

실제 프로덕션 환경에서 MySQL 데이터베이스의 읽기 및 쓰기가 모두 데이터베이스 서버에서 수행된다면 보안, 고가용성 또는 높은 동시성 측면에서 실제 요구 사항을 충족할 수 없습니다. 마스터-슬레이브 복제를 통해 데이터를 동기화한 후 읽기-쓰기 분리를 통해 데이터베이스의 동시 로드 용량을 향상시킵니다. 1. 마스터-슬레이브 복제의 개념
메인 라이브러리(마스터)는 외부
데이터 추가, 삭제, 수정 및 조회 서비스를 제공합니다. 마스터 라이브러리의 데이터와 관련된 수정 사항은 binlog에 기록됩니다.슬레이브 라이브러리(슬레이브)는 데이터 동기화 및 데이터에 사용됩니다. 백업, 메인 라이브러리의 binlog는 메인 라이브러리 및 데이터, 권한, 테이블 구조와 관련된 수정 사항을 슬레이브 라이브러리에 동기화합니다. 이는 메인 라이브러리에서 수행된 모든 수정 사항이 통과되고 반영되는 것과 동일합니다. 마스터-슬레이브 복제 메커니즘을 통해 슬레이브 라이브러리에 있습니다. 마스터-슬레이브 복제의 이점:
데이터 백업, MySQL 미들웨어 mycat을 통해 핫 백업도 만들 수 있고, 재해 허용을 달성할 수 있으며 재해 복구도 가능합니다. 반영mycat,可以实现容灾,容灾也体现了高可用。
容灾:如果主库挂了,由中间件代理mycat自动把服务的请求映射到从库,由从库继续对外提供服务,体现出了高可用性(后端的服务允许一定的异常发生,但是后端的架构服务要可以容错,把这些异常的错误处理掉,并对外重新提供正常的服务)
读写分离是基于主从复制来实现的。在实际的应用环境中,肯定是读操作多,就像我们在电商平台上去购买东西,可能看了100个也就买了一两个。所以读操作永远比写这种更新操作多很多。所以我们基于主从复制的读写分离配置,就是让一个主库专门用来做数据的修改,写的时候专门在主库上写,主库通过主从复制把数据的更改通过binlog同步到从库上去,那么其他的客户端查询的请求都会最终映射到从库上去,而我们一个主库带上两三个从库,主库专门用来做数据的更新(写操作),从库专门用来做读操作这样一来可以很好的分摊读写的压力,不用全部都集中在主库上,对于后端服务的并发处理能力有很大的提高,另外就是它的高可用容灾,当主库挂了以后,可以把指定的从库变成主库。
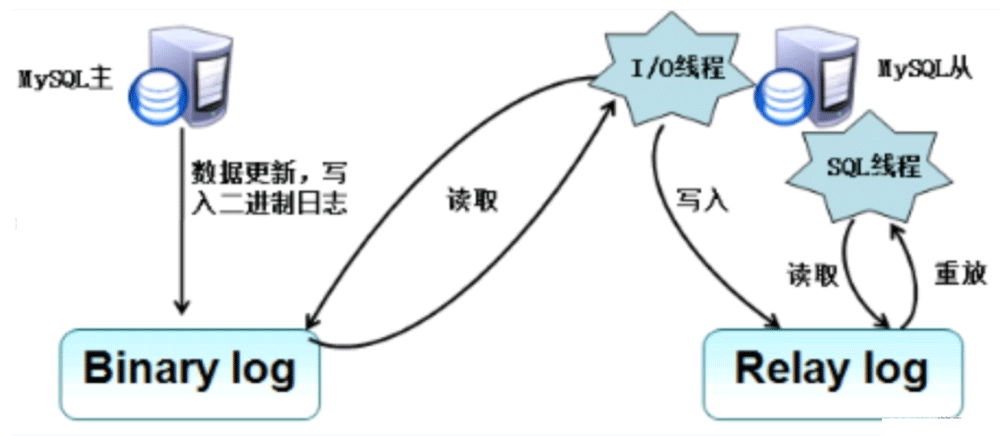
上图中的binlog,即使我们没有主从复制,也是会写binlog的,只不过主从复制是通过binlog来实现的。
主库master服务器创建一个binlog转储线程,将二进制日志内容发送到从服务器
从库里面专门有一个I/O线程专门读取接收主库发送的内容,它会把主库里面发过来的binlog内容接收并写到一个relay log 고가용성 .
