

빅모델 시대, 부적절한 콘텐츠를 어떻게 잡아낼 것인가? EU 법안은 AI 회사가 사용자의 알 권리를 보장하도록 요구합니다.

지난 10년 동안 거대 기술 기업은 언어, 예측, 개인화, 보관, 텍스트 구문 분석, 데이터 처리 등 다양한 기술에 매우 능숙해졌습니다. 그러나 유해한 콘텐츠를 포착하고, 표시하고, 제거하는 데는 여전히 형편 없습니다. 미국에 퍼지고 있는 선거와 백신 음모론의 경우, 그것이 야기하고 있는 실제 피해를 이해하려면 지난 2년간의 사건을 되돌아보기만 하면 됩니다.
이 차이점은 몇 가지 질문을 제기합니다. 기술 회사가 콘텐츠 조정을 개선하지 않는 이유는 무엇입니까? 강제로 그렇게 할 수 있습니까? 인공 지능의 새로운 발전으로 나쁜 정보를 포착하는 능력이 향상될까요?
대부분의 기술 회사는 미국 의회에서 증오와 잘못된 정보 확산에 대한 설명을 요청받을 때 자신의 실패를 언어 자체의 복잡성으로 비난하는 경향이 있습니다. 경영진은 서로 다른 언어와 상황에서 발생하는 상황에 맞는 증오심 표현을 이해하고 예방하는 것이 어려운 일이라고 말합니다.
Mark Zuckerberg가 가장 좋아하는 말 중 하나는 기술 회사가 전 세계의 모든 정치적 문제를 해결하는 데 책임을 져서는 안 된다는 것입니다.
 (출처: STEPHANIE ARNETT/MITTR | GETTY IMAGES)
(출처: STEPHANIE ARNETT/MITTR | GETTY IMAGES)
현재 대부분의 회사는 기술 및 인간 콘텐츠 중재자를 모두 사용하고 있으며, 후자의 업무는 과소평가되어 있으며 이는 낮은 급여에 반영됩니다.
예를 들어 AI는 현재 Facebook에서 삭제되는 모든 콘텐츠의 97%를 담당하고 있습니다.
그러나 Stanford Internet Observatory의 연구 관리자인 Renee DiResta는 AI가 뉘앙스와 맥락을 잘 해석하지 못하기 때문에 인간 콘텐츠 조정자를 완전히 대체할 가능성은 낮으며 인간조차도 이러한 사항을 항상 잘 설명하는 것은 아니라고 말했습니다. .
자동 콘텐츠 조정 시스템은 일반적으로 영어 데이터를 기반으로 훈련되기 때문에 문화적 배경과 언어도 문제를 야기하므로 다른 언어로 된 콘텐츠를 효과적으로 처리하기가 어렵습니다.
UC Berkeley 정보대학원의 Hani Farid 교수는 좀 더 명확한 설명을 제공합니다. Farid에 따르면 콘텐츠 조정은 기술 회사의 금전적 이익에 부합하지 않기 때문에 위험을 감당할 수 없습니다. 그것은 모두 탐욕에 관한 것입니다. 돈이 아닌 척 하지 마세요. ”
연방 규제가 없기 때문에 온라인 폭력 피해자가 플랫폼에 재정적 책임을 요구하기는 어렵습니다.
콘텐츠 조정은 기술 회사와 악당 사이의 끝없는 전쟁인 것 같습니다. 기술 회사가 콘텐츠 조정 규칙을 시행할 때 악의적인 행위자는 탐지를 피하기 위해 이모티콘이나 의도적인 철자 오류를 사용하는 경우가 많습니다. 그러면 이들 기업은 허점을 막으려고 노력하고, 사람들은 새로운 허점을 찾아내는 순환이 계속됩니다.

이제 대규모 언어 모델이 등장합니다...
현재 상황은 이미 매우 어렵습니다. 생성적 인공지능과 ChatGPT 등 대규모 언어 모델의 등장으로 상황은 더욱 악화될 수도 있다. 생성 기술에는 자신있게 사물을 구성하고 사실로 제시하는 경향과 같은 문제가 있지만 한 가지는 분명합니다. AI는 언어 능력이 매우 강력해지고 있다는 것입니다.
