

총계 계산 및 동점 값 계산과 같은 일반적인 작업은 집계 함수를 사용하여 구현할 수 있습니다.


참고:
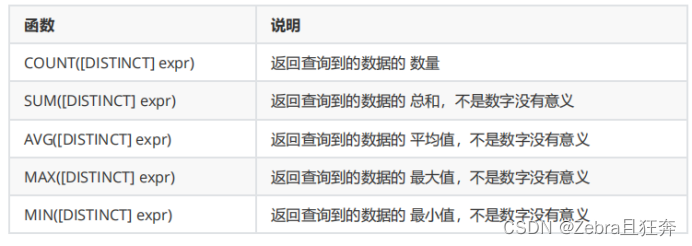
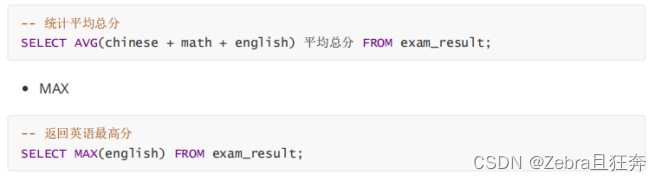
1.count: count(*), count(0), count(1)을 사용할 수 있습니다. 직설적으로 말하면 전체 테이블에서 1을 선택하는 것과 같습니다. 이유는 이 개수의 0과 1이 매개변수로 전달되기 때문입니다. 먼저 1을 선택한 다음 count

2.sum, max, min 및 avg 값을 계산합니다. 허용 *를 전달하려면 필드 또는 표현식을 전달해야 합니다.
3.avg는 합계와 함께 사용할 수 있으며 여러 집계 함수를 함께 사용할 수 있습니다. 2.GROUP BY 절
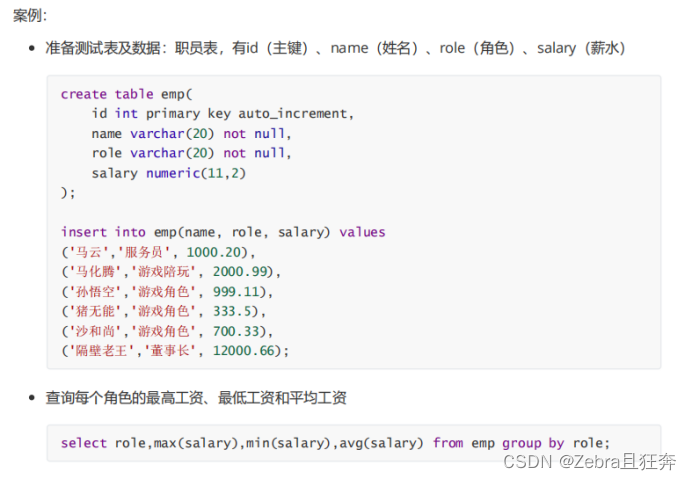
GROUP BY 절을 사용하여 지정합니다. 그룹 쿼리에 대한 특정 열입니다. 충족해야 할 사항: 그룹화 쿼리에 GROUP BY를 사용할 때 SELECT로 지정된 필드는 "그룹화 기준 필드"여야 하며, 다른 필드가 SELECT에 표시되려면 집계 함수에 포함되어야 합니다. 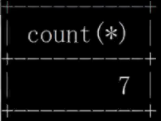
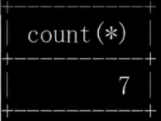 Select 뒤에 있는 집계 기능은 Group by가 그룹화를 완료한 후에 수행됩니다. Group by 문의 핵심은 집계 쿼리와 함께 자주 사용됩니다. by Select는 group by 다음에 있어야 합니다. 사용할 수 없는 항목은 집계 기능에만 나타날 수 있습니다. 그렇지 않으면 문제가 발생합니다.
Select 뒤에 있는 집계 기능은 Group by가 그룹화를 완료한 후에 수행됩니다. Group by 문의 핵심은 집계 쿼리와 함께 자주 사용됩니다. by Select는 group by 다음에 있어야 합니다. 사용할 수 없는 항목은 집계 기능에만 나타날 수 있습니다. 그렇지 않으면 문제가 발생합니다.
 GROUP BY Notes
GROUP BY Notes
 Limit은 항상 마지막에 실행됩니다
Limit은 항상 마지막에 실행됩니다
이후에 실행됩니다.

구문:

에서는 연결 조건과 필터링 결과 집합 조건의 차이를 구분하지 못할 수 있습니다. 두 번째 방법. 둘 중 하나를 사용할 수 있지만 후속 외부 조인에 대응하기 위해 첫 번째 조인에 우선순위를 부여합니다. 내부 조인은 구해진 데카르트 곱에 연결 조건을 부여하는 것과 같습니다
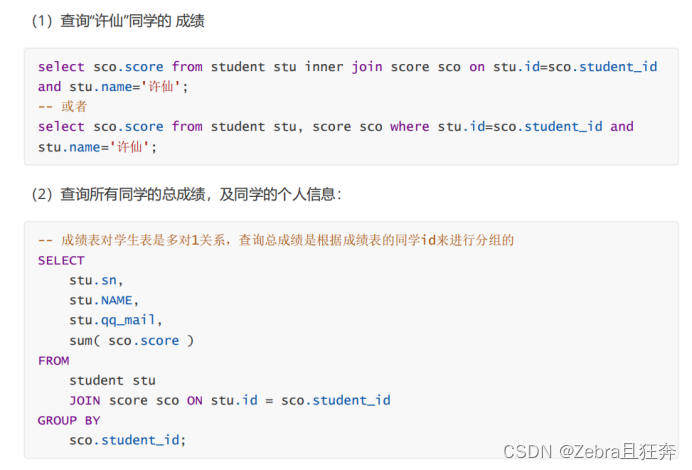
여기서 그룹이 없으면 다음과 같은 한 줄만 남게 되며 이는 모든 학생의 점수를 모두 합한 것과 같습니다. . 필요한 것은 각 학생의 총점이므로 먼저 학생 ID에 따라 그룹화해야 합니다.

