

MySQL 최적화 인덱스 병합으로 인한 교착 상태를 해결하는 방법

Background
프로덕션 환경에서 교착상태가 발생했습니다. 교착상태 로그를 살펴보면 동일한 두 개의 업데이트 문(where 조건의 값만 다름)으로 인해 교착상태가 발생한 것을 확인했습니다.
다음과 같습니다. :
UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx1' AND `status` = 0; UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx2' AND `status` = 0;
一처음에는 좀 혼란스러웠습니다. 많은 문의와 연구 끝에 교착상태를 겪는 친구들에게 도움이 되길 바라는 마음으로 분석해보았습니다. 같은 문제.
MySQL에는 지식 포인트가 많기 때문에 여기서는 많은 명사를 소개하지 않을 것입니다. 관심 있는 친구들은 특별한 심층 학습을 통해 후속 조치를 취할 수 있습니다. MySQL知识点较多,这里对很多名词不进行过多介绍,有兴趣的朋友,可以后续进行专项深入学习。
死锁日志
*** (1) TRANSACTION: TRANSACTION 791913819, ACTIVE 0 sec starting index read, thread declared inside InnoDB 4999 mysql tables in use 3, locked 3 LOCK WAIT 4 lock struct(s), heap size 1184, 3 row lock(s) MySQL thread id 462005230, OS thread handle 0x7f55d5da3700, query id 2621313306 x.x.x.x test_user Searching rows for update UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx1' AND `status` = 0; *** (1) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 110 page no 39167 n bits 1056 index `idx_status` of table `test`.`test_table` trx id 791913819 lock_mode X waiting Record lock, heap no 495 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 *** (2) TRANSACTION: TRANSACTION 791913818, ACTIVE 0 sec starting index read, thread declared inside InnoDB 4999 mysql tables in use 3, locked 3 5 lock struct(s), heap size 1184, 4 row lock(s) MySQL thread id 462005231, OS thread handle 0x7f55cee63700, query id 2621313305 x.x.x.x test_user Searching rows for update UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx2' AND `status` = 0; *** (2) HOLDS THE LOCK(S): RECORD LOCKS space id 110 page no 39167 n bits 1056 index `idx_status` of table `test`.`test_table` trx id 791913818 lock_mode X Record lock, heap no 495 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 *** (2) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 110 page no 41569 n bits 88 index `PRIMARY` of table `test`.`test_table` trx id 791913818 lock_mode X locks rec but not gap waiting Record lock, heap no 14 PHYSICAL RECORD: n_fields 30; compact format; info bits 0 *** WE ROLL BACK TRANSACTION (1)
简要分析下上边的死锁日志:
