

ChatGPT(Chat Generative Pre-training Transformer)는 NLP(자연어 처리) 분야에 속하는 AI 모델입니다. 소위 자연어란 사람들이 일상생활에서 접하고 사용하는 영어, 중국어, 독일어 등을 말한다. 자연어 처리란 컴퓨터가 자연어를 이해하고 올바르게 작동하여 인간이 지정한 작업을 완료할 수 있도록 하는 것을 말합니다. NLP의 일반적인 작업에는 텍스트에서 키워드 추출, 텍스트 분류, 기계 번역 등이 포함됩니다.
NLP에는 또 다른 매우 어려운 작업이 있습니다. 일반적으로 챗봇이라고도 할 수 있는 대화 시스템입니다. 이것이 바로 ChatGPT가 수행하는 작업입니다.
ChatGPT 및 Turing Test
오랫동안 튜링 테스트는 학계에서 파악하기 힘든 정점으로 여겨져 왔습니다. 이 때문에 NLP는 인공지능의 보석이라고도 불린다. ChatGPT가 할 수 있는 작업은 채팅 로봇의 범위를 훨씬 뛰어넘어 사용자 지시에 따라 기사를 작성하고, 기술적인 질문에 답하고, 수학 문제를 풀고, 외국어 번역, 단어 게임 등을 할 수 있습니다. 