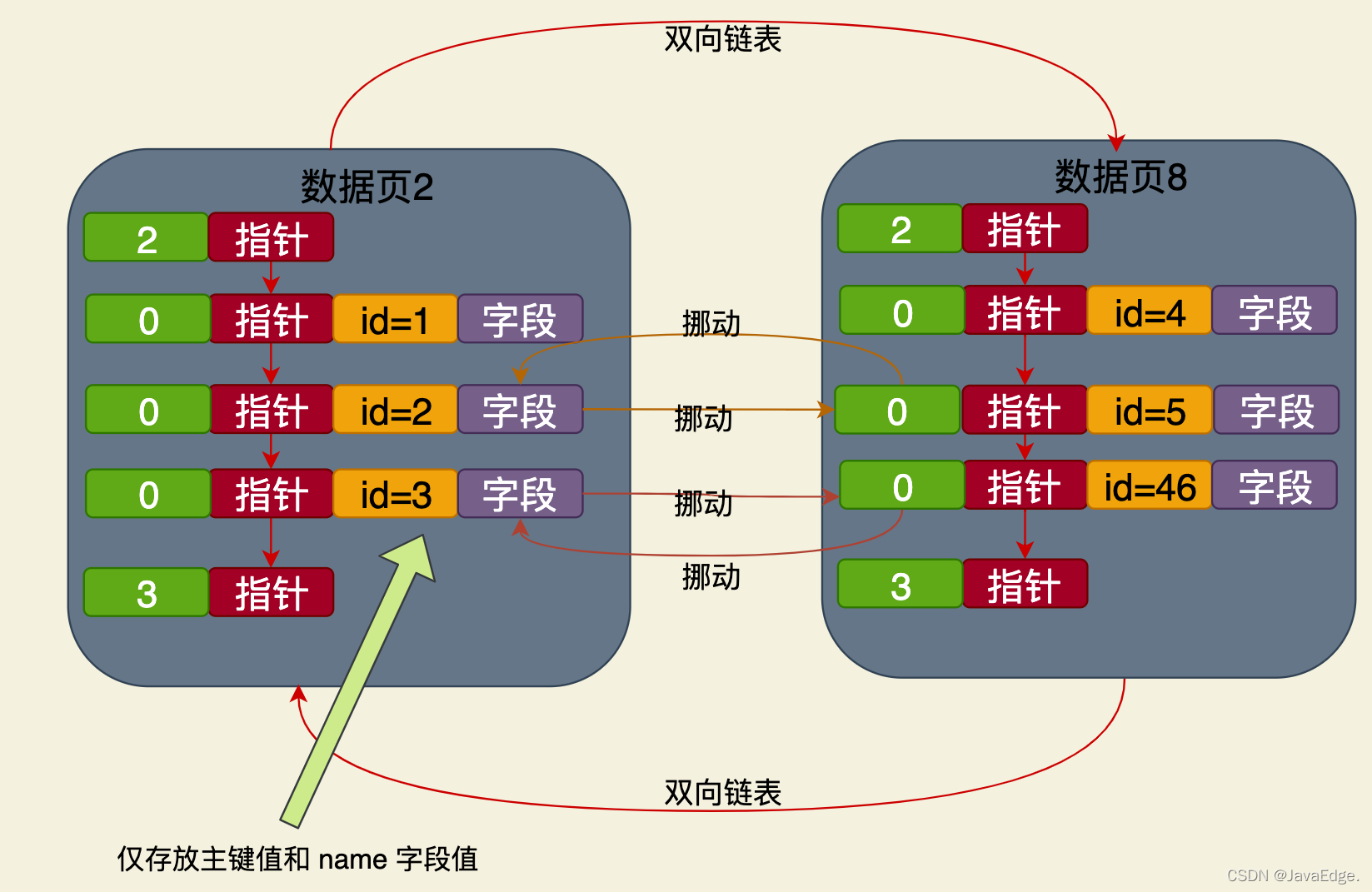
이것은 이름 필드가 클러스터형 인덱스와 독립적인 B+ 트리 기반 인덱스 구조입니다. 리프 노드에 저장된 데이터는 다음과 같습니다. 기본 키 및 이름 필드의 값.
전체 정렬 규칙은 기본 키에 따른 클러스터형 인덱스의 정렬 규칙과 동일합니다. 즉,
리프 노드의 데이터 페이지에 있는 이름 값이 모두 정렬됩니다
다음 데이터 페이지의 이름 필드 값 모두 > 이전 데이터 페이지의 이름 필드 값
이름 필드의 인덱스 B+ 트리는 또한 다중 레벨 인덱스 페이지를 구축합니다.
다음 레벨의 페이지 번호
최소 이름 필드 값, 이름 필드 값에 따라 정렬됨.
따라서 이름 필드를 기반으로 데이터를 쿼리하는 경우 이름 인덱스 트리의 루트 노드에서 시작하여 리프 노드의 데이터 페이지를 찾을 때까지 레이어별로 검색하고 프로세스는 동일합니다. 이름 필드 키 값에 해당하는 기본 페이지를 찾습니다.
그런 다음
select * from t where name='xx'
와 같은 문에 대해 먼저 이름 값을 기반으로 이름 인덱스 트리에서 검색하고 해당 기본 키 값만 찾을 수 있지만 이 데이터 행의 모든 필드를 찾을 수는 없습니다.
그래서 여전히 테이블로 돌아가야 합니다. 기본 키 값을 기반으로 루트 노드에서 시작하는 클러스터형 인덱스로 이동하여 리프 노드의 데이터 페이지를 찾고, 해당 테이블에 해당하는 전체 데이터 행을 찾아야 합니다. 그래야만 select * 모든 필드 값을 꺼낼 수 있습니다.
예를 들어 name+age이면 실행 프로세스는 동일하며 리프 노드의 데이터 페이지에 id+name+age가 저장되면 기본적으로 이름별로 정렬됩니다. 이름이 같으면 나이순으로 정렬됩니다. 페이지 간 이름+나이 값의 순서도 마찬가지입니다.
그러면 이름+나이 결합 인덱스의 B+ 트리 인덱스 페이지가 저장됩니다.
다음 레이어 노드의 페이지 번호
가장 작은 이름+나이 값
그러면 이름+나이를 기준으로 나이를 검색할 경우 이름+나이 조인트 인덱스 트리를 거쳐 기본키를 검색한 후 기본키를 기준으로 클러스터형 인덱스에서 검색하게 된다.
위 내용은 MySQL 보조 인덱스 쿼리 프로세스란 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



