

클러스터드 인덱스는 각 테이블의 기본 키를 기반으로 B+ 트리를 구성하고, 리프 노드에는 전체 테이블의 행 레코드 데이터가 저장됩니다.
예를 들어 클러스터형 인덱스를 직관적으로 느껴보자.
테이블 t를 생성하고 각 페이지에 두 개의 행 레코드만 인위적으로 저장하도록 허용합니다(페이지당 두 개의 행 레코드만 인위적으로 제어하는 방법은 모르겠습니다).
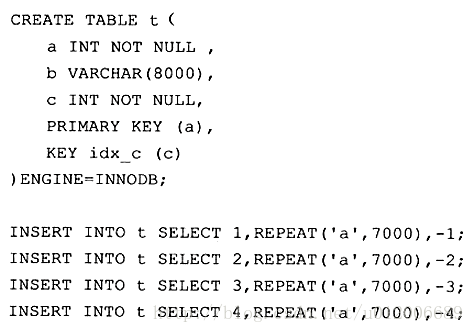
마지막으로 "MySQL Technology Insider" 작성자가 획득했습니다. 분석 도구를 통해 이 클러스터형 인덱스 트리의 대략적인 구조를 살펴보면 다음과 같습니다.
클러스터형 인덱스의 리프 노드를 데이터 페이지라고 하며, 각 노드는 이중 연결 리스트로 연결되어 있으며, 데이터 페이지는 배열되어 있습니다. 기본 키 순서대로.
그림과 같이 각 데이터 페이지에는 완전한 행 레코드가 저장되는 반면, 비데이터 페이지의 인덱스 페이지에는 완전한 행 레코드가 아닌 키 값과 데이터 페이지를 가리키는 오프셋만 저장됩니다. .
기본 키가 정의되면 InnoDB는 자동으로 기본 키를 사용하여 클러스터형 인덱스를 생성합니다. 기본 키가 정의되지 않은 경우 InnoDB는 기본 키 역할을 할 고유하고 비어 있지 않은 인덱스를 선택합니다. InnoDB는 null이 아닌 고유 인덱스가 없는 경우 기본 키를 클러스터형 인덱스로 암시적으로 정의합니다.
보조 인덱스, 비클러스터형 인덱스라고도 합니다. 클러스터형 인덱스와 비교하여 리프 노드에는 행 레코드의 모든 데이터가 포함되어 있지 않습니다. 키 값 외에도 리프 노드의 인덱스 행에는 인덱스에 해당하는 행 데이터를 찾을 위치를 InnoDB에 알려주는 데 사용되는 북마크(북마크)도 포함되어 있습니다.
"MySQL Technology Insider"의 예시를 통해 보조 인덱스가 어떤 모습인지 직관적으로 느껴보세요.
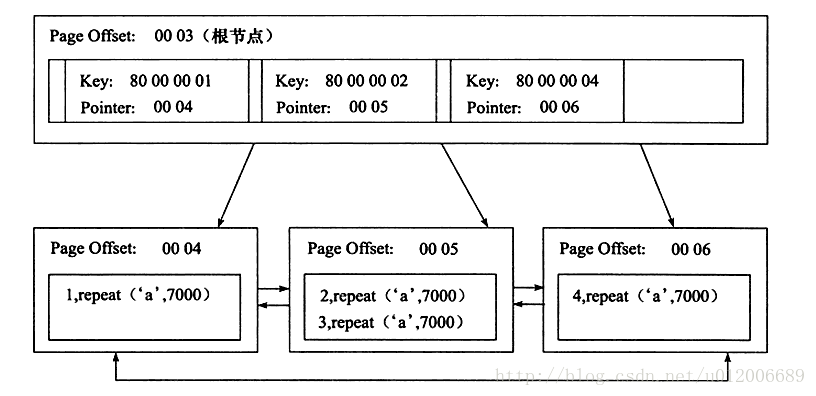
위의 표 t를 예로 들어 c열에 non-clustered 인덱스를 생성합니다.
그런 다음 작성자는 분석 작업을 통해 보조 인덱스와 클러스터형 인덱스 간의 관계 다이어그램을 얻었습니다.
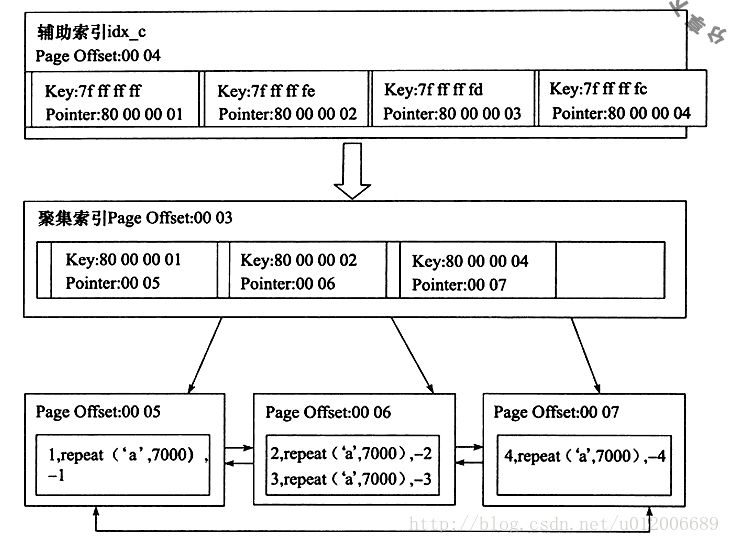
보조 인덱스를 볼 수 있습니다. idx_c의 리프 노드에는 c 열의 값과 기본 키의 값이 포함되어 있습니다.
예를 들어 Key 값이 0x7ffffffff라고 가정합니다. 여기서 7의 이진수 표현은 0111이고 0은 음수입니다. 실제 정수 값은 1을 더한 값으로 반전되어야 하므로 결과는 -1이 되며, 이것이 c열의 값이 됩니다. 기본 키 값은 양수 1이며 포인터 값 80000001로 표시됩니다. 여기서 8비트는 이진수 1000을 나타냅니다.
InnoDB 스토리지 엔진을 사용하면 클러스터형 인덱스의 레코드를 쿼리하지 않고도 보조 인덱스를 통해 인덱스를 커버하고 쿼리 레코드를 직접 얻을 수 있습니다.
커버링지수를 사용하면 어떤 장점이 있나요?
IO 작업을 많이 줄일 수 있습니다
위 그림에서 보조 인덱스에 포함되지 않은 필드를 쿼리하려면 먼저 보조 인덱스를 순회한 다음 클러스터링된 인덱스를 순회해야 함을 알 수 있습니다. 쿼리할 필드 값이 이미 보조 인덱스에 있으므로 클러스터형 인덱스를 확인할 필요가 없으므로 IO 작업이 확실히 줄어듭니다.
예를 들어 위 그림에서 다음 SQL은 보조 인덱스를 직접 사용할 수 있으며,
select a from where c = -2;
는 통계에 도움이 됩니다.
다음 테이블이 존재한다고 가정합니다.
CREATE TABLE `student` ( `id` bigint(20) NOT NULL, `name` varchar(255) NOT NULL, `age` varchar(255) NOT NULL, `school` varchar(255) NOT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`), KEY `idx_school_age` (`school`,`age`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
이 테이블에서 실행되는 경우:
select count(*) from student
옵티마이저는 어떻게 될까요?
클러스터형 인덱스와 보조 인덱스를 모두 순회하여 결과를 얻을 수 있지만 보조 인덱스의 크기가 클러스터형 인덱스보다 훨씬 작기 때문에 최적화 프로그램에서는 통계용 보조 인덱스를 선택합니다. explain 명령을 실행하십시오 :