따라서 어떤 면에서는 ChatGPT가 최고의 보석을 차지했습니다.
ChatGPT의 모델링 양식
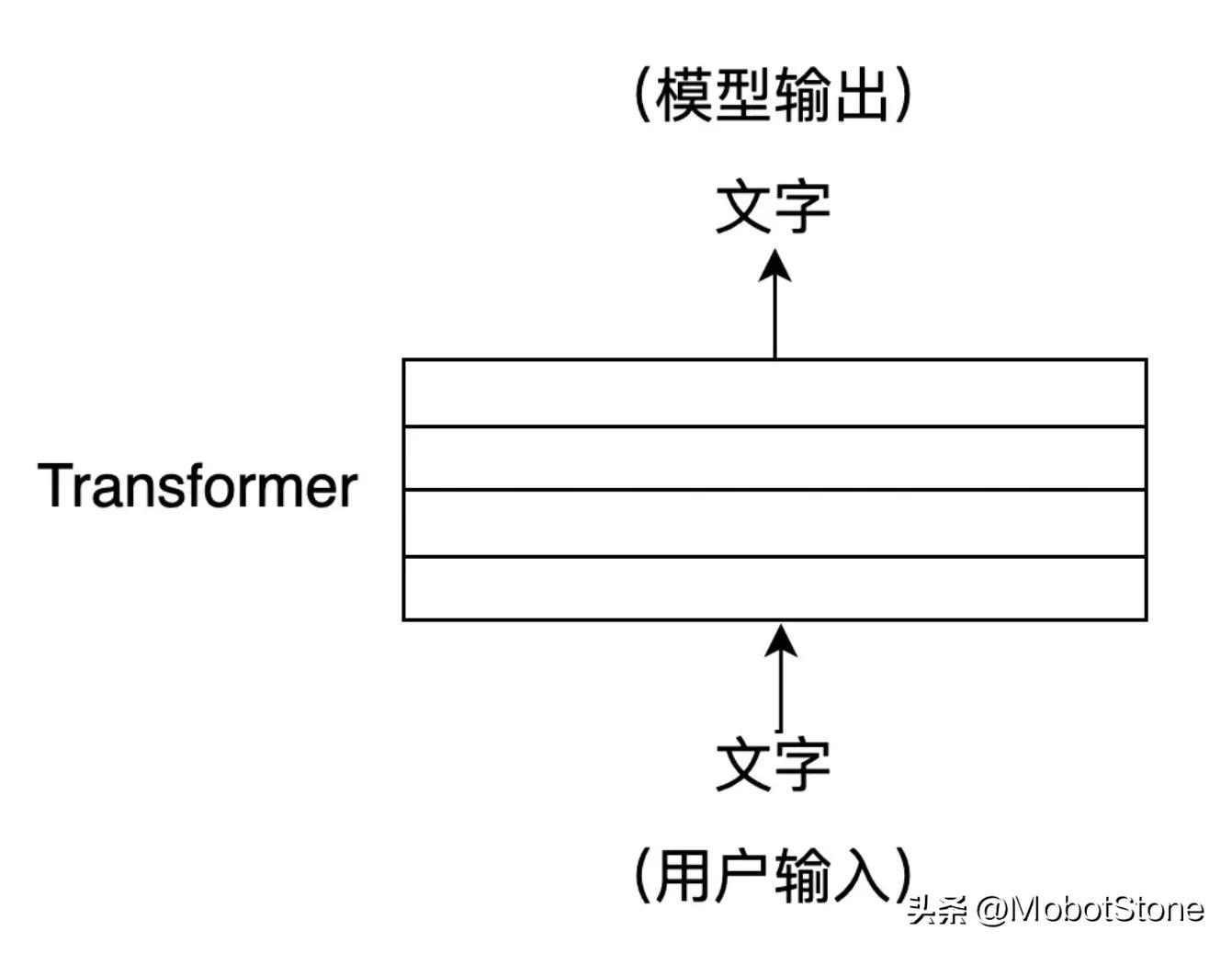
 그 중 사용자의 입력과 모델의 출력이 모두
그 중 사용자의 입력과 모델의 출력이 모두
형식입니다. 하나의 사용자 입력과 모델의 해당 출력 하나를 대화라고 합니다. ChatGPT 모델을 다음 프로세스로 추상화할 수 있습니다.
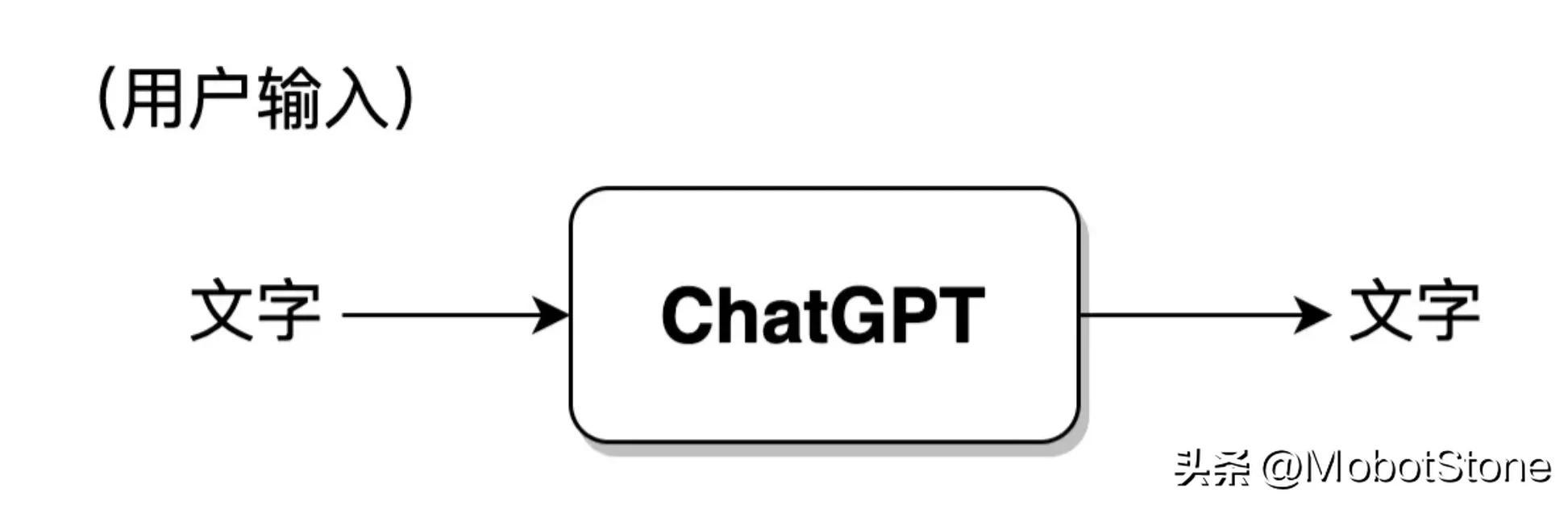 또한 ChatGPT는 사용자의 지속적인 질문, 즉 여러 라운드의 대화에 답할 수도 있으며 여러 라운드의 대화 간에 정보 상관 관계가 있습니다. 구체적인 형식도 매우 간단합니다. 사용자가 두 번째로 입력하면 시스템은 기본적으로 ChatGPT가 마지막 대화의 정보를 참조할 수 있도록 첫 번째 입력 및 출력 정보를 결합합니다.
