

Redis의 기본 지식 포인트는 무엇입니까?

1. Redis란 무엇입니까
먼저 Redis 공식 웹사이트의 소개를 살펴보겠습니다.
Redis는 오픈 소스(BSD 라이선스), 메모리 내 데이터 구조 저장소로 데이터베이스, 캐시로 사용됩니다. 메시지 브로커는 문자열, 해시, 목록, 세트, 범위 쿼리가 포함된 정렬된 세트, 비트맵, 하이퍼로그 로그, 반경 쿼리 및 스트림이 포함된 지리 공간 인덱스를 지원합니다. Redis에는 복제, Lua 스크립팅, LRU 제거, 트랜잭션이 내장되어 있습니다. 다양한 수준의 온디스크 지속성을 제공하며 Redis Sentinel과 Redis Cluster를 통한 자동 파티셔닝을 통해 고가용성을 제공합니다.
간단히 말하면 Redis는 ANSI C 언어로 작성된 오픈 소스이며 BSD 프로토콜을 준수하고 네트워크를 지원하며 메모리 기반 및 지속성 로그 유형과 Key-Value 데이터베이스를 갖추고 있으며 매우 강력한 기능으로 다양한 데이터 유형을 제공합니다.
2. Redis의 아버지
Redis의 아버지는 이탈리아 시칠리아 출신의 프로그래머인 Salvatore Sanfilippo입니다. 그에게 관심이 있다면 그의 블로그를 방문하거나 그의 GitHub를 팔로우하세요.
3. Redis의 장점은 무엇인가요?
속도: Redis는 메모리를 사용하여 데이터 세트를 저장하고 한 번에 여러 명령을 보낼 수 있는 파이프라이닝 명령을 지원합니다.
지속성: 메모리의 데이터를 디스크에 저장할 수 있으며 다시 시작할 때 다시 로드할 수 있습니다.
원자성: 모든 작업은 원자성이며 트랜잭션이 지원됩니다.
풍부한 데이터 구조: 대부분의 사용 요구 사항을 충족하기 위해 문자열, 목록, 해시, 세트 및 순서 세트를 지원합니다.
여러 언어 지원: Redis는 C, C++, C#, Go, Java, JavaScript, PHP 등과 같은 다양한 언어를 지원합니다.
다양한 기능: Redis는 게시/구독, 알림, 키 만료 및 기타 기능도 지원합니다.
4. Redis는 무엇을 할 수 있나요
Redis는 데이터를 빠르게 교환하기 때문에 자주 검색해야 하는 일부 데이터를 서버에서 저장하는 데 사용되는 경우가 많습니다. 데이터를 얻기 위해 디스크를 직접 읽는 것과 비교할 때 Redis를 사용할 수 있습니다. 많은 시간을 절약하고 효율성을 향상시킵니다. 예:
어떤 동영상 웹사이트에는 매일 홈페이지의 추천 동영상 열에 100만 명이 방문하고 있습니다. 이들이 모두 데이터베이스에 쿼리하고 읽는다면 매일 최소 100만 건 이상의 데이터베이스 쿼리 요청이 발생하게 됩니다. Redis를 사용하면 자주 검색되는 데이터를 메모리에 저장하여 1회 0.1초, 100만회에 100,000초가 절약되므로 속도와 비용이 크게 향상됩니다.
간단히 말하면 Redis는 다양한 애플리케이션 시나리오를 갖추고 있으며 지금부터 기본 사항을 학습하는 것이 매우 중요합니다.
5. Redis 설치
작업을 잘하려면 먼저 도구를 준비해야 합니다. Redis를 배우고 싶다면 당연히 첫 번째 단계는 Redis를 설치하는 것입니다. 저는 Windows 운영 체제를 사용하고 있으므로 Windows 시스템에 Redis를 설치하는 방법만 보여드리겠습니다. Redis를 사용해 보고 싶지만 설치하고 싶지 않다면 간단한 소개와 튜토리얼도 제공하는 공식 온라인 테스트 웹사이트를 이용할 수 있습니다.