1、第一块内容(第1行到第9行)中,第6行为事务(1)执行的SQL语句,第7和第8行意思为事务(1)在等待 idx_status 索引上的X锁;
2、第二块内容(第11行到第19行)中,第16行为事务(2)执行的SQL语句,第17和第18行意思为事务(2)持有 idx_status 索引上的X锁;
意思为:事务(2)正在等待在 PRIMARY 索引上获取 X 锁。(but not gap指不是间隙锁)
4、最后一句的意思即为,MySQL将事务(1)进行了回滚操作。
表结构
CREATE TABLE `test_table` ( `id` int(11) NOT NULL AUTO_INCREMENT, `trans_id` varchar(21) NOT NULL, `status` int(11) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uniq_trans_id` (`trans_id`) USING BTREE, KEY `idx_status` (`status`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
通过表结构可以看出,trans_id 列上有一个唯一索引uniq_trans_id ,status 列上有一个普通索引idx_status ,id列为主键索引 PRIMARY 。
InnoDB引擎中有两种索引:
聚簇索引: 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据。
辅助索引: 辅助索引叶子节点存储的是主键值,也就是聚簇索引的键值。
主键索引 PRIMARY 就是聚簇索引,叶子节点中会保存行数据。uniq_trans_id 索引和idx_status 索引为辅助索引,叶子节点中保存的是主键值,也就是id列值。
当我们通过辅助索引查找行数据时,先通过辅助索引找到主键id,再通过主键索引进行二次查找(也叫回表),最终找到行数据。
执行计划
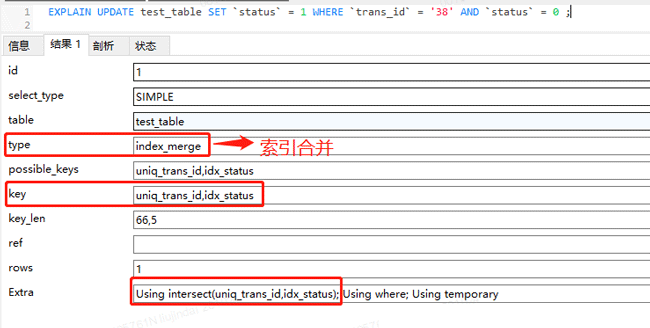
通过看执行计划,可以发现,update语句用到了索引合并,也就是这条语句既用到了 uniq_trans_id 索引,又用到了 idx_status 索引,Using intersect(uniq_trans_id,idx_status)的意思是通过两个索引获取交集。
为什么会用 index_merge(索引合并)
MySQL5.0之前,一个表一次只能使用一个索引,无法同时使用多个索引分别进行条件扫描。但是从5.1开始,引入了 index merge 优化技术,对同一个表可以使用多个索引分别进行条件扫描。
如执行计划中的语句:
UPDATE test_table SET `status` = 1 WHERE `trans_id` = '38' AND `status` = 0 ;
MySQL会根据 trans_id = ‘38’这个条件,利用 uniq_trans_id 索引找到叶子节点中保存的id值;同时会根据 status = 0这个条件,利用 idx_status 索引找到叶子节点中保存的id值;然后将找到的两组id值取交集,最终通过交集后的id回表,也就是通过 PRIMARY 索引找到叶子节点中保存的行数据。
这里可能很多人会有疑问了,uniq_trans_id 已经是一个唯一索引了,通过这个索引最终只能找到最多一条数据,那MySQL优化器为啥还要用两个索引取交集,再回表进行查询呢,这样不是多了一次 idx_status 索引查找的过程么。我们来分析一下这两种情况执行过程。
第一种 只用uniq_trans_id索引 :
根据
trans_id = ‘38’查询条件,利用uniq_trans_id索引找到叶子节点中保存的id值;通过找到的id值,利用PRIMARY索引找到叶子节点中保存的行数据;
再通过
status = 0条件对找到的行数据进行过滤。
第二种 用到索引合并 Using intersect(uniq_trans_id,idx_status):
根据
trans_id = ‘38’查询条件,利用uniq_trans_id索引找到叶子节点中保存的id值;-
根据
교착 상태 로그🎜rrreee🎜🎜위 교착 상태 로그에 대한 간략한 분석:🎜🎜status = 0查询条件,利用idx_status- 🎜1 첫 번째 내용(라인 1 ~ 라인 9). 6번째 줄은 트랜잭션(1)이 실행한 SQL 문이고, 7번째와 8번째 줄은 트랜잭션(1)이 idx_status 인덱스에 대한 X 잠금을 기다리고 있음을 의미합니다. 🎜
- 🎜2. 내용(11행~19행)에서 16행은 트랜잭션(2)에 의해 실행되는 SQL 문이고, 17행과 18행은 트랜잭션(2)이 idx_status 인덱스에 X 잠금을 보유하고 있음을 의미합니다. 🎜 🎜의미: 트랜잭션 (2)가 PRIMARY 인덱스에 대한 X 잠금을 획득하기를 기다리고 있습니다. (그러나 gap이 아니라는 것은 gap 잠금이 아니라는 것을 의미합니다)🎜