또한 ChatGPT는 사용자의 지속적인 질문, 즉 여러 라운드의 대화에 답할 수도 있으며 여러 라운드의 대화 간에 정보 상관 관계가 있습니다. 구체적인 형식도 매우 간단합니다. 사용자가 두 번째로 입력하면 시스템은 기본적으로 ChatGPT가 마지막 대화의 정보를 참조할 수 있도록 첫 번째 입력 및 출력 정보를 결합합니다.
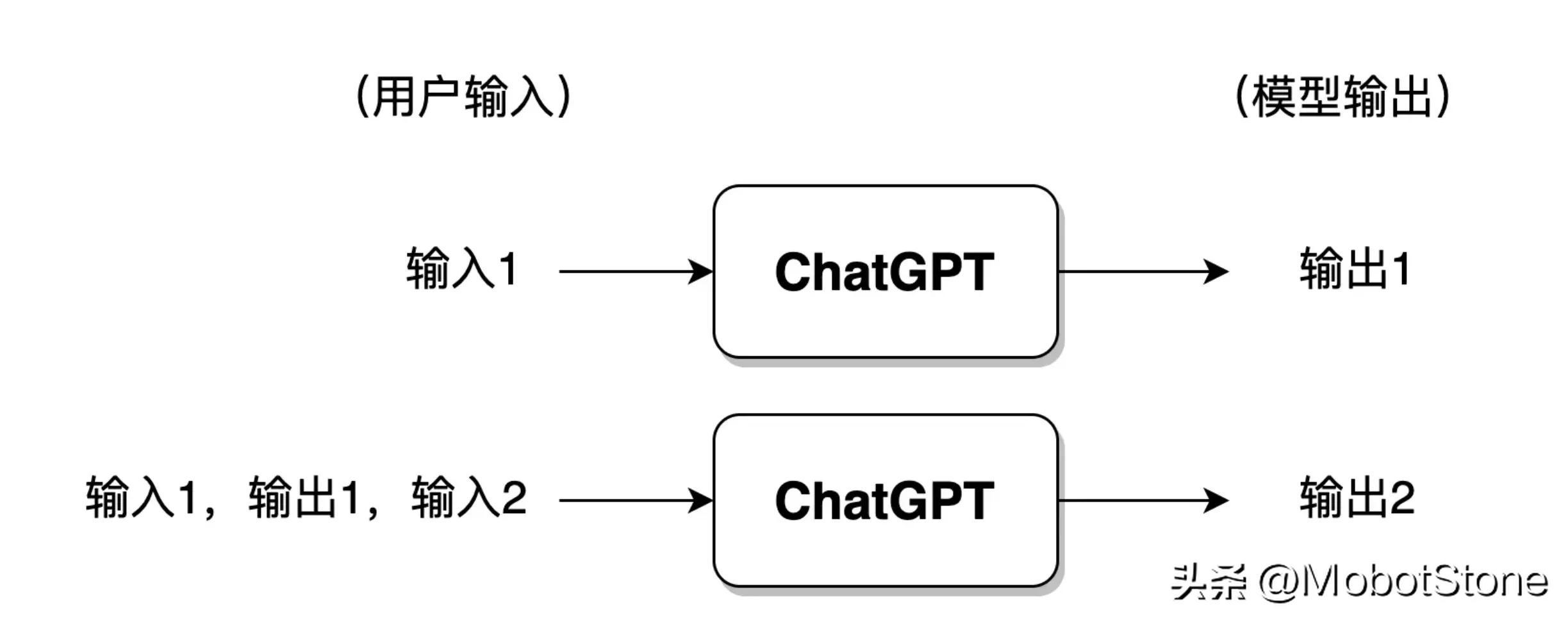 사용자가 ChatGPT와 너무 많은 대화를 나눈 경우 일반적으로 모델은 가장 최근 대화 라운드의 정보만 유지하며 이전 대화 정보는 잊어버립니다.