외부 조인은 왼쪽 외부 조인과 오른쪽 외부 조인으로 구분됩니다. 왼쪽 외부 조인은 결합 쿼리를 수행할 때 왼쪽 테이블이 완전히 표시될 때의 연결 방법이고, 오른쪽 외부 조인은 결합 쿼리를 수행할 때 오른쪽 테이블이 완전히 표시될 때의 연결 방법입니다.
참고:
왼쪽 테이블의 데이터는 결합 조건(and를 포함한 on 뒤의 부분)에 따라 필터링 및 표시되지 않습니다. 나중에 where 및 기타 조건을 추가하세요.
오른쪽 테이블에 데이터가 있고 연결 조건에 맞지 않는 값이 있는 경우 오른쪽 테이블의 데이터는 null로 표시되고 왼쪽 테이블에는 모두 표시됩니다.
구문: (참고: On where도 올 수 있음)


동일한 쿼리 방법으로 이번에는 점수가 비어 있는 8번째 학생의 정보를 표시할 수 있습니다. 왼쪽 테이블의 모든 데이터, 즉 학생 테이블은 표시되며 접속 조건이 적용되지 않습니다. 표시됩니다, sco 테이블에는 "중국어를 공부하는 외국인" 학생이 없기 때문입니다. 3. 셀프 조인 셀프 조인은 쿼리를 위해 동일한 테이블에 자신을 연결하는 것을 의미합니다. 사용 시나리오: 동일한 테이블의 여러 행을 비교합니다.
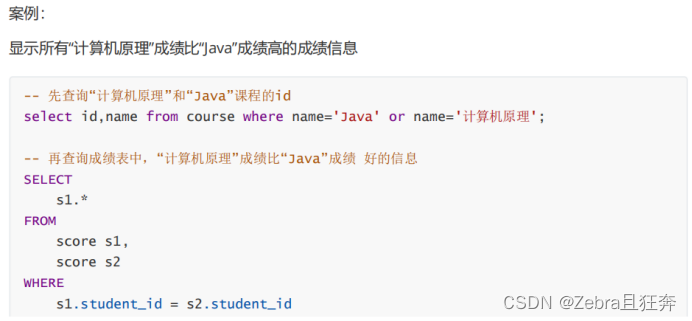 쿼리라고도 하며 동급생의 동급생을 "졸업하고 싶지 않음": (자체 조인)
쿼리라고도 하며 동급생의 동급생을 "졸업하고 싶지 않음": (자체 조인)

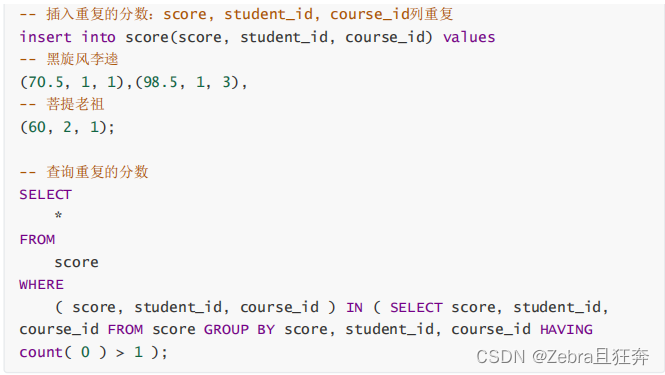
여기 group by는 병합하는 역할을 하지 않고 그룹화하는 역할을 합니다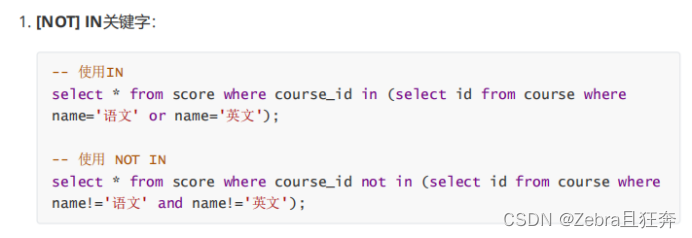
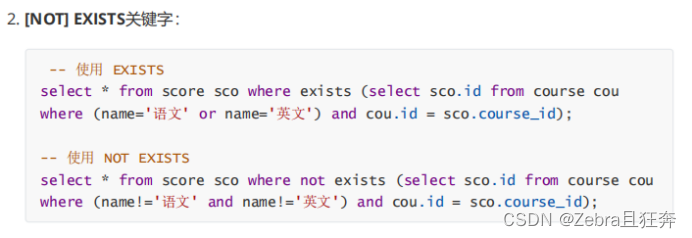 필드는 쿼리 전후의 결과 집합에서 일관적
필드는 쿼리 전후의 결과 집합에서 일관적
**여러 테이블을 연결할 수 없는 경우에도 동일한 필드의 데이터를 쿼리하려는 경우**Union이 or
union
사례: ID가 3보다 작거나 이름이 "English"인 강좌를 쿼리합니다.
이 연산자는 두 결과 집합의 합집합을 얻는 데 사용됩니다. 이 연산자를 사용하면 결과 집합의 중복 행이 제거되지 않습니다. (획득한 데이터가 완전히 동일한 경우 표시되며 중복은 제거되지 않습니다.)
사례: ID가 3 미만이거나 이름이 "Java"인 강좌를 쿼리합니다.

위 내용은 MySQL 집계 쿼리 및 통합 쿼리 작업 분석 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