key 및 Extra는 idx_name 보조 인덱스가 사용되었음을 보여줍니다.
또한 다음 SQL이 실행된다고 가정합니다.
select * from student where age > 10 and age < 15
공동 인덱스 idx_school_age의 필드 순서가 학교가 첫 번째이고 그 다음이 age이므로 일반적으로 인덱스를 사용하지 않고 나이에 따라 조건부 쿼리가 수행됩니다.

그러나 조건이 변경되지 않은 경우 항목 수를 쿼리하는 대신 모든 필드를 쿼리합니다.
select count(*) from student where age > 10 and age < 15
최적화 프로그램은 다음 조인트 인덱스를 선택합니다.

Joint index는 테이블의 여러 열을 인덱싱하는 것을 의미합니다.
다음은 공동 인덱스 idx_a_b를 생성하는 예입니다.

공동 인덱스의 내부 구조:
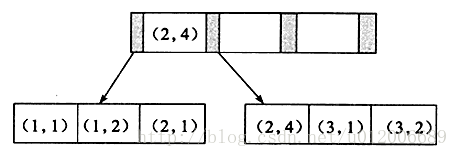
联合索引也是一棵B+树,其键值数量大于等于2。键值都是排序的,通过叶子节点可以逻辑上顺序的读出所有数据。数据(1,1)(1,2)(2,1)(2,4)(3,1)(3,2)是按照(a,b)先比较a再比较b的顺序排列。
基于上面的结构,对于以下查询显然是可以使用(a,b)这个联合索引的:
select * from table where a=xxx and b=xxx ; select * from table where a=xxx;
但是对于下面的sql是不能使用这个联合索引的,因为叶子节点的b值,1,2,1,4,1,2显然不是排序的。
select * from table where b=xxx
联合索引的第二个好处是对第二个键值已经做了排序。举个例子:
create table buy_log(
userid int not null,
buy_date DATE
)ENGINE=InnoDB;
insert into buy_log values(1, '2009-01-01');
insert into buy_log values(2, '2009-02-01');
alter table buy_log add key(userid);
alter table buy_log add key(userid, buy_date);当执行
select * from buy_log where user_id = 2;
时,优化器会选择key(userid);但是当执行以下sql:
select * from buy_log where user_id = 2 order by buy_date desc;
时,优化器会选择key(userid, buy_date),因为buy_date是在userid排序的基础上做的排序。
如果把key(userid,buy_date)删除掉,再执行:
select * from buy_log where user_id = 2 order by buy_date desc;
优化器会选择key(userid),但是对查询出来的结果会进行一次filesort,即按照buy_date重新排下序。所以联合索引的好处在于可以避免filesort排序。
위 내용은 mysql에서 클러스터형 인덱스, 보조 인덱스, 커버 인덱스, 조인트 인덱스 사용법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