사용자가 ChatGPT와 너무 많은 대화를 나눈 경우 일반적으로 모델은 가장 최근 대화 라운드의 정보만 유지하며 이전 대화 정보는 잊어버립니다.
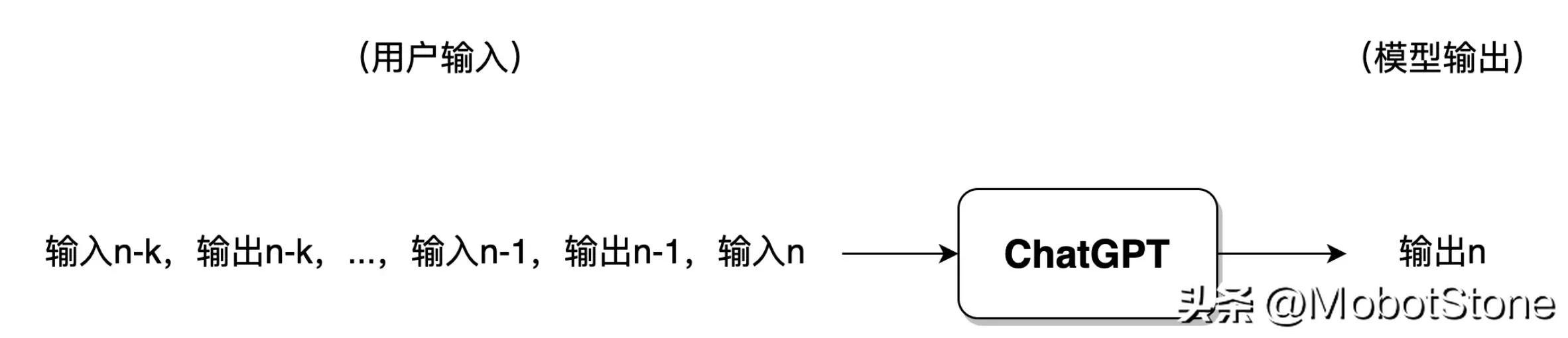 ChatGPT가 사용자의 질문 입력을 받은 후 출력 텍스트가 단숨에 직접 생성되는 것이 아니라 단어 단위로 생성됩니다. 아래 그림과 같이.
ChatGPT가 사용자의 질문 입력을 받은 후 출력 텍스트가 단숨에 직접 생성되는 것이 아니라 단어 단위로 생성됩니다. 아래 그림과 같이.
사용자가 "사과나 바나나를 좋아합니까?"라는 질문을 입력하면 ChatGPT가 데이터를 수신한 후 먼저 "I"라는 단어를 생성한 다음 모델은 사용자의 질문과 생성된 단어를 결합합니다. "나" 단어는 계속해서 다음 단어 "안녕"을 생성합니다. 그리고 "I like apples"라는 완전한 문장이 생성될 때까지 계속됩니다.
ChatGPT의 모델링 형식이 앞서 소개되었습니다. ChatGPT 모델을 구현하라는 요청을 받았다면 어떤 아이디어와 방법이 있을까요? 실제로 규칙을 기반으로 한 NLP와 통계를 기반으로 한 NLP의 두 가지 전략이 있습니다. ChatGPT가 시작된 이후 NLP 분야는 강화학습, 즉 강화학습 기반의 NLP 시대로 진입했습니다.
규칙 기반 NLP는 자연어를 처리하기 위해 수동으로 작성된 규칙을 사용하는 것을 말합니다. 이러한 규칙은 일반적으로 문법, 의미론 및 화용론에 대한 지식을 기반으로 하며 자연어를 구문 분석하고 생성하는 데 사용될 수 있습니다. 예를 들어, 다음 규칙에 따라 대화 시스템을 설계할 수 있습니다.
규칙 1: 모델이 사용자의 질문을 받으면 질문에서 "?"라는 단어를 제거하고 "."