Windows에서 Redis를 설치하려면 여기에서 Redis-x64-3.2.100.zip 압축 패키지 파일을 다운로드합니다(최신 버전이 있는 경우 최근 업데이트된 안정 버전을 다운로드할 수 있습니다).
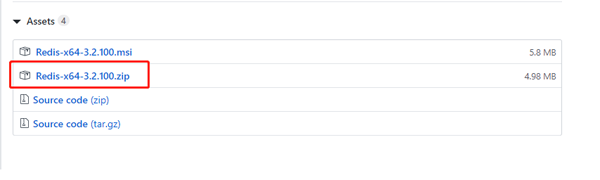
download
다운로드 후 자신의 폴더에 압축을 풀어주세요. 예를 들어 D:redis에 압축을 풀었습니다.
unzip
cmd 창을 열고 cd 명령을 사용하여 디렉터리를 압축이 풀린 폴더 경로로 전환한 다음(예: 디렉터리를 D:redis로 전환) 다음 명령을 실행합니다.
redis-server.exe redis.windows.conf。
After
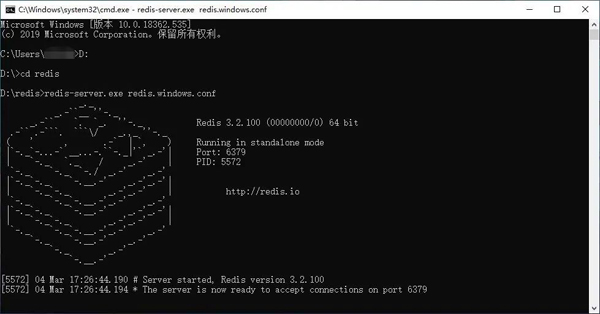
redis-server
그림과 같이 포트 번호가 6379이고 기타 관련 정보를 볼 수 있습니다. Redis 서버를 사용하는 경우 새 cmd 창을 열고 원래 창을 열어 두어야 합니다. 그렇지 않으면 서버에 액세스할 수 없습니다. 또한 경로를 redis 디렉터리로 전환한 후 다음을 실행합니다.
redis-cli.exe -h 127.0.0.1 -p 6379
키-값 쌍 저장:
set firstkey "hello redis"
키-값 쌍 제거:
get firstkey
연결 닫기:
quit
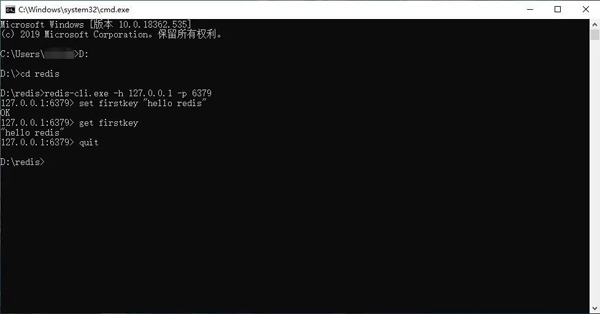
first_use
Windows Redis에서 성공적으로 작동되었으며 시스템에 설치되었으며 처음으로 Redis의 키-값 쌍 저장 모드를 경험했습니다.
6. Redis 데이터 구조
Redis는 String(문자열), Hash(해시), List(목록), Set(컬렉션) 및 SortedSet(순서가 지정된 집합)의 5가지 데이터 구조를 지원합니다. 아래에서는 각 데이터 구조와 기본 명령을 간략하게 소개합니다.