재해 복구: 메인 데이터베이스가 다운되면 미들웨어 에이전트 mycat이 자동으로 서비스 요청을 슬레이브 데이터베이스에 매핑하고, 슬레이브 데이터베이스는 높은 가용성을 반영하여 계속해서 외부 세계에 서비스를 제공합니다
마스터-슬레이브 복제를 기반으로 읽기-쓰기 분리가 구현됩니다. 실제 애플리케이션 환경에서는 읽기 작업이 많을 텐데요, 마치 전자상거래 플랫폼에서 물건을 살 때처럼 100개의 상품을 보고 한두 개만 구매하면 됩니다. 따라서 항상 쓰기 업데이트 작업보다 읽기 작업이 더 많습니다. 따라서 마스터-슬레이브 복제를 기반으로 한 읽기-쓰기 분리 구성은 마스터 데이터베이스가 데이터 수정 전용임을 의미합니다. 쓰기 시 마스터 데이터베이스는 마스터-슬레이브를 통해 데이터 변경 사항을 슬레이브에 동기화합니다. binlog 라이브러리를 통한 복제 후 다른 클라이언트 쿼리 요청은 결국 슬레이브 라이브러리에 매핑되며, 두 개 또는 세 개의 슬레이브 라이브러리가 있는 하나의 메인 라이브러리가 특별히 데이터(쓰기 작업)를 업데이트하는 데 사용됩니다. 라이브러리는 데이터 업데이트(쓰기 작업)에 특별히 사용되며 읽기 및 쓰기 작업의 부담을 분산할 수 있어 기본 데이터베이스에 집중할 필요가 없습니다. 또한, 고가용성 및 재해 복구 기능을 갖추고 있으며, 메인 라이브러리가 다운되면 지정된 슬레이브 라이브러리를 메인 라이브러리로 전환할 수 있습니다. 위 그림 binlog에서는 master-slave 복제가 없어도 binlog는 계속 기록되지만, master-slave 복제는 binlog를 통해 구현됩니다. 3. 메인 라이브러리와 슬레이브 라이브러리
2. 슬레이브 라이브러리
가 있습니다. 라이브러리를 작성하여 relay log에 기록합니다. 릴레이 로그는 버퍼와 동일하므로 마스터는 다음 이벤트를 보내기 전에 슬레이브 실행이 완료될 때까지 기다릴 필요가 없습니다. 메인 라이브러리에서 binlog 내용을 읽어서 직접 실행하는 대신, 직접 실행의 단점은 메인 라이브러리에 binlog 내용이 많아 슬레이브 라이브러리에서 받은 binlog 내용의 실행이 매우 느릴 수 있다는 점, 결과적으로 슬레이브 라이브러리의 업데이트로 인해 데이터와 기본 데이터베이스 사이의 간격이 점점 넓어집니다. 데이터 복제가 지연될 수 있습니다.
읽는 데 전념하는 SQL 스레드도 시작하므로