규칙 2: "you"를 "I"로 바꾸고 "I"를 "you"로 바꾸세요
이로부터 이러한 규칙을 기반으로 대화 모델을 만들고 대화 모드를 시작할 수 있습니다.
사용자: 안녕하세요. 모델: 안녕하세요. 사용자: ChatGPT이신가요? 모델: 네, 저는 ChatGPT입니다. 사용자: 너겟 커뮤니티를 좋아하시나요? 모델: 저는 Nuggets 커뮤니티를 좋아합니다. 사용자: jionlp 툴킷을 사용해 본 적이 있나요? 모델: jionlp 툴킷을 사용했습니다.
위는 규칙 기반 대화 시스템의 매우 조잡한 예입니다. 나는 독자들이 존재하는 문제를 쉽게 찾아낼 수 있다고 믿는다. 사용자 문제가 너무 복잡하면 어떻게 되나요? 질문에 물음표가 없으면 어떻게 되나요? 위의 특별한 상황을 다루기 위해서는 다양한 규칙을 지속적으로 작성해야 합니다. 이는 규칙에 기반한 몇 가지 명백한 단점이 있음을 보여줍니다.
초기 NLP가 개발된 방식은 다음과 같습니다. 규칙을 기반으로 모델 시스템을 구축하는 것입니다. 초기에는 일반적으로 상징주의라고도 불렸다.
통계 기반 NLP는 기계 학습 알고리즘을 사용하여 수많은 말뭉치에서 자연어의 규칙적인 특징을 학습합니다. 초기에는 연결주의라고도 불렸습니다. 이 방법은 규칙을 수동으로 작성할 필요가 없으며, 규칙은 주로 언어의 통계적 특성을 학습하여 모델에 암시됩니다. 즉, 규칙 기반 방법에서는 규칙이 명시적이고 수동으로 작성되지만 통계 기반 방법에서는 규칙이 보이지 않고 모델 매개변수에 암시적이며 데이터를 기반으로 모델에 의해 훈련됩니다.
이러한 모델은 최근 몇 년 동안 빠르게 발전했으며 ChatGPT도 그중 하나입니다. 또한 모양과 구조가 다른 다양한 모델이 있지만 기본 원리는 동일합니다. 그들의 처리 방법은 주로 다음과 같습니다.
훈련 모델 => 훈련된 모델을 사용하여 작업
ChatGPT에서는 통계 기반 NLP 모델 학습을 완료하기 위해 사전 훈련(Pre-training) 기술이 주로 사용됩니다. 초기 NLP 분야의 사전 학습은 ELMO 모델(Embedding from Language Models)에 의해 처음 도입되었으며, 이 방법은 ChatGPT 등 다양한 심층 신경망 모델에서 널리 채택되었습니다.
핵심은 대규모 원본 코퍼스를 기반으로 언어 모델을 학습하는 것이며, 이 모델은 특정 작업의 해결 방법을 직접 학습하는 것이 아니라 문법, 형태론, 화용론, 상식, 지식 등에 이르는 정보를 학습합니다. . 이를 언어 모델에 통합합니다. 직관적으로는 지식을 실제 문제 해결에 적용하기보다는 지식 기억에 가깝습니다.
사전 훈련에는 많은 이점이 있으며 거의 모든 NLP 모델 훈련에 필요한 단계가 되었습니다. 이에 대해서는 다음 장에서 자세히 설명하겠습니다.
통계 기반 방법은 규칙 기반 방법보다 훨씬 더 널리 사용됩니다. 그러나 가장 큰 단점은 블랙박스 불확실성, 즉 규칙이 매개변수에 보이지 않고 암시적이라는 점입니다. 예를 들어, ChatGPT는 모호하고 이해할 수 없는 결과를 제공하기도 합니다. 모델이 왜 그러한 답변을 했는지 결과로는 판단할 방법이 없습니다.

ChatGPT 모델은 통계 기반이지만 새로운 방법인 RLHF(Reinforcement Learning with Human Feedback)를 사용하여 우수한 결과를 달성하며 NLP 발전을 새로운 단계로 끌어올립니다.