DiResta와 Farid 모두 조심스럽기는 하지만 상황이 어떻게 전개될 것인지 판단하기에는 아직 이르다고 생각합니다. GPT-4 및 Bard와 같은 많은 대형 모델에는 콘텐츠 조정 필터가 내장되어 있지만 여전히 증오심 표현이나 폭탄 제조 방법에 대한 지침과 같은 유해한 출력을 생성할 수 있습니다.
제너레이티브 AI를 사용하면 악의적인 행위자가 더 큰 규모와 속도로 허위 정보 캠페인을 수행할 수 있습니다. AI 생성 콘텐츠를 식별하고 라벨을 지정하는 방법이 비참할 정도로 부적절하다는 점을 고려하면 이는 끔찍한 상황입니다.
한편, 최신 대규모 언어 모델은 이전 인공 지능 시스템보다 텍스트 해석 성능이 더 좋습니다. 이론적으로는 자동화된 콘텐츠 조정 개발을 촉진하는 데 사용될 수 있습니다.
기술 회사는 이 특정 목표를 달성하기 위해 대규모 언어 모델을 재설계하는 데 투자해야 합니다. Microsoft와 같은 회사가 이 문제를 조사하기 시작했지만 아직 중요한 활동은 없습니다.
Farid는 다음과 같이 말했습니다. "많은 기술 발전을 보았지만 콘텐츠 조정의 개선에는 회의적입니다."
대규모 언어 모델이 빠르게 발전하고 있지만 여전히 맥락 이해에 어려움을 겪고 있습니다. 이로 인해 게시물과 이미지 간의 미묘한 차이를 인간 조정자만큼 정확하게 이해하지 못할 수 있습니다. 문화 간 확장성과 특수성도 문제를 야기합니다. DiResta는 "특정 유형의 틈새 시장에 대한 모델을 배포합니까? 국가별로 수행합니까? 커뮤니티별로 수행합니까? 이는 일률적인 질문이 아닙니다"라고 DiResta는 말했습니다.
신기술을 기반으로 한 새로운 도구
생성 AI가 궁극적으로 온라인 정보 환경에 해를 끼치거나 도움이 되는지 여부는 기술 회사가 콘텐츠가 AI에 의해 생성되었는지 여부를 알려주는 훌륭하고 널리 채택된 도구를 생각해 낼 수 있는지 여부에 크게 좌우될 수 있습니다.
DiResta는 합성 매체를 탐지하는 것이 기술적으로 어려운 일이기 때문에 우선순위를 두어야 한다고 말했습니다. 여기에는 첨부된 콘텐츠가 인공 지능에 의해 생성되었다는 영구적인 표시로 코드 조각을 삽입하는 것을 의미하는 디지털 워터마킹과 같은 방법이 포함됩니다. AI가 생성하거나 조작한 게시물을 탐지하는 자동화된 도구는 워터마크와 달리 AI 생성 콘텐츠 작성자의 적극적인 태그가 필요하지 않기 때문에 매력적입니다. 즉, 기계 생성 콘텐츠를 식별하려는 현재 도구는 제대로 작동하지 않습니다.
일부 회사에서는 콘텐츠 생성 방법과 같은 정보의 암호화 서명을 안전하게 기록하기 위해 수학을 사용할 것을 제안하기도 했지만 이는 워터마크와 같은 자발적 공개 기술에 의존합니다.
지난 주 유럽 연합이 제안한 최신 버전의 인공 지능법(AI Act)에서는 생성 인공 지능을 사용하는 회사가 콘텐츠가 실제로 기계 생성된 경우 사용자에게 알리도록 요구합니다. AI 생성 콘텐츠의 투명성에 대한 요구가 증가함에 따라 앞으로 몇 달 안에 새로운 도구에 대해 더 많이 듣게 될 것입니다.
지원: 렌
원문:
https://www.technologyreview.com/2023/05/15/1073019/catching-bad-content-in-the-age-of-ai/
위 내용은 빅모델 시대, 부적절한 콘텐츠를 어떻게 잡아낼 것인가? EU 법안은 AI 회사가 사용자의 알 권리를 보장하도록 요구합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7868
7868
 15
1649
14
1407
52
1301
25
1244
29
15
1649
14
1407
52
1301
25
1244
29

 대형 모델 앱 Tencent Yuanbao가 온라인에 출시되었습니다! Hunyuan은 어디서나 휴대할 수 있는 만능 AI 비서로 업그레이드되었습니다.