Hongmeng 공식 전략적 협력 및 공동 구축 - HarmonyOS 기술 커뮤니티
StringString是Redis最基本的数据结构,也是任何存储系统都必备的数据类型。String类型是二进制安全的,简单来说,基本上你什么都能用字符串存储,你可以把图片文件的内容或者序列化的对象作为字符串来存储。String类型的值最大可以存512MB,确实基本什么都够存了。
> set mykey "hello world" OK
> gey mykey "hello world"
> getrange mykey 6 10 "world" > getrange mykey 0 20 "hello world" > getrange mykey 0 -1 "hello world"
Tips:从上面几个实例,我们不难看出字符串起始从0开始;若end大于字符串长度时返回完整字符串;而当end为-1时,end为字符串最后一个字符。
> getset database "mysql" (nil) > get database "mysql" > getset database "redis" "mysql" > get database "redis"
Tips: 当键未设置时,会返回(nil)。
> strlen mykey (integer) 11
> append mykey ", hello redis" 24 >get mykey "hello world, hello redis"
> set incr_num 10 OK >get incr_num "10" >incr incr_num (integer) 11
> incrby incr_num 4 (intrger) 15
> incrbyfloat incr_num 0.5 15.5
Tips:整数值会显示为integer,当变为浮点型后并不会提示为float
> set decr_num 10 OK > get decr_num "10" > decr decr_num (integer) 9
> decrby decr_num 4 (integer) 5
Tips:redis并没有数字值减少给定浮点值的命令,如果我们想要decr_num减少2.5,可以用incrbyfloat命令执行incrbyfloat decr_num -2.5。
> incrbyfloat decr_num -2.5 2.5
decrby key decrement:整数值减少给定整数值(decrement)
decr key:整数值-1
incrbyfloat key increment:数字值增加给定浮点值(increment)
incrby key increment:整数值增加给定整数值(increment)
ncr key:整数值+1
append key value:如果可以已存在且是一个字符串,则将指定value添加到原值末尾,会返回操作后字符串长度
strlen key:返回键所存储的字符串值的长度
getset key value:设置指定键的新值,并返回旧值
getrange key start end:返回key中字符串的子串
get key:获取指定键的值
set key value:设置指定键的值
2. HashHash存储的是field和value的映射关系,适合用户存储对象。比如要存储一个用户的姓名、年龄、地址等,就可以使用Hash。每个Hash可以存储232>-1个field-value对(4294967295,40多亿)。
> hset myhash name "test" (integer) 1 > hget myhash name "NPC" > hset myhash name "NPC" (integer) 0
Tips:使用hset命令,新建字段并设置值成功后返回1,如果修改已有字段的值则返回0。
> hmset myhash age "20" country "China" OK
> hexists myhash name (integer) 1 > hexists myhash phone (integer) 0
Tips:哈希表key中含有字段field返回1,不含有或对应key不存在返回0。
> hmget myhash name age phone 1) "NPC" 2) "20" 3) (nil)
> hgetall myhash 1) "name" 2) "NPC" 3) "age" 4) "20" 5) "country" 6) "China"
> hkeys myhash 1) "name" 2) "age" 3) "country"
> hvals myhash 1) "NPC" 2) "20" 3) "China"
> hlen myhash 3
> hdel myhash age (integer) 1
hdel key field1:删除哈希表key中一个field
hlen key:获取哈希表key中字段的数量
hvals key:获取哈希表key中所有value
hkeys key:获取哈希表key中所有field
hgetall key:获取哈希表key中所有field-value对
hmget key field1 [field2]:获取哈希表key中所有给定field的value
hexists key field:查看field是否存在于哈希表key中