몇 년 전 Alpha GO가 Ke Jie를 이겼습니다. 이는 강화학습이 적절한 조건에서 이루어지면 인간을 완전히 패배시키고 완벽의 한계에 접근할 수 있음을 거의 증명할 수 있습니다. 현재 우리는 여전히 약한 인공지능 시대에 살고 있지만 바둑 분야에 국한됩니다. 알파GO는 강한 인공지능이며 그 핵심은 강화학습에 있습니다.
일명 강화학습은 에이전트(에이전트, NLP에서는 주로 심층신경망 모델, 즉 ChatGPT 모델을 가리킨다)가 환경과의 상호작용을 통해 최적의 결정을 내리는 방법을 학습하도록 하는 것을 목표로 하는 기계학습 방법입니다. .
이 방법은 개(에이전트)가 휘파람 소리(환경)를 듣고 식사(학습 목표)를 하도록 훈련시키는 것과 같습니다.
주인이 휘파람을 불면 강아지는 보상으로 음식을 받지만, 주인이 휘파람을 불지 않으면 강아지는 굶어 죽을 수밖에 없습니다. 반복적으로 먹고 배고픔을 겪음으로써 강아지는 상응하는 조건 반사를 확립할 수 있으며, 이는 실제로 강화 학습을 완료합니다.
NLP 분야의 환경은 훨씬 더 복잡합니다. NLP 모델의 환경은 실제 인간의 언어 환경이 아니라 인위적으로 구축된 언어 환경 모델이다. 따라서 여기서는 인위적인 피드백을 통한 강화 학습에 중점을 둡니다.

통계를 기반으로 모델은 가장 큰 자유도로 훈련 데이터 세트에 적합할 수 있으며 강화 학습은 모델에 더 큰 자유도를 제공하여 모델이 독립적으로 학습하고 기존의 한계를 뛰어넘을 수 있도록 합니다. 데이터 세트. ChatGPT 모델은 통계 학습 방법과 강화 학습 방법을 통합합니다. 모델 훈련 과정은 아래 그림에 나와 있습니다.
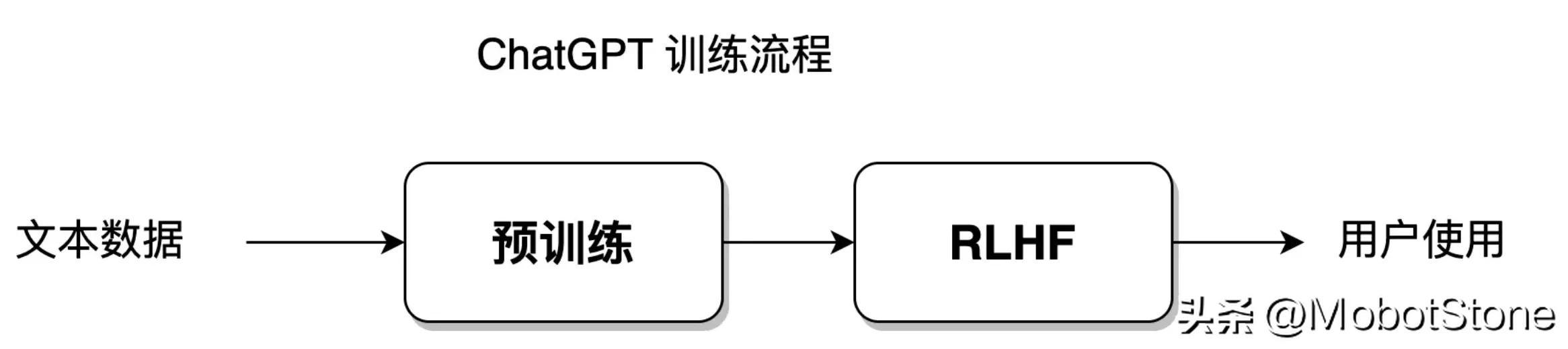
훈련 과정의 이 부분은 섹션 8-11에서 설명됩니다.
사실 규칙 기반, 통계 기반, 강화 학습 기반의 세 가지 방법은 단순한 자연어 처리 수단이 아니라 하나의 아이디어입니다. 특정 문제를 해결하는 알고리즘 모델은 종종 이 세 가지 솔루션을 융합한 결과입니다.