- 🎜4. 마지막 문장은 MySQL이 트랜잭션을 롤백했음을 의미합니다(1). 🎜
trans_id 열에 고유 인덱스 uniq_trans_id 가 있습니다. code>status 컬럼에는 일반 인덱스 idx_status가 있고, id 컬럼은 기본키 인덱스 PRIMARY입니다. 🎜🎜🎜InnoDB 엔진에는 두 종류의 인덱스가 있습니다: 🎜🎜- 🎜🎜클러스터형 인덱스: 🎜 데이터 저장소와 인덱스를 함께 넣고 리프 노드를 저장합니다. 인덱스 구조 행 데이터의 🎜
- 🎜🎜보조 인덱스: 🎜 보조 인덱스 리프 노드에는 클러스터형 인덱스의 키 값인 기본 키 값이 저장됩니다. 🎜
PRIMARY는 클러스터형 인덱스이며 행 데이터는 리프 노드에 저장됩니다. uniq_trans_id 인덱스와 idx_status 인덱스는 보조 인덱스이며 리프 노드에는 id 열 값인 기본 키 값이 저장됩니다. 🎜🎜보조 인덱스를 통해 행 데이터를 검색할 때 먼저 보조 인덱스를 통해 기본 키 ID를 찾은 다음 기본 키 인덱스를 통해 2차 검색을 수행하고(테이블로 다시 호출되기도 함) 마지막으로 행 데이터를 찾습니다. . 🎜🎜실행 계획🎜🎜🎜🎜실행 계획을 보면 업데이트 문이 인덱스 병합을 사용하는 것을 알 수 있습니다. 즉, 이 문은 uniq_trans_id 인덱스와 idx_status 인덱스를 모두 사용합니다. , intersect(uniq_trans_id,idx_status)를 사용한다는 것은 두 개의 인덱스를 통해 교차점을 얻는 것을 의미합니다. 🎜🎜index_merge를 사용하는 이유는 무엇인가요? 🎜🎜MySQL 5.0 이전에는 테이블이 한 번에 하나의 인덱스만 사용할 수 있었고 조건부 스캔을 위해 동시에 여러 인덱스를 사용할 수 없었습니다. 하지만 5.1부터는 인덱스 병합 최적화 기술이 도입되어 여러 인덱스를 사용하여 동일한 테이블에 대해 조건부 스캔을 수행할 수 있습니다. 🎜🎜🎜예를 들어 실행 계획의 문: 🎜🎜rrreee🎜MySQL은 trans_id = &lsquo 조건에 따라 <code>uniq_trans_id 인덱스를 사용하여 리프 노드에 저장된 ID를 찾습니다. ;38’ 값; 동시에 status = 0 조건에 따라 idx_status 인덱스를 사용하여 저장된 id 값을 찾습니다. 그러면 발견된 두 개의 id 값이 교차되고 최종적으로 전달됩니다. 교차 후의 ID는 테이블로 반환됩니다. 즉, 리프 노드에 저장된 행 데이터는 PRIMARY 인덱스를 통해 검색됩니다. 🎜🎜여기서 많은 사람들이 질문할 수 있습니다. uniq_trans_id는 이미 고유한 인덱스입니다. 그러면 MySQL 최적화 프로그램은 왜 두 개의 인덱스를 사용하여 데이터를 검색합니까? 그런 다음 쿼리를 위해 테이블로 돌아가면 또 다른 idx_status 인덱스 검색 프로세스가 추가되지 않나요? 이 두 가지 상황의 실행 과정을 분석해 보겠습니다. 🎜🎜🎜첫 번째는 uniq_trans_id 인덱스만 사용합니다: 🎜🎜- 🎜
trans_id = ‘38’쿼리 조건에 따라 uniq_trans_id 인덱스는 리프 노드에 저장된 id 값을 찾습니다. 🎜 - 🎜PRIMARY 인덱스를 사용하여 찾은 id 값을 통해 리프 노드에 저장된 행 데이터를 찾습니다. /li>
- 🎜그런 다음
status = 0조건을 통해 발견된 행 데이터를 필터링합니다. 🎜
intersect(uniq_trans_id,idx_status) 사용: 🎜- 🎜에 따르면
trans_id = ‘38’쿼리 조건은uniq_trans_id인덱스를 사용하여 리프 노드에 저장된 id 값을 찾습니다. 🎜 - 🎜
status = 0쿼리 조건,idx_status인덱스를 사용하여 리프 노드에 저장된 id 값을 찾습니다. 1/2에서 찾은 id 값을 교차시킨 후 PRIMARY 인덱스를 사용하여 리프 노드에 저장된 행 데이터를 찾습니다
위 두 경우의 주요 차이점은 첫 번째는 먼저 인덱스를 통해 데이터를 전달합니다. 찾은 후 다른 쿼리 조건을 사용하여 필터링합니다. 두 번째 방법은 먼저 두 인덱스에서 찾은 id 값의 교차점을 얻는 것입니다. 교차점 후에도 id 값이 여전히 존재합니다. 데이터를 검색하려면 테이블로 돌아가세요.