hmset key field1 value1 [field2 value2]:同时设置哈希表key中的多个field-value对。
hset key field value:设置哈希表中key中field的值为value
hget key field:获取哈希表key中field对应的value
3. ListRedis的List类型是简单的字符串列表,在底层实现上相当于一个链表,我们可以在列表的头部(左边)或尾部(右边)添加值。列表最多可以存储232>-1个元素(4294967295,40多亿)。
> lpush mylist "a" "b" (integer) 2 > rpush mylist "c" "d" (integer) 4
Tips:执行lpush和rpush命令后返回列表的长度。
> llen mylist (integer) 4
> lrange mylist 0 -1 1) "b" 2) "a" 3) "c" 4) "d" > lrange mylist 1 -2 1) "a" 2) "c"
Tips:由上述例子我们不难看出lrange命令中的start和end参数都是索引值,其中0代表第一个元素,-1表示最后一个元素。
> lindex mylist 0 "b"
> lpop mylist "b" > rpop mylist "d"
> rpush rem "hello" "hello" "redis" "hello" (integer) 4 > lrange rem 0 -1 1) "hello" 2) "hello" 3) "redis" 4) "hello" > lrem rem -2 "hello" (integer) 2 >lrange rem 0 -1 1) "hello" 2) "redis"
在列表中从左到右搜索,移除数量为count且与value相等的元素。count
lrem key count value:根据count的值,移除列表中与参数value相等的元素
lpop key:移除并获取列表头部的值
rpop key:移除并获取列表尾部的值
lindex key index:通过索引获取列表中元素
lrange key start end:获取列表指定范围内的值
llen key:获取列表长度
lpush key value1 [value2]:将一个或多个值插入到列表头部(左边)
rpush key value1 [value2]:将一个或多个值插入到列表尾部(右边)
4. SetSet(集合)存储string类型的值,集合不允许重复元素,但集合里面的元素没有先后顺序。集合中最大的成员数为232>-1(4294967295,40多亿)。
> sadd myset1 "hello" "redis" (integer) 2 > sadd myset1 "hello" (integer) 0
Tips:当向集合添加重复成员时,返回0
> scard myset1 2
> smembers myset1 1) "hello" 2) "redis"
> sadd myset2 "hello" "world" (integer) 2 > sdiff myset1 myset2 1) "redis" > sdiff myset2 myset1 1) "world"
> sinter myset1 myset2 1) "hello"
> sunion myset1 myset2 1) "hello" 2) "redis" 3) "world"
> sadd myset1 "NPC" (integer) 1 >spop myset1 "redis" >smembers myset1 1) "NPC" 2) "hello"
spop key:移除并返回集合中的一个随机元素
sunion key1 [key2]:返回所有给定集合的并集
sinter key1 [key2]:返回所有给定集合的交集
sdiff key1 [key2]:返回所有给定集合的差集
smembers key:返回集合中的所有成员
scard key:获取集合成员数量
sadd key member1 [member2]:向集合添加一个或多个成员
5. SortedSet除了无序集合(Set),Redis还提供了有序集合(SortedSet),有序集合不允许重复的成员,且每个不同的成员都关联一个double类型的分数,redis通过这些分数对成员进行从小到大排序。有序集合有时也被称为ZSet,因为其命令都是以字母Z开头的。
> zadd myzset 10 "one" 20 "two" 30 "three" (integer) 3
> zcard myzset 3
> zscore myzset "one" 10.0
> zrange myzset 0 -1 1) "one" 2) "two" 3) "three" > zrange myzset 0 -1 withscores 1) "one" 2) 10.0 3) "two" 4) 20.0 5) "three" 6) 30.0 > zrevrange myzset 0 -1 withscores 1) "three" 2) 30.0 3) "two" 4) 20.0 5) "one" 6) 10.0
> zrank myzset "one" 0 >zrank myzset "three" 2 > zrevrank myzset "one" 2 > zrevrank myzset "three" 0