Jun 09, 2024 pm 10:38 PM
대형 모델 앱 Tencent Yuanbao가 온라인에 출시되었습니다! Hunyuan은 어디서나 휴대할 수 있는 만능 AI 비서로 업그레이드되었습니다.
Jun 09, 2024 pm 10:38 PM
5월 30일, Tencent는 Hunyuan 모델의 포괄적인 업그레이드를 발표했습니다. Hunyuan 모델을 기반으로 하는 앱 "Tencent Yuanbao"가 공식 출시되었으며 Apple 및 Android 앱 스토어에서 다운로드할 수 있습니다. 이전 테스트 단계의 Hunyuan 애플릿 버전과 비교하여 Tencent Yuanbao는 일상 생활 시나리오를 위한 작업 효율성 시나리오를 위한 AI 검색, AI 요약 및 AI 작성과 같은 핵심 기능을 제공하며 Yuanbao의 게임 플레이도 더욱 풍부해지고 다양한 기능을 제공합니다. , 개인 에이전트 생성과 같은 새로운 게임 플레이 방법이 추가됩니다. Tencent Cloud 부사장이자 Tencent Hunyuan 대형 모델 책임자인 Liu Yuhong은 "Tencent는 먼저 대형 모델을 만들기 위해 노력하지 않을 것입니다."라고 말했습니다. Tencent Hunyuan 대형 모델 비즈니스 시나리오에서 풍부하고 방대한 폴란드 기술을 활용하면서 사용자의 실제 요구 사항에 대한 통찰력을 얻습니다.
 Bytedance Beanbao 대형 모델 출시, Volcano Engine 풀스택 AI 서비스로 기업의 지능적 혁신 지원
Jun 05, 2024 pm 07:59 PM
Bytedance Beanbao 대형 모델 출시, Volcano Engine 풀스택 AI 서비스로 기업의 지능적 혁신 지원
Jun 05, 2024 pm 07:59 PM
Volcano Engine의 Tan Dai 사장은 대형 모델을 구현하려는 기업은 모델 효율성, 추론 비용, 구현 어려움이라는 세 가지 주요 과제에 직면하게 된다고 말했습니다. 복잡한 문제를 해결하기 위한 지원으로 좋은 기본 대형 모델이 있어야 하며, 서비스를 통해 대규모 모델을 널리 사용할 수 있으며 기업이 시나리오를 구현하는 데 더 많은 도구, 플랫폼 및 애플리케이션이 필요합니다. ——Tan Dai, Huoshan Engine 01 사장. 대형 빈백 모델이 출시되어 많이 사용되고 있습니다. 모델 효과를 연마하는 것은 AI 구현에 있어 가장 중요한 과제입니다. Tan Dai는 좋은 모델은 많은 양의 사용을 통해서만 연마될 수 있다고 지적했습니다. 현재 Doubao 모델은 매일 1,200억 개의 텍스트 토큰을 처리하고 3,000만 개의 이미지를 생성합니다. 기업이 대규모 모델 시나리오를 구현하는 데 도움을 주기 위해 ByteDance가 독자적으로 개발한 beanbao 대규모 모델이 화산을 통해 출시됩니다.
 NVIDIA 대규모 모델 추론 프레임워크 살펴보기: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
NVIDIA 대규모 모델 추론 프레임워크 살펴보기: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
1. TensorRT-LLM의 제품 포지셔닝 TensorRT-LLM은 NVIDIA에서 LLM(대형 언어 모델)을 위해 개발한 확장 가능한 추론 솔루션입니다. TensorRT 딥 러닝 컴파일 프레임워크를 기반으로 계산 그래프를 구축, 컴파일 및 실행하고 FastTransformer의 효율적인 커널 구현을 활용합니다. 또한 장치 간 통신에는 NCCL을 활용합니다. 개발자는 커틀라스를 기반으로 한 맞춤형 GEMM을 개발하는 등 기술 개발 및 수요 차이를 기반으로 특정 요구 사항을 충족하도록 운영자를 맞춤화할 수 있습니다. TensorRT-LLM은 고성능을 제공하고 실용성을 지속적으로 개선하기 위해 노력하는 NVIDIA의 공식 추론 솔루션입니다. 텐서RT-LL
 Shengteng AI 기술을 사용한 Qinling·Qinchuan 교통 모델은 Xi'an이 스마트 교통 혁신 센터를 구축하는 데 도움이 됩니다.