옵티마이저가 두 번째 경우의 실행 비용이 첫 번째 경우보다 작다고 판단하면 인덱스 병합이 발생합니다. (프로덕션 환경 플로우 테이블 status = 0에는 데이터가 거의 없습니다. 이는 최적화 프로그램이 두 번째 경우를 고려하는 이유 중 하나입니다.) status = 0 的数据非常少,这也是优化器考虑用第二种情况的原因之一)。
为什么用了 index_merge 就死锁了
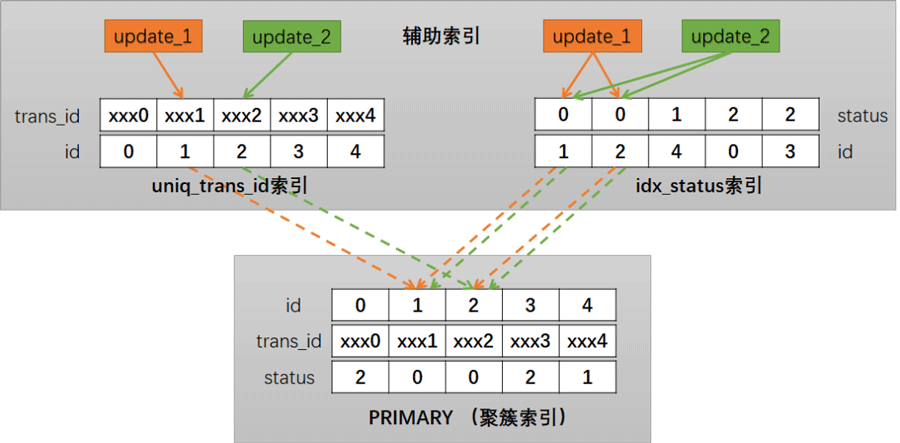
上面简要画了一下两个update事务加锁的过程,从图中可以看到,在idx_status 索引和 PRIMARY (聚簇索引) 上都存在重合交叉的部分,这样就为死锁造成了条件。
如,当遇到以下时序时,就会出现死锁:
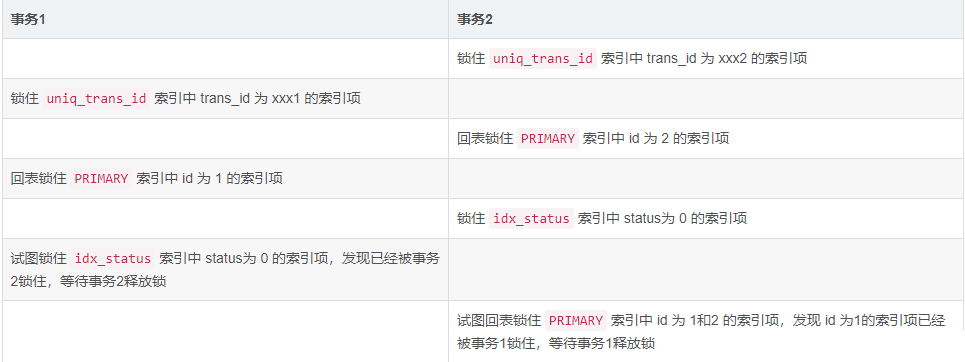
事务1等待事务2释放锁,事务2等待事务1释放锁,这样就造成了死锁。
MySQL检测到死锁后,会自动回滚代价更低的那个事务,如上边的时序图中,事务1持有的锁比事务2少,则MySQL就将事务1进行了回滚。
解决方案
一、从代码层面
where 查询条件中,只传
trans_id,将数据查询出来后,在代码层面判断 status 状态是否为0;使用
force index(uniq_trans_id)强制查询语句使用uniq_trans_id索引;where 查询条件后边直接用 id 字段,通过主键去更新。
二、从MySQL层面
删除
idx_status索引或者建一个包含这俩列的联合索引;-
将MySQL优化器的
index mergeindex_merge를 사용한 후 교착 상태가 발생하는 이유는 무엇입니까?