> zcount myzset 15 40 2
> zrange myzset 0 -1 withscores 1) "one" 2) 10.0 3) "two" 4) 20.0 5) "three" 6) 30.0 > zincrby myzset 40 "one" 50.0 > zrange myzset 0 -1 withscores 1) "two" 2) 20.0 3) "three" 4) 30.0 5) "one" 6) 50.0
zincrby key increment member:将指定成员的分数增加increment
zcount key min max:返回分数在min和max之间的成员数量
zrank key member:返回指定成员的排名,从小到大排序
zrevrank key member:返回指定成员的排名,从大到小排序
zrange key start end [withscores]:通过索引start和end从小到大返回成员
zrevrange key start end [withscores]:通过索引start和end从大到小返回成员
zscore key member:返回指定成员的分数
zcard key:获取有序集合的成员数量
zadd key score1 member1 [score2 member2]:向有序集合中添加一个或多个成员,或者更新已有成员分数
위 내용은 Redis의 기본 지식 포인트는 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 Redis 클러스터 모드를 구축하는 방법
Apr 10, 2025 pm 10:15 PM
Redis 클러스터 모드를 구축하는 방법
Apr 10, 2025 pm 10:15 PM
Redis Cluster Mode는 Sharding을 통해 Redis 인스턴스를 여러 서버에 배포하여 확장 성 및 가용성을 향상시킵니다. 시공 단계는 다음과 같습니다. 포트가 다른 홀수 redis 인스턴스를 만듭니다. 3 개의 센티넬 인스턴스를 만들고, Redis 인스턴스 및 장애 조치를 모니터링합니다. Sentinel 구성 파일 구성, Redis 인스턴스 정보 및 장애 조치 설정 모니터링 추가; Redis 인스턴스 구성 파일 구성, 클러스터 모드 활성화 및 클러스터 정보 파일 경로를 지정합니다. 각 redis 인스턴스의 정보를 포함하는 Nodes.conf 파일을 작성합니다. 클러스터를 시작하고 Create 명령을 실행하여 클러스터를 작성하고 복제본 수를 지정하십시오. 클러스터에 로그인하여 클러스터 정보 명령을 실행하여 클러스터 상태를 확인하십시오. 만들다
 Redis 데이터를 지우는 방법
Apr 10, 2025 pm 10:06 PM
Redis 데이터를 지우는 방법
Apr 10, 2025 pm 10:06 PM
Redis 데이터를 지우는 방법 : Flushall 명령을 사용하여 모든 키 값을 지우십시오. FlushDB 명령을 사용하여 현재 선택한 데이터베이스의 키 값을 지우십시오. 선택을 사용하여 데이터베이스를 전환 한 다음 FlushDB를 사용하여 여러 데이터베이스를 지우십시오. del 명령을 사용하여 특정 키를 삭제하십시오. Redis-Cli 도구를 사용하여 데이터를 지우십시오.
 Redis 대기열을 읽는 방법
Apr 10, 2025 pm 10:12 PM
Redis 대기열을 읽는 방법
Apr 10, 2025 pm 10:12 PM
Redis의 대기열을 읽으려면 대기열 이름을 얻고 LPOP 명령을 사용하여 요소를 읽고 빈 큐를 처리해야합니다. 특정 단계는 다음과 같습니다. 대기열 이름 가져 오기 : "큐 :"와 같은 "대기열 : my-queue"의 접두사로 이름을 지정하십시오. LPOP 명령을 사용하십시오. 빈 대기열 처리 : 대기열이 비어 있으면 LPOP이 NIL을 반환하고 요소를 읽기 전에 대기열이 존재하는지 확인할 수 있습니다.
 Centos redis에서 lua 스크립트 실행 시간을 구성하는 방법
Apr 14, 2025 pm 02:12 PM
Centos redis에서 lua 스크립트 실행 시간을 구성하는 방법
Apr 14, 2025 pm 02:12 PM
CentOS 시스템에서는 Redis 구성 파일을 수정하거나 Redis 명령을 사용하여 악의적 인 스크립트가 너무 많은 리소스를 소비하지 못하게하여 LUA 스크립트의 실행 시간을 제한 할 수 있습니다. 방법 1 : Redis 구성 파일을 수정하고 Redis 구성 파일을 찾으십시오. Redis 구성 파일은 일반적으로 /etc/redis/redis.conf에 있습니다. 구성 파일 편집 : 텍스트 편집기 (예 : VI 또는 Nano)를 사용하여 구성 파일을 엽니 다. Sudovi/etc/redis/redis.conf LUA 스크립트 실행 시간 제한을 설정 : 구성 파일에서 다음 줄을 추가 또는 수정하여 LUA 스크립트의 최대 실행 시간을 설정하십시오 (Unit : Milliseconds).