Oct 15, 2023 am 08:17 AM
Shengteng AI 기술을 사용한 Qinling·Qinchuan 교통 모델은 Xi'an이 스마트 교통 혁신 센터를 구축하는 데 도움이 됩니다.
Oct 15, 2023 am 08:17 AM
"높은 복잡성, 높은 단편화 및 교차 도메인"은 항상 운송 산업의 디지털 및 지능적 업그레이드로 가는 길의 주요 문제점이었습니다. 최근에는 China Vision, Xi'an Yanta District Government, Xi'an Future Artificial Intelligence Computing Center가 공동으로 구축한 매개변수 규모 1,000억 규모의 '친링·친추안 교통 모델'이 스마트 교통 및 스마트 교통 분야를 지향하고 있습니다. 시안과 그 주변 지역에 서비스를 제공하여 스마트 교통 혁신의 거점을 만들 것입니다. '친링·친추안 교통 모델'은 개방형 시나리오의 시안의 대규모 지역 교통 생태 데이터, China Vision이 독자적으로 개발한 독창적인 고급 알고리즘, 시안 미래 인공 지능 컴퓨팅 센터의 Shengteng AI의 강력한 컴퓨팅 성능을 결합하여 도로를 제공합니다. 네트워크 모니터링, 비상 명령, 유지 관리, 대중 교통 등 스마트 교통 시나리오는 디지털 및 지능적 변화를 가져옵니다. 교통 관리는 도시마다 특성이 다르며 도로 교통도 다릅니다.
 산업지식 그래프 고급실습
Jun 13, 2024 am 11:59 AM
산업지식 그래프 고급실습
Jun 13, 2024 am 11:59 AM
1. 배경 소개 먼저 Yunwen Technology의 발전 역사를 소개하겠습니다. Yunwen Technology Company...2023년은 대형 모델이 유행하는 시기입니다. 많은 기업에서는 대형 모델 이후 그래프의 중요성이 크게 감소했으며 이전에 연구된 사전 설정 정보 시스템이 더 이상 중요하지 않다고 생각합니다. 그러나 RAG의 홍보와 데이터 거버넌스의 확산으로 우리는 보다 효율적인 데이터 거버넌스와 고품질 데이터가 민영화된 대형 모델의 효율성을 향상시키는 중요한 전제 조건이라는 것을 알게 되었습니다. 따라서 점점 더 많은 기업이 주목하기 시작했습니다. 지식 구축 관련 콘텐츠에 이는 또한 탐구할 수 있는 많은 기술과 방법이 있는 더 높은 수준으로 지식의 구성 및 처리를 촉진합니다. 신기술의 출현이 기존 기술을 모두 패배시키는 것이 아니라, 신기술과 기존 기술을 통합할 수도 있음을 알 수 있습니다.
 벤치마크 GPT-4! 차이나 모바일의 Jiutian 대형 모델이 이중 등록을 통과했습니다.
Apr 04, 2024 am 09:31 AM
벤치마크 GPT-4! 차이나 모바일의 Jiutian 대형 모델이 이중 등록을 통과했습니다.
Apr 04, 2024 am 09:31 AM
4월 4일 뉴스에 따르면 중국 사이버공간국은 최근 등록된 대형 모델 목록을 공개했는데, 여기에 차이나 모바일의 'Jiutian Natural Language Interaction Large Model'이 포함돼 있어 차이나 모바일의 Jiutian AI 대형 모델이 공식적으로 생성 인공 지능을 제공할 수 있음을 알렸다. 외부 세계에 대한 정보 서비스. 차이나 모바일은 이 모델이 중앙 기업이 개발한 최초의 대규모 모델로 국가 '생성 인공 지능 서비스 등록'과 '국내 심층 합성 서비스 알고리즘 등록' 이중 등록을 모두 통과했다고 밝혔습니다. 보고서에 따르면 Jiutian의 자연어 상호 작용 대형 모델은 향상된 산업 역량, 보안 및 신뢰성을 갖추고 있으며 풀 스택 현지화를 지원하며 90억, 139억, 570억, 1000억 등 다양한 매개변수 버전을 형성했습니다. 클라우드에 유연하게 배포할 수 있으며 엣지와 엔드는 상황이 다릅니다.