모든 SQL은 한 번 실행🎜하여 🎜슬레이브 라이브러리의 내용과 내용을 실현합니다. 🎜🎜🎜🎜🎜 4. 마스터-슬레이브 복제 프로세스 🎜🎜🎜마스터-슬레이브 복제 프로세스: 🎜로그 2개(binlog 바이너리 로그 및 릴레이 로그 로그) 및 스레드 3개(마스터 스레드 1개 및 스레드 2개) 노예)). 🎜🎜🎜🎜메인 라이브러리의 업데이트 작업은 🎜binlog 바이너리 로그🎜에 기록됩니다. (메인 라이브러리는 binlog 스위치를 켜야 합니다.) 🎜🎜🎜🎜마스터 서버는 🎜binlog 덤프 스레드🎜를 생성하고 바이너리를 보냅니다. 슬레이브 서버에 콘텐츠 로그🎜 슬레이브 시스템이 START SLAVE 명령을 실행하면 슬레이브 서버에 START SLAVE命令会在从服务器创建一个IO线程,接收master的binary log复制到其中继日志(处于内存中,读写快)。 首先slave开始一个工作线程(I/O线程),I/O线程会主动连接master ,然后主库会开启dump线程,dump线程从master的binlog中读取事件并发送给slave的I/O线程,如果dump线程已经跟上master(主库上的dump线程已经把binlog的内容发完了,而且主库上binlog没有产生更多的内容),dump线程会睡眠并等待binlog产生新的事件,slave的I/O线程接收的事件写入中继日志
slave的SQL线程处理该过程的最后一步,SQL线程从relay log中读取事件,并执行其中的事件更新slave的数据,使其与master的数据同步。只要SQL线程与I/O线程保持一致,中继日志通常会位于os缓存中,所以中继日志的开销很小
linux上的centos作为主库win10上的mysql server作为从库来演示:
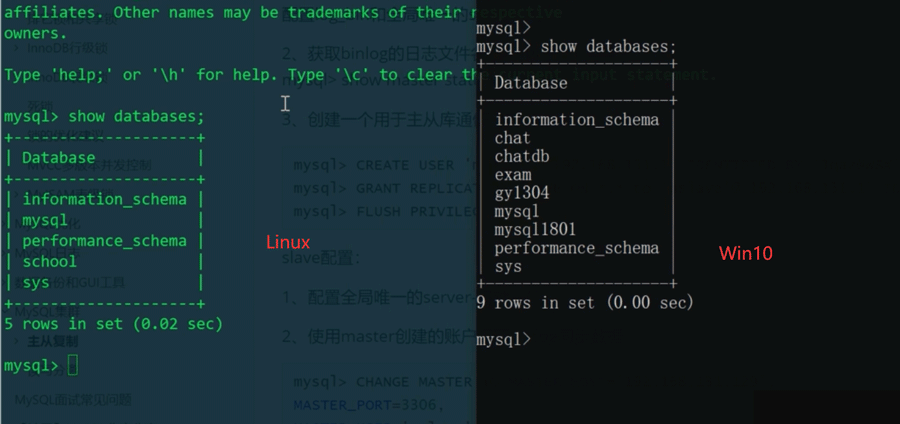
主从复制是单向同步,master的更改往slave同步。在设置主从复制时,主从库之间的数据可能不同。一旦配置完成,主库的所有更改将会同步到从库。
master创建mytest数据库:
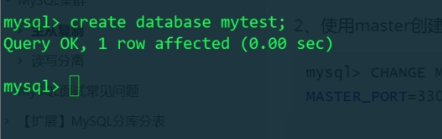
查看slave,发现mytest同步过来了:
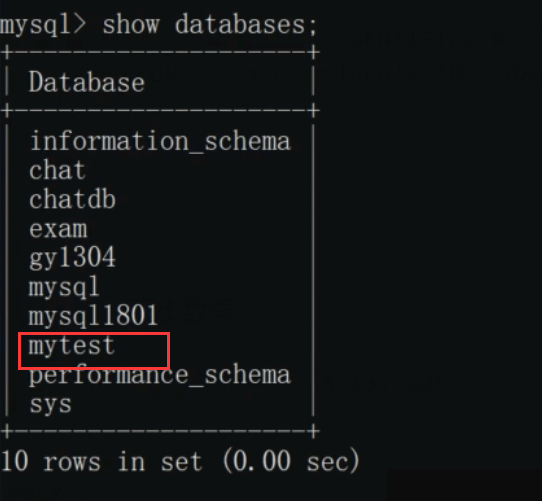
master创建了user表,slave也同步了user表:


现在linux端的MySQL(master)删除mytest库
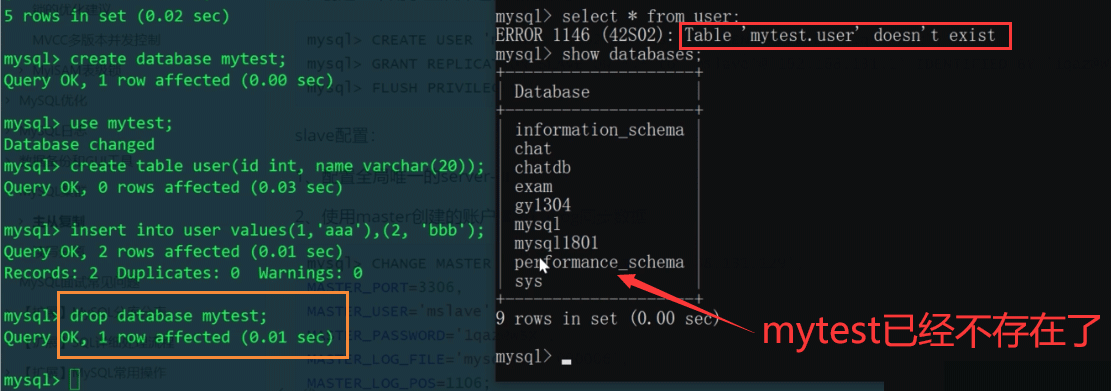
此时slave的mytest也不存在了
show processlistIO 스레드
dump 스레드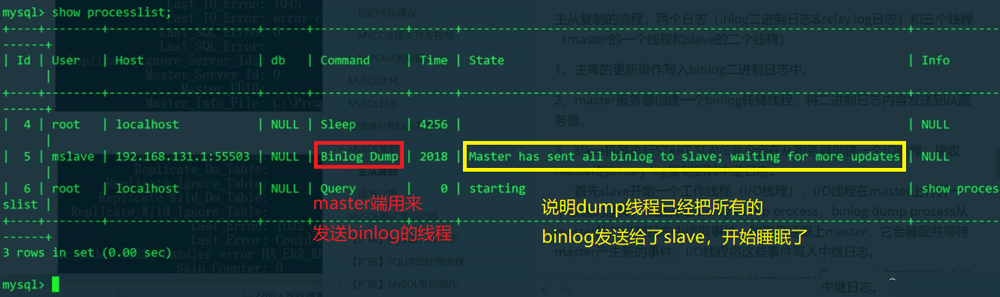 를 시작하고 마스터의 binlog에서 이벤트를 보냅니다. 덤프 스레드가 마스터를 따라잡은 경우(메인 라이브러리의 덤프 스레드가 binlog의 콘텐츠 전송을 완료했고 메인 라이브러리의 binlog가 더 이상 콘텐츠를 생성하지 않은 경우) , 덤프 스레드는 휴면 상태가 되며 binlog가 새 이벤트를 생성할 때까지 기다립니다. 슬레이브 I/O 스레드에서 수신한 이벤트는 릴레이 로그