컴퓨터를 아이에 비유한다면 자연어 처리는 인간이 아이의 성장을 교육하는 것과 같습니다.
규칙 기반 접근 방식은 부모가 자녀를 100% 통제하는 것과 같으며, 하루 학습 시간을 설정하고 자녀에게 모든 질문을 가르치는 등 자녀가 자신의 지시와 규칙에 따라 행동하도록 요구합니다. 과정 전반에 걸쳐 실습 교육이 강조되며, 주도권과 초점은 부모에게 있습니다. NLP의 경우 전체 프로세스의 주도권과 초점은 언어 규칙을 작성하는 프로그래머와 연구원에게 있습니다.
통계 기반 방법은 부모가 자녀에게 학습 방법만 알려주고 각 특정 질문을 가르치지 않는 것과 같습니다. NLP의 경우 학습의 초점은 신경망 모델에 있지만 이니셔티브는 여전히 알고리즘 엔지니어에 의해 제어됩니다.
강화 학습 방법을 기반으로 하면 부모는 자녀에게 교육 목표만 설정하는 것과 같습니다. 예를 들어 자녀가 시험에서 90점을 달성하도록 요구하지만 자녀가 어떻게 학습하는지에는 전혀 관심이 없습니다. 자율 학습에 있어서 아이들은 매우 높은 자유도와 주도성을 가지고 있습니다. 부모는 최종 결과에 대해서만 상을 주거나 처벌할 뿐 전체 교육 과정에 참여하지는 않습니다. NLP의 경우 전체 프로세스의 초점과 주도권은 모델 자체에 있습니다.
NLP의 발전은 점차 통계 기반 방법에 가까워지고 있으며 마침내 강화 학습 기반 방법이 완전한 승리를 달성했습니다. 승리의 상징은 ChatGPT의 출현입니다. 점차 쇠퇴하여 보조가공방식으로 축소되었습니다. ChatGPT 모델의 개발은 처음부터 모델이 스스로 학습하도록 하는 방향으로 변함없이 진행되어 왔습니다.
이전 서문에서는 독자의 이해를 돕기 위해 ChatGPT 모델의 구체적인 내부 구조는 언급하지 않았습니다.
ChatGPT는 내부 구조가 여러 레이어의 Transformer로 구성되어 있는 대규모 신경망 구조입니다. 2018년부터 NLP 분야의 공통 표준 모델 구조가 되었으며, Transformer는 거의 모든 NLP 모델에서 찾아볼 수 있습니다.
ChatGPT가 집이라면 Transformer는 ChatGPT를 만드는 벽돌입니다.
Transformer의 핵심은 셀프 어텐션 메커니즘(Self-Attention)입니다. 이를 통해 모델은 입력 텍스트 시퀀스를 처리할 때 현재 위치 문자와 관련된 다른 위치 문자에 자동으로 주의를 기울일 수 있습니다. self-attention 메커니즘은 입력 시퀀스의 각 위치를 벡터로 표현할 수 있으며, 이러한 벡터는 동시에 계산에 참여할 수 있으므로 효율적인 병렬 컴퓨팅을 달성할 수 있습니다. 예를 들어보세요:
기계 번역에서 "나는 좋은 학생입니다"라는 영어 문장을 중국어로 번역할 때 전통적인 기계 번역 모델은 이를 "나는 좋은 학생입니다"로 번역할 수 있지만 이 번역 결과는 그렇지 않을 수 있습니다. 충분히 정확합니다. 영어의 관사 "a"는 중국어로 번역할 때 문맥에 따라 결정되어야 합니다.
번역에 Transformer 모델을 사용하면 "나는 좋은 학생입니다"와 같은 더 정확한 번역 결과를 얻을 수 있습니다.
Transformer는 영어 문장에서 장거리에 걸쳐 있는 단어 간의 관계를 더 잘 포착하고 텍스트 컨텍스트에 대한 오랜 의존성을 해결할 수 있기 때문입니다. Self-Attention 메커니즘은 5-6절에서 소개하고, Transformer의 세부 구조는 6-7절에서 소개하겠습니다.
위 내용은 누구나 ChatGPT 1장: ChatGPT 및 자연어 처리를 이해합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