🎜🎜위에서는 두 개의 업데이트 트랜잭션의 잠금 프로세스를 간략하게 그렸습니다. 그림에서 알 수 있듯이 idx_status 인덱스와 PRIMARY에 (클러스터형 인덱스)에는 겹치고 교차하는 부분이 있어 교착 상태가 발생합니다. 🎜🎜예를 들어 다음 타이밍에 도달하면 교착 상태가 발생합니다.🎜🎜 🎜🎜트랜잭션 1은 트랜잭션 2가 잠금을 해제할 때까지 기다리고, 트랜잭션 2는 트랜잭션 1이 잠금을 해제할 때까지 기다리므로 오류가 발생합니다. 이중 자물쇠. 🎜🎜MySQL은 교착 상태를 감지한 후 자동으로 더 낮은 비용으로 트랜잭션을 롤백합니다. 예를 들어 위의 타이밍 다이어그램에서 트랜잭션 1은 트랜잭션 2보다 적은 수의 잠금을 보유하므로 MySQL은 트랜잭션 1을 롤백합니다. 🎜
🎜🎜트랜잭션 1은 트랜잭션 2가 잠금을 해제할 때까지 기다리고, 트랜잭션 2는 트랜잭션 1이 잠금을 해제할 때까지 기다리므로 오류가 발생합니다. 이중 자물쇠. 🎜🎜MySQL은 교착 상태를 감지한 후 자동으로 더 낮은 비용으로 트랜잭션을 롤백합니다. 예를 들어 위의 타이밍 다이어그램에서 트랜잭션 1은 트랜잭션 2보다 적은 수의 잠금을 보유하므로 MySQL은 트랜잭션 1을 롤백합니다. 🎜해결책
1. 코드 수준에서
- 🎜🎜여기서 쿼리 조건은
trans_id만 전달하세요. 데이터를 쿼리한 후 코드 수준에서 상태가 0인지 확인합니다. 🎜🎜🎜🎜force index(uniq_trans_id)를 사용하여 쿼리 문이 uniq_trans_id 인덱스를 사용하도록 합니다. 🎜 🎜🎜🎜여기서 쿼리 조건 바로 뒤에 id 필드를 사용하고 기본 키를 통해 업데이트합니다. 🎜🎜🎜2. MySQL 수준에서
- 🎜🎜
idx_status 인덱스를 삭제하거나 이 두 열을 포함하는 공동 인덱스를 생성합니다. ; 🎜🎜🎜🎜MySQL 최적화 프로그램의 인덱스 병합 최적화를 끄세요. 🎜🎜🎜위 내용은 MySQL 최적화 인덱스 병합으로 인한 교착 상태를 해결하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7469
7469
 15
1376
52
77
11
48
19
19
29
15
1376
52
77
11
48
19
19
29

 MySQL 사용자와 데이터베이스의 관계
Apr 08, 2025 pm 07:15 PM
MySQL 사용자와 데이터베이스의 관계
Apr 08, 2025 pm 07:15 PM
MySQL 데이터베이스에서 사용자와 데이터베이스 간의 관계는 권한과 테이블로 정의됩니다. 사용자는 데이터베이스에 액세스 할 수있는 사용자 이름과 비밀번호가 있습니다. 권한은 보조금 명령을 통해 부여되며 테이블은 Create Table 명령에 의해 생성됩니다. 사용자와 데이터베이스 간의 관계를 설정하려면 데이터베이스를 작성하고 사용자를 생성 한 다음 권한을 부여해야합니다.
 MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL은 설치가 간단하고 강력하며 데이터를 쉽게 관리하기 쉽기 때문에 초보자에게 적합합니다. 1. 다양한 운영 체제에 적합한 간단한 설치 및 구성. 2. 데이터베이스 및 테이블 작성, 삽입, 쿼리, 업데이트 및 삭제와 같은 기본 작업을 지원합니다. 3. 조인 작업 및 하위 쿼리와 같은 고급 기능을 제공합니다. 4. 인덱싱, 쿼리 최적화 및 테이블 파티셔닝을 통해 성능을 향상시킬 수 있습니다. 5. 데이터 보안 및 일관성을 보장하기위한 지원 백업, 복구 및 보안 조치.
 Navicat에서 데이터베이스 비밀번호를 검색 할 수 있습니까?
Apr 08, 2025 pm 09:51 PM
Navicat에서 데이터베이스 비밀번호를 검색 할 수 있습니까?
Apr 08, 2025 pm 09:51 PM
Navicat 자체는 데이터베이스 비밀번호를 저장하지 않으며 암호화 된 암호 만 검색 할 수 있습니다. 솔루션 : 1. 비밀번호 관리자를 확인하십시오. 2. Navicat의 "비밀번호 기억"기능을 확인하십시오. 3. 데이터베이스 비밀번호를 재설정합니다. 4. 데이터베이스 관리자에게 문의하십시오.