를 시작하고 마스터의 binlog에서 이벤트를 보냅니다. 덤프 스레드가 마스터를 따라잡은 경우(메인 라이브러리의 덤프 스레드가 binlog의 콘텐츠 전송을 완료했고 메인 라이브러리의 binlog가 더 이상 콘텐츠를 생성하지 않은 경우) , 덤프 스레드는 휴면 상태가 되며 binlog가 새 이벤트를 생성할 때까지 기다립니다. 슬레이브 I/O 스레드에서 수신한 이벤트는 릴레이 로그
슬레이브의
SQL 스레드가 프로세스의 마지막 단계를 처리합니다. SQL 스레드는 릴레이 로그에서 이벤트를 읽고 이벤트를 실행하여 슬레이브의 데이터를 마스터의 데이터와 동기화합니다. SQL 스레드가 I/O 스레드와 일치하는 한 릴레이 로그는 일반적으로 os 캐시에 위치하므로 릴레이 로그의 오버헤드는 매우 작습니다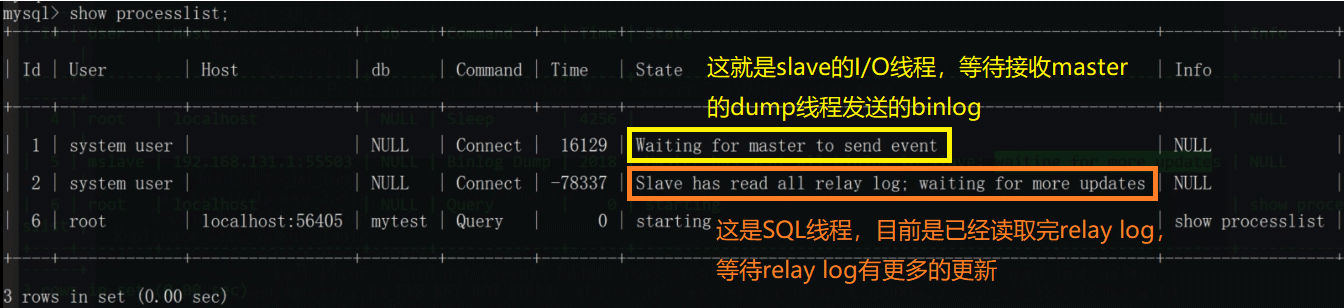
🎜🎜마스터-슬레이브 복제는 단방향 동기화이며 마스터에서 변경 사항이 발생합니다. 슬레이브와 동기화됩니다. 마스터-슬레이브 복제를 설정할 때 마스터 데이터베이스와 슬레이브 데이터베이스 간의 데이터가 다를 수 있습니다. 구성이 완료되면 마스터 데이터베이스의 모든 변경 사항이 슬레이브 데이터베이스에 동기화됩니다. 🎜🎜🎜master는 mytest 데이터베이스를 생성합니다: 🎜🎜🎜🎜🎜🎜슬레이브를 확인하고 mytest가 동기화되었는지 확인하세요. 🎜🎜🎜 🎜🎜🎜마스터가 사용자 테이블을 생성했고 슬레이브도 사용자 테이블을 동기화했습니다. 🎜🎜🎜
🎜🎜🎜마스터가 사용자 테이블을 생성했고 슬레이브도 사용자 테이블을 동기화했습니다. 🎜🎜🎜 🎜🎜
🎜🎜 🎜🎜🎜이제 Linux 측 MySQL(마스터)에서는 mytest 라이브러리를 삭제합니다🎜🎜 🎜
🎜🎜🎜이제 Linux 측 MySQL(마스터)에서는 mytest 라이브러리를 삭제합니다🎜🎜 🎜 🎜🎜🎜 현재 슬레이브의 mytest는 더 이상 존재하지 않습니다🎜🎜🎜
🎜🎜🎜 현재 슬레이브의 mytest는 더 이상 존재하지 않습니다🎜🎜🎜show processlist code>현재 마스터 환경에서 작업 중인 스레드를 볼 수 있습니다🎜🎜🎜🎜🎜🎜현재 환경에서 작업 중인 스레드를 볼 수 있습니다. 노예🎜🎜🎜🎜🎜위 내용은 MySQL의 마스터-슬레이브 복제 원칙은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