 새로운 테스트 벤치마크 공개, 가장 강력한 오픈소스 라마3 당황스럽다
Apr 23, 2024 pm 12:13 PM
새로운 테스트 벤치마크 공개, 가장 강력한 오픈소스 라마3 당황스럽다
Apr 23, 2024 pm 12:13 PM
시험 문제가 너무 단순하면 상위권 학생과 하위 학생 모두 90점을 받을 수 있어 격차가 더 벌어질 수 없다… 클로드3, 라마3, 심지어 GPT-5 등 더욱 강력한 모델이 출시되면서 업계는 보다 어렵고 차별화된 모델 벤치마크가 시급히 필요합니다. 대형 모델 아레나를 운영하는 조직인 LMSYS가 차세대 벤치마크인 Arena-Hard를 출시해 큰 관심을 끌었습니다. Llama3 명령의 두 가지 미세 조정 버전의 강점에 대한 최신 참조도 있습니다. 이전에 비슷한 점수를 받았던 MTBench와 비교하면 Arena-Hard 판별력이 22.6%에서 87.4%로 증가해 한눈에 봐도 강하고 약해졌습니다. Arena-Hard는 경기장의 실시간 인간 데이터를 사용하여 구축되었으며 인간 선호도와 89.1%의 일치율을 가지고 있습니다.
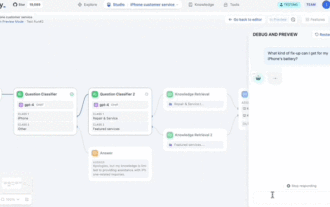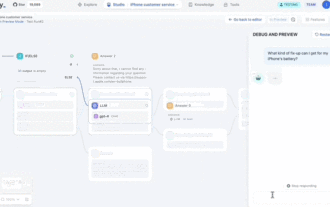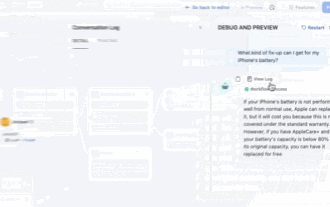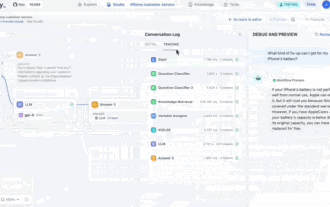 GPT Store는 문도 열 수 없습니다. 이 국내 플랫폼이 어떻게 감히 이런 길을 갈 수 있습니까? ?
Apr 19, 2024 pm 09:30 PM
GPT Store는 문도 열 수 없습니다. 이 국내 플랫폼이 어떻게 감히 이런 길을 갈 수 있습니까? ?
Apr 19, 2024 pm 09:30 PM
주의하세요. 이 사람은 1,000개 이상의 대형 모델을 연결하여 원활하게 연결하고 전환할 수 있습니다. 최근에는 시각적인 AI 워크플로우가 출시되었습니다. 직관적인 드래그 앤 드롭 인터페이스를 제공하여 무한한 캔버스에 드래그하고 당기고 드래그하여 자신만의 워크플로우를 배열할 수 있습니다. 속담처럼 전쟁에는 속도가 필요하며 Qubit은 이 AIWorkflow가 온라인에 접속한 후 48시간 이내에 사용자가 이미 100개 이상의 노드로 개인 워크플로를 구성했다는 소식을 들었습니다. 더 이상 고민하지 않고 오늘 제가 이야기하고 싶은 것은 LLMOps 회사인 Dify와 그 CEO인 Zhang Luyu입니다. Zhang Luyu는 Dify의 창립자이기도 합니다. 사업에 합류하기 전에 그는 인터넷 업계에서 11년의 경력을 쌓았습니다. 저는 제품 디자인에 참여하고 있으며 프로젝트 관리를 이해하고 있으며 SaaS에 대한 독특한 통찰력을 가지고 있습니다. 나중에 그는