 MySQL의 쿼리 최적화는 데이터베이스 성능을 향상시키는 데 필수적입니다. 특히 대규모 데이터 세트를 처리 할 때
Apr 08, 2025 pm 07:12 PM
MySQL의 쿼리 최적화는 데이터베이스 성능을 향상시키는 데 필수적입니다. 특히 대규모 데이터 세트를 처리 할 때
Apr 08, 2025 pm 07:12 PM
1. 올바른 색인을 사용하여 스캔 한 데이터의 양을 줄임으로써 데이터 검색 속도를 높이십시오. 테이블 열을 여러 번 찾으면 해당 열에 대한 인덱스를 만듭니다. 귀하 또는 귀하의 앱이 기준에 따라 여러 열에서 데이터가 필요한 경우 복합 인덱스 2를 만듭니다. 2. 선택을 피하십시오 * 필요한 열만 선택하면 모든 원치 않는 열을 선택하면 더 많은 서버 메모리를 선택하면 서버가 높은 부하 또는 주파수 시간으로 서버가 속도가 느려지며, 예를 들어 Creation_at 및 Updated_at 및 Timestamps와 같은 열이 포함되어 있지 않기 때문에 쿼리가 필요하지 않기 때문에 테이블은 선택을 피할 수 없습니다.
 Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 사용하여 데이터베이스 생성 : 데이터베이스 서버에 연결하고 연결 매개 변수를 입력하십시오. 서버를 마우스 오른쪽 버튼으로 클릭하고 데이터베이스 생성을 선택하십시오. 새 데이터베이스의 이름과 지정된 문자 세트 및 Collation의 이름을 입력하십시오. 새 데이터베이스에 연결하고 객체 브라우저에서 테이블을 만듭니다. 테이블을 마우스 오른쪽 버튼으로 클릭하고 데이터 삽입을 선택하여 데이터를 삽입하십시오.
 MariaDB 용 Navicat에서 데이터베이스 비밀번호를 보는 방법은 무엇입니까?
Apr 08, 2025 pm 09:18 PM
MariaDB 용 Navicat에서 데이터베이스 비밀번호를 보는 방법은 무엇입니까?
Apr 08, 2025 pm 09:18 PM
MariaDB 용 Navicat은 암호가 암호화 된 양식으로 저장되므로 데이터베이스 비밀번호를 직접 볼 수 없습니다. 데이터베이스 보안을 보장하려면 비밀번호를 재설정하는 세 가지 방법이 있습니다. Navicat을 통해 비밀번호를 재설정하고 복잡한 비밀번호를 설정하십시오. 구성 파일을 봅니다 (권장되지 않음, 위험이 높음). 시스템 명령 줄 도구를 사용하십시오 (권장되지 않으면 명령 줄 도구에 능숙해야 함).
 MySQL을 보는 방법
Apr 08, 2025 pm 07:21 PM
MySQL을 보는 방법
Apr 08, 2025 pm 07:21 PM
다음 명령으로 MySQL 데이터베이스를보십시오. 서버에 연결하십시오. mysql -u username -p password run show database; 기존의 모든 데이터베이스를 가져 오려는 명령 데이터베이스 선택 : 데이터베이스 이름 사용; 보기 테이블 : 테이블 표시; 테이블 구조보기 : 테이블 이름을 설명합니다. 데이터보기 : 테이블 이름에서 *를 선택하십시오.
 MySQL에서 테이블을 복사하는 방법
Apr 08, 2025 pm 07:24 PM
MySQL에서 테이블을 복사하는 방법
Apr 08, 2025 pm 07:24 PM
MySQL에서 테이블을 복사하려면 새 테이블을 만들고, 데이터를 삽입하고, 외래 키 설정, 인덱스 복사, 트리거, 저장된 절차 및 기능이 필요합니다. 특정 단계에는 다음이 포함됩니다 : 동일한 구조를 가진 새 테이블 작성. 원래 테이블의 데이터를 새 테이블에 삽입하십시오. 동일한 외래 키 제약 조건을 설정하십시오 (원래 테이블에 하나가있는 경우). 동일한 색인을 만듭니다. 동일한 트리거를 만듭니다 (원래 테이블에 하나가있는 경우). 동일한 저장된 절차 또는 기능을 만듭니다 (원래 테이블이 사용되는 경우).