 Redis 명령 줄을 사용하는 방법
Apr 10, 2025 pm 10:18 PM
Redis 명령 줄을 사용하는 방법
Apr 10, 2025 pm 10:18 PM
Redis Command Line 도구 (Redis-Cli)를 사용하여 다음 단계를 통해 Redis를 관리하고 작동하십시오. 서버에 연결하고 주소와 포트를 지정하십시오. 명령 이름과 매개 변수를 사용하여 서버에 명령을 보냅니다. 도움말 명령을 사용하여 특정 명령에 대한 도움말 정보를 봅니다. 종금 명령을 사용하여 명령 줄 도구를 종료하십시오.
 Redis 카운터를 구현하는 방법
Apr 10, 2025 pm 10:21 PM
Redis 카운터를 구현하는 방법
Apr 10, 2025 pm 10:21 PM
Redis Counter는 Redis Key-Value Pair 스토리지를 사용하여 다음 단계를 포함하여 계산 작업을 구현하는 메커니즘입니다. 카운터 키 생성, 카운트 증가, 카운트 감소, 카운트 재설정 및 카운트 얻기. Redis 카운터의 장점에는 빠른 속도, 높은 동시성, 내구성 및 단순성 및 사용 편의성이 포함됩니다. 사용자 액세스 계산, 실시간 메트릭 추적, 게임 점수 및 순위 및 주문 처리 계산과 같은 시나리오에서 사용할 수 있습니다.
 Redis 만료 정책을 설정하는 방법
Apr 10, 2025 pm 10:03 PM
Redis 만료 정책을 설정하는 방법
Apr 10, 2025 pm 10:03 PM
REDIS 데이터 만료 전략에는 두 가지 유형이 있습니다. 정기 삭제 : 만료 된 기간 캡-프리브-컨트 컨트 및 만료 된 시간 캡-프레임 딜레이 매개 변수를 통해 설정할 수있는 만료 된 키를 삭제하기위한주기 스캔. LAZY DELETION : 키를 읽거나 쓰는 경우에만 삭제가 만료 된 키를 확인하십시오. 그것들은 게으른 불쾌한 말입니다. 게으른 유발, 게으른 게으른 expire, Lazyfree Lazy-user-del 매개 변수를 통해 설정할 수 있습니다.
 Debian Readdir의 성능을 최적화하는 방법
Apr 13, 2025 am 08:48 AM
Debian Readdir의 성능을 최적화하는 방법
Apr 13, 2025 am 08:48 AM
Debian Systems에서 ReadDir 시스템 호출은 디렉토리 내용을 읽는 데 사용됩니다. 성능이 좋지 않은 경우 다음과 같은 최적화 전략을 시도해보십시오. 디렉토리 파일 수를 단순화하십시오. 대규모 디렉토리를 가능한 한 여러 소규모 디렉토리로 나누어 읽기마다 처리 된 항목 수를 줄입니다. 디렉토리 컨텐츠 캐싱 활성화 : 캐시 메커니즘을 구축하고 정기적으로 캐시를 업데이트하거나 디렉토리 컨텐츠가 변경 될 때 캐시를 업데이트하며 readDir로 자주 호출을 줄입니다. 메모리 캐시 (예 : Memcached 또는 Redis) 또는 로컬 캐시 (예 : 파일 또는 데이터베이스)를 고려할 수 있습니다. 효율적인 데이터 구조 채택 : 디렉토리 트래버스를 직접 구현하는 경우 디렉토리 정보를 저장하고 액세스하기 위해보다 효율적인 데이터 구조 (예 : 선형 검색 대신 해시 테이블)를 선택하십시오.
